《Deep Learning for ECG Segmentation》《利用深度學習對ecg信號進行分割》
- 講在前面
- 摘要
- 1.介紹
- 2.準備作業
- 2.1 符號
- 2.2 問題公式
- 2.3 便攜式設備
- 2.4 資料庫
- 2.5 性能評估演算法
- 3.資料預處理
- 3.1 噪聲移除
- 3.2 資料集失衡
- 3.3 標準化和其他問題
- 4.特征集合
- 4.1 特征提取
- 4.1.1 洛倫茲散點圖
- 4.1.2 龐加萊散點圖
- 4.1.3 其他HRV特征
- 4.2 特征選擇
- 4.3 特征提取技術
- 5 AF檢測的機器學習方法
- 5.1 支持向量機
- 5.2 決策樹
- 6 AF檢測的深度學習
- 6.1 CNN
- 6.2 RNN
- 7 討論和公開問題
- 8 總結
- CRediT 作者貢獻宣告
- 競爭利益宣告
- 我的觀點
- 1.演算法補充:
- 1.1 [MINA](https://github.com/hsd1503/MINA)
- 1.2 [cinc17-paper](https://physionet.org/files/challenge-2017/1.0.0/papers/index.html)
- 1.3 [大佬github](https://github.com/hsd1503?tab=repositories)
講在前面
- 一.筆者最近來搞心電信號了,當前演算法框架就參考的這篇論文,來鉆研一下這篇論文,說真的,搞ecg的人真的太少了;
- 二.我設計了幾種字體顏色用于更加醒目地表現關鍵的思想和主題:
- 紅色表示尚未理解透徹的一些概念
- 藍色表示對原來的理解做的一些修改或補充
- 綠色表示此處需要參考的論文其他部分
- 橙色表示本文的重要關鍵字
- 紫色表示后續更新的內容
我會用洗掉線將自己曾經不到位的理解進行洗掉
摘要
最近醫療物聯網的進步使得連續的心率監測成為了一種時尚,ECG的單導聯信號通過可穿戴服飾進行收集,同時通過一些智能的方法對心率進行自動識別,單導聯的信號和其他一般的ECG信號不同,因為它具有很高的噪聲、干擾,同時確實其他導聯通道的資訊,最近幾年提出了很多通過單導聯信號進行識別的演算法,這篇論文系統的調查了從單導聯ECG信號中反映房顫的SOTA級別的方法,展示了一些相關問題的資料庫和性能演算法,收集了資料預處理和特征提取的方法,同時對相關機器學習和深度學習方法進行了整理和摘要,特別要說的是,我們重新回顧了資料預處理的技術,并且羅列了最通用且高效的特征,這些都可以幫助開發者去進一步實作AF監測演算法,最后,我們討論了一些在AF識別上可能有用的想法,
1.介紹
CVDs指的是一些與心臟和血管相關的疾病,包括冠狀動脈疾病、心臟衰竭、中風、心律失常和心肌病,根據WHO的資料,全世界每年有1790萬人死于心血管疾病,尤其是美國,2016年84萬人死于心血管疾病,而歐洲2017年則有390萬人死于心血管疾病,而歐盟則有超過180萬人,比例達到了45%和37%,臨床病例證明了心律例外是最常見的心臟疾病,常見的心律例外包括室性早搏、房性早搏、房顫(AF),其中,房顫最容易導致死亡,因為它與心臟病風險的增加是相關的,比如中風、心臟衰竭和冠狀動脈血管疾病,從某方面講,AF可以被認為是死亡和疾病發生的間接原因,之前的研究表明AF患病幾率會隨著年齡的增加而增加,85歲及以后的患病概率可增加至15%,所以,AF的早期檢測篩查對于心臟病的防御和治療是非常重要的,可以進一步減小心血管疾病的死亡率,
在AF檢測領域,ECG是最常用的診斷工具,廣泛使用的ECG設備包含了10個電極,其中6個被放置在胸部上(從V1到V6),而其他的電極會放在腿上和胳膊上,如圖一所示:
圖一:
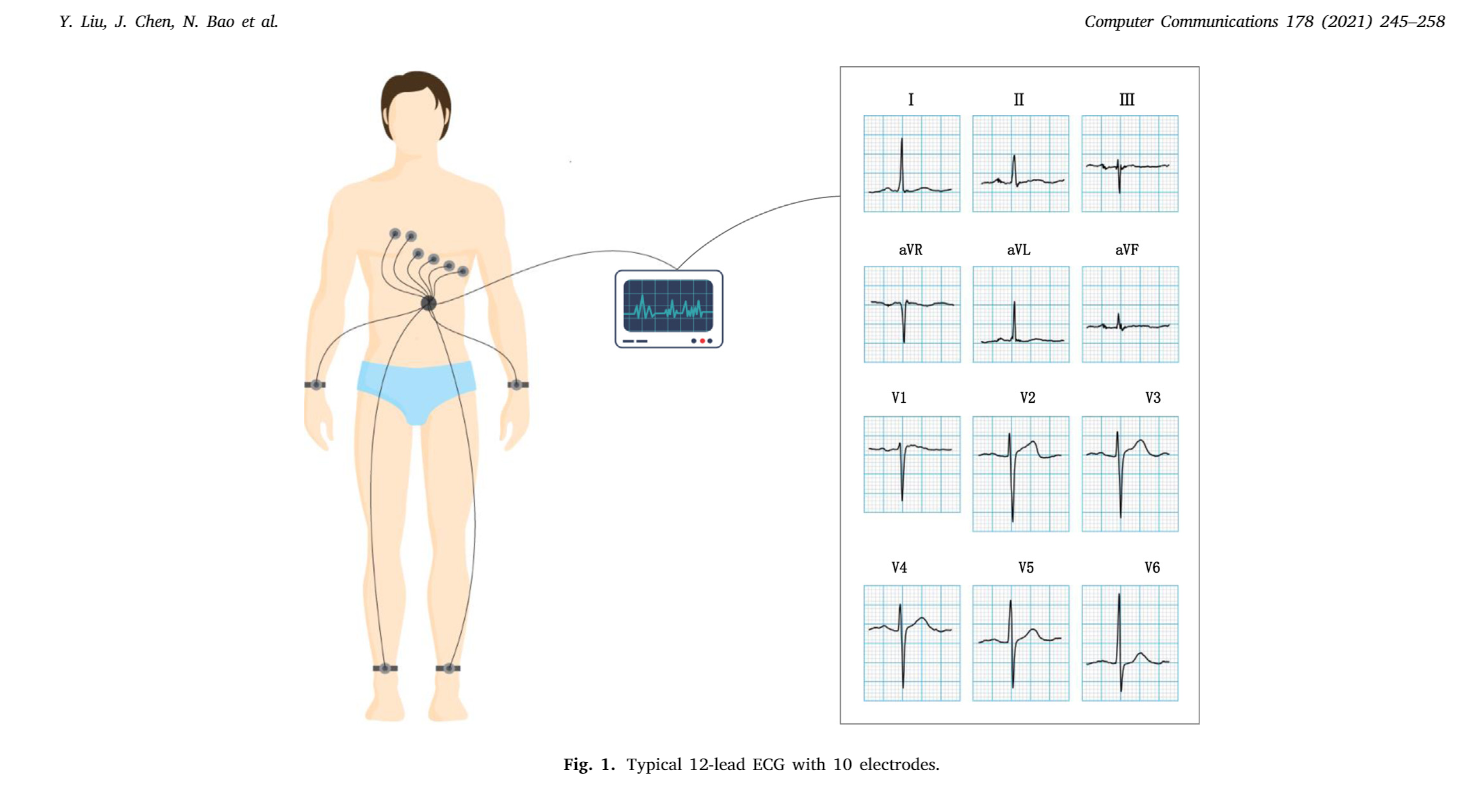
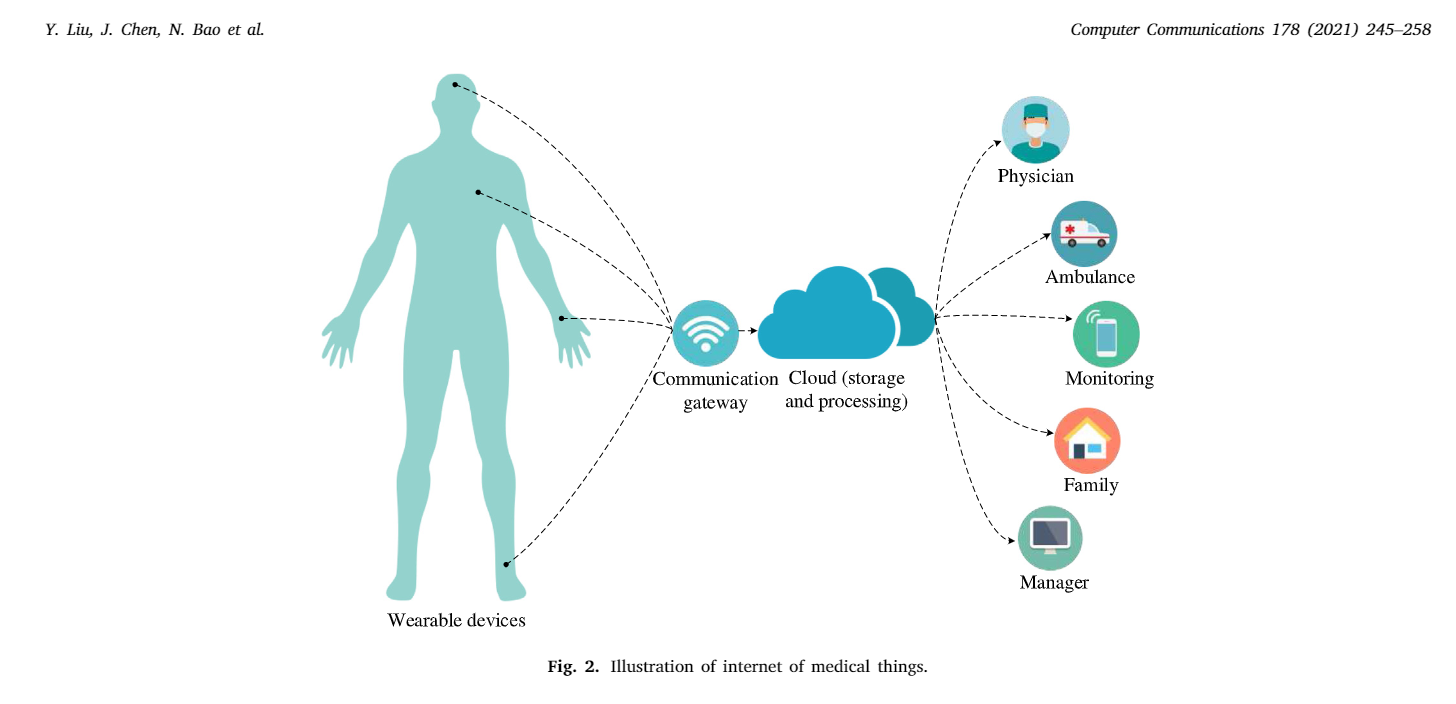
因為需要電極對來構建波形,12導聯的ECG因此被生產出來,特別的是,導聯I、II、III和aVR、aVL、aVF是從位于胳膊和腿上的四個電極產生的,而另外六個則由胸部電極產生,在過去的一個世紀,這種導聯信號在診斷AF上是一種重要工具,但是,很多AF病人通常是無癥狀的或者是僅有些非典型癥狀,這些都增加了AF檢測的復雜度,因為房顫發作的一些屬性,AF的檢測要求使用一些設備進行長期的ECG跟蹤,但是要把12導聯的ECG設備或者可植入的設備穿戴變成一種時尚是不可能的,而且可植入設備的造價昂貴,得益于一些信號收集和資料挖掘技術,利用可穿戴設備進行舒適的ECG信號收集成為了一種備選方案,使用手指的多個點來創建單導聯軌道,可插入的設備就可以收集到單導聯ECG信號,然后通過網路進行傳輸,從而進行監測和分析,而現實環境中,醫療物聯網就是一個將可插入設備、云端、客戶端通過安全網路進行整合的有效工具,同時促進了安全的生理資料的收集,如圖二所示:
圖二:
