如果需要完整代碼可以關注下方公眾號,后臺回復“代碼”即可獲取,阿光期待著您的光臨~

文章目錄
- 一、概述
- 二、問題求解
- 1.構造拉格朗日函式
- 2.對偶問題
- 3.KKT條件求解極值
2021人工智能領域新星創作者,帶你從入門到精通,該博客每天更新,逐漸完善機器學習各個知識體系的文章,幫助大家更高效學習,

一、概述
上篇文章我們引出了SVM的硬間隔的概念,它是最大化我們每個樣本到超平面的間隔,使每個樣本的函式間隔大于等于1,即:
y
i
(
w
T
x
i
+
b
)
≥
1
y_i(w^Tx_i+b)\geq1
yi?(wTxi?+b)≥1
而且它有個前提條件就是資料是線性可分的,就是能夠找到一個超平面能夠將資料完全區分,但是區分方式有很多種,硬間隔就是為了找到最優的一個超平面,但是在實際中,我們很多資料是不可分的,找不到一個超平面進行完全區分,比如說:
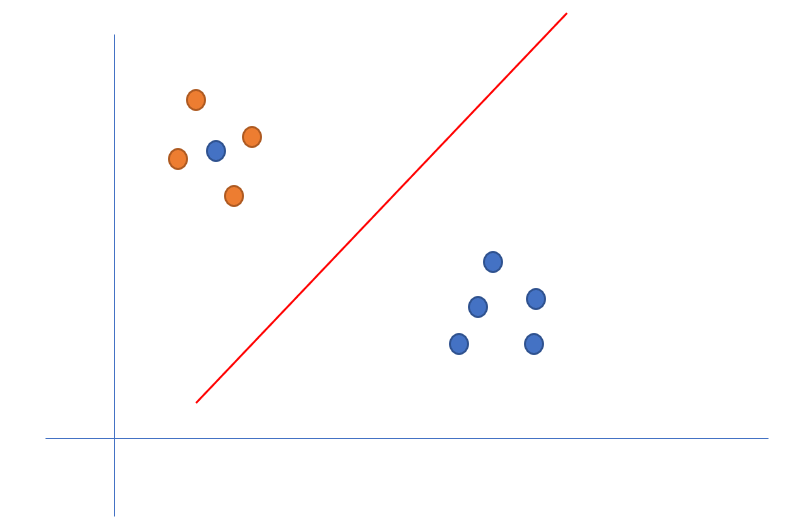
上面這幅圖可以看到在黃色區域存在一個噪音點,我們是無論如何都無法進行完全分類的,但是我們還想找到一個超平面進行區分,顯然仍然是中間這條線效果最好,盡管分類錯誤一個藍色噪音點,但是只是犧牲一個樣本的分類正確率,成就絕大數樣本的分類正確,
也就是說,除去一些難以區分的噪音點,我們的資料仍舊是線性可分的,
此時就說明一些噪音點是不能滿足我們之前函式間隔大于1的條件的,即
y
i
(
w
T
x
i
+
b
)
≥
1
y_i(w^Tx_i+b)\geq1
yi?(wTxi?+b)≥1 ,那么我們可以引入一個松弛變數,讓每個樣本可以存在一定的誤判誤差,現在約束條件就變成了:
y
i
(
w
T
x
i
+
b
)
≥
1
?
ξ
i
y_i(w^Tx_i+b)\geq1-\xi_i
yi?(wTxi?+b)≥1?ξi?
這樣引入了松弛變數后,原來的約束條件就不那么強了,而且這個
ξ
i
\xi_i
ξi? 每個樣本是不同的,如果對于那些線性可分的資料他應該是為0的,仍滿足之前的條件,但是如果是那些噪音點,就可以降低要求,比如說上面的那個藍色噪音點,如果要滿足新的約束條件,那么
ξ
\xi
ξ 應該為大于1的,所以可以將它看成一種損失,如果正確線性可分的資料應該為0,如果是不可分的資料一定是大于0的,我們目標就是讓每個樣本的
ξ
\xi
ξ 最小,那么我們的目標函式就從原來的
m
i
n
1
2
w
T
w
min\frac{1}{2}w^Tw
min21?wTw 變為了:
m
i
n
1
2
w
T
w
+
C
∑
i
=
1
m
ξ
i
min\frac{1}{2}w^Tw+C\sum_{i=1}^m\xi_i
min21?wTw+Ci=1∑m?ξi?
其中的C代表懲罰系數,和正則項的那個意義差不多,如果C值越大,我們允許錯誤的程度越小,即
ξ
\xi
ξ 就越小,也就是容忍錯誤的能力越小,
那么此時的問題就變成了:
m
i
n
1
2
w
T
w
+
C
∑
i
=
1
m
ξ
i
min\frac{1}{2}w^Tw+C\sum_{i=1}^m\xi_i
min21?wTw+Ci=1∑m?ξi?
y i ( w T x i + b ) ≥ 1 ? ξ i y_i(w^Tx_i+b)\geq1-\xi_i yi?(wTxi?+b)≥1?ξi?
