前言
在閱讀了一系列Activation Funtion論文之后,其中Dynamic Relu的論文提到了基于注意力機制的網路,因此先來看看經典的SE-Net的原理
Introduction
對于CNN,卷積核在區域感受野中將空間和通道資訊融合得到資訊組合.通過堆疊一系列非線性交錯的卷積層和下采樣,CNN能夠獲取具有全域感受野的分層模式,作為強大的影像描述,
最近的研究表明,網路的性能可以通過顯式嵌入學習機制來提高,這有助于捕獲空間相關性,而無需需要額外的監督,其中一種方法是由Inception推廣的,這表明網路可以通過在其模塊中嵌入多尺度程序來實作具有競爭力的準確性,
最近的作業試圖更好地模擬空間依賴[1,31],并納入空間注意[19],
其中上述參考的論文如下
- [1]S. Bell, C. L. Zitnick, K. Bala, and R. Girshick. Inside- outside net: Detecting objects in context with skip pooling and
recurrent neural networks. InCVPR, 2016.1- [31]A. Newell, K. Y ang, and J. Deng. Stacked hourglass networks for human pose estimation. InECCV, 2016.1,2
- [19]M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu. Spatial transformer networks. In NIPS, 2015.1,2
該篇論文研究了網路結構設計的一個不同的方面-通道關系,通過引入一個新的結構單元,稱之為“Squeeze-and-
Excitation” (SE) block,
作者目標是將卷積特征通道之間的相互依賴性顯式地建模出來,以提高網路的表示能力,為了實作這一點,我們提出了一種機制,允許網路執行特征重新校準,通過該機制,網路可以學習使用全域資訊來選擇性地強調資訊性特征,并抑制不太有用的特征,
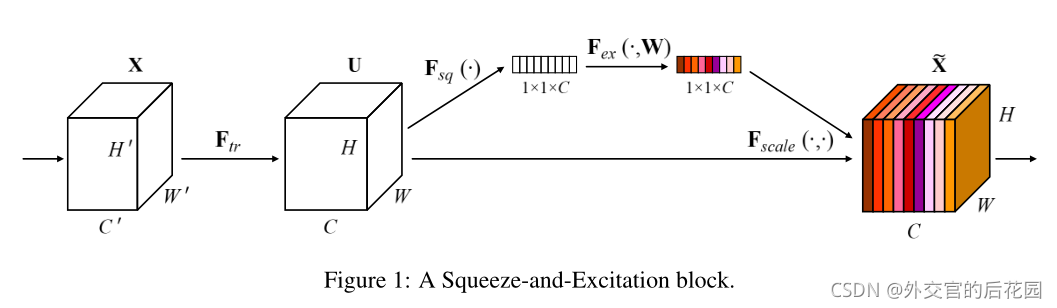
SE-block的基本結構如上圖所示,有如下定義:
對任何給定的變換
F
t
r
:
X
→
U
,
X
∈
R
H
′
×
W
′
×
C
′
,
U
∈
R
H
×
W
×
C
F_{tr}:X\to U,X\in \mathbb{R}^{H^{'}\times W^{'}\times C^{'}},U\in \mathbb{R}^{H\times W\times C}
Ftr?:X→U,X∈RH′×W′×C′,U∈RH×W×C
以上給定的變換針對一個卷積或者一組卷積而言,
我們可以構造一個相應的SE塊來執行特征重新校準,如下所示,
特征
U
U
U首先通過一個
s
q
u
e
e
z
e
squeeze
squeeze操作,該操作將空間維度上的特征映射聚合,生成通道descriptor,
該descriptor嵌入了通道特征回應的全域分布,使來自網路全域感受野的資訊能夠被其較低層利用,
然后經過一個
e
x
c
i
t
a
t
i
o
n
excitation
excitation操作,在該操作中,通過基于通道依賴性的self-gating機制為每個通道學習的樣本特定激活控制每個通道的
e
x
c
i
t
a
t
i
o
n
excitation
excitation
然后對特征映射
U
U
U重新加權以生成SE-block的輸出,然后將其直接輸入后續的layers,
SE-network可以通過簡單地堆疊SE building block的集合來生成,SE-block 也可以作為架構中任何深度中original block的替代,
SE-block在計算上是輕量級的,只會稍微增加模型的復雜性和計算負擔,
使用SENets,作者贏得了2017年ILSVRC分類比賽的第一名,
表現最好的模型組合實作了2.251% top-5 error在ILSVRC測驗集上,比前一年的winner提高了25%(前一年的winner的top-5 error是2.991%)
Related Work
Attention and gating mechanisms
從廣義上講,注意力可以被視為一種工具,使可用處理資源的分配偏向于輸入信號中資訊量最大的成分,它通常與gating功能(例如softmax或sigmoid)和sequential技術結合使用,(這里指的sequential技術沒有深入了解,有興趣看如下參考文獻)
- S. Hochreiter and J. Schmidhuber. Long short-term memory.Neural computation, 1997.2
- M. F. Stollenga, J. Masci, F. Gomez, and J. Schmidhuber.Deep networks with internal selective attention through feedback
connections. In NIPS, 2014.2
在這些應用中,它通常用于表示更高層次抽象的一個或多個層之上,以便在不同的模式之間進行適配,
Related work的詳細描述我沒有全貼出來,原因是講述的領域有點廣,或者不太重要的描述,我們主要關注SE-block是怎么實作的,
Squeeze-and-Excitation Blocks
SE-block是一個計算單元,可以構造任何給定變換:
F
t
r
:
X
→
U
,
X
∈
R
H
′
×
W
′
×
C
′
,
U
∈
R
H
×
W
×
C
\textbf{F}_{tr}:\textbf{X}\to \textbf{U},\textbf{X}\in\mathbb{R}^{H^{'}\times W^{'}\times C^{'}},\textbf{U}\in\mathbb{R}^{H\times W\times C}
Ftr?:X→U,X∈RH′×W′×C′,U∈RH×W×C
其中,
F
t
r
\textbf{F}_{tr}
Ftr?是一個卷積算子,令
V
=
[
v
1
,
v
2
,
.
.
.
,
v
C
]
\textbf{V}=[\textbf{v}_1,\textbf{v}_2,...,\textbf{v}_C]
V=[v1?,v2?,...,vC?]表示學習的濾波器核集,其中
v
c
v_c
vc?指的是第c個濾波器引數,
F
t
r
\textbf{F}_{tr}
Ftr?的輸出可以寫成
U
=
[
u
1
,
u
2
,
.