最近幾年,通過單導聯信號推理是否有患房顫是一個火熱的主題,多數人都相信它可以在未來為人提供智能健康服務,但是將12導聯的AF檢測演算法用于單導聯上,還缺乏實作,考慮到這個問題,CINC2017提出了從單一的簡短的ECG單導聯信號(30-60s)中檢測AF的競賽,這個競賽已經提出了很多演算法,也鼓勵更多的人參與,
通常,基于特征提取的例外分類演算法包括四個步驟,分別為:資料預處理、特征提取、特征選擇和分類,值得注意的是特征提取和特征選擇能夠被保存進深度學習演算法,整個檢測的步驟影像化表示在圖三中:
圖三:
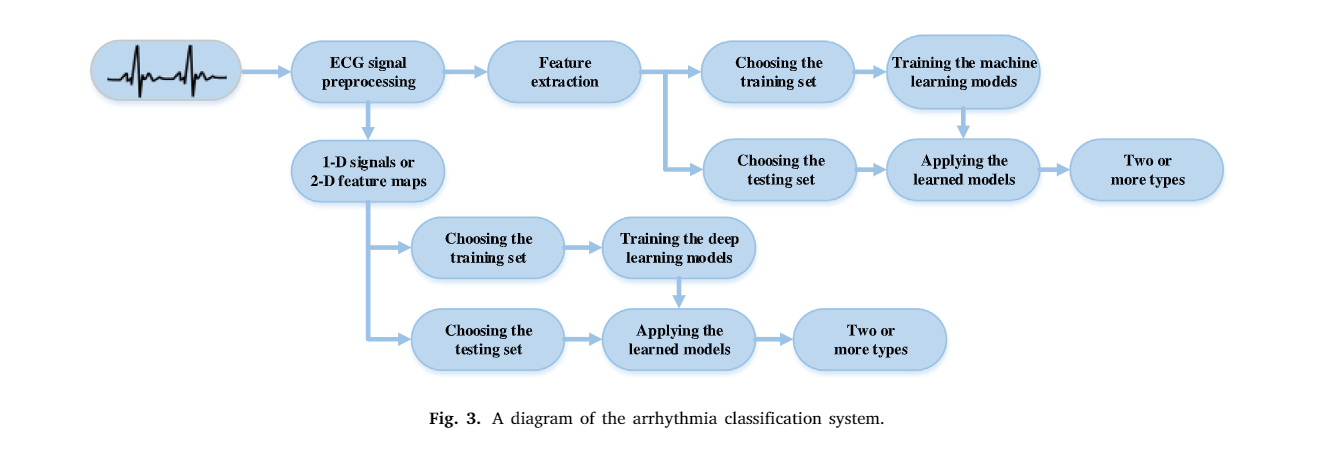
資料預處理是第一步,目的是去除噪聲,同時為特征提取提供一個干凈的信號,然后,特征提取技識訓將信號轉換為特征向量,一些特征就會用于進一步分類,在這篇論文中,我們給出了當前AF單導聯檢測的SOTA級別方法的調查結果和一些影響模型最終結果的兩點,為了更加綜合的進行調查,我們通過下面一些關鍵詞進行了搜索:“‘single-lead ECG”、“‘‘atrial fibrillation”、“‘machine learning”、“‘deep learning”、“‘‘survey”、“review”,然后再通過不用關鍵詞,根據內容摘要篩選,我們共搜索到了100篇相關論文,
這些論文的貢獻摘要如下:
- (1) 資料的預處理方法很全面,可以給進行ECG單導聯信號處理的研究人員一些指引;
- (2) AF領域最常用最有效的特征提取演算法被列了出來,這樣能很好的增強模型的精度;
- (3) 提出了一些可能改善模型精度的潛在想法,
除此之外,這片論文其他的部分的內容安排如下:
- Section 2 介紹了本文的預備知識,包括所討論的 AF 檢測問題的公式、資料庫和性能指標;
- Section 3 回顧了一些資料預處理的技術;
- Section 5 是相關機器學習技術;
- Section 6 是相關深度學習技術;
2.準備作業
2.1 符號
2.2 問題公式
一般情況下,竇房結會導致心房和心室的壓縮,這些收縮在心電圖上的表示就是PQRST的波峰,如圖四:
圖四:
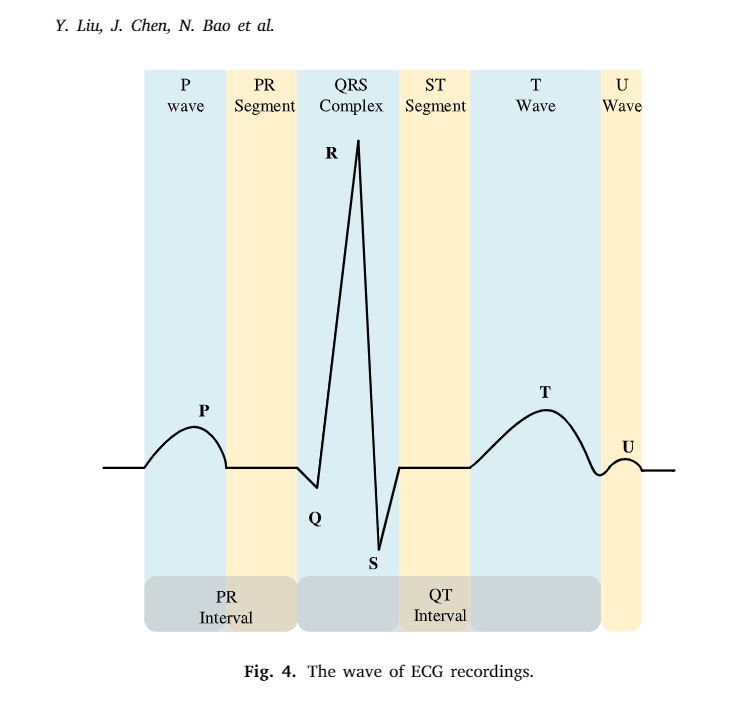
但是在AF中,有很多看起來很像心臟在顫動的收縮,AF會增加中風、心衰、冠狀動脈疾病、全身性血栓等,同時會帶來死亡率和患病率的劇增,因此,早期識別房顫對心血管疾病的治療起著至關重要的作用,尤其是,每種心率例外都有自己的ECG信號特征,比如,房顫信號的表現為RR間隙不規則,而且p波消失,就像是在鋸齒中隱藏了一個p波,就像圖五中顯示的一樣:
圖五:
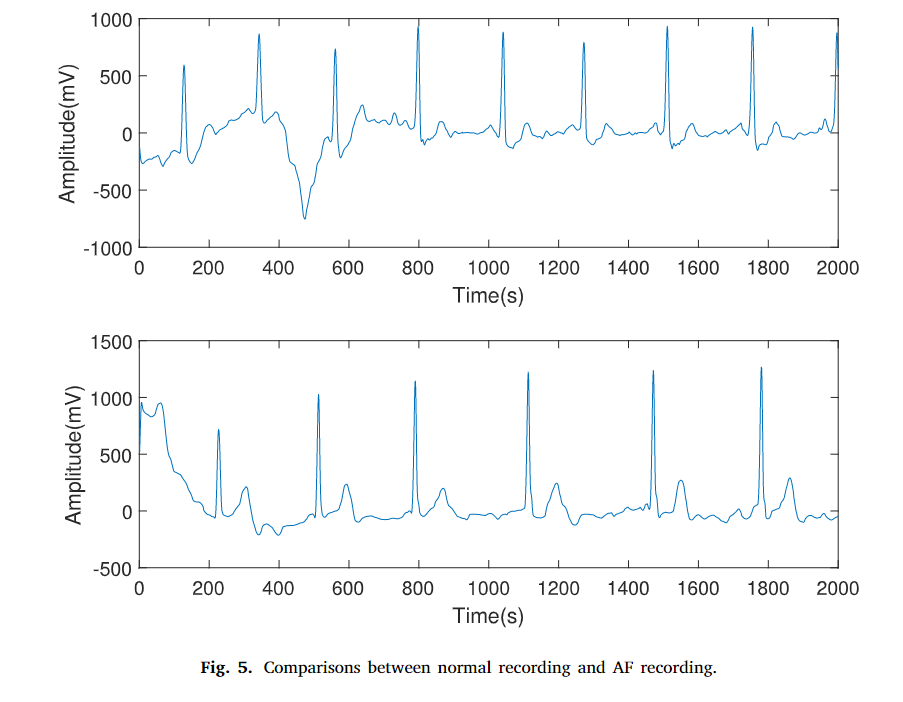
受益于可穿戴設備的快速發展,單導聯信號能被連續收集,同時又不至于太麻煩,蘋果手表等產品是典型代表,怎么去發掘這些信號中存在的潛在的影響健康的資訊,吸引了全世界范圍內人員的注意,單導聯AF檢測也成為了一種火熱的主題,但是單導聯信號通常會有很高噪聲、干擾、基線漂移,傳統的12導聯的演算法不能直接應用在單導聯上面,
2.3 便攜式設備
Alivecor kardia是一個能夠將智能手機收集到的醫學信號轉換成ECG信號,然后顯示波形圖的設備,它可以使用一種叫做FDA-clear的機器學習演算法,獲取30s醫療級別的ECG信號,然后進行分析和分享,你僅僅需要將手指放在傳感器上,然后放在口袋里隨身帶著它,
Omron是一款便攜的、袖珍的、無繩的可以檢測類似于AF等例外的設備,它能夠感知心律波形,同時生成一個30s的記錄,無論是在手術室還是在家里,都可以通過這種方法分析潛在的心律例外,在那之后,它能分析收集到的ECG信號,同時提供一個高質量的信號表現在螢屏上,
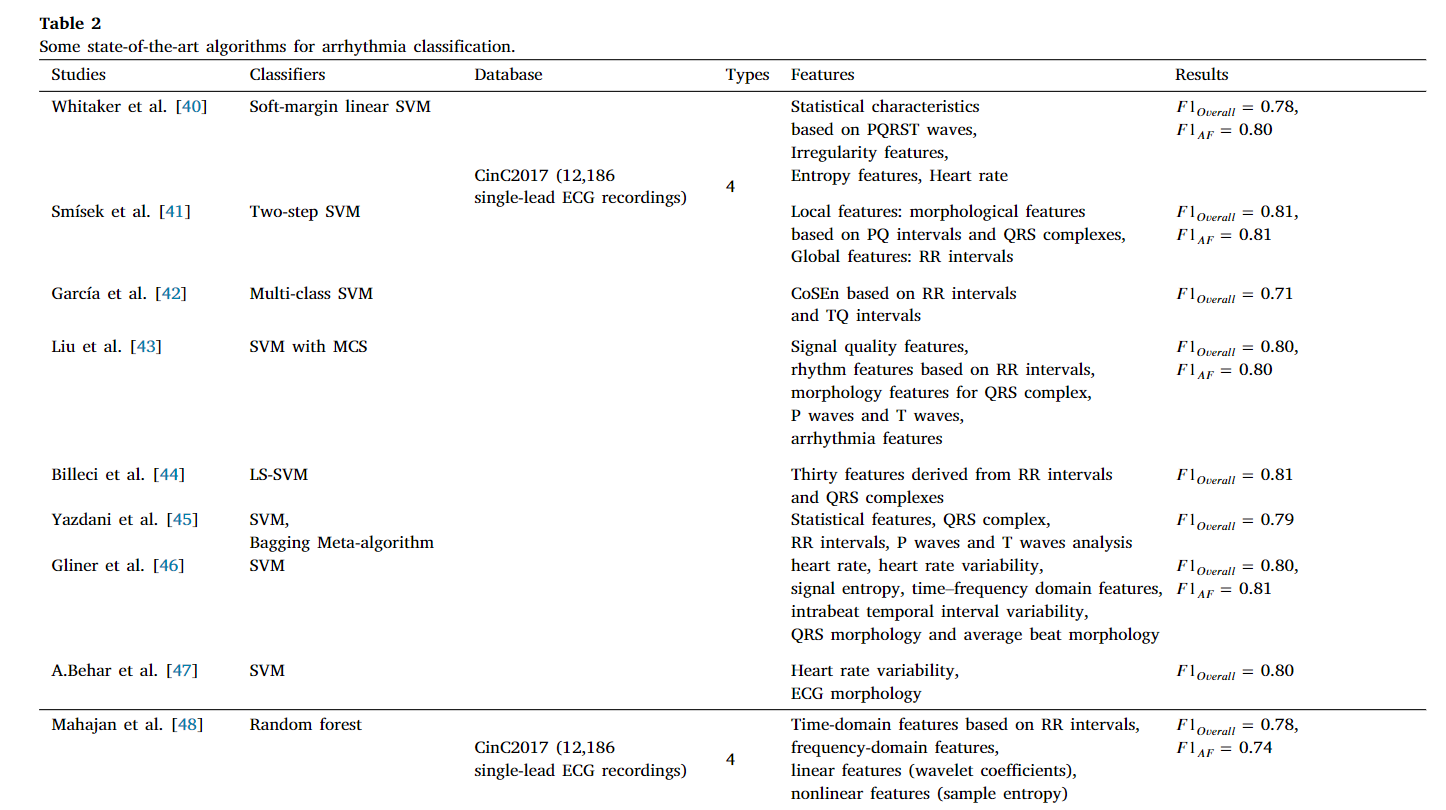
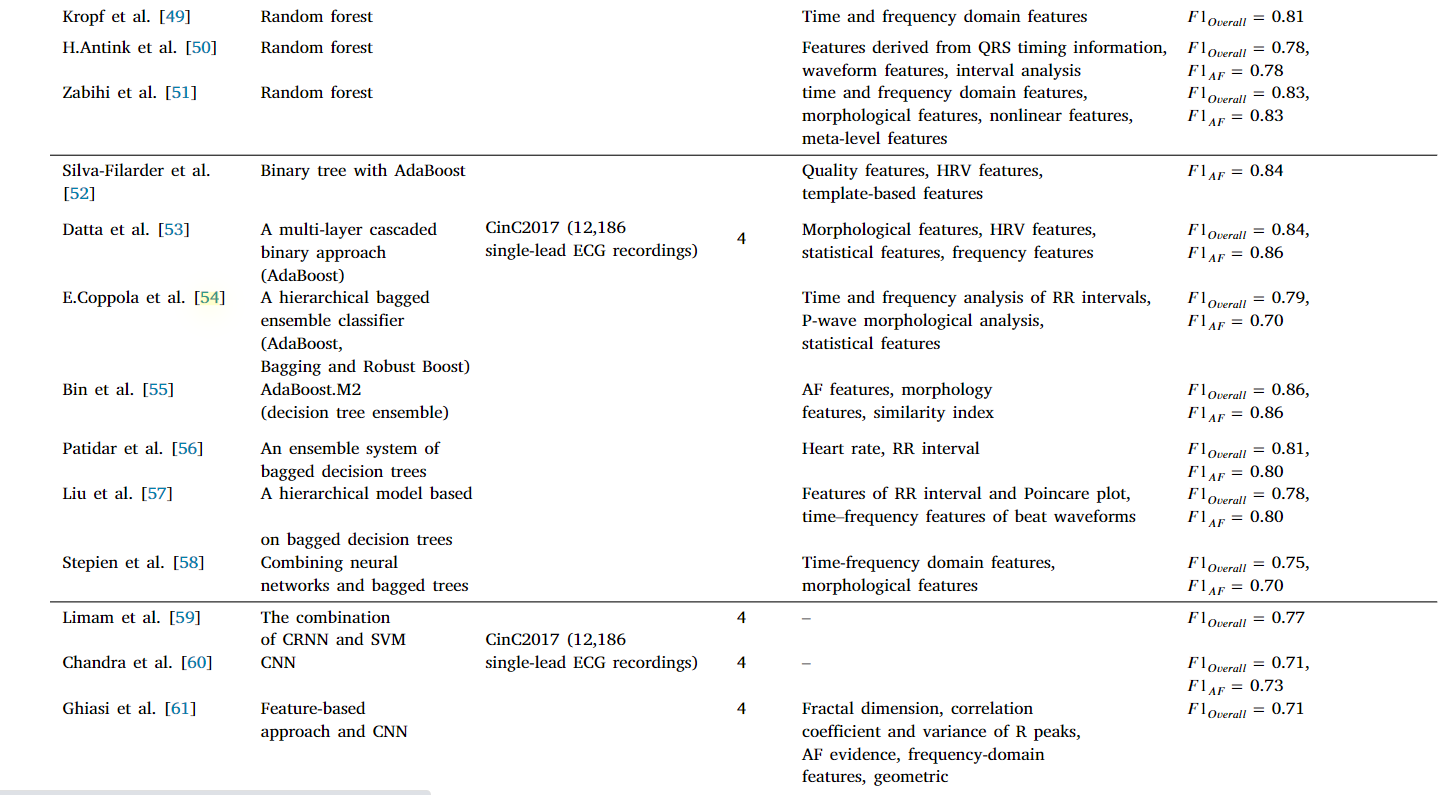
Zenicor ECG是一款完整、簡單的系統解決方案,它包含了兩個部分,手持ECG設備和網頁端設備,手持式心電圖設備可以長時間記錄心電圖資料,從而可以檢測到偶發性心律例外, 基于網路的服務用于存盤、處理和呈現接收到的 ECG 資料, 我們的目標是提供一個全面的AF檢測的演算法的調查,以及潛在的可能影響模型性能的演算法,我們把回顧的演算法簡潔的列入了表二中,我們會在接下來的部分進行分析,
表二:


2.4 資料庫
隨著AF單導聯檢測的流行,有些相關的資料庫已經開源,表三中做有統計,
表三:

CINC2017:包含有12186個單導聯ECG信號,每個信號持續時間為9s到60s,其中8528個信號用于訓練,3658個信號用于性能評估,所有的ECG信號的采樣頻率為300Hz,并且已經被 AliveCor device進行了帶通濾波,.hea包含了資訊,.mat包含了標簽和資料,這些ECG信號被專家分成了四種,分別為正常、房顫、噪聲和其他心律,
MITDB:這個資料集直到現在都用于進行演算法開發和評估心律例外檢測器,這個資料集包含了48個完全標注的二通道ECG信號,來自47個不同的病人,采樣頻率為360Hz,每種資料都是被兩個或者更多的醫生標注的,所有的心跳被分成多余10種心律例外,
