深度學習—從入門到放棄(五)正則化
1.正則化引入
在說到正則化的概念之前,我們先來回想一下我們花費力氣建立神經網路的目的是什么?我們之所以建立模型,那么肯定是希望它能處理真實世界里的資料,換言之,也就是網路的泛化,那么為了達到良好的泛化效果,我們究竟要讓模型訓練時擬合效果達到哪種程度呢?
1.1 過擬合
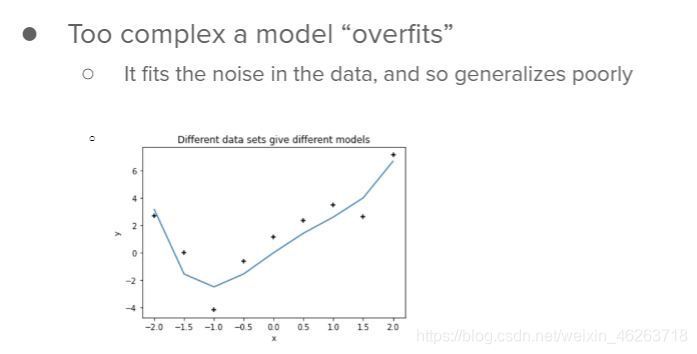
過擬合是一個普遍存在的問題,尤其是在神經網路領域,神經網路模型動輒都有上萬個引數,現代的深度網路引數則更是上百萬的引數,所以深度網路更容易出現過擬合現象,
-
存在過擬合現象的網路通常無法良好的泛化,這是因為它可能把資料噪聲也一并進行了擬合,
-
過擬合現象主要體現在accuracy rate和cost兩方面:
1.模型在測驗集上的準確率趨于飽和而訓練集上的cost仍處于下降趨勢
2.訓練集資料的cost趨于下降但測驗集資料的cost卻趨于飽和或上升
1.2 欠擬合
欠擬合則與過擬合正好相反,過于簡單的模型可能不足以概括模型的所有特征,
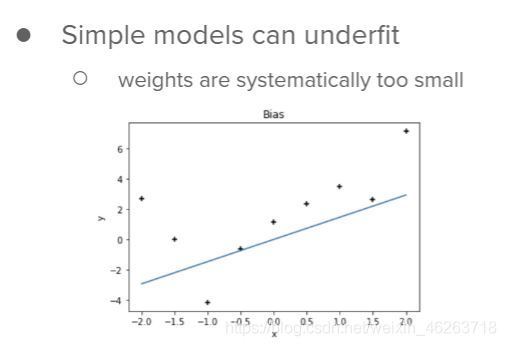
因此我們需要在盡量減少過擬合,欠擬合的可能性下選擇合適復雜度的模型,
- 過擬合會導致在不同資料集上擬合出完全不同的模型
- 欠擬合會導致在不同資料集上擬合出完全相同的模型
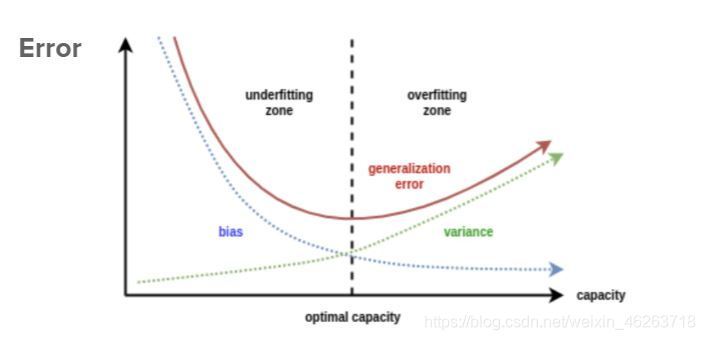
2.案例分析
在固定訓練集大小和固定模型復雜度的情況下解決過擬合問題就是今天正則化所要討論的內容,
理解正則化的一種方法是根據模型的整體權重的大小來考慮,具有大權重的模型可以完美地擬合更多資料,但有可能出現過擬合;而具有較小權重的模型往往在訓練集上表現不佳,但在測驗集上卻表現出色,可能出現欠擬合,
- 在這里我們使用Frobenius 范數來進行模型整體權重的度量,(m×n 的矩陣 A 元素的絕對平方和的平方根)
2.1 可視化過擬合
2.1.1 資料準備
set_seed(seed=SEED)
# creating train data
# input
X = torch.rand((10, 1))
# output
Y = 2*X + 2*torch.empty((X.shape[0], 1)).normal_(mean=0, std=1) # adding small error in the data