.
.
,
u
C
]
\textbf{U}=[\textbf{u}_1,\textbf{u}_2,...,\textbf{u}_C]
U=[u1?,u2?,...,uC?],其中
u
c
=
v
c
?
X
=
∑
s
=
1
C
′
v
c
s
?
x
s
.
?
?
?
(
1
)
\textbf{u}_c=\textbf{v}_c\ast \textbf{X}=\sum_{s=1}^{C^{'}}\textbf{v}_c^s\ast \textbf{x}^s.---(1)
uc?=vc??X=s=1∑C′?vcs??xs.???(1)
這里?表示卷積,
v
c
=
[
v
c
1
,
v
c
2
,
.
.
.
,
v
c
C
′
]
\textbf{v}_c=[\textbf{v}_c^1,\textbf{v}_c^2,...,\textbf{v}_c^{C^{'}}]
vc?=[vc1?,vc2?,...,vcC′?]和
X
=
[
x
1
,
x
2
,
.
.
.
,
x
C
′
]
\textbf{X}=[\textbf{x}^1,\textbf{x}^2,...,\textbf{x}^{C{'}}]
X=[x1,x2,...,xC′](簡化符號,省略偏置項)
其中
v
c
s
v_c^s
vcs?是一個二維的卷積核,表示
v
c
v_c
vc?的一個通道,作用于
X
X
X對應的通道,由于輸出是通過所有通道的求和產生的,因此通道依賴性是隱式嵌入到
v
c
v_c
vc?中,但是這些依賴關系與濾波器捕獲的空間相關性糾纏在一起,
我們的目標式確保網路能夠提高其對資訊特征的敏感性,以便它們可以被后續的轉換利用,并抑制不太有用的特征,
我們建議通過顯式建模通道相互依賴來實作這一點,在它們被饋送到下一個變換之前,在Squeeze和Excitation兩個步驟中重新校準濾波器回應,圖1顯示了一個SE構建塊的示意圖,
Squeeze: Global Information Embedding
為了解決利用通道依賴性的問題,我們首先考慮信號到每個通道輸出特征,每個學習過的濾波器都有一個區域感受野,因此每一個轉換輸出的單元 U U U是無法利用該感受野之外的背景關系資訊,
這里通俗的說可以有兩種解釋:
1.學習過的濾波器之間無法互相利用之間的資訊,即如下公式中的 v c v_c vc?之間無法通信,
2.每個轉換輸出的單元 U U U的公式如下:
u c = v c ? X = ∑ s = 1 C ′ v c s ? x s . ? ? ? ( 1 ) \textbf{u}_c=\textbf{v}_c\ast \textbf{X}=\sum_{s=1}^{C^{'}}\textbf{v}_c^s\ast \textbf{x}^s.---(1) uc?=vc??X=s=1∑C′?vcs??xs.???(1)
對于轉換輸出的單元 u c \textbf{u}_c uc?無法利用其他轉換輸出單元的背景關系,只能捕獲當前 v c \textbf{v}_c vc?感受野的資訊,
這個問題在感受野較小的網路低層變得更加嚴重,
為了緩解這個問題,我們建議將全域空間資訊放入通道descriptor(原論文為channel descriptor,這里我不知道咋翻譯,將原單詞copy過來,防止引起歧義)中,這是通過使用全域平均池化生成通道統計資訊來實作的,
形式上,統計量
z
∈
R
C
z\in \mathbb{R}^C
z∈RC是由壓縮輸出
U
U
U的空間維度
H
×
W
H\times W
H×W生成的,其中
z
\textbf{z}
z的第
c
c
c個元素可以被計算為:
z
c
=
F
s
q
(
u
c
)
=
1
H
×
W
∑
i
=
1
H
∑
j
=
1
W
u
c
(
i
,
j
)
,
?
?
?
(
2
)
z_c=\textbf{F}_{sq}(\textbf{u}_c)=\frac{1}{H\times W}\sum_{i=1}^H\sum_{j=1}^Wu_c(i,j),---(2)
zc?=Fsq?(uc?)=H×W1?i=1∑H?j=1∑W?uc?(i,j),???(2)
簡潔地說:統計量 z c z_c zc?就是第 c c c個輸出單元的全域平均池化輸出,這個資訊是通道統計資訊的一部分,作為每個通道的統計量,
作者的討論: 變換輸出 U \textbf{U} U可以解釋為一個區域descriptors的集合,這些descriptors的統計量可以表達整個影像,在特征工程作業中,利用這些資訊是很普遍的[35,38,49],
[35] J. Sanchez, F. Perronnin, T. Mensink, and J. V erbeek. Image classification with the fisher vector: Theory and practice.RR-8209, INRIA, 2013.3
[38] L. Shen, G. Sun, Q. Huang, S. Wang, Z. Lin, and E. Wu.Multi-level discriminative dictionary learning with application to large scale image classification.IEEE TIP, 2015.3
[49] J. Y ang, K. Y u, Y . Gong, and T. Huang. Linear spatial pyramid matching using sparse coding for image classification.InCVPR, 2009.3
我們選擇了最簡單的全域平均池,注意到這里也可以使用更復雜的聚合策略,
Excitation: Adaptive Recalibration
為了利用squeeze操作(上一節提到的全域平均池化為一種squeeze)中聚集的資訊,我們隨后進行第二次操作,目標是完全捕獲通道依賴性,
為了實作這一目標,該function必須符合兩個準則:
- 首先,它必須是靈活的(特別是,它必須能夠學習通道之間的非線性相互作用)
- 其次,它必須學會一種非互斥的關系,因為我們想要確保多個通道被允許被強調,而不是一次性激活,
為了滿足這些標準,我們選擇采用簡單的sigmoid激活gating機制:
s
=
F
e
x
(
z,W
)
=
σ
(
g
(
z,W
)
)
=
σ
(
W
2
δ
(
W
1
z
)
)
,
?
?
?