EDB:通常被用于ST和T波的分析,它包含了90個2小時、采樣率為250Hz的二導聯的信號,同時,臨床的資訊保存在.hea檔案里面,每個信號被兩個醫生獨立標注,包含了ST分割和T波模態、心律、信號質量的改變,值得注意的是,這個資料集都被貢獻給了PhysioNet,
AHA:美國心臟協的資料集,它包含了兩組每個心跳都標注,每組154個的2通道ECG信號,第一組被用于心律例外檢測的研究,第二組被用于檢查演算法,所有的ECG信號采樣率都為250Hz,已經被分成了8種型別,另外,ECG信號的長度是3h,但是只有最后30分鐘進行了分類,
CCDD:是一些中國大學提出的,包括中科院、華東師大和廈門大學,它包含了179,130個帶有心臟疾病標注的信號,每個標注都有兩個醫生獨立標注,同時由第三方醫生進行確認,
2.5 性能評估演算法
通常有五個指標評估單導聯AF檢測器的性能:Acc、TNR、TPR、PPV和F1,所有的計算都基于TP、TN、FP和FN,另外,混淆矩陣會用于表示TP、TN、FP和FN的指標,而且,不同的論文專注于不同的指標,因為它們的目的、方向和應用都不同,例如,在專注于比較可穿戴設備篩選心臟病的能力的場景中,特異性和敏感性更重要,而F1值則由專注于開發ECG分類演算法的研究選擇,
- 1.好的分類器有一個更高的準確率:

- 2.特異性,也稱為真陰性率,是被演算法正確識別為陰性的陰性預測的比率, 它被定義為:

- 3.敏感度,也稱為真陽性率或召回率,是在總體存在陽性的情況下被正確識別為陽性的陽性預測的比例:

- 4.精度是被正確識別為正的正預測與被識別為正的正預測的比率:

- 5.F1 值是靈敏度和精度的加權諧波平均值,可以通過以下等式獲得:

3.資料預處理
3.1 噪聲移除
與12導聯的ecg信號相比,單導聯ECG信號因為通常由便攜式設備收集,所有會有各種各樣的噪聲,比如肢體移動導致的基線漂移,據報道一個前置的降噪步驟會提升分類系統的精度,因此降噪是AF分類上的一個重要步驟,一些主要的降噪手段在表四中進行了列出:
表四:

CINC2017的資料由AliveCor進行收集,已經使用帶通濾波器提取了0.5Hz和40Hz之間的信號,因此,一些競賽的演算法不能應用在這個上面,但是【71】的研究確是在信號預處理上面加了一個偽影濾波,通過對這些方法進行綜合的考量,我們認為帶通濾波器是最簡單也最廣泛使用的技術,
盡管帶通濾波器是最流行的技術,但是每個論文中的截止頻率都會有不同,在【74】中,使用了兩個中值濾波來移除信號的基線漂移,在【60】中,先把信號重采樣到300Hz,然后連續使用兩個中值濾波器來抽取基線,隨后,使用減法來移除基線漂移,在【67,76】中,使用FIR濾波器來移除噪聲的偽影,截止頻率設定為3Hz和45Hz,而【75,77】的研究都使用了巴特沃茲濾波器來進行資料預處理,【75】中使用了1Hz到25Hz的3階巴特沃茲帶通濾波器來移除基線漂移和高頻噪聲,截止頻率的選擇基于交叉驗證,【77】使用10階帶通巴特沃茲濾波器(窄帶5-45Hz,寬帶1-100Hz),來移除噪聲偽影,【48】使用5Hz-26Hz的帶通濾波器來移除基線漂移和電源線影響,同時最大化QRS波的能量,所有的ECG信號都通過截止頻率在1Hz和50Hz之間的濾波器過濾,
另一方面,高通濾波、低通濾波、以及一些組合也都被用于移除噪聲和單導聯偽影,【42,61】使用低通和高通濾波,【42】中使用截止頻率為0.5Hz的IIR高通濾波器來移除基線漂移,另外使用截止頻率為50Hz的IIR低通濾波來移除高頻噪聲和電源線介面噪聲,【61】中使用巴特沃茲低通濾波和高通濾波來移除基線漂移,但是,【53】僅僅使用了截止頻率為0.5Hz的高通濾波來移除基線的移動,另外,【41】使用了小波維納濾波器和金字塔中值濾波器來移除噪聲和基線漂移,【78】使用使用移動的均值濾波來移除基線漂移,【57】也使用移動的均值濾波器來提取低頻噪聲和基線漂移,盡管如此,一些噪聲仍然存在于信號中,干擾了后續的分析, 因此,通過使用小波變換去噪并切斷噪聲過渡期,進一步降低了殘余噪聲,
除了移除噪聲,ECG質量評估也是在進行分類前的一個重要步驟,ECG質量評估是PhysioNet的一個競賽Computing in Cardiology Challenge 2011,出于這個目的,【43,61】都使用了信號質量評估來改善ECG信號的質量,【61】使用環形質量評估來移除被噪聲污染的每個心跳的信號,剩余的高質量信號用于進一步處理,同樣的,【43】把ECG分割10s的周期,然后對每個周期進行ECG質量評估,低質量的信號被丟棄,高質量的信號被用于特征提取,不同于之前這些方法,【79】的預處理階段包含了資料再標注和導聯反演,目的是移除ECG資料的質量,【51】使用稀疏導數分解和去噪演算法來提高心電圖信號的質量,
3.2 資料集失衡
訓練和測驗集的樣本平衡是機器學習的一個重要部分,人群中有患AF的概率大概為2%,而公開資料集的AF樣本也不平衡,CINC2017中的資料有738個AF信號記錄,而正常心律記錄是5050個,是AF信號記錄的6倍多,這樣的資料集肯定會影響分類模型的表現,
