如果你是一名資料分析師,要讓你為你們公司的某類產品尋求市場增長點,你會怎么做呢?
下圖是我用xmind整理的一個分析框架:
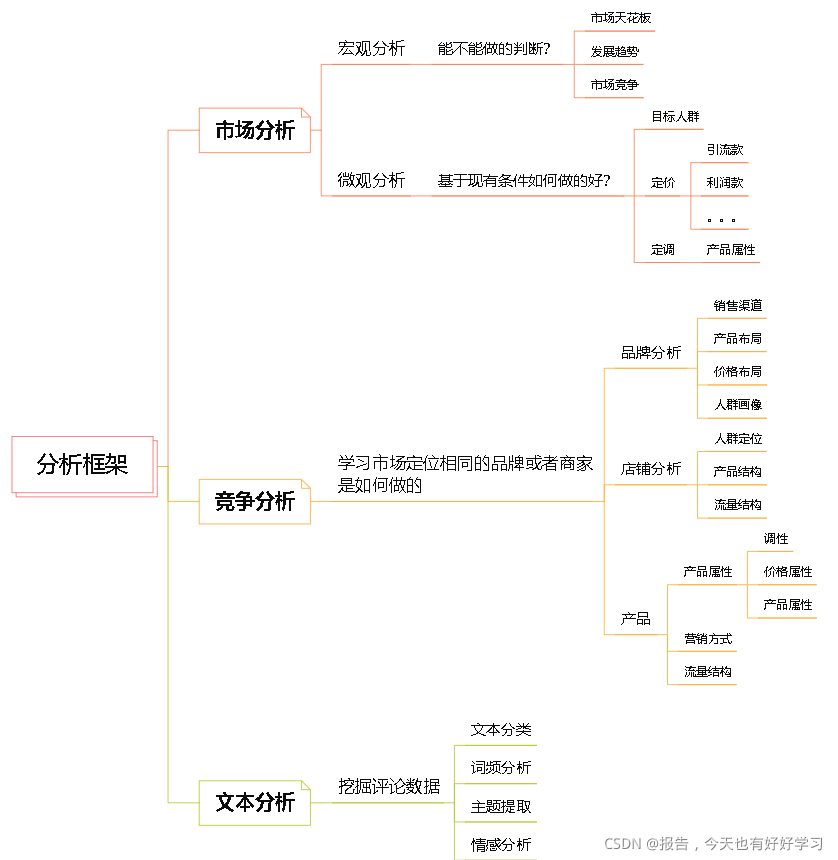
本次專案具體內容大家可以從1.1小節的專案背景開始進行了解,而前言這一部分是我這段時間在學習資料分析這一領域知識的程序中慢慢整理總結出來的,有任何錯誤還請大家不吝賜教,
目錄
- 前言:資料分析思維與業務流程
- 分析流程概述
- 市場分類
- 產品生命周期
- 產品結構-波士頓矩陣(BCG Matrix)
- 處理專案需求的基本思路
- 專案需求例子
- 1 業務背景
- 1.1 專案背景&產品架構
- 1.2 資料說明
- 2 驅蟲市場的潛力分析
- 2.1 分析目的&加載資料
- 2.1.1 分析目的
- 2.1.2 加載資料
- 2.2 清洗&補全資料
- 2.3 市場變化趨勢描述
- 2.4 各市場變化趨勢
- 2.5 各市場占比
- 2.6 各市場年增幅
- 2.7 市場集中度描述(壟斷)
- 2.8 市場的潛力分析-結論
- 2.8.1 加載資料&清洗資料
- 2.8.2 結論
- 3 市場機會點
- 3.1 業務邏輯
- 3.2 產品類別
- 3.3 類別分析
- 3.4 0_50-細分價格市場
- 3.5 其他屬性分析
- 3.6 市場機會點-結論
- 4 競爭分析
- 4.1 分析流程
- 4.2 品類分布-產品類別
- 4.3 品類分布-適用物件
- 4.4 產品結構分析-拜耳
- 4.4.1 拜耳資料
- 4.4.2 產品結構-拜耳-BCG圖
- 4.4.3 產品結構-拜耳-明星
- 4.4.4 產品結構-拜耳-奶牛
- 4.4.5 產品結構-拜耳-問題
- 4.4.6 總結
- 4.5 產品結構分析-安速
- 4.5.1 安速資料
- 4.5.2 產品結構-安速-BCG圖
- 4.5.3 產品結構-安速-明星
- 4.5.4 產品結構-安速-奶牛
- 4.5.5 產品結構-安速-問題
- 4.5.6 總結
- 4.6 產品結構分析-科凌蟲控
- 4.6.1 科凌蟲控資料
- 4.6.2 產品結構-科凌蟲控-BCG圖
- 4.6.3 產品結構-科凌蟲控-明星
- 4.6.4 產品結構-科凌蟲控-奶牛
- 4.6.5 產品結構-科凌蟲控-問題
- 4.6.6 總結
- 4.7 流量結構-業務邏輯
- 4.7.1 概述
- 4.7.2 流量結構-拜耳
- 4.7.3 流量結構-安速
- 4.7.4 流量結構-科凌蟲控
- 5 輿情分析
- 5.1 文本挖掘基本流程
- 5.2 關鍵字提取
- 5.3 總結
- 6 專案總結
前言:資料分析思維與業務流程
前言這一部分是我這段時間在學習資料分析這一領域知識的程序中慢慢整理總結出來的,有任何錯誤還請大家不吝賜教,
分析流程概述
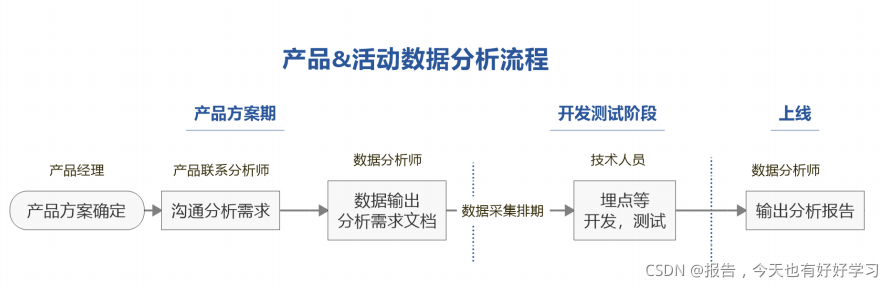
上圖是一些電商平臺的資料分析流程,大家可以看下,
其中這個資料采集排期的話中小公司用的比較多一點,而大公司是有自己的灰度發布系統的(已經埋好點了),
另外,通過建模等分析后輸出分析報告之后,也要再和產品經理反復溝通確定結論,
- 每個環節都有具體的要求,例如需求檔案要求包含:目的、分析思路、預期效果,
- 業務部門出問題和需求,以及對演算法&資料部門輸出報告的理解和應用,
市場分類
評判市場和品牌的發展趨勢和增長情況,從宏觀到微觀,從大市場到細分市場:
- 互聯網產品由關注用戶增量到用戶存量,判斷產品或市場是用戶增量還是存量,只需要判斷有新的需求出現即可:
?○ 增量市場(又叫藍海市場):從無到有,以前關注哪些需求沒有被滿足,快速迭代搶占市場,考慮最多的不是用戶體驗,
??流量=新增客戶,例如:智能手機潮開始時的市場,小米面對的是增量,
?○ 存量市場(又叫紅海市場):從有到優,現在關注如何更好的滿足需求,考慮更多的是用戶體驗(如拼多多就是從紅海市場殺出來的),
??產品價值=新體驗-舊體驗-替換成本,新體驗沒有突破性大幅增加,產品價值很難實作,
??流量=用戶時間(停留時間越久,利益價值越大),
??例如:現在人手一臺智能手機,小米面對存量市場,如何讓需要換手機的用戶換成小米,從有到優, - 創新:想要用產品價值撬動一個用戶,同緯度競爭別家的先發優勢門檻太高,如果別家體量很大,基本可以放棄,
創新可能就是剩下的活路,而面對互聯網的高速發展,線下需求基本都被互聯網化,切入點可能就轉移到細分市場,
例如:微信QQ是社交領域的霸主,陌陌探探在陌生人社交上也分了一杯羹,這些已存在的需求,沒有被充分實作,也算增量市場,
產品生命周期
● 客戶生命周期
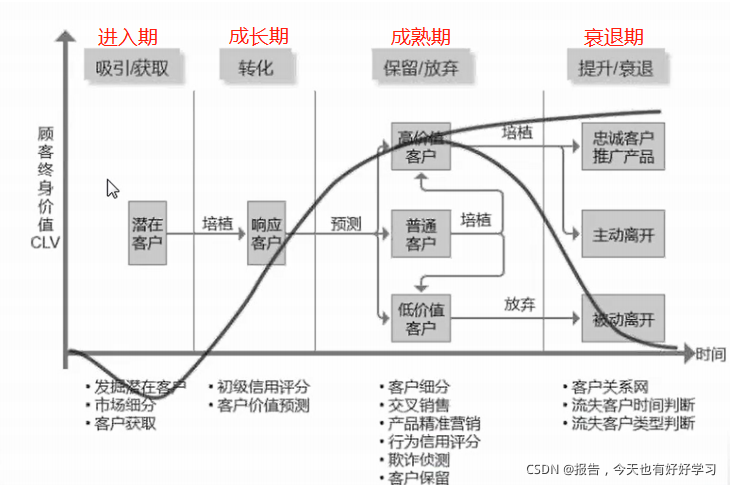
- 初級信用評分(京東的白條、支付寶的花唄)、客戶價值預測可以用分類演算法去實作(像大家常遇到的大資料殺熟這種情況,就是基于分類的結果——富人賣貴,窮人賣的便宜點,兩頭賺)
- 客戶細分可以用聚類演算法實作,交叉銷售可以用關聯規則,產品精準營銷可以考慮用戶畫像(分類),行為信用評分也可以用分類方法實作,欺詐偵測(比方說防止你惡意薅羊毛)可以用例外值分析;
- 客戶關系網、流失客戶時間判斷、流失客戶型別判斷這些也可以用分類演算法實作(流失客戶時間判斷這里會涉及時間序列)
這里大家也可以發現,這里很多的業務都是可以用分類的演算法來實作的,
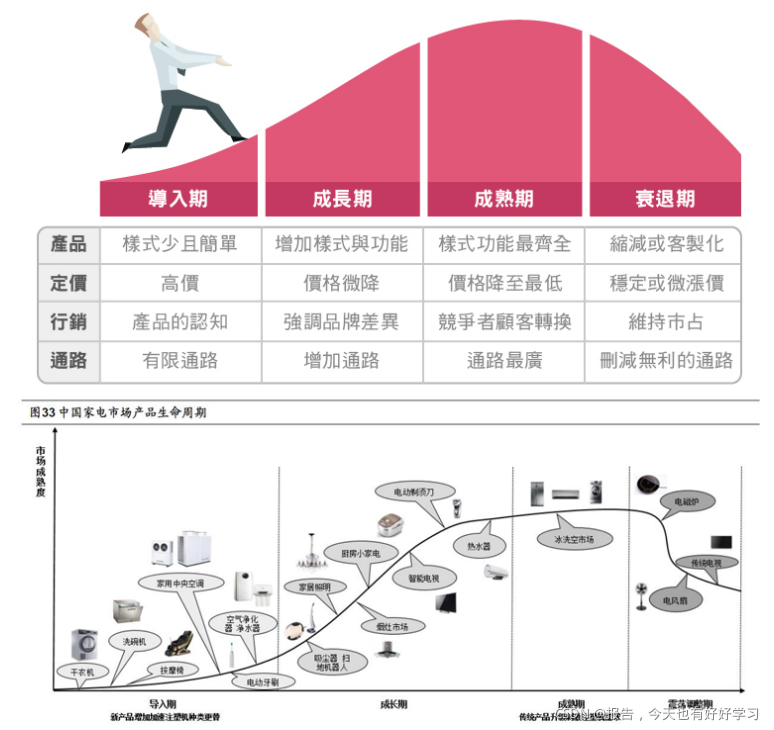
產品結構-波士頓矩陣(BCG Matrix)
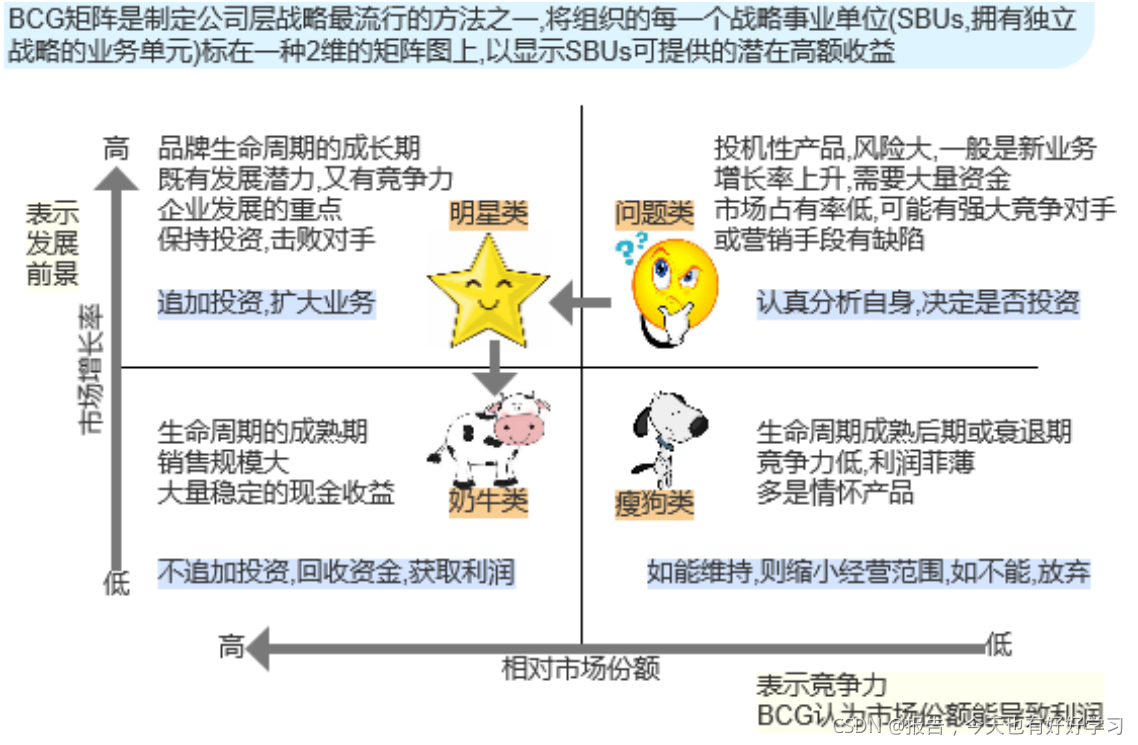
我們來看下上圖的波士頓矩陣,
這里的相對市場份額我們可以理解為銷售額,
我們可以把產品都分成四種型別:問題類(成長期)、明星類(成熟期)、奶牛類(穩定期)、瘦狗類(衰退期),
我們拿到產品的資料后我們就可以判斷產品是屬于哪一類的,判斷是不是有提升空間,
像騰訊旗下的手游王者榮耀就屬于奶牛類產品,當它想要一些穩定的現金流的話,就可以出個活動,相當于擠擠奶,這就是奶牛類產品,
處理專案需求的基本思路
這里我們簡單了解一下就可以了,
- 了解專案公司的背景和對接人員情況,
?○ 公司的產品結構,市場環境,對接人的角色和權利等級等, - 溝通明確實際的專案需求,
?○ 團隊內部理解專案需求,
?○ 和業務方溝通需求:從業務的角度理解需求可能的解決方案,
?○ 優化專案需求,
?○ 和業務核對專案需求, - 根據專案需求梳理分析思路:每一步分析的目標,需要的資料支持,反復優化,
- 確定分析工具和人員配置,進行資料分析,
- 撰寫分析結論和方案
專案需求例子
問題:銷售額下降,怎么辦?