#visualizing trian data
plt.figure(figsize=(8, 6))
plt.scatter(X.numpy(),Y.numpy())
plt.xlabel('input (x)')
plt.ylabel('output(y)')
plt.title('toy dataset')
plt.show()
#creating test dataset
X_test = torch.linspace(0, 1, 40)
X_test = X_test.reshape((40, 1, 1))
2.1.2 構建網路
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
#構建了3個全連接層(下一講CNN中會詳細說到)
self.fc1 = nn.Linear(1, 300)
self.fc2 = nn.Linear(300, 500)
self.fc3 = nn.Linear(500, 1)
def forward(self, x):
x = F.leaky_relu(self.fc1(x))#激活函式為leaky relu
x = F.leaky_relu(self.fc2(x))
output = self.fc3(x)
return output
2.1.3 訓練網路
set_seed(seed=SEED)
# train the network on toy dataset
model = Net()
criterion = nn.MSELoss()#這里使用均方誤差作為目標函式
optimizer = optim.Adam(model.parameters(), lr=1e-4)#優化器選擇Adam
iters = 0
# Calculates frobenius before training
normi, wsi, label = calculate_frobenius_norm(model)
set_seed(seed=SEED)
# initializing variables
# losses
train_loss = []
test_loss = []
# model norm
model_norm = []
# Initializing variables to store weights
norm_per_layer = []
max_epochs = 10000 #訓練事件
running_predictions = np.empty((40, int(max_epochs / 500 + 1)))
for epoch in tqdm(range(max_epochs)):
# frobenius norm per epoch
norm, pl, layer_names = calculate_frobenius_norm(model)
# 訓練
model_norm.append(norm)
norm_per_layer.append(pl)
model.train()
# 針對目標函式的梯度下降
optimizer.zero_grad()#初始化
predictions = model(X)
loss = criterion(predictions, Y)#應用目標函式求loss
loss.backward()#反向傳播
optimizer.step()#梯度下降
train_loss.append(loss.data)
model.eval()
Y_test = model(X_test)
loss = criterion(Y_test, 2*X_test)
test_loss.append(loss.data)
if (epoch % 500 == 0 or epoch == max_epochs - 1):
running_predictions[:, iters] = Y_test[:, 0, 0].detach().numpy()
iters += 1
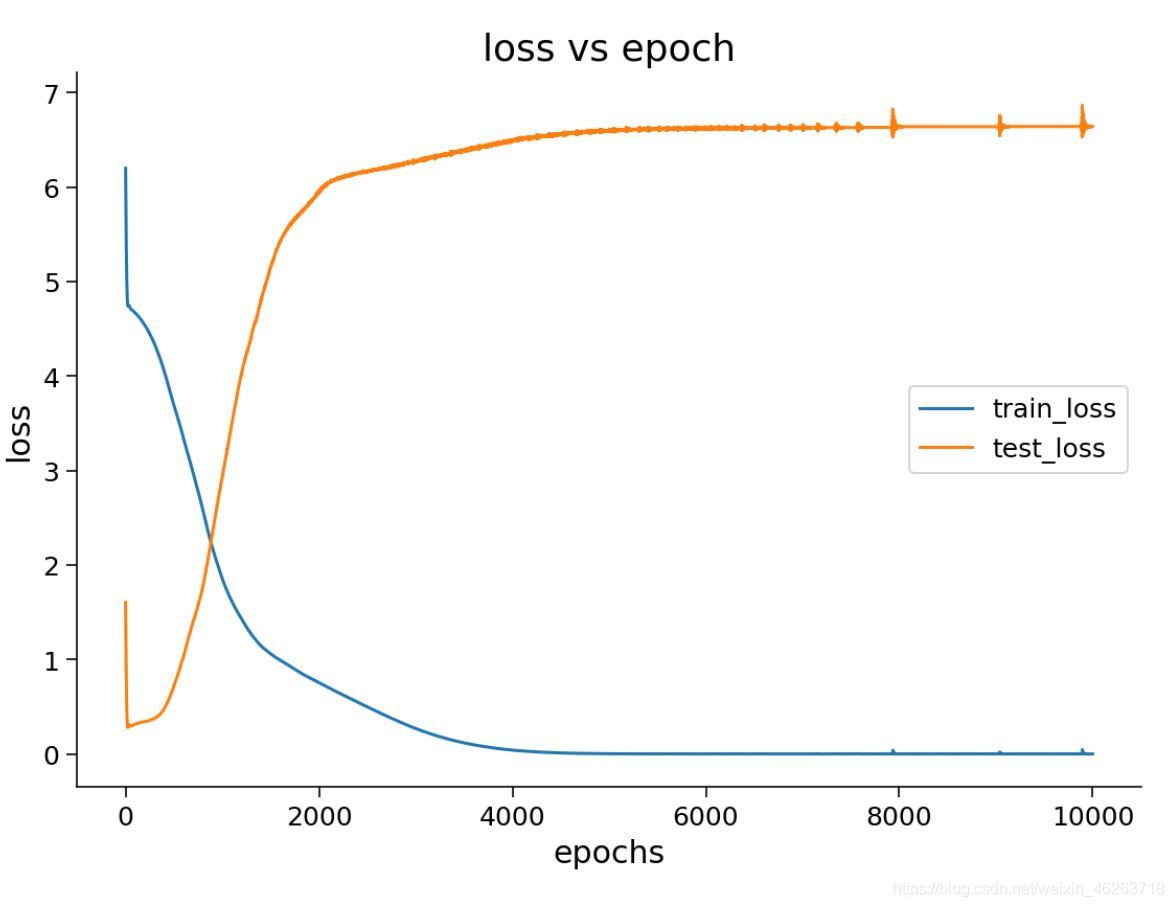
這里就可以看到我們的神經網路在訓練程序中呈現了一個較為明顯的過擬合趨勢(訓練集資料的loss趨于下降但測驗集資料的loss卻趨于上升),
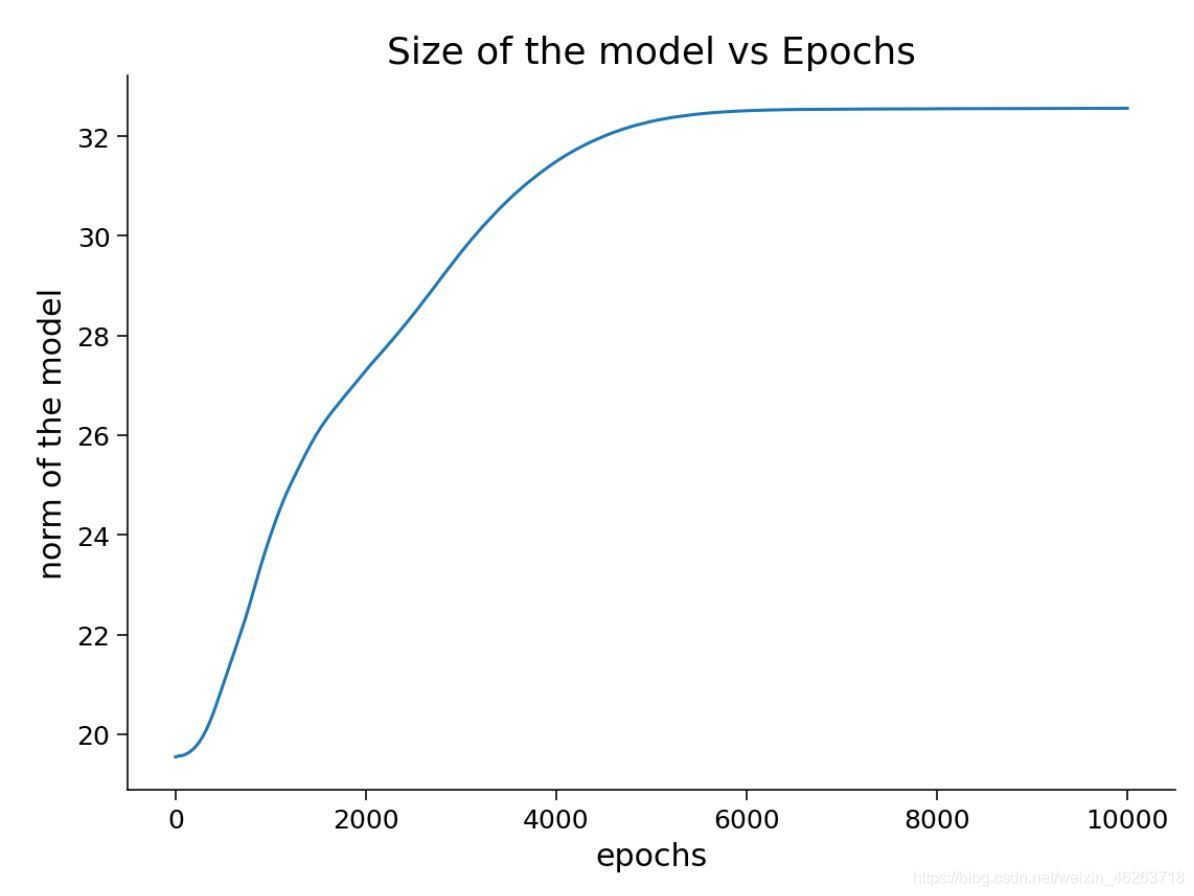
Frobenius 范數隨著訓練事件增加也趨于不斷上升,說明模型整體權重過大,那么我們該如何在訓練程序中得知目前的神經網路是處于哪種狀態呢?