ξ i ≥ 0 \xi_i\geq0 ξi?≥0
二、問題求解
求解軟間隔的問題和硬間隔是一模一樣的,都是構造拉格朗日,然后轉化成對偶問題,利用KKT條件求解最優值,
1.構造拉格朗日函式
第一節中最終我們獲得了目標函式和兩個不等式約束條件,那么需要構造一個拉格朗日函式,為:
L
(
w
,
b
,
ξ
,
λ
,
μ
)
=
1
2
w
T
w
+
C
∑
i
=
1
m
ξ
i
+
∑
i
=
1
m
λ
i
[
(
1
?
ξ
i
)
?
y
i
(
w
T
x
i
+
b
)
]
?
∑
i
=
1
m
μ
i
ξ
i
L(w,b,\xi,\lambda,\mu)=\frac{1}{2}w^Tw+C\sum_{i=1}^m\xi_i+\sum_{i=1}^m\lambda_i[(1-\xi_i)-y_i(w^Tx_i+b)]-\sum_{i=1}^m\mu_i\xi_i
L(w,b,ξ,λ,μ)=21?wTw+Ci=1∑m?ξi?+i=1∑m?λi?[(1?ξi?)?yi?(wTxi?+b)]?i=1∑m?μi?ξi?
λ i ≥ 0 \lambda_i\geq0 λi?≥0
μ i ≥ 0 \mu_i\geq0 μi?≥0
所以此時我們的原問題就轉化成了:
m
i
n
w
,
b
,
ξ
m
a
x
λ
,
μ
L
(
w
,
b
,
ξ
,
λ
,
μ
)
min_{w,b,\xi}max_{\lambda,\mu}L(w,b,\xi,\lambda,\mu)
minw,b,ξ?maxλ,μ?L(w,b,ξ,λ,μ)
2.對偶問題
為了求解方便,我們將原問題轉化為它的對偶問題,對偶問題是拉格朗日函式的極大極小問題,也就是:
m
a
x
λ
,
μ
m
i
n
w
,
b
,
ξ
L
(
w
,
b
,
ξ
,
λ
,
μ
)
max_{\lambda,\mu}min_{w,b,\xi}L(w,b,\xi,\lambda,\mu)
maxλ,μ?minw,b,ξ?L(w,b,ξ,λ,μ)
對于該對偶問題,我們應該先求拉格朗日函式的極小值,首先對
w
,
b
,
ξ
w,b,\xi
w,b,ξ 進行求偏導,得到:
?
L
?
w
=
w
?
∑
i
=
1
m
λ
i
y
i
x
i
=
0
\frac{\partial L}{\partial w}=w-\sum_{i=1}^m\lambda_iy_ix_i=0
?w?L?=w?i=1∑m?λi?yi?xi?=0
? L ? b = ? ∑ i = 1 m λ i y i = 0 \frac{\partial L}{\partial b}=-\sum_{i=1}^m\lambda_iy_i=0 ?b?L?=?i=1∑m?λi?yi?=0
? L ? ξ i = C ? λ i ? μ i = 0 \frac{\partial L}{\partial \xi_i}=C-\lambda_i-\mu_i=0 ?ξi??L?=C?λi??μi?=0
我們將上面獲得的三個式子帶入原拉格朗日函式中就可以獲得
m
i
n
w
,
b
,
ξ
L
(
w
,
b
,
ξ
,
λ
,
μ
)
min_{w,b,\xi}L(w,b,\xi,\lambda,\mu)
minw,b,ξ?L(w,b,ξ,λ,μ) ,得:
m
i
n
w
,
b
,
ξ
L
(
w
,
b
,
ξ
,
λ
,
μ
)
=
?
1
2
∑
i
=
1
m
∑
j
=
1
m
λ
i
λ
j
y
i
y
j
x
i
T
x
j
+
∑
i
=
1
m
λ
i
min_{w,b,\xi}L(w,b,\xi,\lambda,\mu)=-\frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m\lambda_i\lambda_jy_iy_jx_i^Tx_j+\sum_{i=1}^m\lambda_i
minw,b,ξ?L(w,b,ξ,λ,μ)=?21?i=1∑m?j=1∑m?λi?λj?yi?yj?xiT?xj?+i=1∑m?λi?
所以我們得對偶問題又變成了:
m
a
x
λ
,
μ
m
i
n
w
,
b
,
ξ
L
(
w
,
b
,
ξ
,
λ
,
μ
)
=
m
a
x
λ
,
μ
?
1
2
∑
i
=
1
m
∑
j
=
1
m
λ
i
λ
j
y
i
y
j
x
i
T
x
j
+
∑
i
=
1
m
λ
i
max_{\lambda,\mu}min_{w,b,\xi}L(w,b,\xi,\lambda,\mu)=max_{\lambda,\mu}-\frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m\lambda_i\lambda_jy_iy_jx_i^Tx_j+\sum_{i=1}^m\lambda_i
maxλ,μ?minw,b,ξ?L(w,b,ξ,λ,μ)=maxλ,μ??21?i=1∑m?j=1∑m?λi?λj?yi?yj?xiT?xj?+i=1∑m?λi?