這個問題其實很大,比方說電商類的產品方法有:優化老客戶、擴大流量、提高轉化率等等,這種問題也是需要我們一步步來拆分的,具體操作可以如下:
- 了解涉及專案相關的所有的業務部門的需求,邏輯,問題點
- 拆分:銷售額=流量轉化率客單價
- 待溝通部門:營銷部門(活動),推廣部門(流量),客服,售后,供應鏈
○ 營銷:精準營銷(找到高價值客戶),客戶行為分析(回應效果),組合營銷(購物籃)
○ 推廣:競價排名,買廣告位,點擊付費(需要很強的經驗)
○ 退款和評論分析:優化產品,優化服務質量 - 溝通之前出想法,溝通之后優化,確認專案需求,
- 資料收集:確認每一步需求的資料(可能用到爬蟲),
像上面提到的流量,還可以接著細分成站內流量和站外流量,而站內流量還可以分成全部流量和每個商品流量(詳情頁的訪問),我們需要不斷的拆分問題,直至不能拆分為止,
1 業務背景
那下面我們開始正式介紹我們此次專案的背景啦,
1.1 專案背景&產品架構
接著我介紹一下本次專案的背景與其產品架構,
- 客戶介紹: 拜耳官方旗艦店(拜耳公司,總部位于德國的勒沃庫森,在六大洲的200個地點建有750家生產廠;擁有120,000名員工及350家分支機構,幾乎遍布世界各國,高分子醫藥保健,化工以及農業是公司的四大支柱產業.公司的產品種類超過10000種),
- 客戶需求:尋求市場增長點,
- 產品架構:
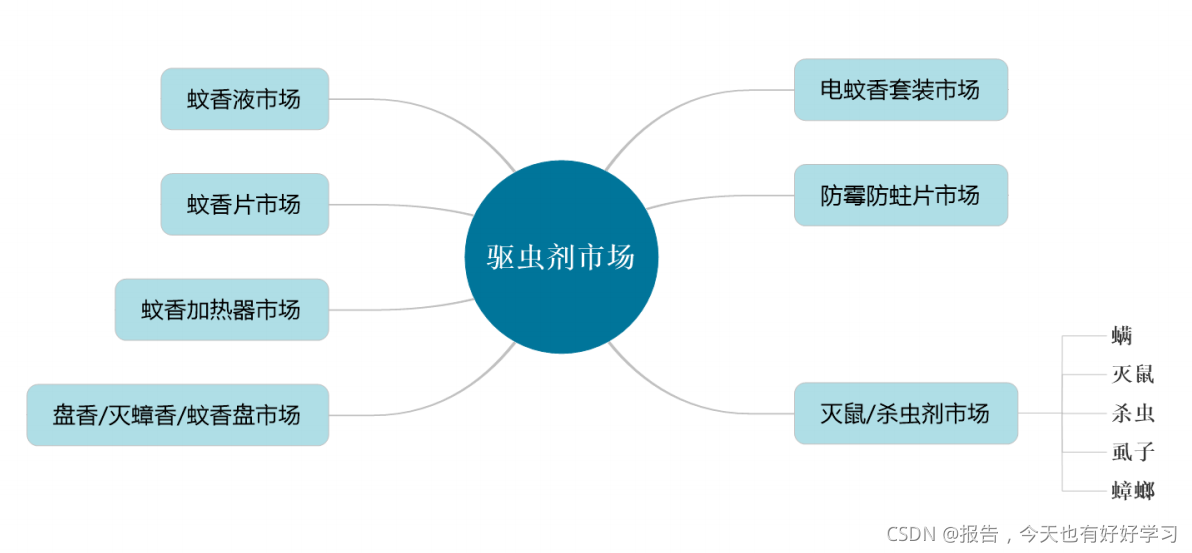
其實上圖也有體現出拆分問題的思想,我們可以把中間這個看成一級市場,左右這7個市場看成二級市場,右下角的可以看出三級市場,
1.2 資料說明

本次專案已有的資料十分齊全,
2 驅蟲市場的潛力分析
老規矩,先導包,設定一下中文編碼,
import glob #讀檔案
import os #設定作業路徑
import pandas as pd
import re #正則運算式
import numpy as np
import datetime as dt #時間包
from sklearn.linear_model import LinearRegression
import seaborn as sns
from matplotlib import pyplot as plt
import jieba #分詞
import jieba.analyse
import imageio #配合做詞云的
from wordcloud import WordCloud #詞云
# 中文編碼
plt.rcParams['font.sans-serif']='simhei'
plt.rcParams['axes.unicode_minus']=False
sns.set_style("darkgrid",{"font.sans-serif":['simhei','Droid Sans Fallback']})
os.chdir('E:\Data-analysis-project\電商文本挖掘\data/') # 作業路徑
os.chdir('./驅蟲劑市場')
2.1 分析目的&加載資料
2.1.1 分析目的
- 分析目的:針對各個子類目市場近三年的交易額資料,以及top100品牌資料(2017年11月到2018年10月),通過描述性分析,在年變化的維度上:
?○ 分析整個市場的總體趨勢
?○ 分析各子類目市場占比及變化趨勢
?○ 分析市場集中度,即是否存在壟斷 - 分析程序:
?○ 讀取各子類目市場近三年交易額資料
?○ 依時間匯總成各子類目在時間線上的交易金額資料
2.1.2 加載資料
- 讀取各子類交易額資料并合并
filenames = glob.glob('*市場近三年交易額.xlsx')
filenames
輸出結果:
['滅鼠殺蟲劑市場近三年交易額.xlsx',
'電蚊香套裝市場近三年交易額.xlsx',
'盤香滅蟑香蚊香盤市場近三年交易額.xlsx',
'蚊香加熱器市場近三年交易額.xlsx',
'蚊香液市場近三年交易額.xlsx',
'蚊香片市場近三年交易額.xlsx',
'防霉防蛀片市場近三年交易額.xlsx']
- 自定義函式讀取單個xlsx檔案:提取檔案名,作為列名,修改時間格式
re.search(r'.*(?=市場)',"盤香滅蟑香蚊香盤市場近三年交易額.xlsx",).group() # 匹配市場之前的wenb
‘盤香滅蟑香蚊香盤’
def load_xlsx(filename):
#抽取子類目的名字
colname = re.search(r'.*(?=市場)',filename).group()
#讀取檔案
df = pd.read_excel(filename)
#修改日期的格式(原本是文本格式)
if df['時間'].dtypes == 'int64':
df['時間'] = pd.to_datetime(df['時間'],unit='D',origin=pd.Timestamp('1899-12-30')) # 系統默認的時間格式
#重命名列名為子類目名
df.rename(columns={df.columns[1]:colname},inplace=True)
#設定時間列作為索引
df = df.set_index('時間')
return df
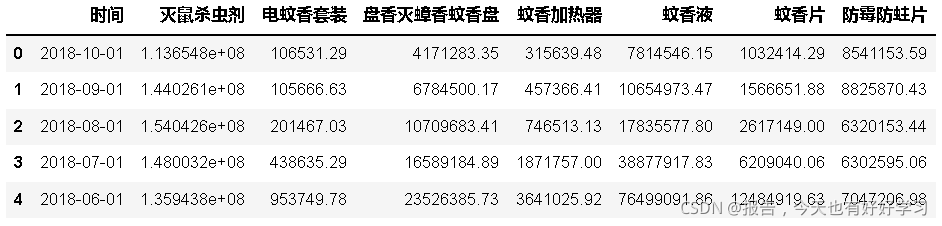
dfs = [load_xlsx(i) for i in filenames]
df = pd.concat(dfs,axis=1).reset_index() # 拼接一下資料
df.head()
2.2 清洗&補全資料
- 由于其中的時間列是從2015年11月到2018年10月,而我們需要的是2016-2018年每月完整的資料(方便從年變化的角度分析產品)
- 這里我們假設:
?○ 每年各月之間沒有明顯規律的周期性變化(近似認為月和月之間的相關性不大)
?○ 每年對應月份的資料是線性變化的(一是因為資料少,二是認為隨著年份的增長,交易額在大環境下是穩步變化的) - 故這里我們可以簡單的用線性回歸預測
即對于每個子類目市場,用15、16、17年的11/12月銷售金額預測18年的對應月份
抽取月份方便建模索引:
month = df['時間'].dt.month
month
輸出結果如下:
0 10
1 9
2 8
3 7
4 6
5 5
6 4
7 3
8 2
9 1
10 12
11 11
12 10
13 9
14 8
15 7
16 6
17 5
18 4
19 3
20 2
21 1
22 12
23 11
24 10
25 9
26 8
27 7
28 6
29 5
30 4
31 3
32 2
33 1
34 12
35 11
Name: 時間, dtype: int64
- 回圈預測2018年11月和12月的銷售額
for i in [11,12]:
# 抽取對月份的資料
dm = df[month == i] #2015.11 2016.11 2017.11
# 訓練x是年份
xtrain = np.array(dm['時間'].dt.year).reshape(-1,1)
# 測驗y是新增的行,對應的日期
ytest = [pd.datetime(2018,i,1)]
for j in range(1,len(dm.columns)):
# 訓練y是指定的列
ytrain = np.array(dm.iloc[:,j]).reshape(-1,1)
# 回歸建模
lm = LinearRegression().fit(xtrain,ytrain)
# 預測當測驗x為2018時銷售額 yhat
yhat = lm.predict(np.array([2018]).reshape(-1,1))
ytest.append(round(yhat[0][0],2))
#給預測結果賦值對應的列名
newrow = pd.DataFrame([dict(zip(df.columns,ytest))])
#預測結果行加在資料前,所以說用newrow來append,不是df來append
df = newrow.append(df)
df.head()
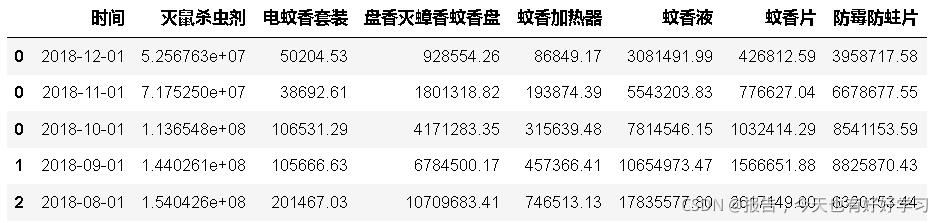
- 去掉原始索引
df.reset_index(drop=True,inplace=True)
# 上圖中的索引是0 0 1 ,用drop=True去掉,而inplace=True的作用是不創建新的物件,直接對原始物件進行修改;
- 去掉15年的資料
df = df[df['時間'].dt.year != 2015]