答案就是在進行訓練集和測驗集劃分時增添一個驗證集!我們在每一epoch訓練之后計算驗證集的預測準確度,而驗證集準確度會在模型過度擬合之前達到峰值,因為一旦出現過擬合,模型的泛化能力就會大打折扣,相對的在訓練集外的資料集上模型的表現就會變差,
2.1 提前終止 early stopping
現在我們已經確定驗證準確度在模型過度擬合之前就達到了峰值,我們希望以某種方式提前停止訓練,換句話說當驗證準確率停止增加時,我們的模型就在當前epoch上停止了訓練,
以下是提前終止這一方法的代碼實作:
def early_stopping_main(args, model, train_loader, val_loader):
device = args['device']
model = model.to(device)
optimizer = optim.SGD(model.parameters(),
lr=args['lr'],
momentum=args['momentum'])#這里使用隨機梯度下降里的momentum方法
best_acc = 0.0#初始化測驗集準確度峰值對應epoch
best_epoch = 0#初始化停止epoch
# 在提前終止后還需訓練的epoch數量
patience = 20
# 等到val_acc < best_acc時的epoch
wait = 0
val_acc_list, train_acc_list = [], []
for epoch in tqdm(range(args['epochs'])):
# 訓練模型
trained_model = train(args, model, train_loader, optimizer)
# 計算測驗集準確度
train_acc = test(trained_model, train_loader, device=device)
# 計算驗證集準確度
val_acc = test(trained_model, val_loader, device=device)
if (val_acc > best_acc):#驗證集準確度持續增加時(模型還未過擬合)
best_acc = val_acc
best_epoch = epoch
best_model = copy.deepcopy(trained_model)
wait = 0
else:#模型過擬合時
wait += 1
if (wait > patience):
print(f'early stopped on epoch: {epoch}')
break
train_acc_list.append(train_acc)
val_acc_list.append(val_acc)
return val_acc_list, train_acc_list, best_model, best_epoch
# 設定引數
args = {
'epochs': 200,
'lr': 5e-4,
'momentum': 0.99,
'device': DEVICE
}
# 初始化模型
set_seed(seed=SEED)