資料增強是一種廣泛使用的解決這個問題的方法【80】,在這一部分,我們會對一些重要的資料增強演算法進行摘要,【54】來使用合成少部分樣本的過采樣技術,來對少量資料的類別進行過采樣,【58,72,77,78】通過增加少樣本類別的樣本數目來改善分類器的表現,出于同樣的目的,【77】從其他資料集中選取了2000個10s的ECG信號,同時通過將現有的284個噪聲信號分割組合成新的2000個信號,來生成更多的噪聲信號記錄,【58】researchers decided to add some surrogate data to the noisy and atrial fibrillation recordings by taking parts of signals already available and choosing a representativegroup of about 2000 recordings.【78】通過從各種渠道收集資料集來增大訓練集和驗證集,【72】從其他資料集中抽取資料來增大資料集,每個訓練樣本對損失函式的貢獻隨著其類別在整個資料集中占比而降低,
3.3 標準化和其他問題
其他的資料預處理問題主要包含了標準化和離群值處理,【61】使用Z-score歸一化解決幅度縮放問題并消除偏移效應,而在【72】中,心電圖被歸一化為平均值為零和一個分割的標準偏差,【48,71】都使用了一種忽略掉離群值的方法,【71】通過 0.5 秒滑動視窗計算計算出的例外最大值和最小值來實作, 類似地,【48】中開發了一種排除例外尖峰的協議,
4.特征集合
4.1 特征提取
特征提取是識別領域一個非常重要的步驟,尤其是機器學習的信號分類領域,我們收集了一些對于ECG信號特征提取有用得方法,這些自動化的AF檢測器,一般都基于RR間隙和P波消失,但是,在多噪聲的信號中定位小的P波是一個困難的任務,因此,AF檢測領域并沒有廣泛應用P波消失這個特征,
一些通過RR間隙來檢測AF的方法被使用,這些特征提取器都表明了RR間隙的分布和變異性,或者心跳的例外,比如,心跳通過下面公式來計算:

f
s
f_s
fs?指的是信號的采樣頻率,
通常,資料的基本特征包括了最小值、最大值、均值、中值、標準差和歐幾里得歸一化,在【40,44,50,53,55,57,71,79,81】都基于RR間隙計算了這些基礎的資料特征值、RR 間隔一階差分或 RR 間隔的二階導數,【74】的研究包含了從每個HR信號中基于RR間隙的基礎資料特征,而【50】則計算龐加萊資料散點圖來反映RR間隙的分布,
HRV(心率變異率)被叫做ECG信號的動態信號,是AF最穩定的標志【81】,一般竇性心律和AF的HRV有很大不同,幸運的是,洛倫茲散點圖和龐加萊散點圖是表示HRV的兩個有用的工具,【83】發現龐加萊散點圖是從其他心律中將AF區分出來的最重要工具,而且【61】認為RR間隙的直方圖可以反映HRV的信號,另外,【76】包括了標準HRV的資料,比如最大值、最小值、中值、均值、標準差和pNNx,這里pNNx的定義是,pNNx 被定義為連續正常竇性 (NN) 間隔變化超過 x ms 時的平均每小時次數,是一種廣泛使用的心率變異性度量【53,71,79】,【84】 的研究檢查了一系列 HRV 統計資料,稱為 pNNx,
4.1.1 洛倫茲散點圖
首先我們要介紹一種度量例外的指標,叫做
δ
R
R
\delta{RR}
δRR間隙,定義為:
 編碼 RR 間期不相關性的 𝛿RR 間期的洛倫茲圖是 𝛿𝑅𝑅(𝑖 ? 1) 相對于 𝛿𝑅𝑅(𝑖) 的散點圖,2D直方圖是洛倫茲散點圖的數字化表達,RR 間隔序列將填充二維直方圖中的不同部分,然后計算2D直方圖不同柱的值,更多關于2D直方圖的資訊在【85】中,在一個類似的作業中,【71】通過使用RR間隙序列的二階導來計算洛倫茲散點圖特征,可以在【85】中找到對有關二維直方圖模式的資訊進行編碼的幾個度量,具體來說,分布的稀疏性是通過IrregularityEvidence來衡量的,簇中的密度由 DensityEvidence 測量,分布的方向由 AnisotropyEvidence 測量,補償性停頓由 PACEviden 測量(下面進行了定義),
編碼 RR 間期不相關性的 𝛿RR 間期的洛倫茲圖是 𝛿𝑅𝑅(𝑖 ? 1) 相對于 𝛿𝑅𝑅(𝑖) 的散點圖,2D直方圖是洛倫茲散點圖的數字化表達,RR 間隔序列將填充二維直方圖中的不同部分,然后計算2D直方圖不同柱的值,更多關于2D直方圖的資訊在【85】中,在一個類似的作業中,【71】通過使用RR間隙序列的二階導來計算洛倫茲散點圖特征,可以在【85】中找到對有關二維直方圖模式的資訊進行編碼的幾個度量,具體來說,分布的稀疏性是通過IrregularityEvidence來衡量的,簇中的密度由 DensityEvidence 測量,分布的方向由 AnisotropyEvidence 測量,補償性停頓由 PACEviden 測量(下面進行了定義),

