首先,我們通過一道例題來回憶一下test error和training error.
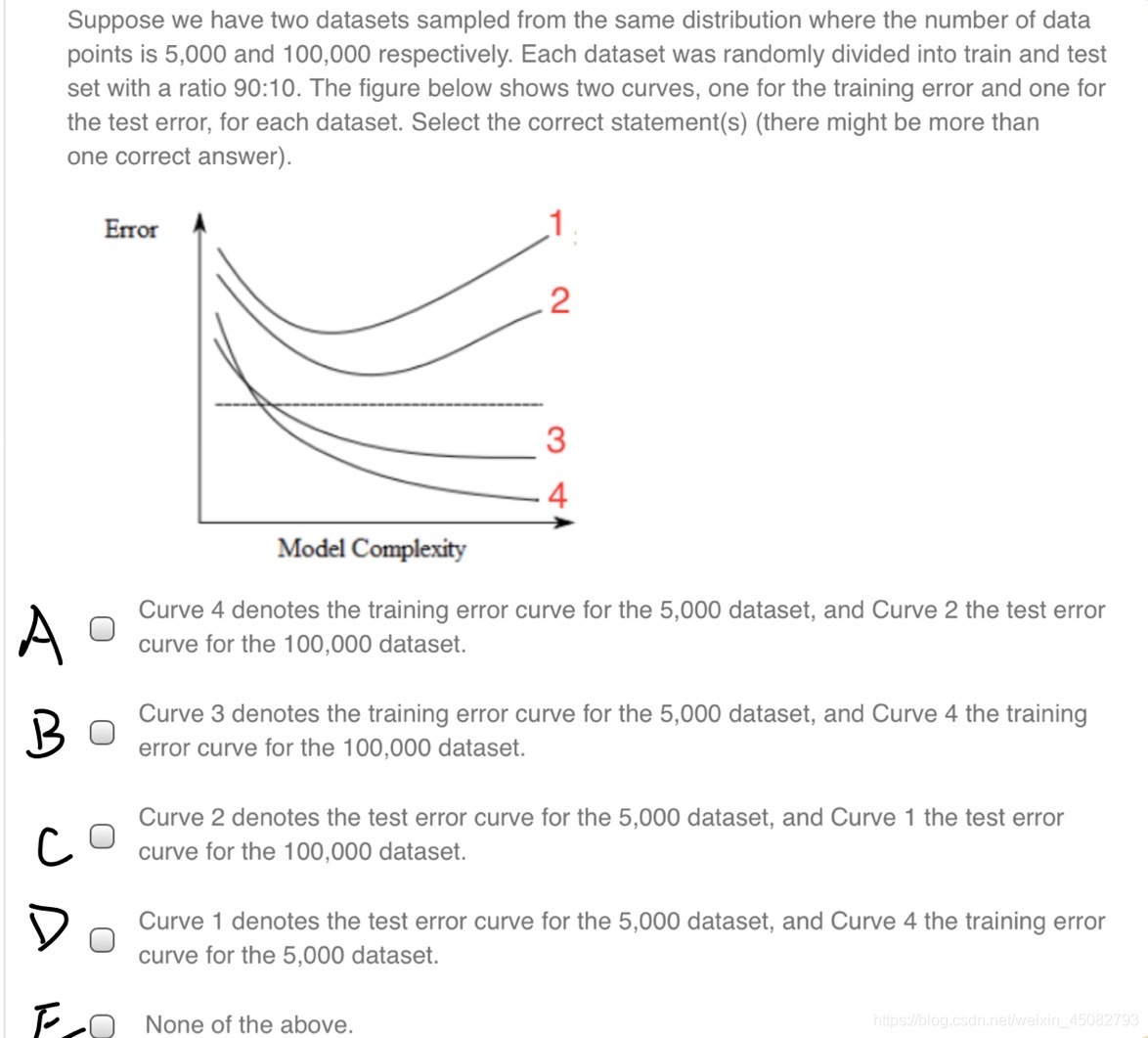
答案:A、D,決議如下:
別急!我們再來重溫一下resampling methods.
Resampling methods are process of repeatedly drawing samples from a training data set and refitting a given model on each sample with the goal of learning more about the model.
也就是說在給定訓練集而且資料量有限的情況下,我們可以通過resampling methods來從有限的資料中獲取更多的資訊,Resampling methods 有時候的計算量特別大,因為它需要repeatedly performing the same statistical methods across different subsets of data.
Cross validation是眾多resampling methods的一種,It can estimate the test error rate by holding out a subset of the training observations from the fitting process and modeling those held out observations.
接下來我們將介紹三類cross validation.
1、Validation set approach
Validation set approach的目的也是基于已有的observations預測test error.

如圖所示,得到一個data set之后我們先要隨機地把整個資料集分為training set和validation set,然后,用training set擬合一個模型,最后,用這個模型來預測validation set的結果,
誠然,validation set approach是個簡單且非常容易理解、實施的方法,但是它卻有兩大缺陷:
1)通過Validation set approach預測的test error是highly variable的,可變性非常大,這點非常好理解,運用此方法時,我們隨機地分割了data set,這就造成了非常大的隨機性,
The validation estimate of the test error rate can be highly variable depending on which observations are included in the training set and which are included in the validation set.
2)因為只有一半的observations被用來擬合模型,所以我們通過Validation set approach得到的對test error rate的估計是overestimate的,
Statistical methods perform worse when trained on fewer observations.