(
3
)
\textbf{s}=\textbf{F}_{ex}(\textbf{z,W})=\sigma(g(\textbf{z,W}))=\sigma(\textbf{W}_2\delta(\textbf{W}_1\textbf{z})),---(3)
s=Fex?(z,W)=σ(g(z,W))=σ(W2?δ(W1?z)),???(3)
其中
δ
\delta
δ為ReLU激活函式,
W
1
∈
R
C
r
×
C
\textbf{W}_1\in\mathbb{R}^{\frac{C}{r}\times C}
W1?∈RrC?×C,
W
2
∈
R
C
×
C
r
\textbf{W}_2\in\mathbb{R}^{C\times\frac{C}{r}}
W2?∈RC×rC?
為了限制模型的復雜性并助于推廣,我們通過圍繞非線性形成兩個完全連接(FC)層的bottleneck來引數化gating機制,換句話說,帶有引數
W
1
\textbf{W}_1
W1?和降維比
r
r
r的降維層(這個引數的選擇后續會提到),接著一個ReLU,還有一個引數為
W
2
\textbf{W}_2
W2?的升維層,
這里回顧下圖1,注意輸入輸出的維度變化:
- Squeeze- F s q \textbf{F}_{sq} Fsq?之后, U [ H × W × C ] U[H\times W\times C] U[H×W×C]經過全域平均池化得到特征輸出維度為 [ 1 × 1 × C ] [1\times 1\times C] [1×1×C]
- Excitation- F e x \textbf{F}_{ex} Fex?得到特征輸出維度為 [ 1 × 1 × C ] [1\times 1\times C] [1×1×C], F e x \textbf{F}_{ex} Fex?的詳細操作中, W 1 \textbf{W}_1 W1?表示第一個FC層的權重引數, W 2 \textbf{W}_2 W2?表示第二個FC層的權重引數,
公式(3) F e x \textbf{F}_{ex} Fex?的具體操作:FC+ReLU+FC+Sigmoid
- FC:論文里提到 W 1 \textbf{W}_1 W1?是降維的,首先通過一個全連接層(FC)將統計量 z \textbf{z} z從特征維度 C C C降維到特征維度 C r \frac{C}{r} rC?
- ReLU+FC:將1步驟得到的特征經過ReLU激活后再傳入一個全連接層(FC),論文里提到 W 2 \textbf{W}_2 W2?是升維的,該FC將特征維度 C r \frac{C}{r} rC?升維到特征維度 C C C,相當于恢復到統計量 z z z的特征維度
- Sigmoid:將1,2步驟得到的特征經過Sigmid歸一化成0-1的權重
上述提到的FC層的處理相當于對統計量 z \textbf{z} z的通道資訊經過全連接層提取通道的相關性特征
block的最終輸出是通過使用激活縮放變換輸出
U
U
U來得到的:
x
~
c
=
F
s
c
a
l
e
(
u
c
,
s
c
)
=
s
c
?
u
c
,
?
?
?
(
4
)
\widetilde{\textbf{x}}_c=\textbf{F}_{scale}(\textbf{u}_c,s_c)=s_c\cdot \textbf{u}_c,---(4)
x
c?=Fscale?(uc?,sc?)=sc??uc?,???(4)
其中
X
~
=
[
x
~
1
,
x
~
2
,
.
.
.
,
x
~
C
]
\widetilde{X}=[\widetilde{x}_1,\widetilde{x}_2,...,\widetilde{x}_C]
X
=[x
1?,x
2?,...,x
C?]和
F
s
c
a
l
e
(
u
c
,
s
c
)
\textbf{F}_{scale}(\textbf{u}_c,s_c)
Fscale?(uc?,sc?)是指特征映射
u
c
∈
R
H
×
W
\textbf{u}_c\in \mathbb{R}^{H\times W}
uc?∈RH×W和標量
s
c
s_c
sc?之間的通道乘積