其中 𝑃𝑜𝑖𝑛𝑡𝐶𝑜𝑢𝑛𝑡𝑛 表示分段 𝑛 中 bin 的次數,而 𝐵𝑖𝑛𝐶𝑜𝑢𝑛𝑛𝑢𝑛𝑛代表在分段,而 𝐵𝑖𝑛𝐶𝑜𝑢𝑛𝑡𝑛 代表段 𝑛 中至少填充一次的 bin 數量,
在【40,53】,𝐼𝑟𝑟𝑒𝑔𝑢𝑙𝑎𝑟𝑖𝑡𝑦𝐸𝑣𝑖𝑑𝑒𝑛𝑐𝑒,𝑃𝐴𝐶𝐸𝑣𝑖𝑑𝑒𝑛𝑐𝑒,𝐴𝐹𝐸𝑣𝑖𝑑𝑒𝑛𝑐𝑒【55】和𝑂𝑟𝑖𝑔𝑖𝑛𝑎𝑙𝐶𝑜𝑢𝑛𝑡基于RR間隔或R峰值在最終的特征集合進行考慮, 此外,幾個像𝐷𝑒𝑛𝑠𝑖𝑡𝑦𝐸𝑣𝑖𝑑𝑒𝑛𝑐𝑒,𝐴𝑛𝑖𝑠𝑜𝑡𝑟𝑜𝑝𝑦𝐸𝑣𝑖𝑑𝑒𝑛𝑐𝑒和𝑃𝑎𝑐𝑒𝐶𝑜𝑢𝑛𝑡這樣的度量基于RR IN- terval是在【53】考慮, 上述部分指標定義如下:


其中𝑂𝑟𝑖𝑔𝑖𝑛𝐶𝑜𝑢𝑛𝑡表示包含原點的bin的{δ𝑅𝑅(𝑖),δ𝑅𝑅(𝑖-1)}值和𝑅𝑒𝑔𝑢𝑙𝑎𝑟𝑖𝑡𝑦𝐸𝑣𝑖𝑑𝑒𝑛𝑐𝑒的bin數目,
4.1.2 龐加萊散點圖
龐加萊散點圖是分析每兩個連續RR間隙分布特征的有效工具,從影像中可以得到三個特征,他們分別是聚類類別的數目,節拍間隔的平均步進增量和對角線附近點的分散程度【83】,
4.1.3 其他HRV特征
delta RR間期分布差異曲線是從每個心跳的密度直方圖中得到的,它反映了deltaRR間隙分布的主要變化【86】,在【44,71】中使用了連續 RR 差異的均方根 (RMSSD) 來量化逐搏變異性,【87】中的計算方式為:
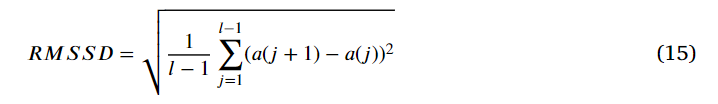
其中,𝑎(𝑖) 表示給定的 RR 間隔段,長度為 𝑙,
作為類似的情況,樣本熵系數(COSEn)【44】在從正常竇性心律中識別AF時具有很高的準確率【88】, 在 【40,42】 中,他們利用 COSEn 來計算 RR 間隔的變異性,
為了突破RR間隙特征的限制,考慮心跳波形圖的特征提取方法在許多演算法里被用到【50,51,55,57,61】,【50】的研究估計了對原始信號沒有峰值檢測的逐搏間隔,但利用了它的自相似性,心跳協方差矩陣的特征值在 【51】 中計算,【55】 的作者計算了 QRS 波群的相似指數、R 幅度的相似指數和高相似搏動的比率, 此外,表示信號自相似性的分形維數被納入【61】,
形態學特征也被使用,他們包括PR間隙、QT間隙、PQRST振幅【50,51,55,67,72,76】,ST振幅【55】、P波寬度【67】、T波寬度【67】、QRS寬度P-QRS-T的坡度和角度【51,53】,在【55,89】中獲得了信號質量指數來評估錄音的質量,為了分類噪聲的種類或者去除掉噪聲段,【43,52,79】考慮了幾個基于信號質量的噪聲特征,
4.2 特征選擇
通常,特征提取可以通過提供更具區分能力的特征,來改善信號分類的精度,同時減少特征的計算復雜度,【41,48】使用遺傳演算法選擇最成功的特征,來進行進一步的分類,在研究【53】中使用了包括最大資訊系數(MIC)和最小冗余最大相關性(mRMR)在內的特征選擇工具來選擇最相關的特征, 此外,分別在【71】]和【50】中執行了向后消除方法和遞回特征消除以降低計算成本.
4.3 特征提取技術
ECG單導聯的特征在之前的部分已經全面的進行了分析,這里我們會專注于用來提取這些特征的技術,根據之前的研究,Pan-Tompkins演算法是特征提取最廣泛使用的技術,它是Jiapu
Pan and Willis J. Tompkins 【90】提出的ECG信號的QRS波峰的實時檢測演算法,在【74,76】中,ECG信號的R峰用Pan-Tompkins演算法來確定,【48】使用Pan-Tompkins演算法從ECG信號中抽取了RR間隙,【52】使用不應期為 250 ms 的 Pan-Tompkins QRS 檢測器,滑動視窗為 3 s,然而,該演算法在存在噪聲和倒置 QRS 的情況下錯過了許多 R 峰,特別是,ECG 信號過渡部分的高能量噪聲會極大地扭曲 Pan-Tompkins 演算法的性能 【57】,
研究【40】的創新點是應用稀疏編碼進行無監督特征提取,在 【41】 中,使用 3 個檢測器(相量變換、連續小波變換和 S 變換)的組合來確定可靠的 QRS 位置,
以下特征提取是使用 Teager-Kaiser Energy Operator (TKEO) 進行的, 在 【77】 中,他們對每個 ECG 使用了四個眾所周知的 QRS 檢測器,即 gqrs、Pan-Tompkins (jqrs)、最大值搜索和匹配過濾, 在 【75,78】 中,使用在 WFDB 工具箱中開放訪問的 gqrs 演算法檢測 QRS 復合波,
隨著基于深度學習的演算法的進步,可以更好地解決特征提取的挑戰, 為了學習輸入 ECG 信號的表示(判別特征),在 【59-61,68,69】 中使用了卷積層,
5 AF檢測的機器學習方法
5.1 支持向量機
SVM是一種很受歡迎的監督學習方法,用于解決分類和預測的問題,【40-47】已經將這種方法應用于ECG單導聯信號,【40,43】通過使用改進的cuckoo演算法來微調SVM訓練期間的引數,從而實作了基于SVM的心律分類器,他們在CinC2017的得分是0.77和0.83,【43】通過計算信號質量指數來實作信號質量評估,然后從質量好的信號中提取特征,顯然,使用高質量的心電圖片段提取特征可以獲得更好的分類系統性能, 在【42】中,選擇分類器是因為它具有泛化能力,即使在分析不平衡的資料集時也是如此, CinC2017的資料庫用于訓練SVM分類器,而MIT-BIH AF資料庫用于常見場景下的性能評估,在【42】中獲得的看不見的資料集的F1 值為 0.71,