最后,給出一道例題方便理解,懶得手打了嗷^^_
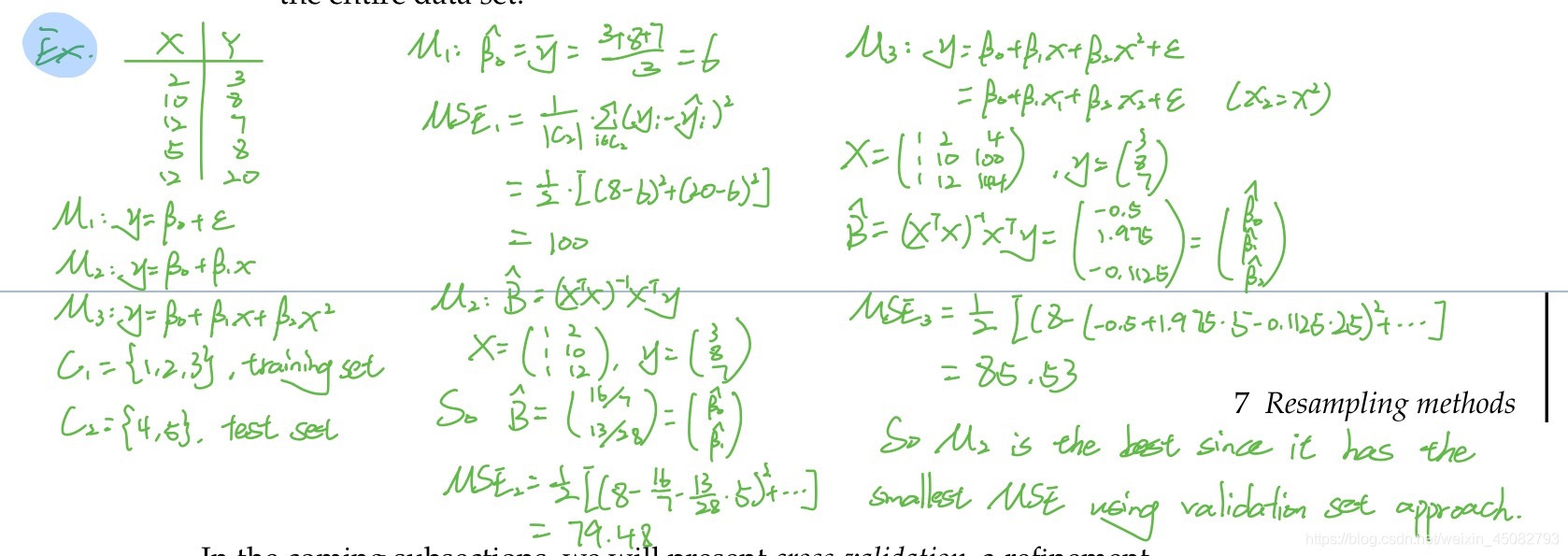
2、k-fold cross-validation
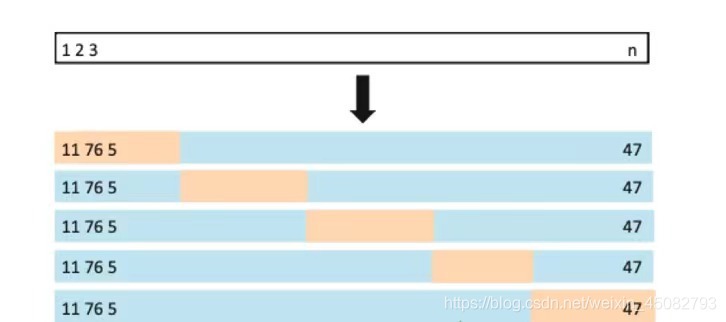
在k-fold cross-validation中,observations被隨機切割成k組,這k組資料的數量大致相同(如果把十個資料分為3組,我們大致分為3-3-4),
我們會從這k組資料選出一組作為validation set,其余k-1組作為training set來訓練模型,重復此操作k次,也就是依次選擇每組資料作為validation set而其他組別作為training set,得到k個MSE(mean squared error).
對這k個MSE,我們通過下方公式估算test MSE.
通常來說,我們不會把k設定得太大因為計算起來太麻煩了,一般會取5或者10,下文第四章我們會提到k值與方差、偏差之間的關系,
最后,給出一道例題方便理解,懶得手打了嗷^^_

3、Leave-one-out cross-validation
簡稱LOOCV,validation set永遠只有一個observation,LOOCV是k-fold cross-validation的一種形式——k=n,n是資料集的大小,
相比起validation set approach,LOOCV大致有以下兩條優勢,
1)Far less bias.我們訓練模型時,訓練集大小為n-1,對比起k-fold cross-validation,此方法用了更多的資料進行訓練,所以此方法的bias更小,而且it tends to not overestimate the test error rate as much as the validation set approach does.
2)Always yield the same results.因為LOOCV方法在分割資料集時,沒有隨機性,
但是此方法的劣勢也很明顯,那就是計算起來太繁瑣了——對于一個大小為n的資料集我們需要進行n此計算,
不過,當我們使用最小二乘回歸時,計算會相對簡單一點,我們可以套用下方公式,其中,被稱之為leverage,是矩陣
的第i個對角元素,
4、k-fold validation中如何權衡方差與偏差?
如果我們想最小化偏差Bias,最合適的方法必然是LOOCV,因為比起其他k值的k-fold validation,它用來訓練模型的資料是最多的,
鑒于偏差不是影響test error的唯一因素,我們同樣需要考慮如何減小方差,LOOCV的方差很大,而且由于LOOCV比較的眾多模型都是建立在幾乎一樣的資料集上的(根據其特性可得),它產生的結果是高度相關的,
總的來說,隨著k值的增大,偏差會減小,方差會增大,
摸魚結束,下班!
參考文獻:James G.,Written D.,Hastie T. and Tibshirani R.(2013). An intruduction to statistical learning with applications in R, Springer.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/295078.html
標籤:AI