這里scale操作中的 s c s_c sc?指 F e x \textbf{F}_{ex} Fex?的輸出, u c \textbf{u}_c uc?指未經squeeze和excitation的輸出 U \textbf{U} U的一部分,用 s c s_c sc?加權到 u c \textbf{u}_c uc?的每個通道特征上,論文中用到的加權是乘法,逐通道乘以權重稀疏,完成在通道維度上引入attention機制
討論:激活充當適應于特定輸入描述 z \textbf{z} z的通道權重,在這一點上,SE-block本質上引入了動態輸入條件,有助于提高特征辨別能力,
Inception和ResNet對應的網路結構
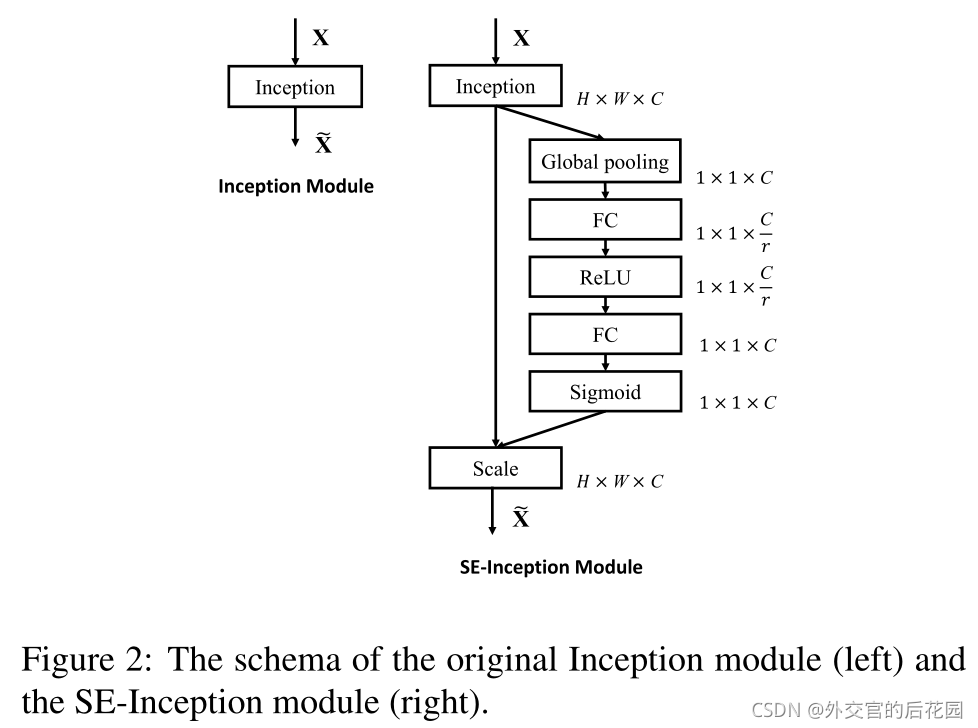
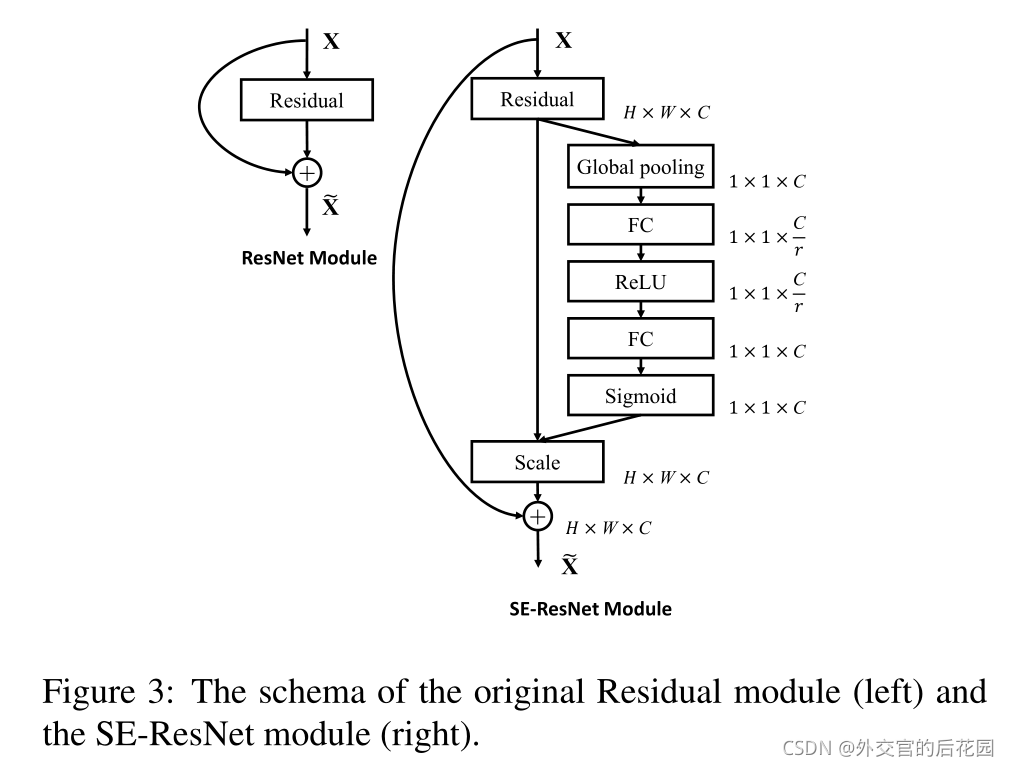
網路模型和計算復雜性
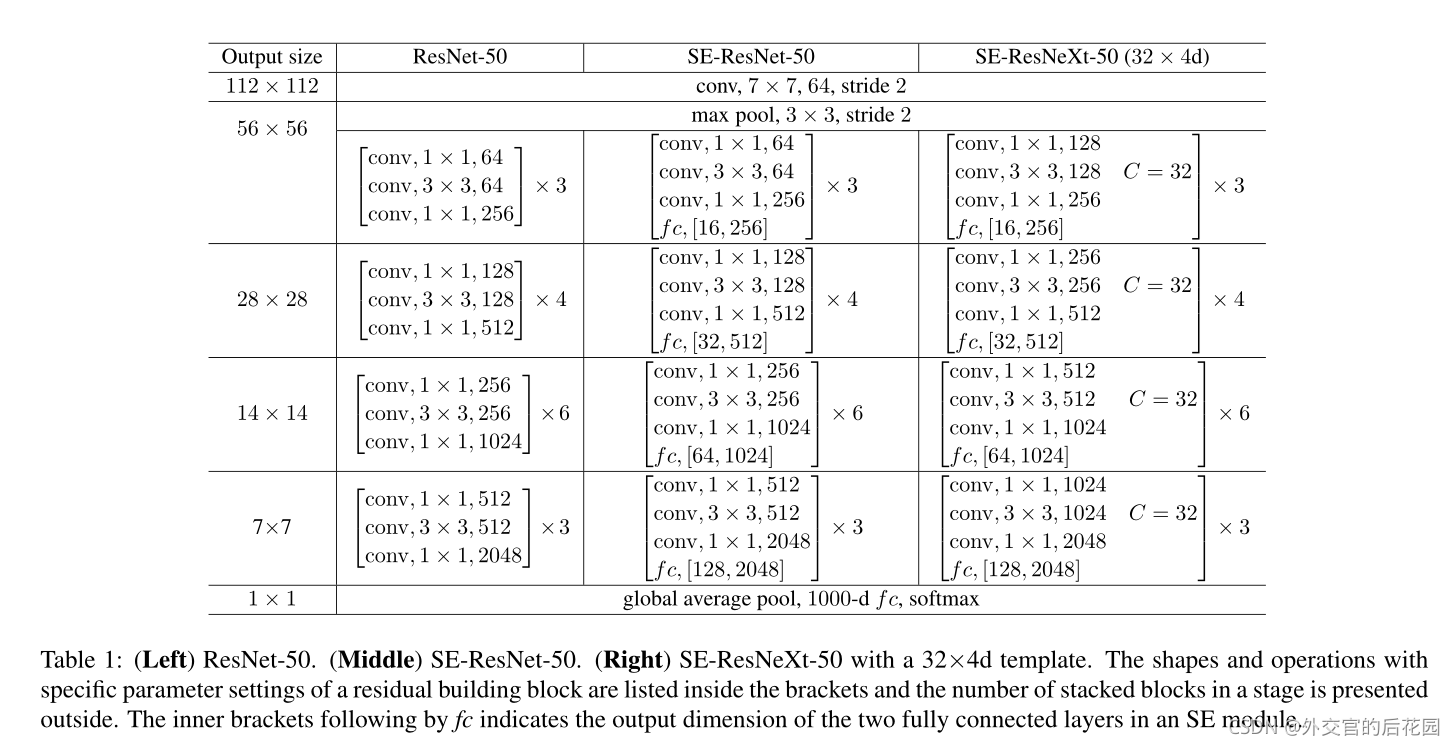
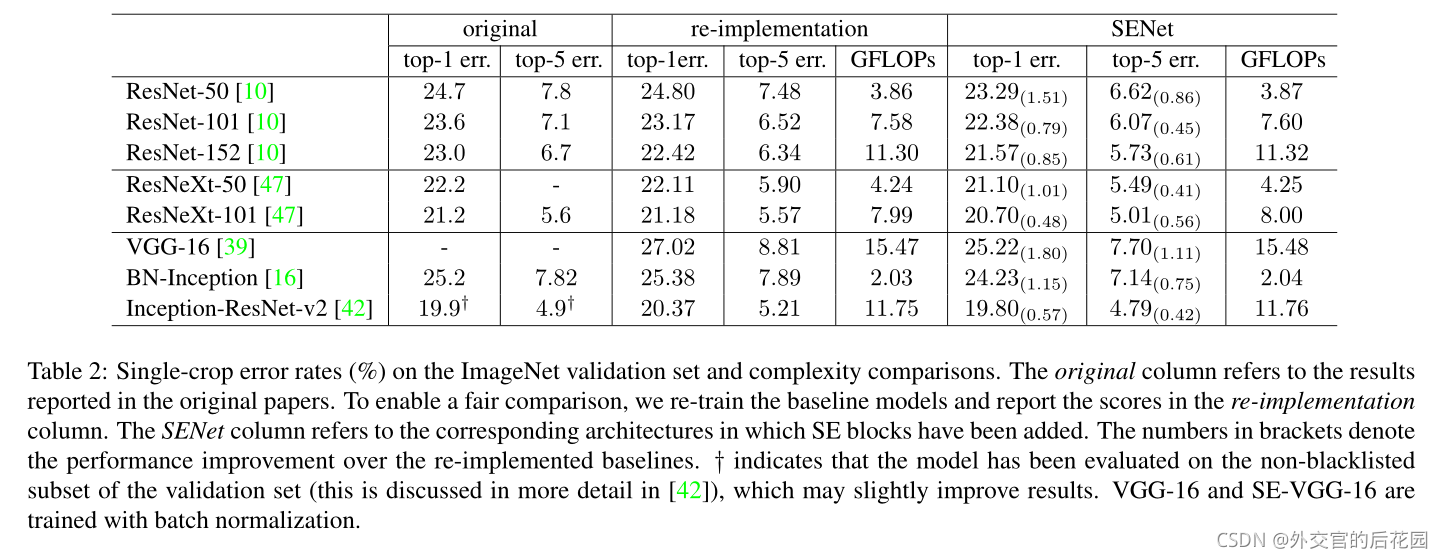
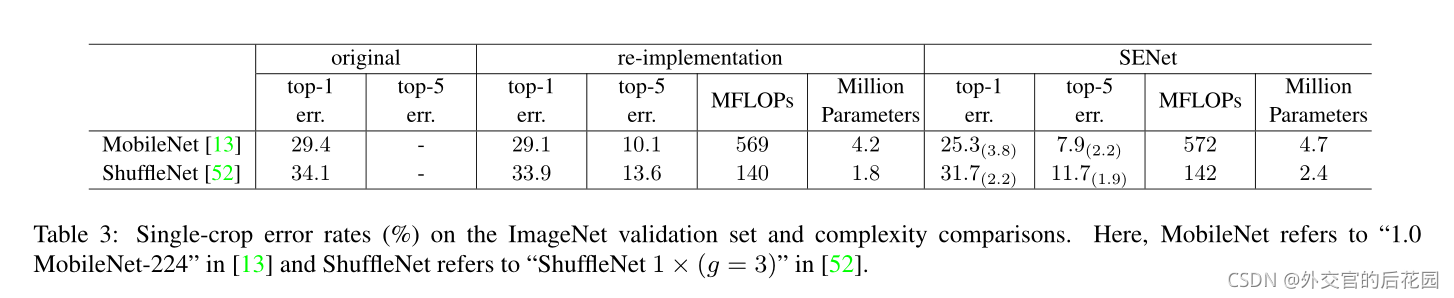
In aggregate,SE-ResNet-50 requires~3.87GFLOPs, corresponding to a 0.26%relative increase over the original ResNet-50.In practice, with a training mini-batch of256images, a single pass forwards and backwards through ResNet-50 takes190ms, compared to209ms for SE-ResNet-50 (both timings are performed on a server with 8 NVIDIA Titan X GPUs).
我們認為,這是一個合理的開銷,特別是因為在現有的GPU庫中,全域池和小型內部產品操作的優化程度較低,此外,由于其對于嵌入式設備應用的重要性,我們還對每個模型的CPU推理時間進行了基準測驗:對于224×224像素的輸入影像,ResNet-50需要164毫秒,而SE-ResNet-50只需要167毫秒,SE塊所需的少量額外計算開銷因其對模型性能的貢獻而被證明是合理的,
SE-ResNet-50引入了多250萬引數量,相比原來包含了2500萬引數量的ResNet-50而言,
實驗
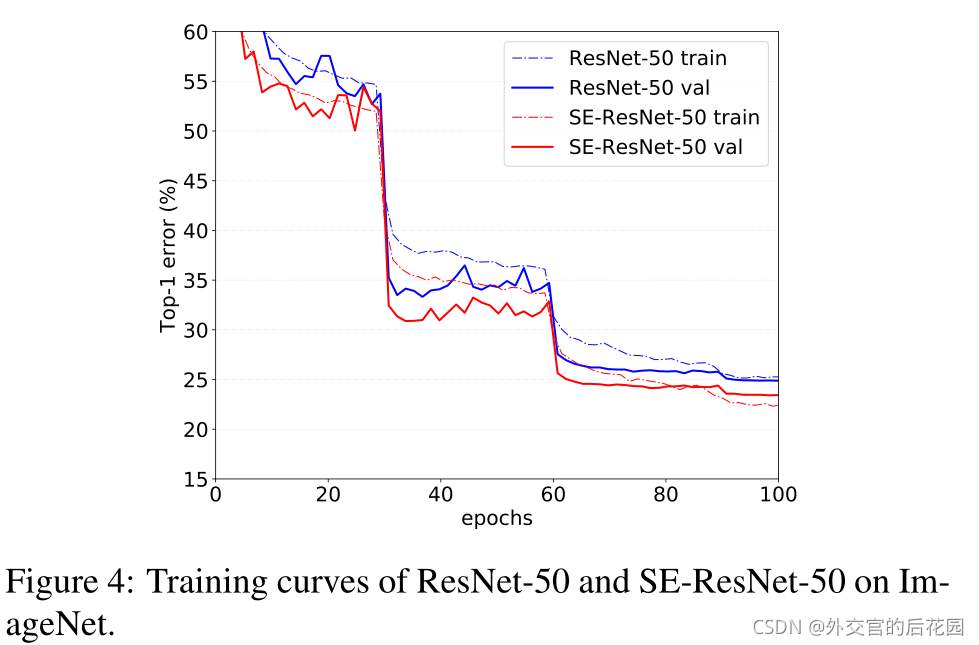
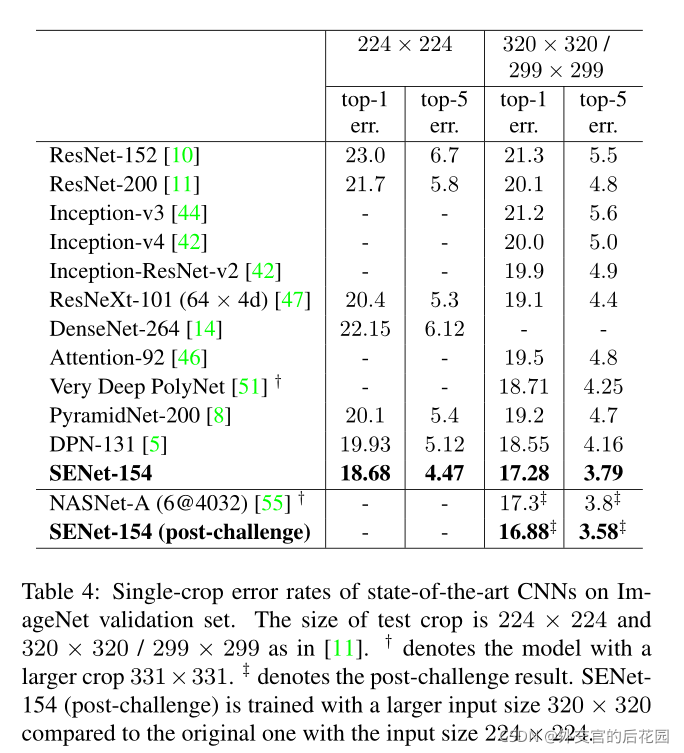
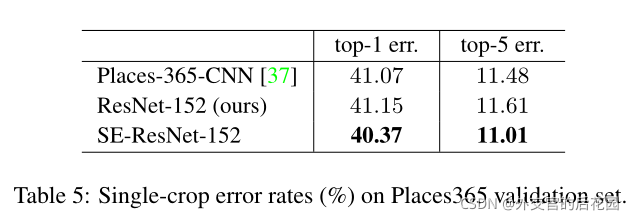
超引數取值
Reduction ratio:
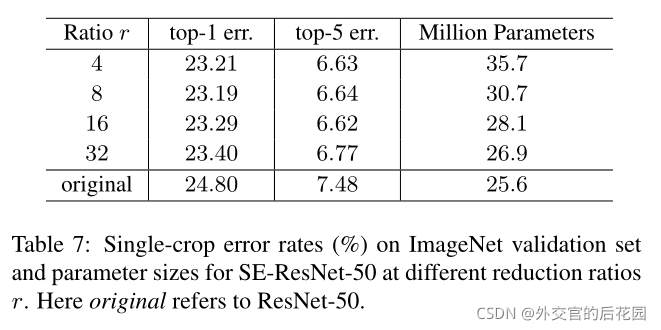
The role of Excitation:
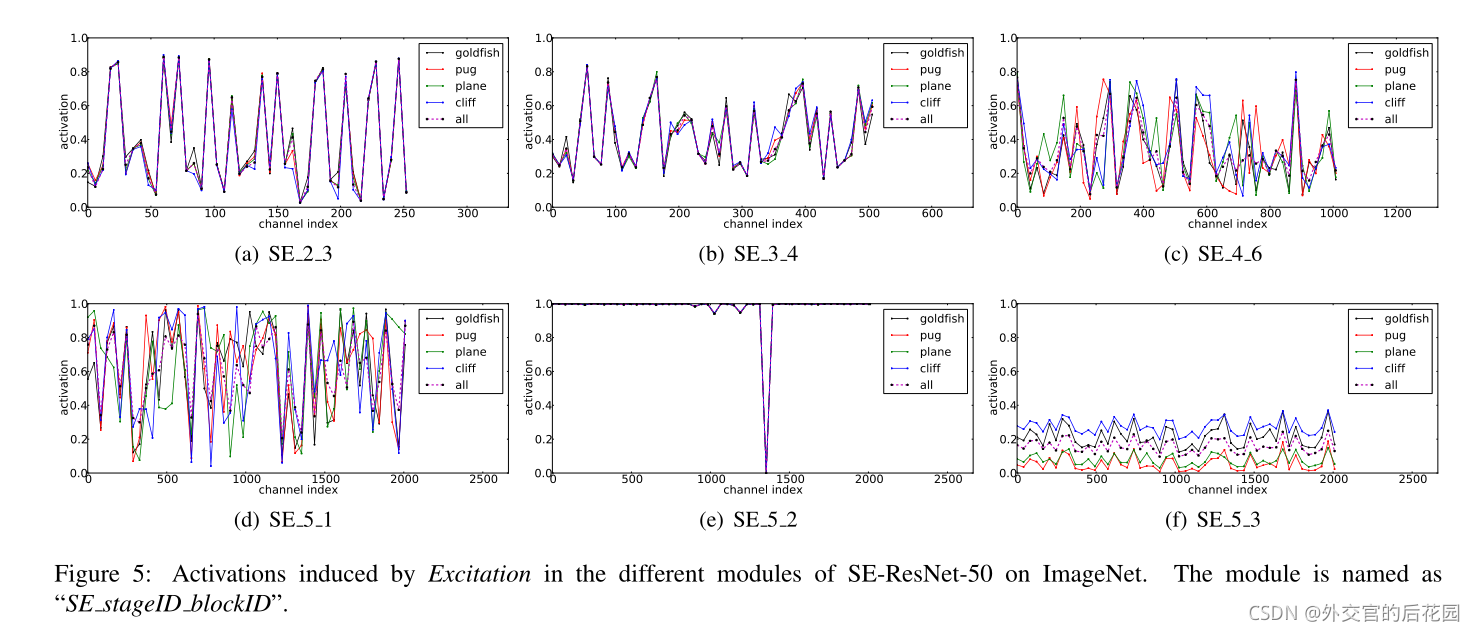
對于上圖,作者在論文進行了解釋
- 首先,在較低的層中,不同類別的分布幾乎相同,例如SE_2_3,這表明在網路的早期階段,通道特征的重要性很可能被不同類別共享,
- 然而,有趣的是,第二個觀察結果是,在更深的深度,每個通道的值變得更加特定于類別,因為不同的類別表現出對特征的區別性值的不同偏好,例如SE_4_6和SE_5_1,
- 這兩個觀察結果與以前作業[23,50]中的發現是一致的,即較低層的特征通常更一般(即在分類的背景關系中與類別無關),而較高層的特征具有更大的特異性,
[23] H. Lee, R. Grosse, R. Ranganath, and A. Y . Ng. Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. InICML, 2009.8
[50] J. Y osinski, J. Clune, Y . Bengio, and H. Lipson. How transferable are features in deep neural networks? InNIPS, 2014.8