model = AnimalNet()
val_acc_earlystop, train_acc_earlystop, best_model, best_epoch = early_stopping_main(args, model, train_loader, val_loader)
print(f'Maximum Validation Accuracy is reached at epoch: {best_epoch:2d}')
with plt.xkcd():
early_stop_plot(train_acc_earlystop, val_acc_earlystop, best_epoch)
這里實作了在驗證準確率停止增加后的20個epochs時模型停止訓練的目標,這里設定patience = 20是因為我們無法確定驗證集準確度的變化曲線是一個凸函式,它仍然存在有區域最大值的可能性,所以我們為了減小這種可能性的發生將提前終止延遲到了20個val_acc < best_acc的epoch之后,
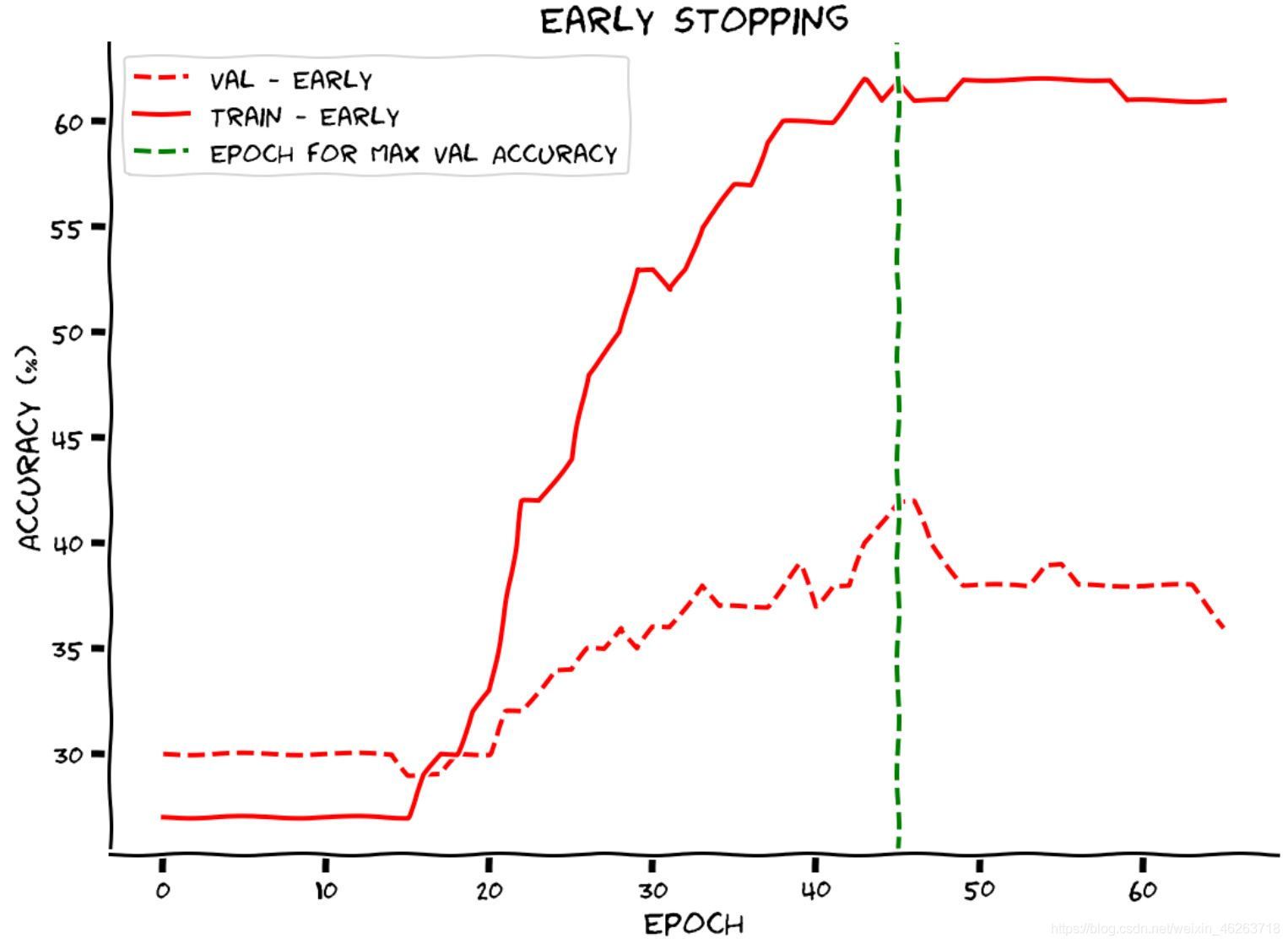
從這里不難發現我們目前想到的解決辦法還是有所欠缺,那么該如何從根本,也就是縮小權值這個角度入手解決過擬合的問題呢?答案就是正則化!
3.L1正則
正則化的一般方法為:在cost function里添加一個懲罰項(penalty)來進行更新,從而使模型整體權重更小,提供更簡單的模型,不會過度擬合,
而我們這里提到的L1正則的懲罰項則是深度學習網路中所有權重的絕對值之和,形成以下損失函式:L通常指交叉熵損失,
λ
\lambda
λ為懲罰項超引數
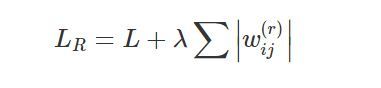
我們都知道在神經網路里我們需要對損失函式進行梯度下降從而找到最佳引數,所以為了更好的了解L1正則是如何縮小權重的,我們來看一下梯度下降后的權值更新規則:
對上面的等式取導數,我們得到:
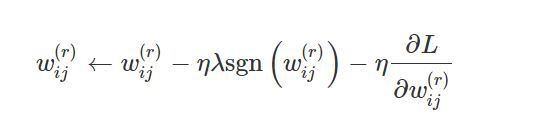
在這里sgn就相當于求絕對值,從這個梯度下降后的權值更新規則中我們可以看出L1正則化卻是使權值通過減去一個常數,因此權重是有可能被削減為0的,也就達到了降低模型復雜度的目的,
- L1正則的懲罰項是深度學習網路中所有權重的絕對值之和
- L1正則可能會讓某些權重歸零
def l1_reg(model):
"""
Inputs: Pytorch model
This function calculates the l1 norm of the all the tensors in the model
"""
l1 = 0.0
for param in model.parameters():
l1 += torch.sum(torch.abs(param))
return l1
# Set the arguments
args1 = {
'test_batch_size': 1000,
'epochs': 150,
'lr': 5e-3,
'momentum': 0.99,