df.tail()
接下來我們可以進行以下操作:
- 分析整個市場的總體趨勢
- 分析各子類市場銷售額占比及變化趨勢
- 分析市場集中度,是否存在壟斷
2.3 市場變化趨勢描述
- 每行所有市場的交易金額總和生成新列
- 抽取年份生成新列
df['colsums'] = df.sum(1) #交易金額總和列
df.head()
df.insert(1,'year',df['時間'].dt.year) #年份列
df.head()
byyear = df.groupby('year').sum().reset_index()
byyear

sns.relplot('year','colsums',kind='line',marker='o',data=byyear,height=4)
plt.title('近三年的市場趨勢')
plt.xticks(byyear.year,rotation=45) # rotation是旋轉角度
plt.xlabel('年份')
plt.ylabel('總交易額')
plt.show()
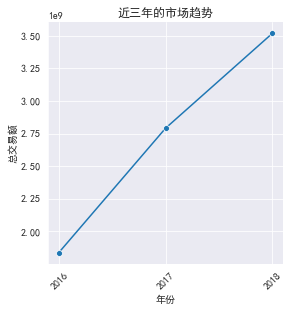
可以看出:近三年呈增長趨勢,整個市場傾向于成長期和成熟期,
2.4 各市場變化趨勢
查看各類目市場三年內銷售額總和的變化趨勢:
# 圖形大小
f,ax = plt.subplots(figsize=(10,6)) # f代表整個影像,ax代表坐標軸和畫的圖,保存影像時需要用到fig
#dashes=False 不區分線型
sns.lineplot(data=byyear.set_index('year').iloc[:,:-1],dashes=False,marker='^')
plt.title('近三年各類市場銷售趨勢')
plt.xticks(byyear.year,rotation=45)
#在指定位置加文本
for a,b in zip(byyear.year,byyear['滅鼠殺蟲劑']):
plt.text(a,b,'%.3e'% b, ha='center',va='bottom',size=12)
plt.xlabel('年份')
plt.ylabel('總交易額')
plt.show()
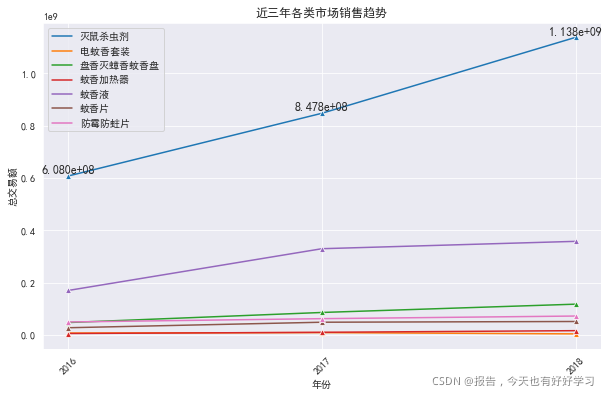
直觀的看滅鼠殺蟲劑和蚊香液都有較大的機會,
- 查看滅鼠殺蟲劑近三年的增長趨勢
g = sns.FacetGrid(byyear,height=5)
g.map(sns.barplot,'year','滅鼠殺蟲劑',color='wheat')
g.map(sns.pointplot,'year','滅鼠殺蟲劑')
for a,b in zip(range(len(byyear)),byyear['滅鼠殺蟲劑']):
plt.text(a,b,'%.3e'% b, ha='center',va='bottom',size=12)
plt.xlabel('年份')
plt.ylabel('滅鼠殺蟲劑近三年的增長趨勢')
plt.xticks(rotation=45)
plt.show()
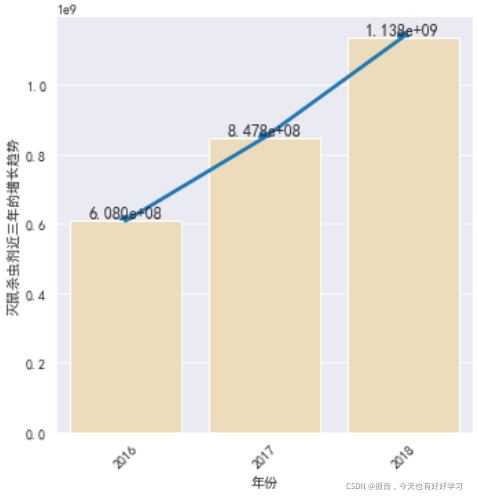
2.5 各市場占比
查看各類目市場三年內銷售額總和的占比:
#計算每年每個子市場的比例
byyear_per = byyear.iloc[:,1:-1].div(byyear.colsums,axis=0)
byyear_per.index = byyear.year
byyear_per
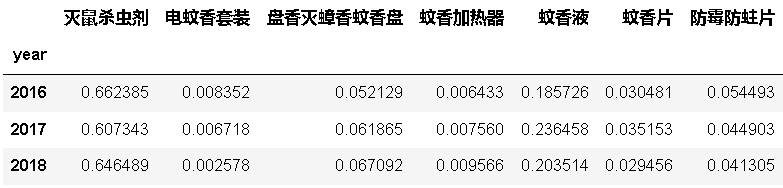
#stacked=True
byyear_per.plot(kind='bar',stacked=True,figsize=(10,8),colormap='tab10')
for a,b in zip(range(len(byyear_per)),byyear_per['滅鼠殺蟲劑']):
plt.text(a,b/2,f'{b*100:.2f}%', ha='center',va='bottom',size=12,color='white')
plt.xlabel('年份')
plt.ylabel('總交易額占比')
plt.title('近三年各子類市場銷量占比')
plt.show()
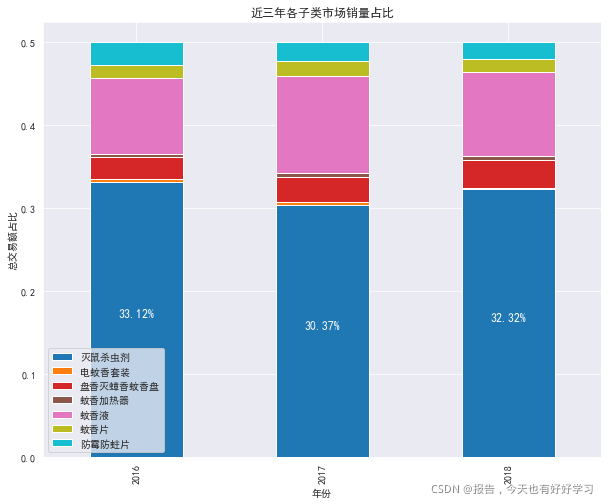
可見滅鼠殺蟲劑和蚊香液可進一步擴展,就需要與甲方業務人員進一步溝通,
這里我們假設溝通后我們重點關注的是滅鼠殺蟲劑,
2.6 各市場年增幅
byyear

#拿到中間7列
byyear0 = byyear.iloc[:,1:-1]
byyear0.diff()#一階差分 17-16 18-17

#計算年增幅
byyear0 = byyear.iloc[:,1:-1]
byyear_diff = byyear0.diff().iloc[1:,:].reset_index(drop=True)/byyear0.iloc[:2,:]
byyear_diff.index = ['16-17','17-18']
byyear_diff

#作圖查看
f,ax = plt.subplots(figsize=(10,8))
sns.lineplot(data=byyear_diff,dashes=False)
plt.title('近三年各子類市場銷量年增幅')
plt.xlabel('年份')
plt.ylabel('總交易額年增幅')
plt.show()
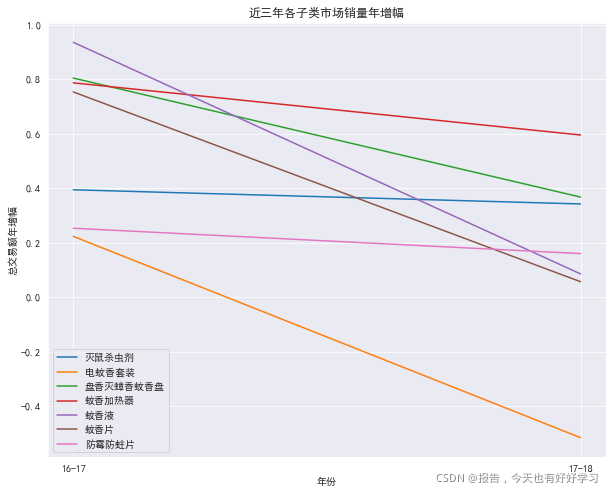
可見除了滅鼠殺蟲劑和蚊香液增幅比較穩定,其它都有下降甚至變負,
2.7 市場集中度描述(壟斷)
這里我們先介紹一下什么是壟斷,以及常見的評估指標有哪些:
- 壟斷程度,或者說市場勢力的重要量化指標是行業集中度,
- 常見的指標有行業集中率:CRn指數,赫芬達爾指數(Herfindahl-Hirschman Index,縮寫HHI),
- 公式:
H
=
∑
i
=
1
N
s
i
2
)
i
H=\sum^N_{i=1}s^2_i)i
H=∑i=1N?si2?)i(有些地方s前乘100或結果乘10000),N:公司數量; 第i個公司的市場份額,
例子:六家最大的公司市場上生產90%的商品,剩余的10%由10個規模相等的生產者分配,六家公司中,最大的公司生產80%,其余各2%, H H I = 0. 8 2 + 5 ? 0.0 2 2 + 10 ? 0.0 1 2 = 0.643 ( 64.2 HHI=0.8^2+5*0.02^2+10*0.01^2=0.643(64.2%) HHI=0.82+5?0.022+10?0.012=0.643(64.2 - 指數范圍從1/N到1,指數的導數表示該行業中“等效”的公司數量,上例的市場結構等同于擁有1.55521加相同規模的公司,
范圍:[1/N,‘高度競爭行業’,0.01],(0.01,‘不集中的行業’,0.15],(0.15,‘中等集中’,0.25], (0.25,‘高度集中’,1] - HHI的局限性:
?○ 行業細分:由于產品分類細化,類間差異大,銷售量資料就不一定能準確判斷行業集中度,(例如某個大行業中各大公司市場份額相同,但業務不同,仍可能造成壟斷),
?○ 地理范圍:從總的市場份額來看占比一致,但是各個公司可能在當地造成壟斷,
?○ 長尾現象:無限小眾市場抗衡大市場(看具體行業), - 分析流程:使用top100品牌資料,通過交易指數反映銷售額從而得到市場占有率,描述各品牌市場份額,計算HHI指標,
那接下來我們就來實作一下,
df1 = pd.read_excel('top100品牌資料.xlsx')
df1.isna().mean()
輸出結果如下:
品牌 0.0
行業排名 0.0
交易指數 0.0
交易增長幅度 0.0
支付轉化指數 0.0
操作 0.0
dtype: float64
df1.head()
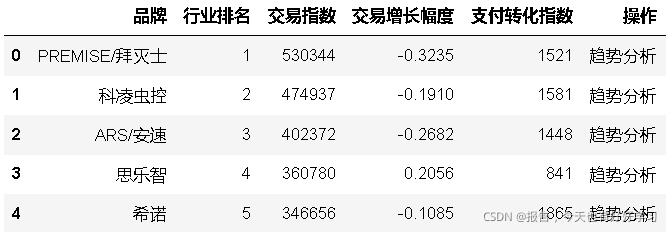
df1.describe(include='all')
- 生成交易指數占比,用來描述市場份額
df1['交易指數占比'] = df1['交易指數']/df1['交易指數'].sum()
df1['交易指數占比']
輸出結果如下:
0 0.035998
1 0.032237
2 0.027311
3 0.024488
4 0.023530
...