- 因此,表示學習受益于SE-block誘導的重新校準,這自適應地促進了特征提取和適應化到需要的程度,
- 最后,我們在網路的最后階段觀察到了一個略有不同的現象,SE_5_2呈現出一種有趣的趨向于飽和狀態,在這種狀態下,大多數激活接近于1,其余的接近于0,在所有激活取值1時,該塊將成為標準殘差塊,在SE53的網路末端(緊隨其后的是在分類器之前的全域池化),類似的模式出現在不同的類上,直到規模上的微小變化(這可以通過分類器進行調整),
- 這表明SE_5_2和SE_5_3在向網路提供重新校準方面不如先前塊重要,這一發現與第四節的實證研究結果是一致的,該調查結果表明,通過去除最后一級的SE塊可以顯著減少總體引數計數,而性能只會有輕微的損失,
結論
在本文中,我們提出了SE塊,這是一種新的結構單元,旨在通過使網路執行動態通道特征重新校準來提高網路的表征能力,大量的實驗證明了SENets的有效性,在多個資料集上實作了最先進的性能,此外,它們還提供了一些對先前體系結構在建模通道特征依賴方面的局限性的見解,我們希望這對其他需要強區分特征的任務是有用的,最后,SE塊所誘導的特征重要性可能有助于網路剪枝壓縮等相關領域的研究,
一些理解
論文認為在Excitation操作中用兩個全連接層比直接用一個全連接層的好處在于:1)具有更多的非線性,可以更好地擬合通道間復雜的相關性;2)極大地減少了引數量和計算量,
原始碼
SE-ResNet代碼:
import torch
from torch import nn
from torchvision.models import resnet
from torchsummary import summary
# 這個模型是將SE模塊加入每個ResBlock中了,還可以只加在模型開頭和結尾,到底是怎么加入模型還是要看實驗結果的
def conv3x3(in_channel, out_channel, stride=1, padding=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=stride, padding=padding, bias=False)
def conv1x1(in_channel, out_channel, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_channel, out_channel, kernel_size=1, stride=stride, bias=False)
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
# https://github.com/moskomule/senet.pytorch/blob/master/senet/se_resnet.py
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size() # x=[b,256,56,56]
y = self.avg_pool(x).view(b, c) # self.avg_pool(x)=>[b,256,1,1] .view=>[b,256]
y = self.fc(y).view(b, c, 1, 1) # self.fc(y)=>[b,256] .view=>[b,256,1,1]
return x * y.expand_as(x) # 復制[b,256,1,1] => [b,256,56,56]
class SE_BasicBlock(nn.Module):
# resnet18 + resnet34(resdual1) 實線殘差結構+虛線殘差結構
expansion = 1 # 殘差結構中主分支的卷積核個數是否發生變化(倍數) 第二個卷積核輸出是否發生變化
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
"""
: params: in_channel=第一個conv的輸入channel
: params: out_channel=第一個conv的輸出channel
