不管是偽分布式搭建,還是完全分布式搭建的集群,都會存在單點故障的問題,
如何解決單點故障?那就是HA高可用 甜
一、概述
1)所謂HA(highavailable),即高可用(7*24小時不中斷服務),
2)實作高可用最關鍵的策略是消除單點故障,
HA嚴格來說應該分成各個組件的HA機制:HDFS的HA和YARN的HA,
3)Hadoop2.0之前,在HDFS集群中NameNode存在單點故障(SPOF),
4)NameNode主要在以下兩個方面影響HDFS集群
NameNode機器發生意外,如宕機,集群將無法使用,直到管理員重啟
NameNode機器需要升級,包括軟體、硬體升級,此時集群也將無法使用
HDFS HA功能通過配置Active(對外提供服務)/Standby(預備)兩個nameNodes實作在集群中對NameNode的熱備來解決上述問題,如果出現故障,如機器崩潰或機器需要升級維護,這時可通過此種方式將NameNode很快的切換到另外一臺機器,zkfc組件是用來進行自動故障轉移的,
之后學習zookeeper分布式協調服務框架就可以對Active/Standby進行管理,接受namenode的注冊,監控namenode的狀態,
注意:在HA環境中,不需要存在SecondaryNamenode
二、HA的搭建
我們先打開官網尋找一下Apache Hadoop 2.8.5檔案,我們看到在HDFS中有這么兩個HA:
https://hadoop.apache.org/docs/r2.8.5/
![]()
QJM代表資料同步通過journalnode同步多個NameNode之間的元資料,NFS需要再搭建一個遠程服務器,較麻煩,QJM使用較多,
搭建前的準備:我們之前搭建Hadoop集群時使用到三個虛擬機node1、node2、node3
使用高可用HA,我們需要先安裝Zookeeper,
步驟一:
打開我們的node1虛擬機,把zookeeper壓縮包上傳到/opt/software路徑下,并解壓


步驟二:
切換到/zookeeper/conf目錄下,編輯zoo_sample.cfg檔案,重命名修改為zoo.cfg;
進入zoo.cfg檔案:vim zoo.cfg
修改dataDir路徑為dataDir=/opt/module/zookeeper-3.4.6/zkData
再在檔案末尾添加
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888這三句話代表三個zookeeper是哪三個
步驟三:
在/home/uek/app/zookeeper-3.4.6/這個目錄下創建zkData
mkdir -p zkData
再創建myid檔案
touch myid
代表本機是幾號服務器
vim myid
在檔案中添加與server對應的編號 1
保存退出
那么node1的zookeeper服務器配置好了,
步驟四:
把組態檔同步到另外兩個節點,
scp -r zookeeper-3.4.6/ root@node2:/opt/app/
scp -r zookeeper-3.4.6/ root@node3:/opt/app/
并分別修改myid檔案中內容為2、3
步驟五:
啟動zookeeper
先配置環境變數(三臺都需要配置)
vim /etc/profile
在末尾添加:
export ZOOKEEPER_HOME=/opt/app/zookeeper-3.4.6
export PATH=$PATH:$ZOOKEEPER_HOME/bin
出來之后source /etc/profile使檔案失效
接下來就可以啟動了!
[root@node1 zookeeper-3.4.6]# zkServer.sh start
[root@node2 zookeeper-3.4.6]# zkServer.sh start
[root@node3 zookeeper-3.4.6]# zkServer.sh start
之后通過jps命令查看就好了,
我們還可以查看狀態(誰是leader)
zkServer.sh status
接下來我們就可以配置HDFS-HA集群了
步驟一:
配置hadoop-env.sh,關聯JDK
export JAVA_HOME=/home/app/jdk1.8.0_192
步驟二:
配置core-site.xml
<configuration>
<!--把兩個NameNode)的地址組裝成一個集群mycluster-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://myCluster</value>
</property>
<!--指定hadoop運行時產生檔案的存盤目錄-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/app/hadoop-2.8.5/temp</value>
</property>
</configuration>步驟三:
配置hdfs-site.xml高可用
<configuration>
<!--高可用集群名稱-->
<property>
<name>dfs.nameservices</name>
<value>myCluster</value>
</property>
<!--集群中NameNode節點都有哪些-->
<property>
<name>dfs.ha.namenodes.myCluster</name>
<value>nn1,nn2</value>
</property>
<!--nn1的RPC通信地址-->
<property>
<name>dfs.namenode.rpc-address.myCluster.nn1</name>
<value>node1:9000</value>
</property>
<!--nn2的RPC通信地址-->
<property>
<name>dfs.namenode.rpc-address.myCluster.nn2</name>
<value>node2:9000</value>
</property>
<!--nn1的http通信地址-->
<property>
<name>dfs.namenode.http-address.myCluster.nn1</name>
<value>node1:50070</value>
</property>
<!--nn2的http通信地址-->
<property>
<name>dfs.namenode.http-address.myCluster.nn2</name>
<value>node2:50070</value>
</property>
<!--指定NameNode元資料在JournalNode上的存放位置-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/myCluster</value>
</property>
<!--配置隔離機制,即同一時刻只能有一臺服務器對外回應-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--使用隔離機制時需要ssh無秘鑰登錄-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--宣告journalnode服務器存盤目錄-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/app/hadoop-2.8.5/journalnodeData</value>
</property>
<!--關閉權限檢查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!--訪問代理類:client,mycluster,active配置失敗自動切換實作方式-->
<property>
<name>dfs.client.failover.proxy.provider.myCluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</
value>
</property>
</configuration>步驟四:
配置HDFS-HA自動故障轉移
(1)在hdfs-site.xml中增加
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
(2)在core-site.xml檔案中增加
<property>
<name>ha.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
接下來給node2、node3同步一下
scp -r hadoop-2.8.5/ root@node2:/opt/app
scp -r hadoop-2.8.5/ root@node3:/opt/app
步驟五:
啟動啟動HDFS-HA集群(前提是啟動了zookeeper)
1)在各個JournalNode節點上,輸入以下命令啟動journalnode服務:
hadoop-daemon.sh start journalnode
2)在[nn1]上,對其進行格式化,并啟動:
hdfs namenode -format
hadoop-daemon.sh start namenode
3)在[nn2]上,同步nn1的元資料資訊
hdfs namenode-bootstrapStandly
4)初始化HA在Zookeeper中狀態
hdfs zkfc -formatZK
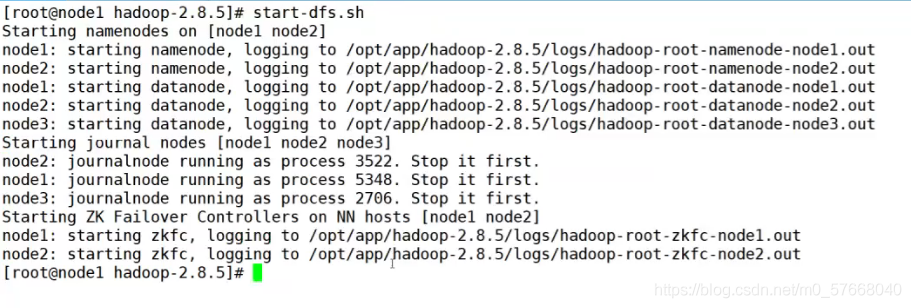
5)啟動HDFS
start-dfs.sh
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294901.html
標籤:其他