在【41】中開發了基于 SVM 的兩步方法,它用于從單導聯心電圖記錄中識別多類節律, 具體來說,他們在第一步中選擇了兩個獨立的徑向基函式核 SVM 進行初步分類, 然后,在第二步中,遵循具有線性核函式的 SVM,它可以實作更可靠的預測性能,將 ECG 記錄分為四種型別, 在【44】中,建議使用最小二乘 SVM 來區分正常、AF、其他心律和嘈雜的 ECG 記錄之間的心律, 他們提出了一種基于一組二元分類器的方法來解決多類分類問題,在 CinC2017 的隱藏挑戰資料集上獲得了 0.81 的總 F1 分數, 與【40,42,43】中的方法相比,似乎在訓練集上應用二元分類器可以提供相對更好的F1分數,
5.2 決策樹
決策樹是另一種廣泛使用的分類方法,受益于其可解釋性以及高效和可擴展的學習概念的可用性,由于單個決策樹容易導致過擬合,因此研究人員嘗試將它們組合在一起以提高分類系統的準確性【48】,【48-51】中的研究就是這類典型案例,它們都實作了隨機森林分類器來區分四類心電節律, 在【51】中,作者通過使用 500 個決策樹在 CinC2017 剩余 80% 的訓練資料上訓練了一個隨機森林分類器,并使用bagging訓練每個分類器,即訓練資料的自舉副本, 另一方面,【48】的研究使用了自舉聚合(bagged)決策樹,聚合了來自 220 個決策樹的集合的預測, 在【49】中,他們用 1000 棵決策樹訓練了一個基于隨機森林的分類器(bagged決策樹),獲得的 F1 分數為 0.81, 在研究【48】和【51】中,使用了220棵決策樹和500棵決策樹,在看不見的測驗資料集(沒有資料平衡)上分別獲得了78%和82.6%的分數, 似乎具有更多決策樹的分類模型可以產生更好的性能來用于從單導聯心電圖記錄中篩選出 AF,【49】中也證明了這種指示, 此外,【48】表明無法處理樣本的均衡性的話會影響分類器性能, 另一方面,【49】中的調查表明,基于樣本分布的權重解決心電資料不平衡有助于提高分類性能,
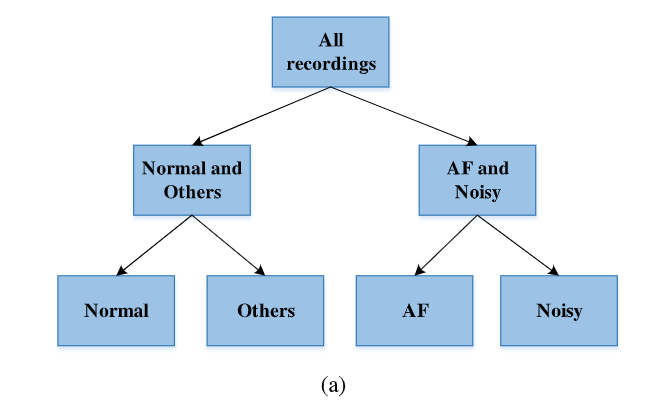
AdaBoost(adaptive boosting)是一種集成學習方法,將許多弱學習器(如決策樹)組合起來構建一個強分類器,并使用一個加權向量來降低誤分類率, 該演算法不太容易過度擬合,尤其是當學習周期數限制為 70【52】時, 但是,它對噪聲資料和例外值更敏感, 因此,在使用 AdaBoost 分類器之前,應建議對原始 ECG 信號進行預處理以生成相對干凈的 ECG 資料,【52】的研究表明AdaBoost二叉樹可以取得更好的效果, 為此,【53】中提出了一種包含三個分類器的多層二進制級聯方法, 一個分類器首先將未知錄音標記為“正常+其他節奏”或“AF+嘈雜”,然后使用另外兩個分類器確定最終的分類結果, 集成學習模型的架構如圖 六(a) 所示:
圖六(a):
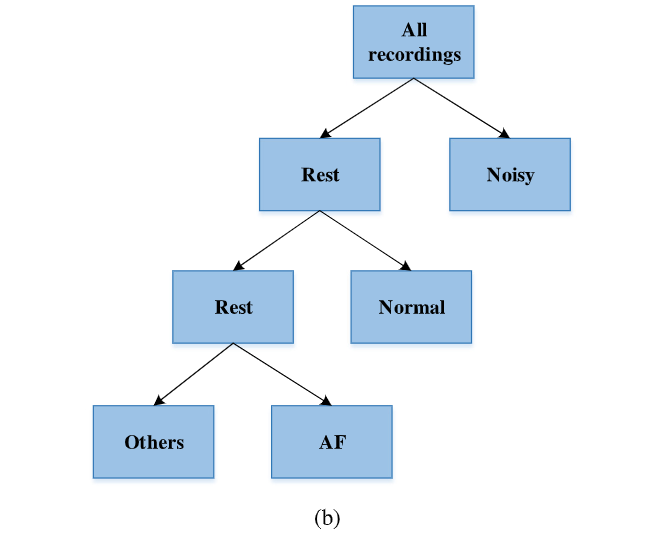
在【54】中使用了一種分層模型,該模型是獨立訓練的分類器的堆疊,每種分類器都進行二值分類,如圖六b描述的一樣:
圖六(b):
在一項類似的作業中,使用 AdaBoost.M2 演算法【55】訓練了二元分類決策樹模型, 【56】的研究提出了一種基于bootstrap聚合的最優集成分類器模型, 集成分類器將一組分類器組合在一起,可以獲得比每個分類器更好的性能, 例如,可以使用多數票將集成分類器的預測結果組合起來以做出最終決定, 【57】的研究使用噪聲檢查分類器來檢查記錄是否太嘈雜而無法分類,并應用心律分類器來區分心律失常, 兩個分類器都基于bagged決策樹模型, 在【58】中,研究人員將神經網路與bagged樹相結合,對心律失常進行分類, 當神經網路不能對信號進行高確定性分類時,bagged樹演算法就起到了最終分類器的作用,
6 AF檢測的深度學習
深度學習已成為一種革命性的工具,可以通過最少的預處理和后處理來分析復雜資料, 本質上,它是機器學習的一個分支,在計算機視覺、自然語言處理和生物醫學信號處理方面取得了可喜的成果, 用于自動對焦檢測的傳統演算法需要資料預處理和特征提取階段,然后提取的特征向量作為支持向量機、集成學習或其他機器學習演算法的輸入, 然而,手工特征提取的程序需要專業領域的特定專業知識,因此復雜且耗時,隨著深度學習的出現,手工特征提取的繁瑣程序不再是強制需要的,
CNN 是最常見的深度學習架構之一,它由卷積層、批量歸一化層、非線性激活層、dropout 層、池化層和分類層組成 【38】, RNN 旨在處理序列資料,例如神經語言處理、語音識別和文本摘要, 然而,這種架構在處理梯度消失這個重要問題方面的能力很差, 為了解決這個問題,Hochreiter 和 Schmidhuber【91】提出了一個 LSTM 網路,它包含一組儲存塊,每個儲存塊都包含記憶體單元,