: params: stride=中間conv的stride
: params: downsample=None:實線殘差結構/Not None:虛線殘差結構
"""
super(SE_BasicBlock, self).__init__()
self.conv1 = conv3x3(in_channel=in_channel, out_channel=out_channel, stride=stride)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(in_channel=out_channel, out_channel=out_channel)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
self.se = SELayer(out_channel)
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.se(out)
out += identity
out = self.relu(out)
return out
class SE_Bottleneck(nn.Module):
# resnet50+resnet101+resnet152(resdual2) 實線殘差結構+虛線殘差結構
expansion = 4 # 殘差結構中主分支的卷積核個數是否發生變化(倍數) 第三個卷積核輸出是否發生變化
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
"""
: params: in_channel=第一個conv的輸入channel
: params: out_channel=第一個conv的輸出channel
: params: stride=中間conv的stride
resnet50/101/152:conv2_x的所有層s=1 conv3_x/conv4_x/conv5_x的第一層s=2,其他層s=1
: params: downsample=None:實線殘差結構/Not None:虛線殘差結構
"""
super(SE_Bottleneck, self).__init__()
# 1x1卷積一般s=1 p=0 => w、h不變 卷積默認向下取整
self.conv1 = conv1x1(in_channel=in_channel, out_channel=out_channel, stride=1)
self.bn1 = nn.BatchNorm2d(out_channel)
# ----------------------------------------------------------------------------------
# 3x3卷積一般s=2 p=1 => w、h /2(下采樣) 3x3卷積一般s=1 p=1 => w、h不變
self.conv2 = conv3x3(in_channel=out_channel, out_channel=out_channel, stride=stride)
self.bn2 = nn.BatchNorm2d(out_channel)
# ---------------------------------------------------------------------------------
self.conv3 = conv1x1(in_channel=out_channel, out_channel=out_channel * self.expansion, stride=1)
self.bn3 = nn.BatchNorm2d(out_channel * self.expansion)
# ----------------------------------------------------------------------------------
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.se = SELayer(out_channel * self.expansion)
