提高模型泛化能力的方法——影像增廣和微調
影像增廣
影像增廣(image augmentation)技術通過對訓練影像做一系列隨機改變,來產生相似但又不同的訓練樣本,從而擴大訓練資料集的規模,
影像增廣的另一種解釋是,隨機改變訓練樣本可以降低模型對某些屬性的依賴,從而提高模型的泛化能力,
例如,我們可以對影像進行不同方式的裁剪,使感興趣的物體出現在不同位置,從而減輕模型對物體出現位置的依賴性,我們也可以調整亮度、色彩等因素來降低模型對色彩的敏感度,可以說,在當年AlexNet的成功中,影像增廣技術功不可沒,
為了在預測時得到確定的結果,我們通常只將影像增廣應用在訓練樣本上,而不在預測時使用含隨機操作的影像增廣,
微調
問題:假設我們想從影像中識別出不同種類的椅子,然后將購買鏈接推薦給用戶,一種可能的方法是先找出100種常見的椅子,為每種椅子拍攝1,000張不同角度的影像,然后在收集到的影像資料集上訓練一個分類模型,這個椅子資料集雖然可能比Fashion-MNIST資料集要龐大,但樣本數仍然不及ImageNet資料集中樣本數的十分之一,這可能會導致適用于ImageNet資料集的復雜模型在這個椅子資料集上過擬合,同時,因為資料量有限,最終訓練得到的模型的精度也可能達不到實用的要求,
解決方法:
1.收集更多的資料,然而,收集和標注資料會花費大量的時間和資金,
2.應用遷移學習(transfer learning),將從源資料集學到的知識遷移到目標資料集上,例如,雖然ImageNet資料集的影像大多跟椅子無關,但在該資料集上訓練的模型可以抽取較通用的影像特征,從而能夠幫助識別邊緣、紋理、形狀和物體組成等,這些類似的特征對于識別椅子也可能同樣有效,
接下來介紹遷移學習中的一種常用技術:微調
微調由以下4步構成:
- 在源資料集(如ImageNet資料集)上預訓練一個神經網路模型,即源模型,
- 創建一個新的神經網路模型,即目標模型,它復制了源模型上除了輸出層外的所有模型設計及其引數,我們假設這些模型引數包含了源資料集上學習到的知識,且這些知識同樣適用于目標資料集,我們還假設源模型的輸出層跟源資料集的標簽緊密相關,因此在目標模型中不予采用,
- 為目標模型添加一個輸出大小為目標資料集類別個數的輸出層,并隨機初始化該層的模型引數,
- 在目標資料集(如椅子資料集)上訓練目標模型,我們將從頭訓練輸出層,而其余層的引數都是基于源模型的引數微調得到的,
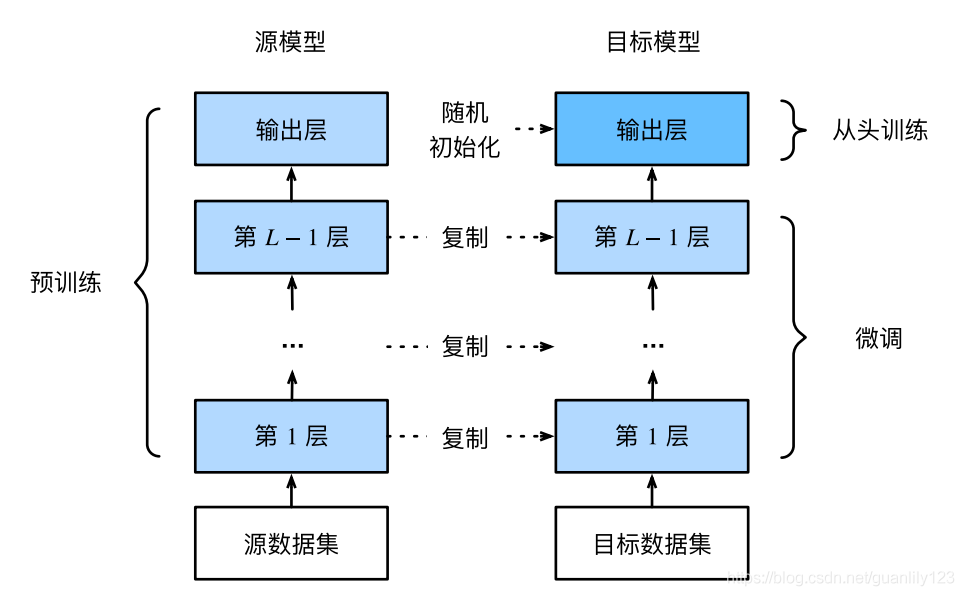
當目標資料集遠小于源資料集時,微調有助于提升模型的泛化能力,
目標檢測和邊界框
很多時候影像里有多個我們感興趣的目標,我們不僅想知道它們的類別,還想得到它們在影像中的具體位置,在計算機視覺里,我們將這類任務稱為目標檢測(object detection)或物體檢測,
在目標檢測里不僅需要找出影像里面所有感興趣的目標,而且要知道它們的位置,位置一般由矩形邊界框來表示,
錨框
目標檢測演算法通常會在輸入影像中采樣大量的區域,然后判斷這些區域中是否包含我們感興趣的目標,并調整區域邊緣從而更準確地預測目標的真實邊界框(ground-truth bounding box),
不同的
模型使用的區域采樣方法可能不同,這里我們介紹其中的一種方法:
它以每個像素為中心生成多個大小和寬高比(aspect ratio)不同的邊界框,這些邊界框被稱為錨框(anchor box),
寫到這里下不下去了,后續需要補充,敬請期待,,,,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294852.html
標籤:AI