6.1 CNN
在【60】和【61】的研究中,獨立使用CNN對ECG記錄進行分類,在CinC2017的隱藏測驗資料集上獲得的F1分數均為71%, 為了評估加深CNN網路對分類性能的影響,【92】中設計了一個實驗,其中卷積層的數量逐步增加和評估,而它們的引數保持不變, 結果表明,訓練階段沒有顯著差異,但是,卷積層數最多的 CNN 模型獲得了最佳性能, 通常,將一維心電信號轉換為二維時頻影像,然后饋入 CNN 模型,該模型可以捕獲深層特征并促進心律失常檢測, 例如,在【62】中,一個二維編碼的雙搏心電耦合矩陣被認為是3層CNN分類器的輸入來檢測室上性異位搏動和室性異位搏動,優于基于1-D CNN的方法【63】, 通過短時傅立葉變換 (STFT) 從一維心電圖記錄轉換而來的二維時頻影像被輸入到所提出的 CNN 模型中,用于識別和分類五種心跳型別【64】, 類似地,同樣由 STFT 生成的二維矩陣流入深度卷積神經網路 (DCNN) 以檢測 AF【66】, 在【65】中,所提出的模型用于根據 STFT 生成的二維影像將所有 ECG 記錄分為 8 類, 上述研究基于多導聯心電圖,這激發了許多研究人員開發用于從單導聯心電圖檢測房顫的相關演算法, 為了將一維時間序列(單導聯心電圖)轉換為二維時頻影像,在【36】中實作了 STFT,然后將所有影像輸入一個密集連接的卷積網路(DenseNet), 在類似的作業中,使用單導聯心電資料的時頻分布矩陣和 CNN 演算法來區分不同的心律(12 類)【35】,
6.2 RNN
盡管 CNN 在學習輸入資料的表征方面非常強大,但考慮 ECG 信號等序列信號的長期和短期依賴性也很重要【92】, 因為經典神經網路不包含記憶單元,它們不足以學習這些依賴關系, 考慮到這一點,RNN 架構是通過向前饋神經網路添加內部存盤器來創建的, RNN 在短期記憶操作中取得了成功,但由于梯度消失問題,它們未能學習長期依賴關系,這是執行長期記憶的主要困難之一, 因此,引入了 LSTM 網路來解決這個問題,【67】的作者在單導聯 ECG 資料上使用誤差反向傳播訓練了 LSTM 網路,【69】中的作業在單導聯 ECG 資料集上評估了所提出的 CNN 和 CRNN 架構,并證明 CRNN 產生了比 CNN 架構更高的整體準確度和 F1 值, 此外,【92】 的作業表明,LSTM 模型的性能在檢測精度方面不及堆疊的 LSTM 結構, 但是,添加到模型中的 LSTM 層數使計算時間增加了一倍,因此,開發了混合技術,尤其是 CNN 和 LSTM 網路,以降低計算成本并提高 LSTM 網路的性能,
在【59,68,69】中采用了CNN特征提取,然后這些特征作為LSTM的輸入, 對于多類分類,【59】的研究通過提出一個包含三個 CRNN 的分層模型,將這個問題轉化為一個多二元分類問題, 在【59】中認為LSTM可以幫助處理長期依賴和梯度消失的問題,因此,特征提取由一維卷積層執行,并將結果輸入LSTM層, 在【68】中,他們提出了一種名為 CL3 的新深度學習模型,該模型使用 CNN 提取特征,這些特征被引導到 LSTM 堆疊中,以使用很少的手動引數從 ECG 時期自動學習隱藏模式,【69】中進行了類似的作業, 它結合了用于特征提取的卷積層堆疊和用于特征時間聚合的 LSTM 層,然后使用帶有 softmax 的標準線性層來計算分類概率, 上述三種演算法 【59,68,69】 在 CinC2017 的隱藏資料集上分別獲得了 0.77、0.80 和 0.82 的整體 F1-measures, 從性能記錄中,我們可以想象,與僅使用 CNN 或 LSTM 的模型相比,CNN 和 LSTM 的組合可能有助于提高 F1 值,
7 討論和公開問題
通過對文獻的綜合回顧,可以獲得一些可能促進單導聯心電圖檢測 AF 性能的潛在因素:
- (1)樣本不平衡, CinC2017 資料集在研究單導聯心電圖的 AF 篩查方面很受歡迎, 該資料集包含 8528 個心電圖記錄,就深度學習模型而言,樣本數量相對較少, 此外,AF 記錄的嚴重不平衡對于監督學習來說是不令人滿意的,因為它會影響分類演算法的性能, 在文獻中和這個社區內,資料增強被廣泛用于解決這個問題, 例如,【93】的研究表明資料增強可以幫助訓練不同資料集的模型, 【80】 的作業研究了資料增強演算法的能力,如過采樣、高斯混合模型 (GMM) 和生成對抗網路 (GAN),以解決資料不平衡問題, 【80,93】 中的結果表明資料增強的性能提升, 特別是,與使用過采樣方法的分類演算法相比,基于深度學習的分類演算法更多地受益于使用 GAN 和 GMM 的資料增強,
- (2)降噪, 可穿戴式采集設備收集的心電圖記錄經常受到服務器噪聲的干擾,這已被證明會對分類系統的準確性產生負面影響, 例如,【94】 的研究表明,隨著信噪比的降低,AF 檢測精度呈線性下降, 因此,認為去除噪聲對分類性能有益【95】, 近年來已經提出了大量用于去除ECG信號的噪聲的技術, 在【96】中,對小波去噪方法和深度學習模型進行了綜合比較, 結果證明小波方法適用于去除隨機噪聲,而深度學習去噪模型對于更高級別的隨機和漂移噪聲具有明顯優勢,