'device': DEVICE,
'lambda1': 0.001 # penalty超引數lambda
}
# intialize the model
set_seed(seed=SEED)
model = AnimalNet()
# Train the model
val_acc_l1reg, train_acc_l1reg, param_norm_l1reg, _ = main(args1,
model,
reg_train_loader,
reg_val_loader,
img_test_dataset,
reg_function1=l1_reg)
4.L2正則
L1正則和L2正則的不同點就在于它們的懲罰項和壓縮權重的方式不同,L2正則的懲罰項是深度學習網路中所有權重的平方和, L2正則也稱權值衰減,
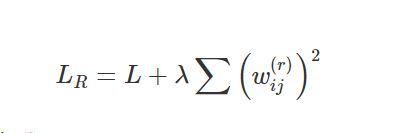
同樣我們來看一下梯度下降后的權值更新規則:
對上面的等式取導數,我們得到:
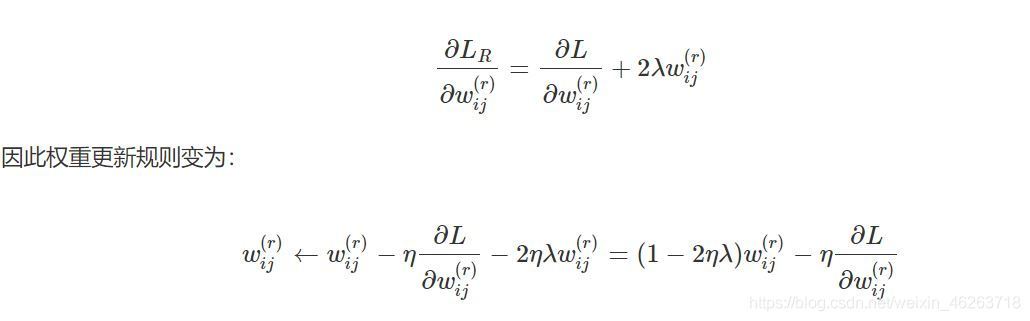
從這個梯度下降后的權重更新規則中我們可以看出L2正則化使權值乘上一個系數,換句話說也就是給權值打(1-2
η
λ
\eta\lambda
ηλ)折,從而壓縮權值,達到減小模型復雜度的目的,并且這種削減對于原本就比較大的權值作用會更加明顯(權值越大打折后變越小),
- L2正則的懲罰項是深度學習網路中所有權重的平方和
- L2正則可以較為明顯的削減那些很大的權值
def l2_reg(model):
"""
Inputs: Pytorch model
This function calculates the l2 norm of the all the tensors in the model
"""
l2 = 0.0
for param in model.parameters():
l2 += torch.sum(torch.abs(param)**2)
return l2
# Set the arguments
args2 = {
'test_batch_size': 1000,
'epochs': 150,
'lr': 5e-3,
'momentum': 0.99,
'device': DEVICE,
'lambda2': 0.001 #penalty超引數lambda
}
# intialize the model
set_seed(seed=SEED)
model = AnimalNet()
# Train the model
val_acc_l2reg, train_acc_l2reg, param_norm_l2reg, model = main(args2,
model,
train_loader,
val_loader,
img_test_dataset,
reg_function2=l2_reg)
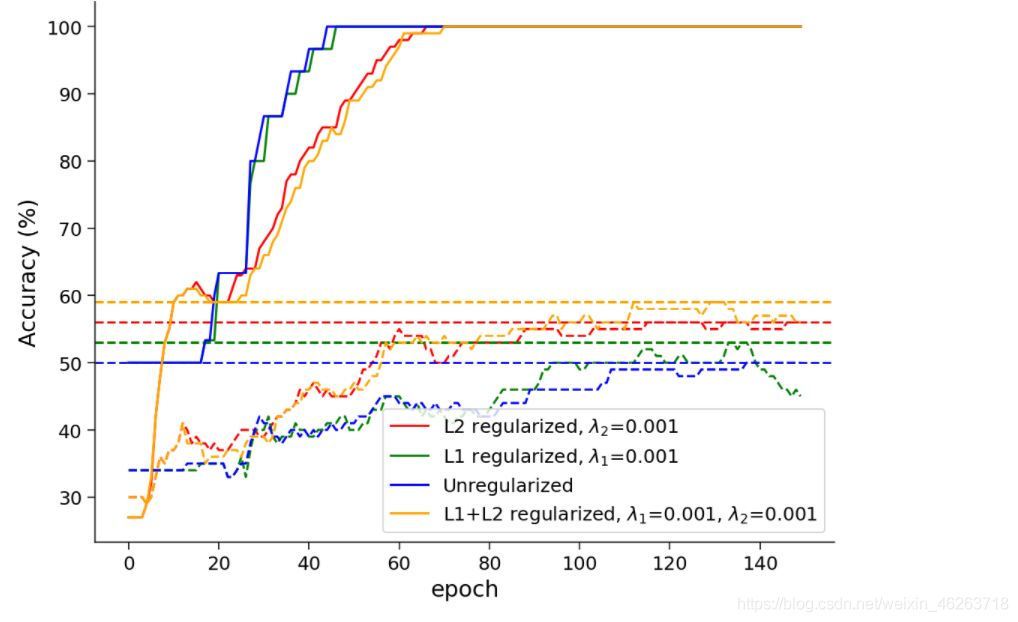
在這里我們可以發現在進行L1、L2、L1+L2正則化后模型在測驗集上的準確度逐漸升高,說明正則化確實提高了模型的泛化水平!