95 0.004603
96 0.004492
97 0.004465
98 0.004447
99 0.004425
Name: 交易指數占比, Length: 100, dtype: float64
df1.plot(x='品牌',y='交易指數占比',kind='bar',figsize=(15,5))
plt.show()
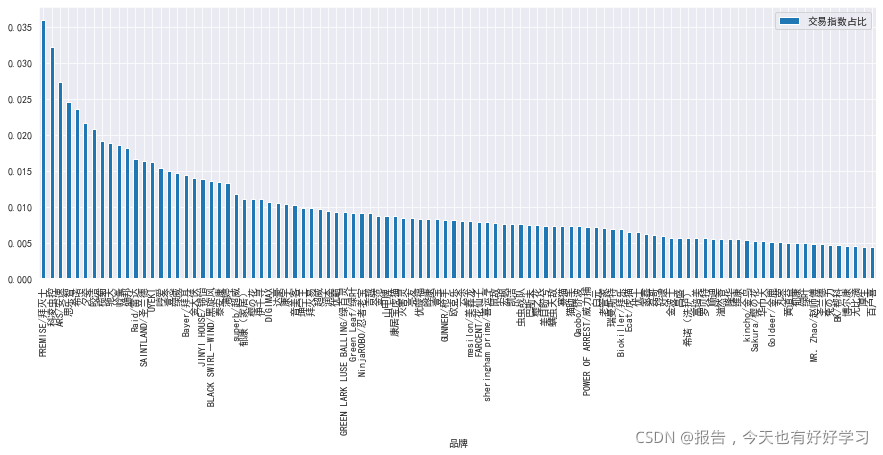
## HHI
HHI = sum(df1['交易指數占比']**2)
HHI
0.013546334007208914
計算得到:驅蟲市場HHI指數:0.013546(或135.46),等效公司數:73.82,
2.8 市場的潛力分析-結論
os.chdir('..')#回傳到上一級目錄
os.chdir('./滅鼠殺蟲劑細分市場')#進入滅鼠殺蟲劑細分市場檔案夾
2.8.1 加載資料&清洗資料
filename1 = glob.glob('*.xlsx')
dfs1 = [pd.read_excel(i) for i in filename1]
df2 = pd.concat(dfs1,sort=False)
df2.info()
輸出結果如下:
<class 'pandas.core.frame.DataFrame'>
Int64Index: 6556 entries, 0 to 1742
Columns: 229 entries, 類別 to 產品名
dtypes: float64(129), int64(5), object(95)
memory usage: 11.7+ MB
#查看缺失值
df2.isna().mean()
輸出結果如下:
類別 0.0
時間 0.0
頁碼 0.0
排名 0.0
鏈接 0.0
...
寶貝成份 1.0
規格: 1.0
樟腦 1.0
包裝 1.0
產品名 1.0
Length: 229, dtype: float64
- 如果一個特征缺失值占比超過98% 從整個資料角度來講沒有意義則洗掉
ind1 = df2.isna().mean()> 0.98
sum(ind1)
191
df20 = df2.loc[:,~ind1] #洗掉缺失值> 0.98的
df20.isna().mean()
輸出結果如下:
類別 0.000000
時間 0.000000
頁碼 0.000000
排名 0.000000
鏈接 0.000000
主圖鏈接 0.000000
主圖視頻鏈接 0.746797
寶貝標題 0.000000
寶貝ID 0.000000
銷量(人數) 0.000000
售價 0.000000
預估銷售額 0.005491
運費 0.000000
評價人數 0.022880
收藏人數 0.000000
下架時間 0.000000
類目 0.000000
地域 0.406955
旺旺 0.000000
店鋪型別 0.000000
品牌 0.095333
型號 0.423276
凈含量 0.421599
適用物件 0.279896
物理形態 0.286303
藥品登記號 0.927090
產品名稱 0.796980
農藥登記證號 0.873093
生產企業 0.888957
農藥生產許可證/批準文號 0.889262
農藥產品標準證號 0.889262
農藥名稱 0.889262
劑型 0.882093
農藥成分 0.885754
有效成分總含量 0.889262
毒性 0.873093
防治物件 0.889262
農藥型別 0.973612
dtype: float64
- 特征值完全一致的進行洗掉
ind2 = np.array([len(df20[i].unique()) == 1 for i in df20.columns])
df21 = df20.loc[:,~ind2]
df21.isna().mean()
輸出結果如下:
類別 0.000000
時間 0.000000
頁碼 0.000000
排名 0.000000
鏈接 0.000000
主圖鏈接 0.000000
主圖視頻鏈接 0.746797
寶貝標題 0.000000
寶貝ID 0.000000
銷量(人數) 0.000000
售價 0.000000
預估銷售額 0.005491
運費 0.000000
評價人數 0.022880
收藏人數 0.000000
下架時間 0.000000
地域 0.406955
旺旺 0.000000
店鋪型別 0.000000
品牌 0.095333
型號 0.423276
凈含量 0.421599
適用物件 0.279896
物理形態 0.286303
藥品登記號 0.927090
產品名稱 0.796980
農藥登記證號 0.873093
生產企業 0.888957
農藥生產許可證/批準文號 0.889262
農藥產品標準證號 0.889262
農藥名稱 0.889262
劑型 0.882093
農藥成分 0.885754
有效成分總含量 0.889262
毒性 0.873093
防治物件 0.889262
農藥型別 0.973612
dtype: float64
#洗掉藥品登記號 之后的屬性
ind3 = df21.columns.get_loc('藥品登記號')
df22 = df21.iloc[:,:ind3]
df22.isna().mean()
輸出結果如下:
類別 0.000000
時間 0.000000
頁碼 0.000000
排名 0.000000
鏈接 0.000000
主圖鏈接 0.000000
主圖視頻鏈接 0.746797
寶貝標題 0.000000
寶貝ID 0.000000
銷量(人數) 0.000000
售價 0.000000
預估銷售額 0.005491
運費 0.000000
評價人數 0.022880
收藏人數 0.000000
下架時間 0.000000
地域 0.406955
旺旺 0.000000
店鋪型別 0.000000
品牌 0.095333
型號 0.423276
凈含量 0.421599
適用物件 0.279896
物理形態 0.286303
dtype: float64
unless = ["時間","鏈接","主圖鏈接","主圖視頻鏈接","寶貝標題","運費" ,"下架時間","旺旺" ,"頁碼","排名"]
unless
[‘時間’, ‘鏈接’, ‘主圖鏈接’, ‘主圖視頻鏈接’, ‘寶貝標題’, ‘運費’, ‘下架時間’, ‘旺旺’, ‘頁碼’, ‘排名’]
df23 = df22.drop(columns=unless)
df23.isna().mean()
輸出結果如下:
類別 0.000000
寶貝ID 0.000000
銷量(人數) 0.000000
售價 0.000000
預估銷售額 0.005491
評價人數 0.022880
收藏人數 0.000000
地域 0.406955
店鋪型別 0.000000
品牌 0.095333
型號 0.423276
凈含量 0.421599
適用物件 0.279896
物理形態 0.286303
dtype: float64
df23.dtypes
輸出結果如下:
類別 object
寶貝ID int64
銷量(人數) int64
售價 float64
預估銷售額 float64
評價人數 float64
收藏人數 int64
地域 object
店鋪型別 object
品牌 object
型號 object
凈含量 object
適用物件 object
物理形態 object
dtype: object
df23 = df23.astype({'寶貝ID':'object'}) #將寶貝ID轉成object
df23.reset_index(drop=True,inplace=True)
df23.describe()
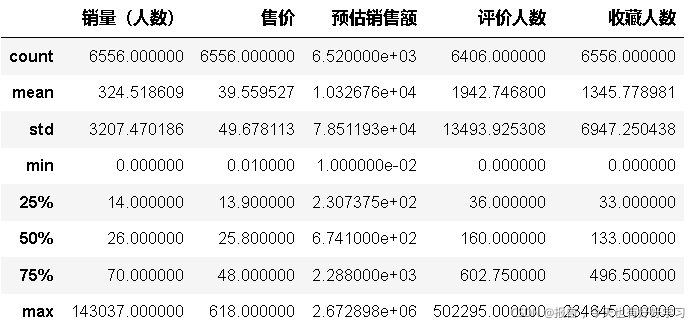
df23.head()
2.8.2 結論
通過上述內容,我們可以得到以下結論:
- 整體驅蟲市場處于快速增長階段,趨向于成長期到成熟期;
- 滅鼠殺蟲劑市場份額較大(大于60%),約是第二名蚊香液的二倍,市場增長率接近40%,可以認為是明星產品類目,需要持續投資和重點關注;
- 驅蟲市場不存在壟斷,結構不集中,競爭相對激烈,即沒有明顯的來自大公司的壓力,
3 市場機會點
3.1 業務邏輯
- 子類目市場確定后(滅鼠殺蟲劑市場),確定市場中最受歡迎的產品類別–>細分價格段–>屬性進一步分析:
什么樣的價格作為主市場,什么樣的商品符合大眾口味, - 不同用途的商品定位:
?○ 引流商品:價格低,利潤空間幾乎沒有,目的是為了引流,
???■ 獲取流量的方式有免費和付費兩種,免費流量看緣分(lian),控制付費流量成本,即是對流量精準度的要求,即精準營銷利潤商品:價格合理,只要的盈利來源,
?○ 利潤商品:價格合理,主要的盈利來源,
?○ 品牌商品:價格偏高,門面商品或奢侈品, - 商品布局時要考慮的問題:價格、產品特征、用戶喜好度、商品需求等,
3.2 產品類別
- 使用滅鼠殺蟲劑細分市場資料(截止到2018年11月22日30天的交易資料):
?○ 讀取五個檔案并且合并
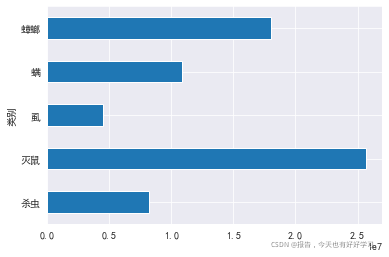
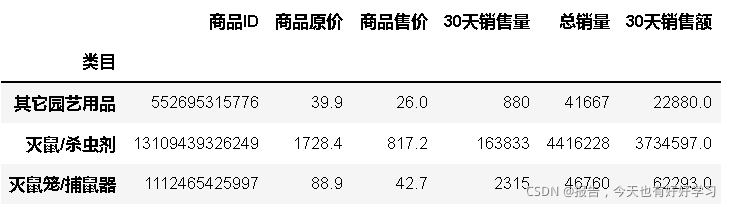
?○ 清洗:去掉大量缺失值的列,去掉單一值的列,去掉邏輯上不可用的列,如:“時間”,“鏈接”,“主圖鏈接”,“主圖視頻鏈接”,“頁碼”,“排名”,“寶貝標題”,“運費”,“下架時間”,“旺旺” , - 查看各產品’類別’總的’預估銷售額’的分布,以此表示市場分布情況,
byclass = df23['預估銷售額'].groupby(df23['類別']).sum()
byclass
類別
殺蟲 8207628.10
滅鼠 25686011.99
虱 4512886.01
螨 10886752.88
蟑螂 18037223.68
Name: 預估銷售額, dtype: float64
byclass.plot.barh()
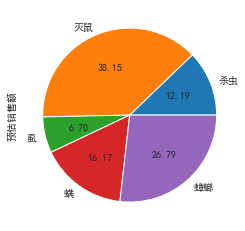
byclass.plot.pie(autopct='%.2f')
import plotly.graph_objects as go #互動圖形 類似于PowerBI
fig = go.Figure(data=[go.Pie(labels=byclass.index,values=byclass.values)])
fig.show()
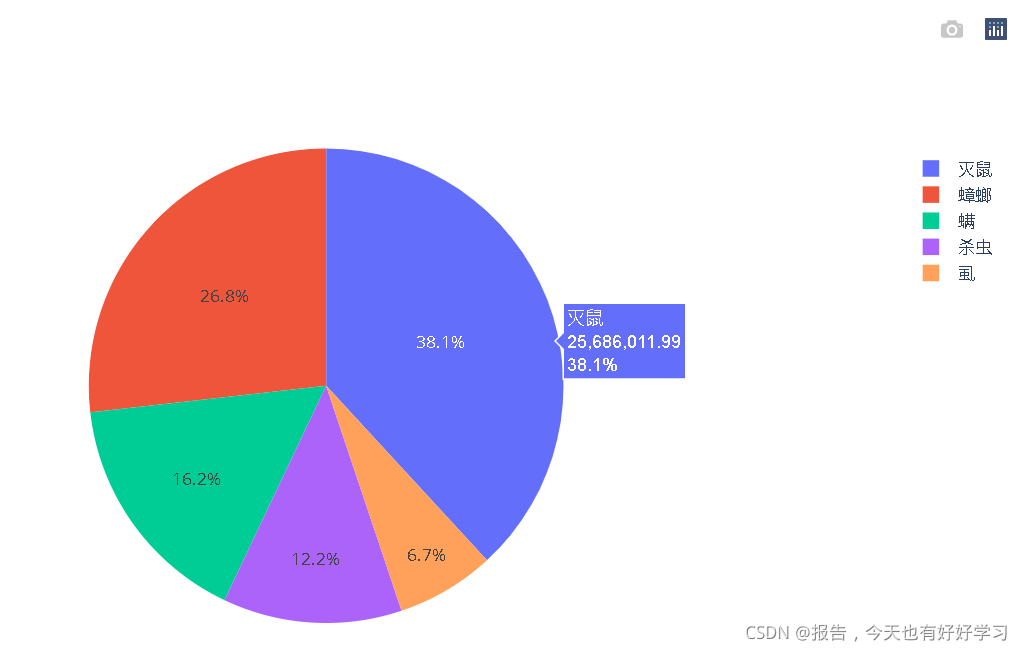
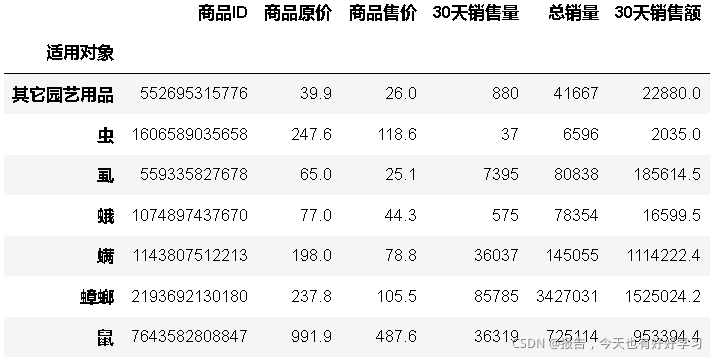
- 可以看出重點需要研究的市場是滅鼠和蟑螂,這里我們選擇滅鼠,
3.3 類別分析
- 選擇滅鼠資料進一步分析–>依據’售價’進行價格劃分,得到若干的價格區間,
df24 = df23[df23['類別']== '滅鼠']
df24
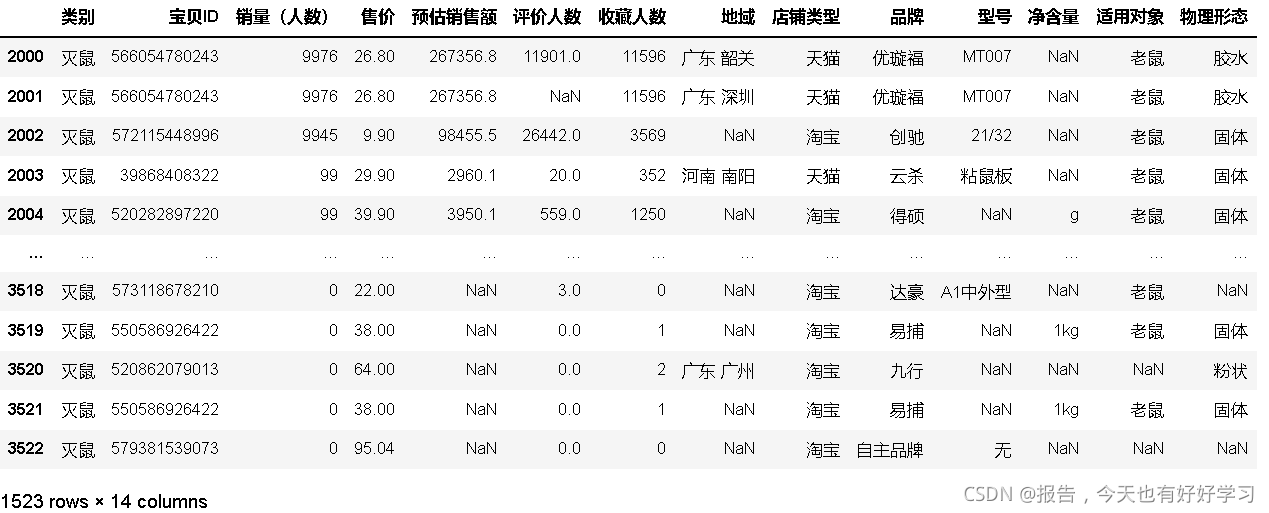
df24['售價'].describe()
輸出結果如下:
count 1523.000000
mean 49.018910
std 69.762057
min 0.010000
25% 15.800000
50% 27.700000
75% 52.600000
max 498.000000
Name: 售價, dtype: float64
df24['售價'].plot.hist()
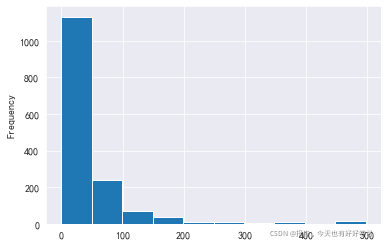
#自定義分箱 銷售額 將連續型變數轉成分型別變數
bins = [0,50,100,150,200,250,300,500] #分界線
labels = ['0_50','50_100','100_150','150_200','200_250','250_300','300_500']#箱子的標題
#pd.cut (0,50] ---> [0,50]
df24['價格區間'] = pd.cut(df24['售價'],bins,labels=labels,include_lowest=True)
df24['價格區間'].value_counts()
輸出結果如下:
0_50 1138
50_100 242
100_150 62
150_200 35
300_500 28
250_300 9
200_250 9
Name: 價格區間, dtype: int64
df24
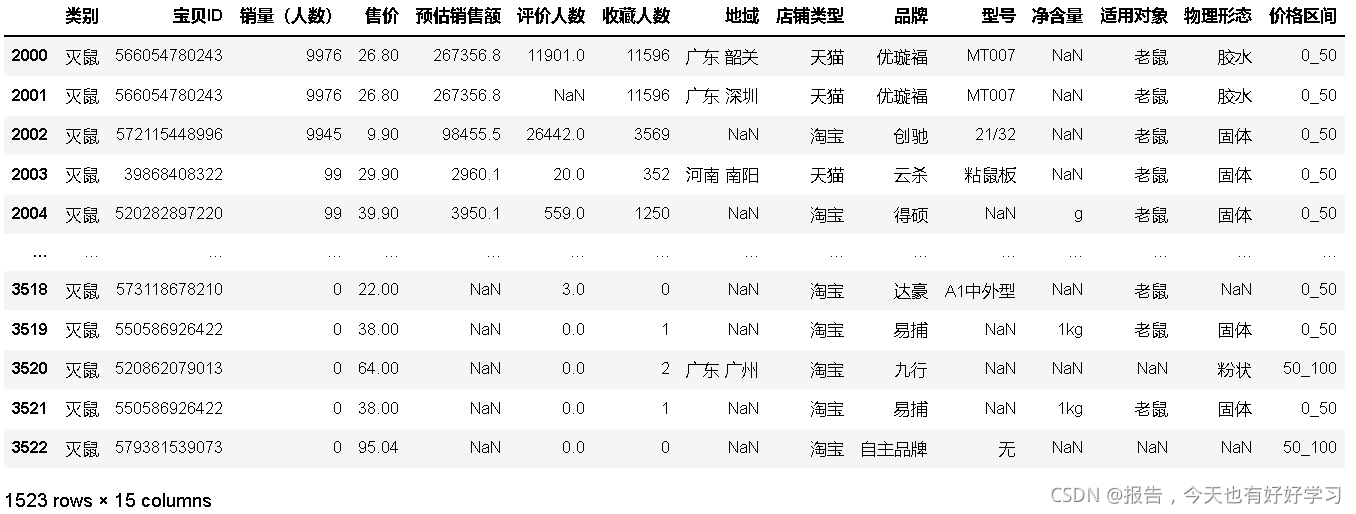
- 每個價格區間計算:預估銷售額(總和),銷售額占比,寶貝數(不同’寶貝ID’數),寶貝數占比,單寶貝平均銷售額(不同寶貝的平均預估銷售額,可以理解為競爭的反面,單寶貝平 均銷售額越高,競爭越低,單寶貝銷售額高才有的分),相對競爭度(由前一項套入線性變換 得到0表示類目中最小競爭,1表示最大),
#分類的依據----價格區間
by = '價格區間'
df = df24
#根據價格區間求和
df.groupby(by).sum()
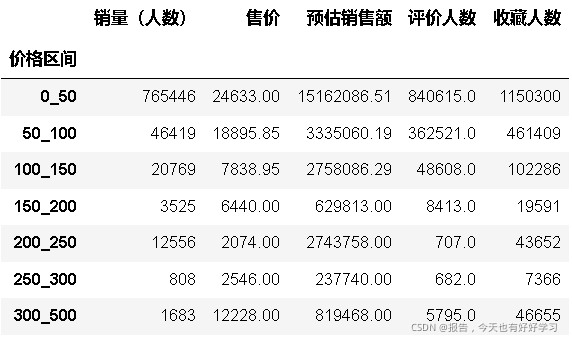
#把預估銷售額列抽出來
byc = pd.DataFrame(df.groupby(by).sum().loc[:,['預估銷售額']])
byc
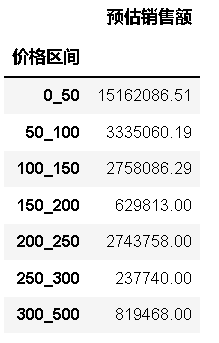
#銷售額占比、寶貝數、寶貝數的占比、單個寶貝的平均銷售額
byc['銷售額占比'] = byc['預估銷售額'] / byc['預估銷售額'].sum()
byc['寶貝數'] = df.groupby(by).nunique()['寶貝ID']
byc['寶貝數占比'] = byc['寶貝數'] / byc['寶貝數'].sum()
byc['單寶貝平均銷售額'] = byc['預估銷售額']/byc['寶貝數']
byc
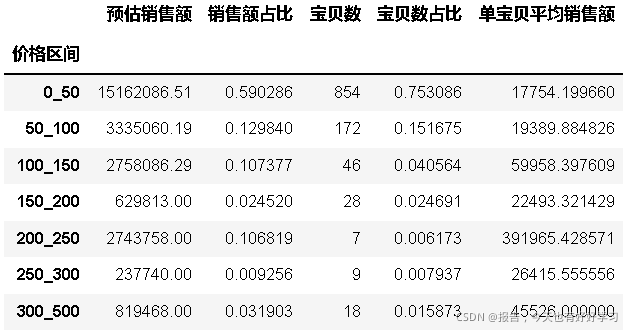
- 競爭度(單寶貝平均銷售額的反面)
- 單寶貝平均銷售額越大,競爭越低,越小,競爭越大,
byc['相對競爭度'] = 1- (byc['單寶貝平均銷售額']-byc['單寶貝平均銷售額'].min())/(
byc['單寶貝平均銷售額'].max()-byc['單寶貝平均銷售額'].min())
byc
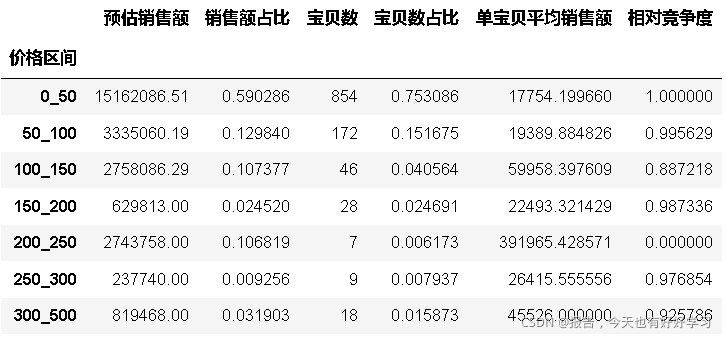
# 自定義函式
def byfun(df,by,sort='單寶貝平均銷售額'):
byc = pd.DataFrame(df.groupby(by).sum().loc[:,['預估銷售額']])
#銷售額占比、寶貝數、寶貝數的占比、單個寶貝的平均銷售額
byc['銷售額占比'] = byc['預估銷售額'] / byc['預估銷售額'].sum()
byc['寶貝數'] = df.groupby(by).nunique()['寶貝ID']
byc['寶貝數占比'] = byc['寶貝數'] / byc['寶貝數'].sum()
byc['單寶貝平均銷售額'] = byc['預估銷售額']/byc['寶貝數']
byc['相對競爭度'] = 1- (byc['單寶貝平均銷售額']-byc['單寶貝平均銷售額'].min())/(
byc['單寶貝平均銷售額'].max()-byc['單寶貝平均銷售額'].min())
if sort:
byc.sort_values(sort,ascending=False,inplace=True)
return byc
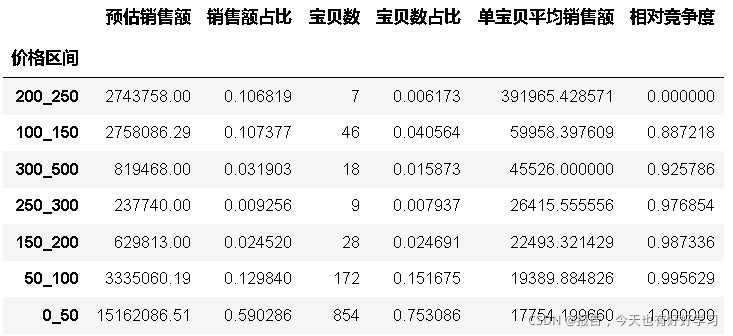
byprices = byfun(df24,'價格區間')
byprices
def mcplot(bydf,figsize=(10,4)):
ax = bydf.plot(y='相對競爭度',linestyle='-',marker='o',figsize=figsize)
bydf.plot(y='銷售額占比',kind='bar',alpha=0.8,color='wheat',ax=ax)
plt.show()
mcplot(byprices)
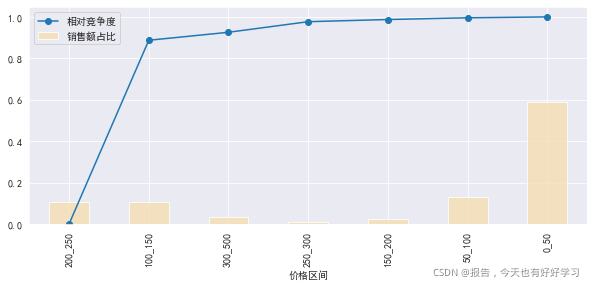
結果依單寶貝銷售額降序,即依競爭度升序,這里銷售額占比可以理解為市場份額,
可見0-50容量大,競爭大,大容量市場(對比的是50-100,容量小,競爭稍小)
200-250,競爭小,做高價市場的優先選擇,屬于機會點,
可見我們喜歡的類目是:市場份額高(表示更適合大眾),相對競爭度低(沒人搶),也就是找到悶聲發大財的那些個分類去分蛋糕,
3.4 0_50-細分價格市場