- (3)信號分割和形態分析, 通過分割 ECG 信號,可以有效降低模型的計算成本, 由于 ECG 信號是非平穩的,因此從整個序列中在區域提取特征可能不合適,因此,【48】的研究將每個心電圖記錄分割成epoch,在類似的作業中,為了減少時間步數,【72】的研究將心電圖分割成一系列心跳, 心電圖的形態分析有助于檢測 PQRST 點,在特征提取階段也起著關鍵作用,【94】表明HRV能夠提供最大F1分數的92.5%,而更復雜的形態分析的附加值為0.19(最大數為0.19),
- (4)質量評估, 信號質量評估可以有效提高信號分類演算法的性能,許多研究在訓練模塊之前引入了信號質量評估, 【52】中的結果表明,高質量的心電圖和噪聲信號之間存在顯著差異, 因此,回圈質量評估應用于每次心跳,剩余的高質量信號用于【61】中的進一步處理, 為了確保該演算法僅在高質量信號上進行訓練,【58】 中的作者在使用神經網路進行初步分析后去除了部分信號, 類似地,【43】 的研究將心電圖記錄分割成幾個心電圖情節,并且只采用質量好的心電圖情節進行特征提取, 在【78】中,應用了信號質量指標技術, 質量指數低的心電圖記錄被識別為噪聲,而信號質量指數合理的心電圖記錄在分類階段進一步處理, 此外,通過在【96】中采用各種質量評估措施來解決錯誤最小化問題,
- (5)深度網路, 已經證明通過增加卷積層提高了分類性能,【92】中報告的結果表明,具有更多層的模型可以實作更好的分類性能, 我們還應該注意卷積層中的過濾器數量或 CNN 模型要使用的卷積層數量 【96】, 結果表明,所提出的具有更多過濾器、更多層和更大卷積核尺寸的模型能夠實作更高的分類精度【96】, 具有更多決策樹的模型也會產生更好的分類性能, 為了證明所提出模型在不同數量的決策樹下的有效性,【49】的研究分別用 100 棵決策樹和 1000 棵決策樹訓練了集成學習模型,
- (6)混合架構, 與僅使用梯度提升的傳統方法相比,CNN 和 LSTM 網路的混合架構實作了更高的準確性, 在**[75]**中,使用梯度提升演算法的模型獲得了 0.79 的 F1 分數,而結合梯度提升演算法和 LSTM 網路的模型獲得了 0.81 的 F1 值, 就檢測精度而言,堆疊 LSTM 結構的性能優于單個 LSTM 模型, 但是,堆疊的 LSTM 模型需要更多的計算時間, 因此,CNN 和 LSTM 的結合在最近幾年非常流行,
- (7)時頻影像,時頻表示能夠反映資料隨時間變化的頻率分量, 近年來,它被認為是心律失常分類模型的輸入以獲得更高的性能,
- (8)非學習方法, 在過去的幾十年中,許多研究人員提出了通過分析 RR 間期的變化 【97,98】、龐加萊散點圖中的心率變異性【83】和相對小波能量【99,100】來檢測 AF 的統計方法, 盡管非學習方法能夠減少計算量,但與基于學習的方法相比,它具有較差的性能和復雜的手動程序,
8 總結
在本文中,我們對單導聯 ECG 波的 AF 篩查進行了全面調查, 其動機是可以方便地采集單導聯心電圖的可穿戴設備的日益普及,以及公眾對實時健康監測的需求日益增加, 首先收集所涉及的常見問題,例如問題制定、開放資料集和性能指標, 然后我們總結并比較分析了用于解決這個問題的主要技術,包括預處理、特征提取、機器學習和深度學習演算法, 通過比較文獻中的性能記錄,列出了一些可能有助于提高單導聯心電波檢測性能的潛在貢獻者,預計有興趣的讀者可以在相關研究作業中從這些問題中受益,
CRediT 作者貢獻宣告
Yu Liu:方法論,形式分析,資料規約,起稿,
Junxin Chen:資料管理、專案管理、資金獲取,
Nan Bao:寫作-評論與編輯,監督,可視化,
BrijB.Gupta:監督、專案管理、形式分析,
Zhihan Lv:監督、可視化、資料規約、形式分析,
競爭利益宣告
作者宣告,他們沒有已知的可能會影響本文報告的作業競爭性經濟利益或個人關系,
我的觀點
1.演算法補充:
文中對很多演算法沒有做描述,尤其神經網路的演算法僅僅只有17年的幾篇,我覺得這篇文章寫的可以說是不全面,18年以后的模型根本沒有涉及到,在此我對一些演算法模型進行補充,
1.1 MINA
利用時域和頻域資訊結合的方式,對從record里面分割出來的定長seg,進行預測,在默認引數下的val loss下降到0.02,具體隱藏測驗集上的測驗結果未知,因為cinc17的測驗集還未公開,
1.2 cinc17-paper
這些演算法的代碼都開源,地址在https://physionet.org/static/published-projects/challenge-2017/1.0.0/sources/,
1.3 大佬github
這里有1d的殘差網路等SOTA模型可以學習,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/295254.html
標籤:其他