5.Drop out
Dropout相對于L1,L2而言,則是一種更為暴力的正則化方法,L1,L2根本方式都是在損失函式上增加一個懲罰項,使得模型在訓練的程序中對高模型復雜度也進行懲罰,但Dropout是不通過損失而直接對網路本身進行修改,
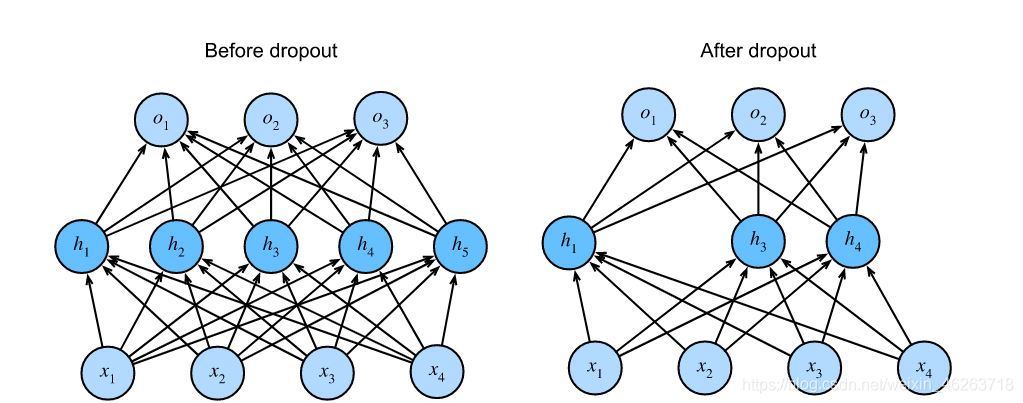
在 dropout 中,我們實際上在訓練期間丟棄(歸零)一些神經元,在整個訓練程序中,在每次迭代中,標準 dropout 在計算后續層之前將每層中節點的一部分(通常為 p=1/2)歸零,隨機選擇不同的子集進行 dropout 會在程序中引入噪聲并減少過擬合,
以下是應用dropout時對模型進行的更改:
# Network Class - 2D
class NetDropout(nn.Module):
def __init__(self):
super(NetDropout, self).__init__()
self.fc1 = nn.Linear(1, 300)
self.fc2 = nn.Linear(300, 500)
self.fc3 = nn.Linear(500, 1)
# 增加了兩個drop out層
self.dropout1 = nn.Dropout(0.4)#drop out 概率p=0.4
self.dropout2 = nn.Dropout(0.2)#p=0.2
def forward(self, x):
x = F.leaky_relu(self.dropout1(self.fc1(x)))
x = F.leaky_relu(self.dropout2(self.fc2(x)))
output = self.fc3(x)
return output
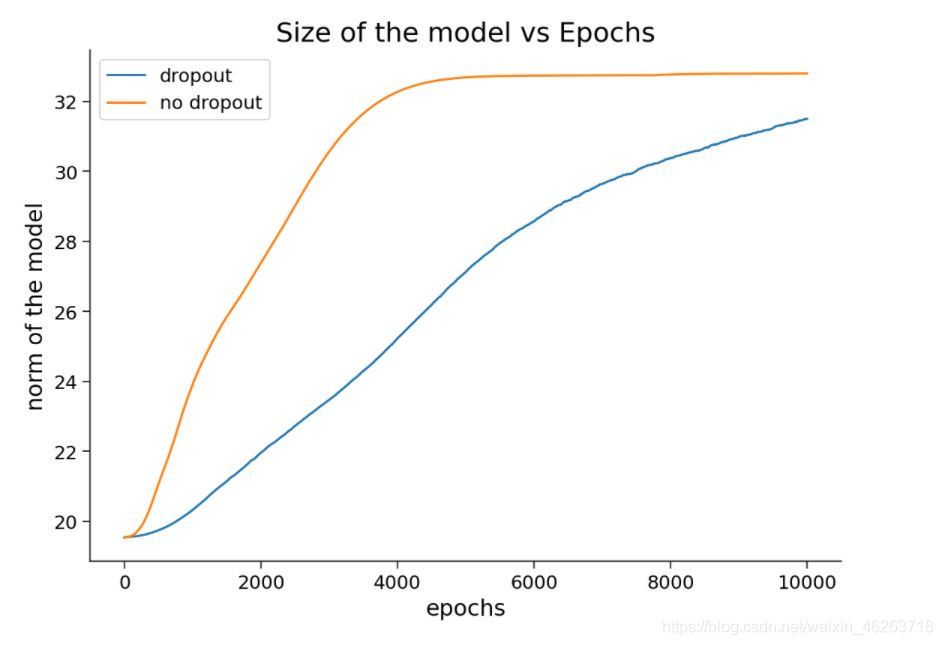
從上圖我們可以看出drop out確實在一定程度上壓縮了權值,那么該如何理解drop out是怎樣發揮這種作用的呢?