- 這里我們選擇容量最大的0-50細分市場進一步分析
df25 = df24[df24['價格區間']=='0_50']
df25['售價'].plot.hist()
- 再一次細分得到新的更小的價格區間,計算每個區間的指標
#自定義分箱 銷售額 將連續型變數轉成分型別變數
bins_01 = [0,10,20,30,40,50] #分界線
labels_01 = ['0_10','10_20','20_30','30_40','40_25']#箱子的標題
#pd.cut (0,50] ---> [0,50]
df25['價格子區間'] = pd.cut(df25['售價'],bins_01,labels=labels_01,include_lowest=True)
byprices_01 = byfun(df25,'價格子區間')
byprices_01
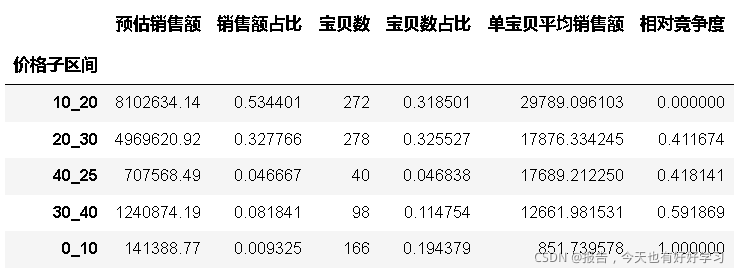
mcplot(byprices_01)
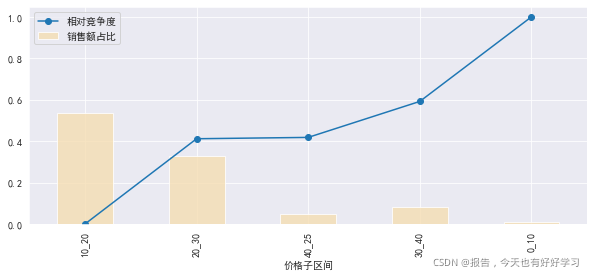
可見10-20競爭度低,容量大,優選,20-30也不錯,
200-250細分市場也是同樣的分析思路,
3.5 其他屬性分析
df25.head()
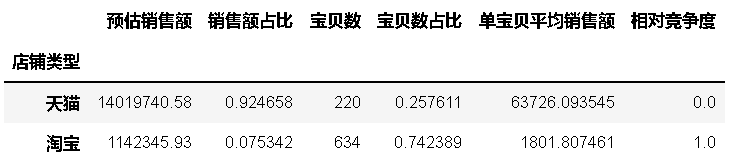
- 店鋪型別
bystore = byfun(df25,'店鋪型別')
bystore
mcplot(bystore)
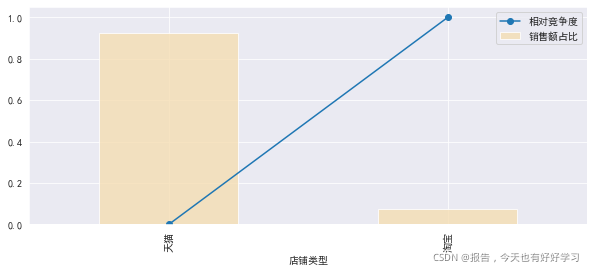
可見天貓各個方面都優于淘寶,
- 型號
bytype = byfun(df25,'型號')
#預估銷售額 前5%的型號
bytype1 = bytype[bytype['預估銷售額']>=bytype['預估銷售額'].quantile(0.95)]
bytype1
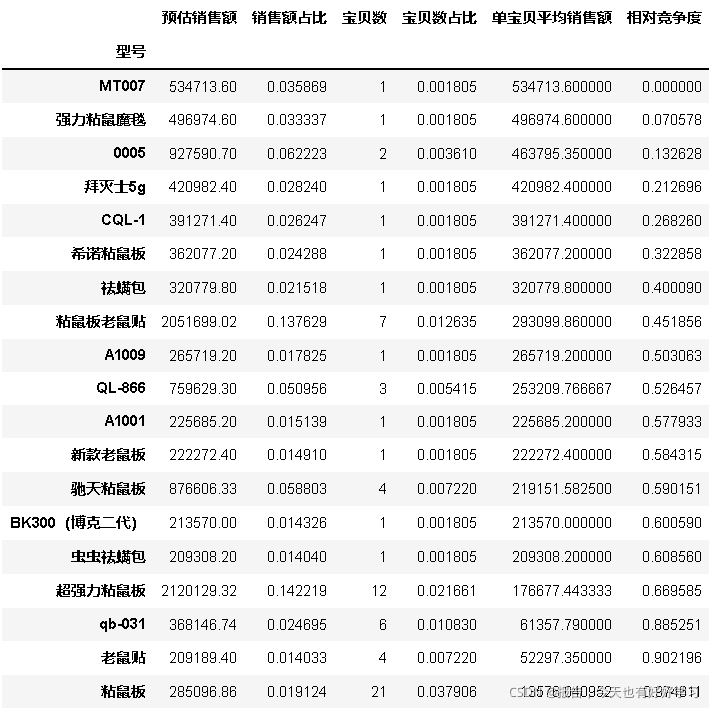
mcplot(bytype1)
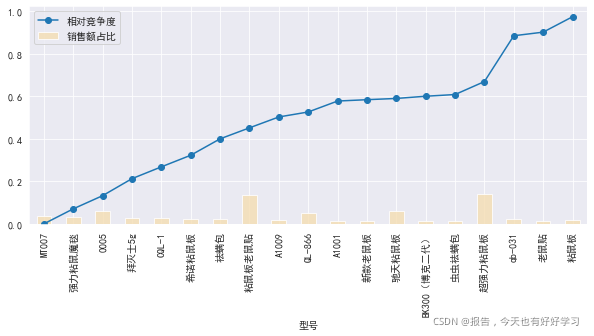
可見雖然粘鼠板市場份額普遍較高,但是0005、MT007在競爭度上有明顯的優勢,
- 物理形態
byshape = byfun(df25,'物理形態')
byshape
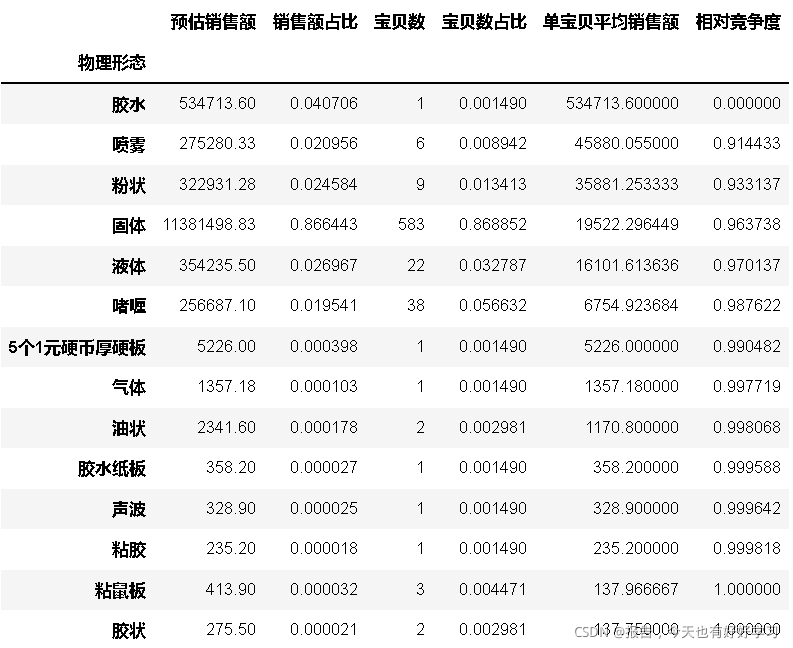
mcplot(byshape)
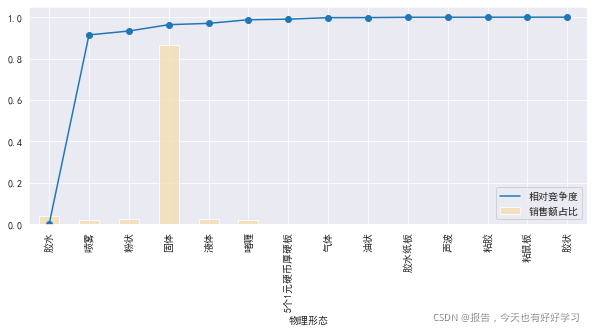
可見市場份額最高的是固體,競爭度也偏高,而膠水雖然競爭度低,但是市場份額較低,基本可以認為常見的物理形態就是固體,
3.6 市場機會點-結論
通過上述分析我們可以得出以下結論:
- 滅鼠殺蟲劑市場中,需要重點關注的產品類別是:滅鼠和蟑螂;
- 滅鼠中:
?○ 最大的市場集中在0-50的價格段,這個價格段競爭也很激烈;
?○ 200-250這個價格段市場份額占10%左右,競爭度很低,是值得挖掘的高價市場. - 滅鼠0-50價格段的產品市場中:
?○ 10-20價格段市場容量大,競爭度低,值得進一步開發,20-30也不錯;
?○ 店鋪型別方面天貓明顯優于淘寶;
?○ 市場份額高的型號是粘鼠板,然而型號0005市場份額還行,競爭度較低,值得開發;
?○ 產品的物理形態基本都是固體,也是被大眾認可的形態;
?○ 當物理形態為固體,凈含量為1時,市場份額高競爭度低,值得開發,
4 競爭分析
依據之前的top100品牌資料,分析市場份額前三的商家:拜耳,科凌蟲控,安速,
4.1 分析流程
- 人群畫像分析:三個品牌的人群特征基本一致(這里省略),
- 品類分布:依據各個商家產品類別和適用物件的分布,理解每個品牌的產品分布情況(橫向發展還是縱向發展),
- 產品結構:依據波士頓矩陣,分析各品牌不同產品的結構特征,為產品發展策略提供依據,
- 流量結構:通過流量結構和流量效果的對比,制定推廣策略,
- 產品輿情:優質產品維穩,
4.2 品類分布-產品類別
使用商品銷售資料分析各家的產品類別的分布:
os.chdir('./商品銷售資料/')
filename2 = glob.glob('*.xlsx')
filename2
[‘安速家居近30天銷售資料.xlsx’, ‘拜耳近30天銷售資料.xlsx’, ‘科凌蟲控旗艦店近30天銷售資料.xlsx’]
df3 = pd.read_excel(filename2[2])
df3.head(1)

# 洗掉無用特征
def load_xlsx_title(filename):
df = pd.read_excel(filename)
unless = ['序號','店鋪名稱','商品名稱','主圖鏈接','商品鏈接']
df.drop(columns=unless,inplace=True)
return df
df3bai = load_xlsx_title(filename2[1])
df3bai.head()
df3an = load_xlsx_title(filename2[0])
df3an.head()
df3kl = load_xlsx_title(filename2[2])
df3kl.head()
bai31 = df3bai.groupby('類目').sum()
bai31

an31 = df3an.groupby('類目').sum()
an31
kl31 = df3kl.groupby('類目').sum()
kl31
#餅圖 [0,1,2]
fig,axes = plt.subplots(1,3,figsize=(10,6))
ax = axes[0] #第一個拜耳
bai31['銷售額'].plot.pie(autopct='%.f',title='拜耳',startangle=30,ax=ax)
ax.set_ylabel('')
ax = axes[1] #第二個安速
an31['30天銷售額'].plot.pie(autopct='%.f',title='安速',startangle=60,ax=ax)
ax.set_ylabel('')
ax = axes[2] #第三個科凌蟲控
kl31['30天銷售額'].plot.pie(autopct='%.f',title='科凌蟲控',startangle=90,ax=ax)
ax.set_ylabel('')
plt.show()
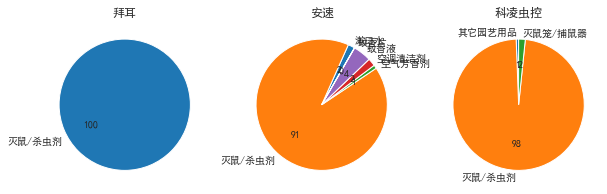
可見拜耳只有一個市場,其他的有不同市場,但主要市場都是滅鼠殺蟲劑,
4.3 品類分布-適用物件
分析各家的適用物件的分布:
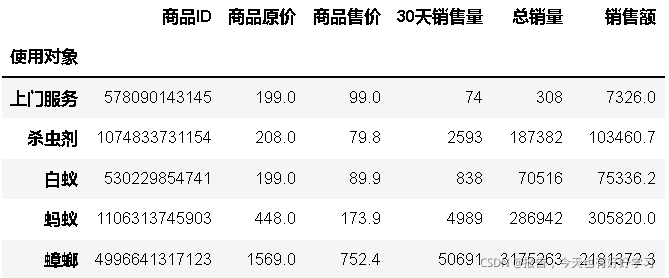
bai32 = df3bai.groupby('使用物件').sum()
bai32
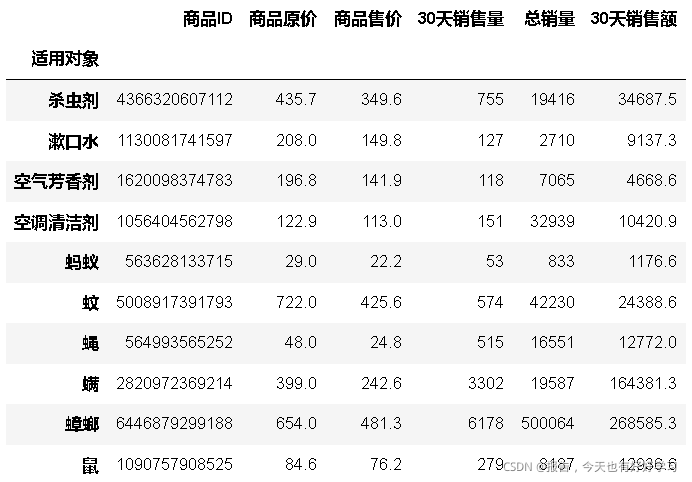
an32 = df3an.groupby('適用物件').sum()
an32
kl32 = df3kl.groupby('適用物件').sum()
kl32
#餅圖 [0,1,2]
fig,axes = plt.subplots(1,3,figsize=(10,6))
ax = axes[0] #第一個拜耳
bai32['銷售額'].plot.pie(autopct='%.f',title='拜耳',startangle=30,ax=ax)
ax.set_ylabel('')
ax = axes[1] #第二個安速
an32['30天銷售額'].plot.pie(autopct='%.f',title='安速',startangle=60,ax=ax)
ax.set_ylabel('')
ax = axes[2] #第三個科凌蟲控
kl32['30天銷售額'].plot.pie(autopct='%.f',title='科凌蟲控',startangle=90,ax=ax)
ax.set_ylabel('')
plt.show()
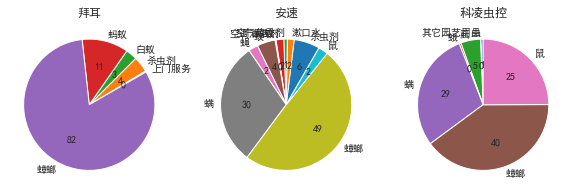
拜耳的主要物件是蟑螂,而另外兩家除此之外還有螨,鼠;
而從之前的分析看滅鼠和蟑螂的整體市場份額都大;應該開拓新市場,尤其是滅鼠,也考察其他兩家都開拓的螨市場,
4.4 產品結構分析-拜耳
os.chdir('..')