由于一般情況下我們是優化最小值的,需要轉換一下,添加個負號,得:
m
i
n
λ
,
μ
1
2
∑
i
=
1
m
∑
j
=
1
m
λ
i
λ
j
y
i
y
j
x
i
T
x
j
?
∑
i
=
1
m
λ
i
min_{\lambda,\mu}\frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m\lambda_i\lambda_jy_iy_jx_i^Tx_j-\sum_{i=1}^m\lambda_i
minλ,μ?21?i=1∑m?j=1∑m?λi?λj?yi?yj?xiT?xj??i=1∑m?λi?
∑ i = 1 m λ i y i = 0 \sum_{i=1}^m\lambda_iy_i=0 i=1∑m?λi?yi?=0
C ? λ i ? μ i = 0 C-\lambda_i-\mu_i=0 C?λi??μi?=0
λ i ≥ 0 \lambda_i\geq0 λi?≥0
μ i ≥ 0 \mu_i\geq0 μi?≥0
我們可以將后三個約束條件進行合并:
即:
0
≤
λ
i
≤
C
0\leq \lambda_i \leq C
0≤λi?≤C
我們的最終目標就是求出使上式達到最優的
λ
\lambda
λ ,然后帶入我們的w方程和b的方程中,獲得最優解
w
?
w^*
w? 和
b
?
b^*
b? ,那么這個最優解方程如何獲得呢?利用KKT條件,
3.KKT條件求解極值
由于我們的原問題是凸二次規劃問題,所以最終的解滿足KKT條件,條件如下:
?
L
?
w
=
w
?
∑
i
=
1
m
λ
i
y
i
x
i
=
0
\frac{\partial L}{\partial w}=w-\sum_{i=1}^m\lambda_iy_ix_i=0
?w?L?=w?i=1∑m?λi?yi?xi?=0
? L ? b = ? ∑ i = 1 m λ i y i = 0 \frac{\partial L}{\partial b}=-\sum_{i=1}^m\lambda_iy_i=0 ?b?L?=?i=1∑m?λi?yi?=0
? L ? ξ i = C ? λ i ? μ i = 0 \frac{\partial L}{\partial \xi_i}=C-\lambda_i-\mu_i=0 ?ξi??L?=C?λi??μi?=0
該三個是拉格朗日函式取得極值點的條件,
λ
i
?
(
y
i
(
w
T
x
i
+
b
)
?
1
+
ξ
i
?
)
=
0
\lambda_i^*(y_i(w^Tx_i+b)-1+\xi_i^*)=0
λi??(yi?(wTxi?+b)?1+ξi??)=0
μ i ? ξ i ? = 0 \mu_i^*\xi_i^*=0 μi??ξi??=0
這兩個為不等式約束條件,可以看出就是用拉格朗日乘子乘以原來的不等式約束使其等于0,
y
i
(
w
T
x
i
+
b
)
?
1
+
ξ
i
?
≥
0
y_i(w^Tx_i+b)-1+\xi_i^*\geq0
yi?(wTxi?+b)?1+ξi??≥0
ξ i ? ≥ 0 \xi_i^*\geq0 ξi??≥0
這兩個為原來的不等式約束條件,
λ
i
≥
0
\lambda_i\geq0
λi?≥0
μ i ≥ 0 \mu_i\geq0 μi?≥0
這兩個就是拉格朗日不等式約束的乘子必須大于等于0,
根據上面的KKT條件我們就可以獲得下面的結論:
w
?
=
∑
i
=
1
m
λ
i
?
y
i
x
i
w^*=\sum_{i=1}^m\lambda_i^*y_ix_i
w?=i=1∑m?λi??yi?xi?
b ? = y j ? ∑ i = 1 m y i λ i ? x i T x j b^*=y_j-\sum_{i=1}^my_i\lambda_i^*x_i^Tx_j b?=yj??i=1∑m?yi?λi??xiT?xj?
這樣我們就獲得了最終引數的運算式,將我們第三步優化目標函式獲得的 λ \lambda λ 帶入上邊的兩個方程就可以求出最優解引數了,
我們最終的分類超平面就可以寫成:
∑
i
=
1
m
λ
i
?
y
i
(
x
i
T
x
)
+
b
?
=
0
\sum_{i=1}^m\lambda_i^*y_i(x_i^Tx)+b^*=0
i=1∑m?λi??yi?(xiT?x)+b?=0
分類決策函式可以寫成:
f
(
x
)
=
s
i
g
n
(
∑
i
=
1
m
λ
i
?
y
i
(
x
i
T
x
)
+
b
?
)
f(x)=sign(\sum_{i=1}^m\lambda_i^*y_i(x_i^Tx)+b^*)
f(x)=sign(i=1∑m?λi??yi?(xiT?x)+b?)
寫在最后
大家好,我是阿光,覺得文章還不錯的話,記得“一鍵三連”哦!!!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294853.html
標籤:AI
上一篇:深度學習——計算機視覺