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.se(out)
out += identity
out = self.relu(out)
return out
class SE_ResNet(nn.Module):
def __init__(self, block, blocks_num, num_classes=1000):
"""
: params: block=BasicBlock/Bottleneck
: params: blocks_num=每個layer中殘差結構的個數
: params: num_classes=資料集的分類個數
"""
super(SE_ResNet, self).__init__()
self.in_channel = 64 # in_channel=每一個layer層第一個卷積層的輸出channel/第一個卷積核的數量
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 池化默認向下取整
# 第1個layer的虛線殘差結構只需要改變channel,長、寬不變 所以stride=1
self.layer1 = self._make_layer(block, blocks_num[0], channel=64, stride=1)
# 第2/3/4個layer的虛線殘差結構不僅要改變channel還要將長、寬縮小為原來的一半 所以stride=2
self.layer2 = self._make_layer(block, blocks_num[1], channel=128, stride=2)
self.layer3 = self._make_layer(block, blocks_num[2], channel=256, stride=2)
self.layer4 = self._make_layer(block, blocks_num[3], channel=512, stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # AdaptiveAvgPool2d 自適應池化層 output_size=(1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
# 凱明初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _make_layer(self, block, block_num, channel, stride=1):
"""
: params: block=BasicBlock/Bottleneck 18/34用BasicBlock 50/101/152用Bottleneck
: params: block_num=當前layer中殘差結構的個數
: params: channel=每個convx_x中第一個卷積核的數量 每一個layer的這個引數都是固定的
: params: stride=每個convx_x中第一層中3x3卷積層的stride=每個convx_x中downsample(res)的stride
resnet50/101/152 conv2_x=>s=1 conv3_x/conv4_x/conv5_x=>s=2
"""
downsample = None
# in_channel:每個convx_x中第一層的第一個卷積核的數量
# channel*block.expansion:每一個layer最后一個卷積核的數量
# res50/101/152的conv2/3/4/5_x的in_channel != channel * block.expansion永遠成立,所以第一層必有downsample(虛線殘差結構)
# 但是conv2_x的第一層只改變channel不改變w/h(s=1),而conv3_x/conv4_x/conv5_x的第一層不僅改變channel還改變w/h(s=2下采樣)
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion)