- 在優化器這一章中有提到小批次梯度下降的概念,而當我們隨機選擇不同子集進行 dropout時,也就是在不同的小批次里以概率p隨機丟棄(歸零)一些神經元,這樣做不僅會在訓練程序中引入噪聲,減小過擬合的可能性;同時我們可以把每一個小批次里的神經網路看成獨立的新網路——因為不同網路可能會有不同的過擬合問題,但把它們綜合到一起考慮,這種問題可能會被榷訓甚至消除,
有關正則化的其他講解
6.資料增強
資料增強通常用于增加訓練樣本的數量,現在我們將探討資料增強對正則化的影響,這里的正則化是通過在每個 epoch 之后向訓練資料中添加噪聲來實作的,
- Pytorch 的 torchvision 模塊提供了一些內置的資料增強技術,我們可以在影像資料集上使用這些技術,我們最常使用的一些技術是:隨機裁剪、隨機旋轉、垂直翻轉、水平翻轉
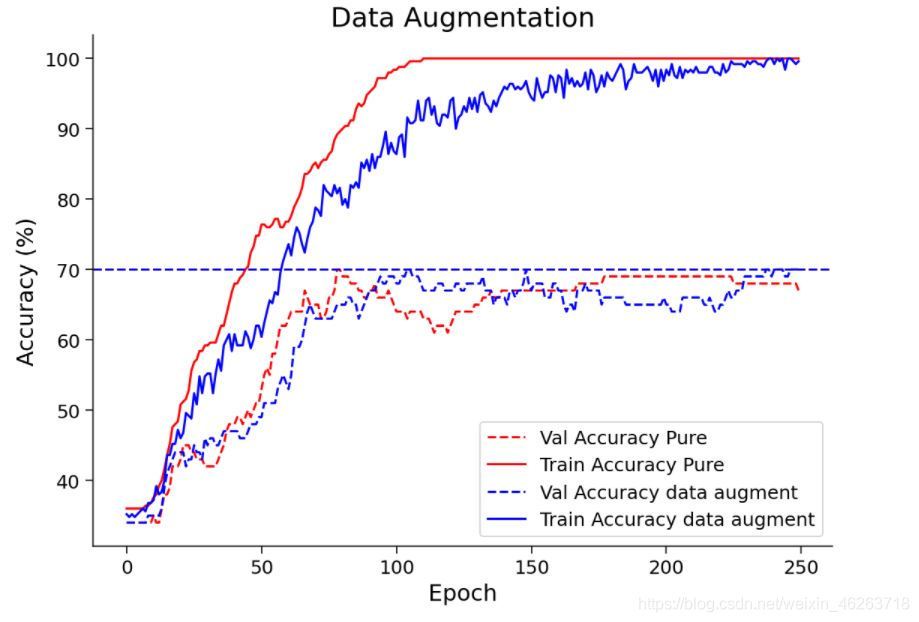
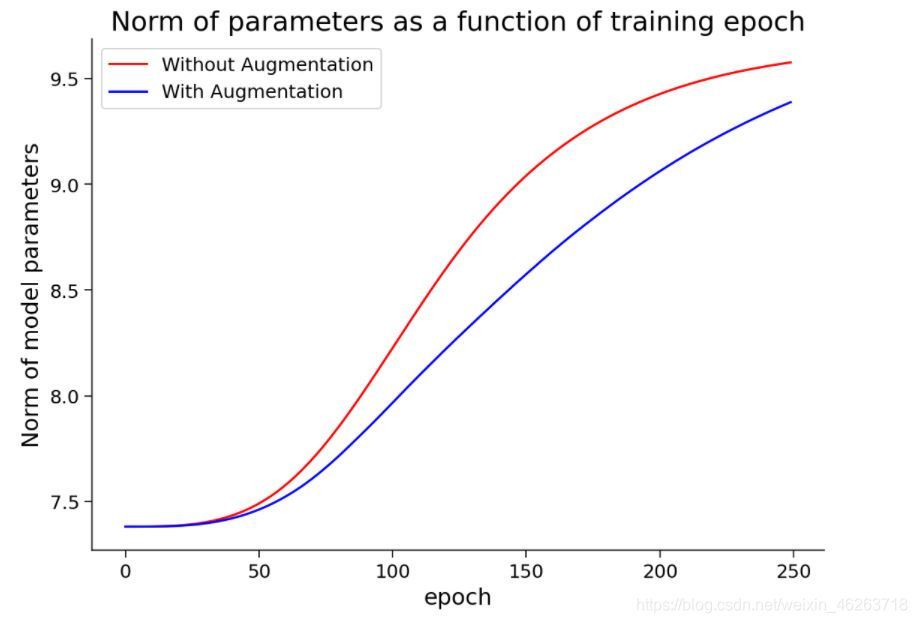
從上圖我們可以發現在進行資料增強后模型準確度也大幅上升,不僅如此,模型整體權值也得到縮減,
7.隨機梯度下降SGD
說到梯度下降,那么最重要的一個超引數就是學習率,在本節中,我們將看到學習率如何在訓練神經網路時充當正則化器,
- 學習率越小,正則化越少,相應目標函式的收斂也會很慢,無法起到對權值的調整
- 較大的學習率通過跳過區域最小值并收斂到更優的最小值(可能是全域最小值)來進行正則化,這通常可以更好地泛化,但是請注意參考之前所講的過大的學習率帶來的影響,
8.超引數微調

歡迎大家關注公眾號奇趣多多一起交流!同時也希望大家能夠多多點贊評論支持!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/295079.html
標籤:AI