os.chdir('./商品交易資料')
filename3 = glob.glob('*.xlsx')
filename3
[‘安速全店商品交易資料.xlsx’, ‘拜耳全店商品交易資料.xlsx’, ‘科凌蟲控全店商品交易資料.xlsx’]
4.4.1 拜耳資料
使用商品交易資料,每個競爭者分開分析,先分析拜耳的資料,
df4bai = pd.read_excel(filename3[1])
df4bai.head()

df4bai.info()
輸出結果如下:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 142 entries, 0 to 141
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 品牌 142 non-null object
1 時間 142 non-null datetime64[ns]
2 商品 142 non-null object
3 行業排名 142 non-null int64
4 交易指數 142 non-null int64
5 交易增長幅度 142 non-null float64
6 支付轉化指數 142 non-null int64
7 操作 142 non-null object
8 交易金額 142 non-null float64
dtypes: datetime64[ns](1), float64(2), int64(3), object(3)
memory usage: 10.1+ KB
- 5個月的資料,每個商品最多5個月都在賣,至少有1個月,所以需要對商品分類匯總
df4bai['商品'].value_counts().count()
44
#自定義分類匯總函式
def byproduct(df):
dfb = df.groupby('商品').mean().loc[:,['交易增長幅度']] #交易增長幅度做均值
dfb['交易金額'] = df.groupby('商品').sum()['交易金額']
dfb['交易金額占比'] = dfb['交易金額']/dfb['交易金額'].sum()
dfb['商品個數'] = df.groupby('商品').count()['交易金額']
dfb.reset_index(inplace= True)
return dfb
bai4 = byproduct(df4bai)
bai4.head()
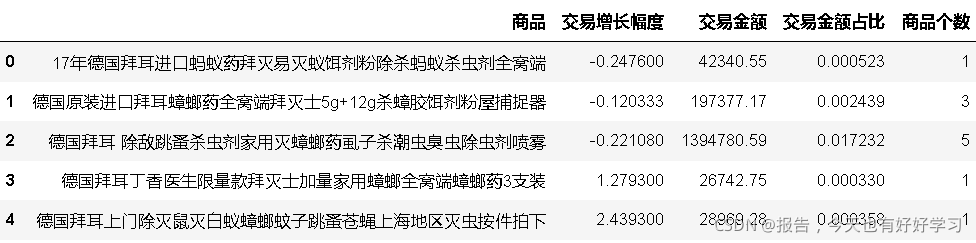
其中交易增長幅度可表示市場發展率,交易金額占比可表示市場份額,
bai4.describe(percentiles=[0.1,0.9,0.99])
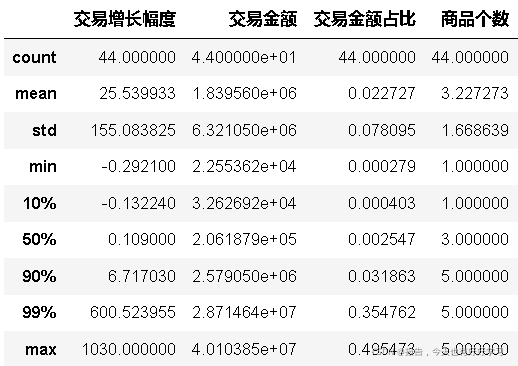
def block(x):
qu = x.quantile(.9)
out = x.mask(x>qu,qu) #當大于90%分位數的進行替換
return(out)
def block2(df):
df1 = df.copy()
df1['交易增長幅度'] = block(df1['交易增長幅度']) #使用蓋帽法進行替換交易增長幅度
df1['交易金額占比'] = block(df1['交易金額占比']) #使用蓋帽法進行替換交易增長幅度
return df1
bai41 = block2(bai4)
bai41.describe(percentiles=[0.1,0.9,0.99])
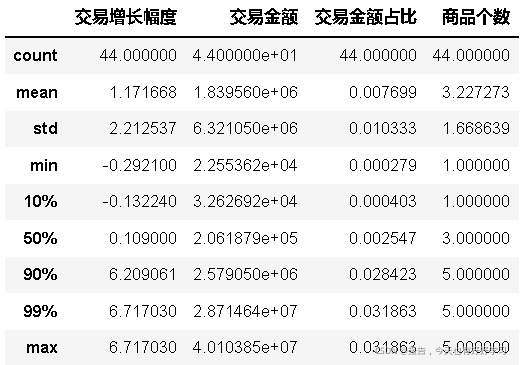
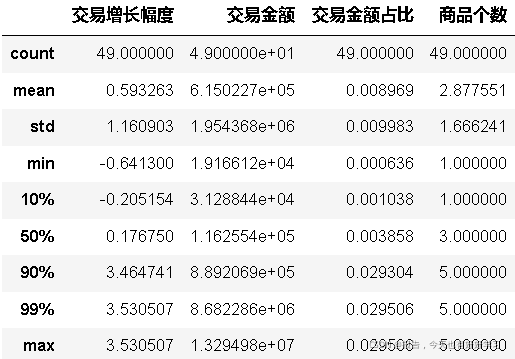
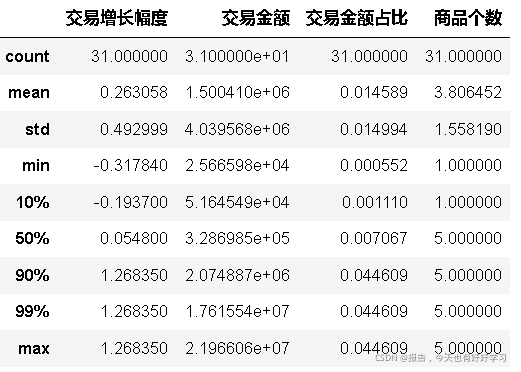
交易增長幅度和交易金額占比這兩個指標的最大值都遠大于3/4分位數,認為是例外值,考慮引入蓋帽法,方便作圖,
4.4.2 產品結構-拜耳-BCG圖
定義波士頓矩陣繪圖函式 可以使用均值、中位數來分割(0.33 0.33) 作為波士頓矩陣的切割線,
# mean True 均值
# mean False 中位數來分割(0.33 0.33)
def plotBOG(df,mean = False,q1=0.5,q2=0.5):
f,ax = plt.subplots(figsize=(10,8))
ax = sns.scatterplot('交易金額占比','交易增長幅度',hue='商品個數',size='商品個數',
sizes=(20,200),palette='cool',legend='full',data=df)
#給所有的點加行索引,點對應的是行資料(對應商品),方便探索
for i in range(0,len(df)):
ax.text(df['交易金額占比'][i]+0.001,df['交易增長幅度'][i],i) #索引標注相對于x軸右移
if mean:
plt.axvline(df['交易金額占比'].mean())#垂線
plt.axhline(df['交易增長幅度'].mean())#水平線
else:
plt.axvline(df['交易金額占比'].quantile(q1))#垂線
plt.axhline(df['交易增長幅度'].quantile(q2))#水平線
plt.show()
plotBOG(bai41,mean=True)