)
layers = []
# 第一層(含虛線殘差結構)加入layers
layers.append(block(self.in_channel, channel, stride=stride, downsample=downsample))
# 經過第一層后channel變了
self.in_channel = channel * block.expansion
# res50/101/152的conv2/3/4/5_x除了第一層有downsample(虛線殘差結構),其他所有層都是實作殘差結構(等差映射)
for _ in range(1, block_num):
layers.append(block(self.in_channel, channel)) # channel在Bottleneck變化:512->128->512
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.maxpool(out)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avgpool(out)
out = torch.flatten(out, 1)
out = self.fc(out)
return out
def se_resnet18(num_classes=5):
return SE_ResNet(SE_BasicBlock, [2, 2, 2, 2], num_classes=num_classes)
def se_resnet34(num_classes=5):
# 預訓練權重 https://download.pytorch.org/models/resnet34-333f7ec4.pth
return SE_ResNet(SE_BasicBlock, [3, 4, 6, 3], num_classes=num_classes)
def se_resnet50(num_classes=5):
# 預訓練權重 https://download.pytorch.org/models/resnet50-19c8e357.pth
return SE_ResNet(SE_Bottleneck, [3, 4, 6, 3], num_classes=num_classes)
def se_resnet101(num_classes=5):
# 預訓練權重 https://download.pytorch.org/models/resnet101-5d3b4d8f.pth
return SE_ResNet(SE_Bottleneck, [3, 4, 23, 3], num_classes=num_classes)
def se_resnet152(num_classes=5):
return SE_ResNet(SE_Bottleneck, [3, 8, 36, 3], num_classes=num_classes)
if __name__ == '__main__':
# 權重測驗
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
model = se_resnet50().to(device)
print(model)
summary(model, (3, 224, 224)) # params:26,033,221 Total Size (MB): 428.90
個人實驗
資料集采用花分類,取其中5類,3700多張圖片,超參跟論文差不多,模型取SEResNet50和ResNet50對比
batch-size設為32,epoch設為50,實驗設備RTX3060 12GB
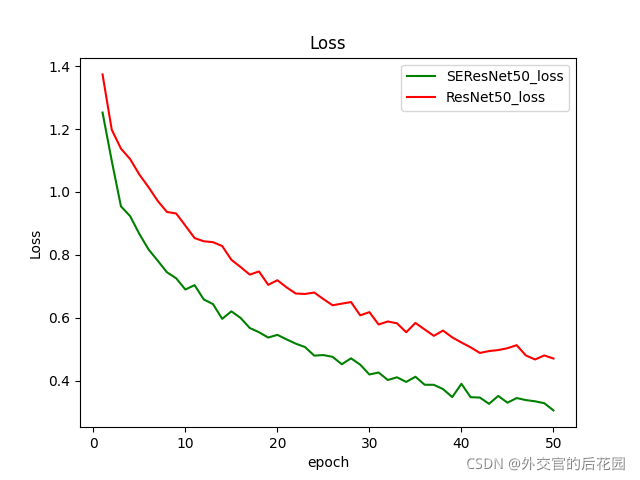
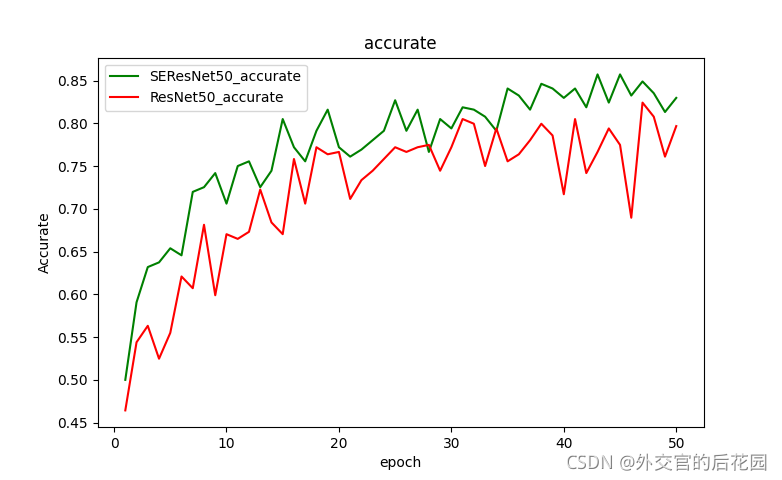
參考
【論文復現】SENet(2019)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/300836.html
標籤:其他
上一篇:openCV簡單加密及解密影像
下一篇:Halcon影像測量