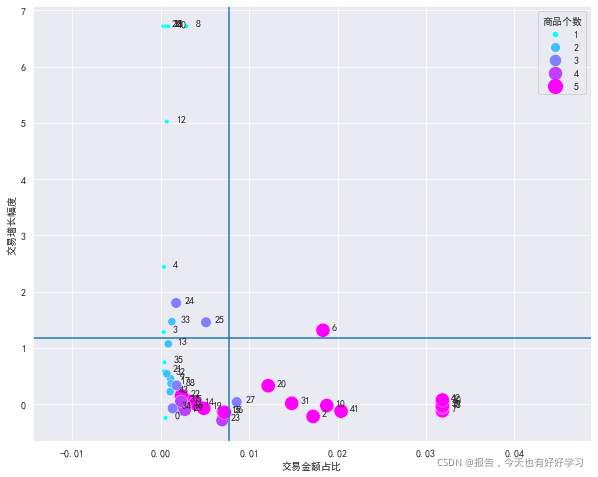
點的大小為商品個數,以中位數作為波士頓矩陣的分隔線,拜耳的BOG圖如下:
plotBOG(bai41,mean=False)
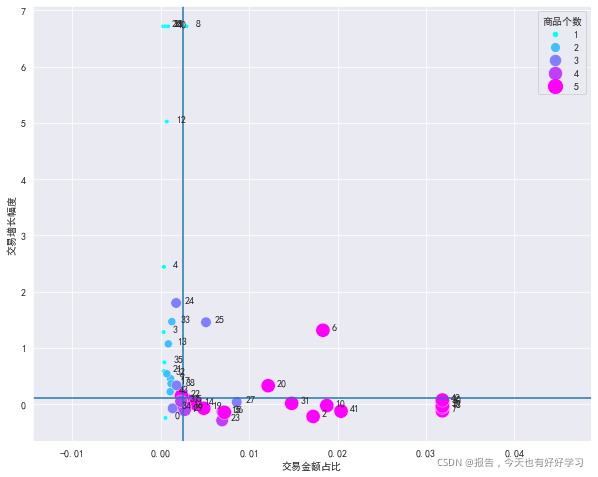
我們可以根據實際的業務選擇區間的分隔線,由行業經驗確定(例如認為增幅0.1在行業里算高,就可以作為分隔線)
從圖可以看出:明星產品和奶牛產品的商品個數普遍比較多,
沒有突出的明星產品,但是有快進入明星產品的問題產品,
4.4.3 產品結構-拜耳-明星
查看各個產品結構的產品(除了瘦狗)
各種產品排序,關心點不同,排序依據不同
- 明星產品:都關心,依什么排序都可以,產品一般不多
- 奶牛產品:老爆款,關心市場份額,依交易金額占比排序
問題產品,潛力款,關心市場增長率,依交易增長幅度排序,
這里要查看實際資料,故使用蓋帽前資料,拜耳明星產品如下:
def extractBOG(df,q1=0.5,q2=0.5,by='交易金額占比'):
# 明星產品
star = df.loc[(df['交易金額占比'] >= df['交易金額占比'].quantile(q1))#交易金額大于0.5
& (df['交易增長幅度'] >= df['交易增長幅度'].quantile(q2)),:] #交易增長幅度大于0.5
star = star.sort_values(by,ascending=False)
# 爆款產品
cow = df.loc[(df['交易金額占比'] >= df['交易金額占比'].quantile(q1))#交易金額大于0.5
& (df['交易增長幅度'] < df['交易增長幅度'].quantile(q2)),:] #交易增長幅度小于0.5
cow = cow.sort_values(by,ascending=False)
# 問題產品
que = df.loc[(df['交易金額占比'] < df['交易金額占比'].quantile(q1))#交易金額小于0.5
& (df['交易增長幅度'] >= df['交易增長幅度'].quantile(q2)),:] #交易增長幅度大于0.5
que = que.sort_values(by,ascending=False)
return star,cow,que
bai4star,bai4cow,bai4que = extractBOG(bai4)
bai4star

主要是除蟑和殺蟲,但是占比不大,增幅一般,
4.4.4 產品結構-拜耳-奶牛
bai4cow
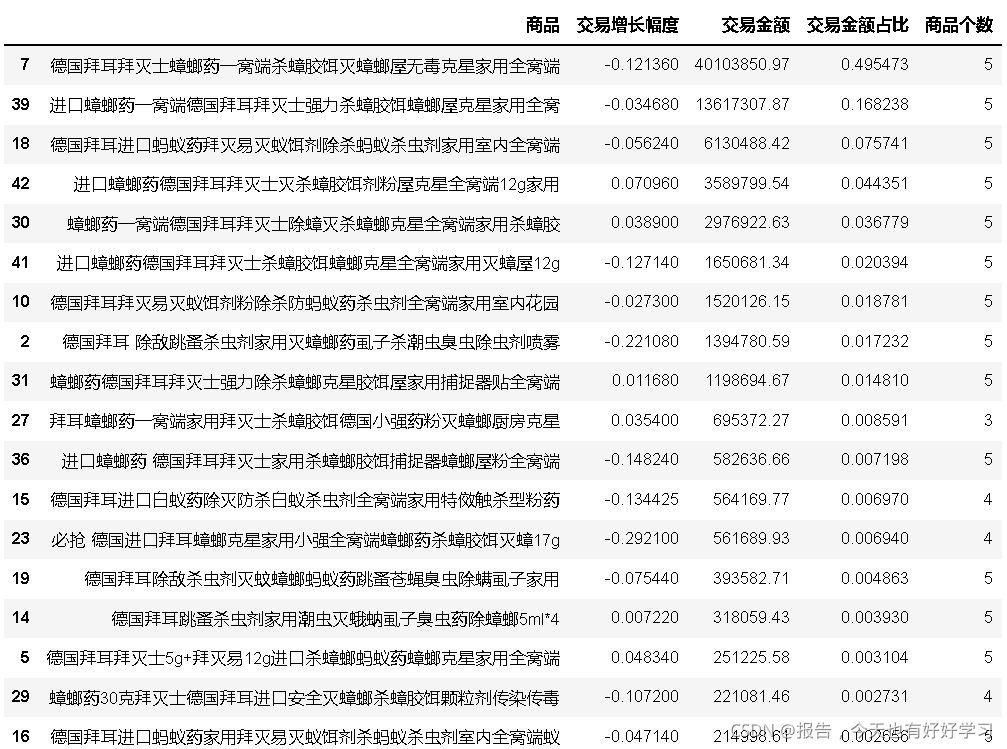
可見占比最高的是除蟑,滅蟲也占一部分,占比一般,
4.4.5 產品結構-拜耳-問題
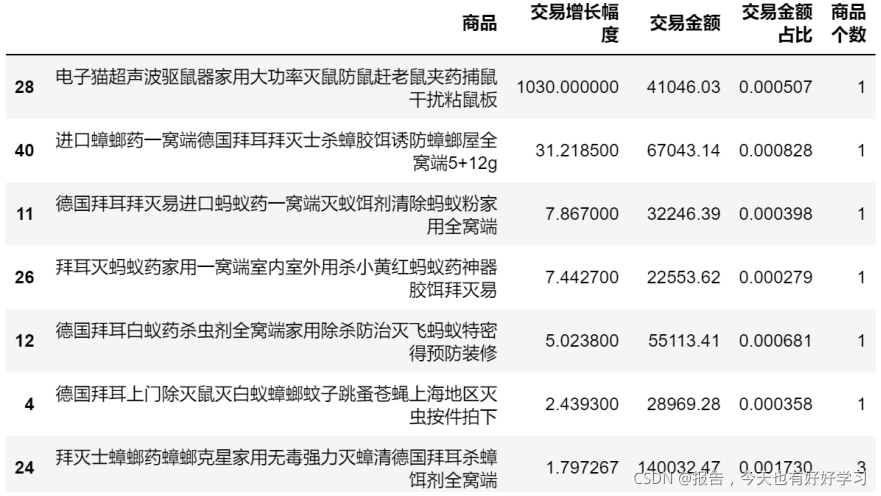
可見大部分仍然是滅蟑和殺蟲,
交易增長幅度最大的是滅鼠,而之前描述過滅鼠有最高的市場份額,可以作為下一步著力點,
4.4.6 總結
總結:拜耳大部分產品集中在除蟑上,殺蟲也有一定的規模,但是明星產品略乏力,可以進一步發展問題產品滅鼠為明星產品,
4.5 產品結構分析-安速
4.5.1 安速資料
df4an = pd.read_excel(filename3[0])
df4an.head()

df4an['商品'].value_counts().count()
49
an4 = byproduct(df4an)
an4.head()
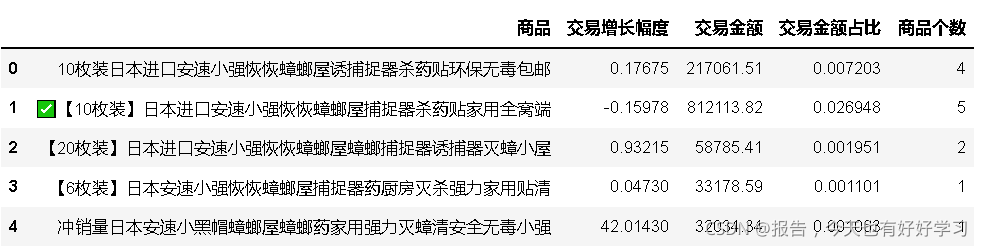
an4.describe()
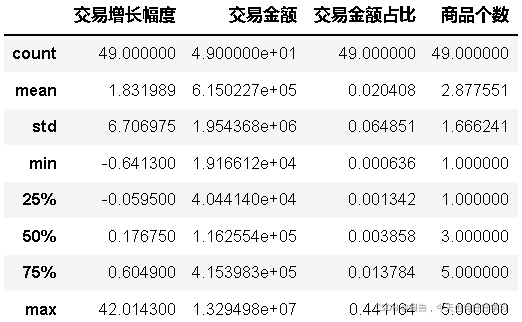
an41 = block2(an4)
an41.describe(percentiles=[0.1,0.9,0.99])
4.5.2 產品結構-安速-BCG圖
分析方法和之前一致,故直接看圖和產品:
plotBOG(an41)
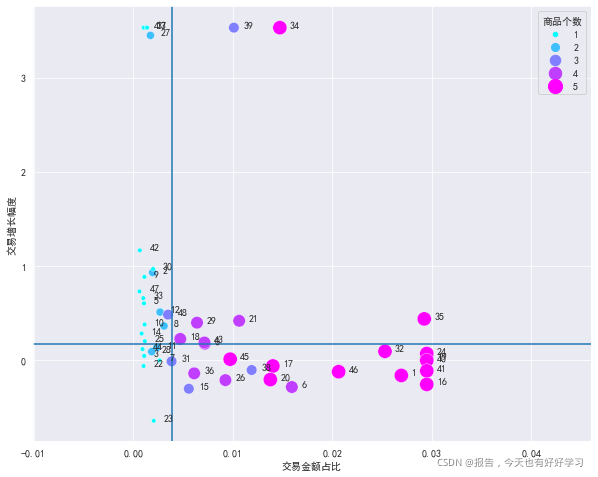
可見奶牛產品足,明星產品部分有前途,問題產品部分有潛力,瘦狗產品不多,
4.5.3 產品結構-安速-明星
anstar,ancow,anque = extractBOG(an4)
anstar
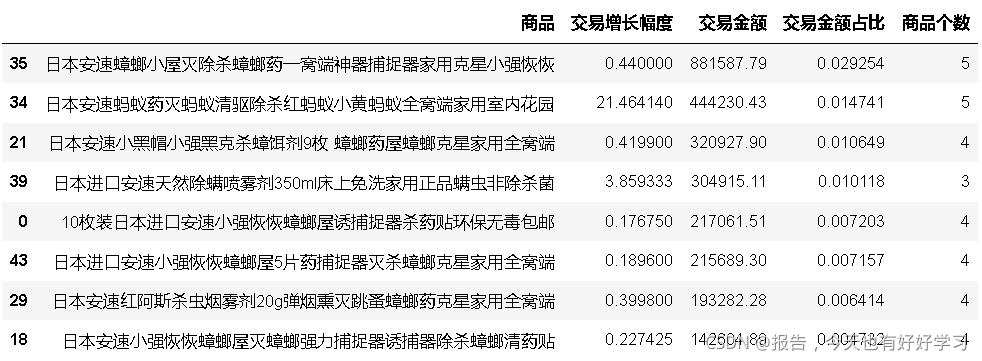
殺蟲和除蟑表現都不錯,
4.5.4 產品結構-安速-奶牛
ancow.head()
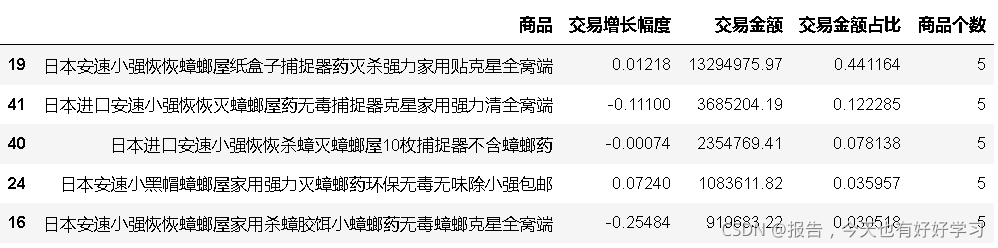
主要是除蟑,和拜耳產生競爭,
4.5.5 產品結構-安速-問題
anque.head()
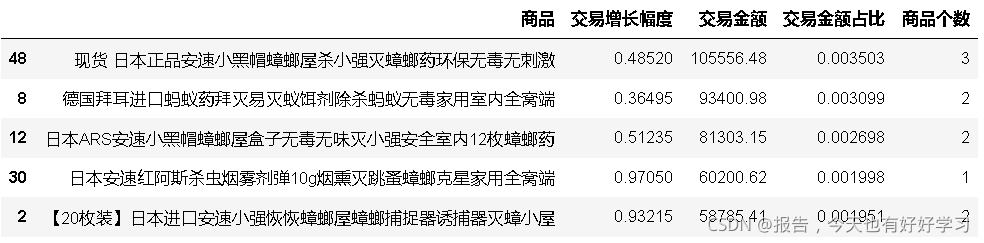
前幾款是滅蟑,除螨,殺蟲,都有發展空間,
4.5.6 總結
安速沒有明顯的滅鼠市場;拜耳和安速比較:拜耳殺蟲是老爆款,滅蟑存在一定競爭,
4.6 產品結構分析-科凌蟲控
4.6.1 科凌蟲控資料
df4ke = pd.read_excel(filename3[2])
df4ke.head()

df4ke['商品'].value_counts().count()
31
ke4 = byproduct(df4ke)
ke4.head()
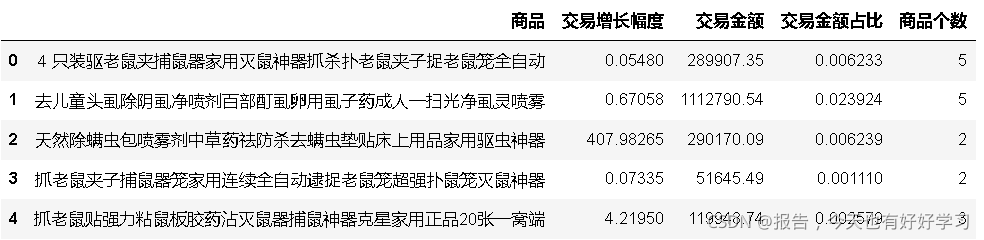
ke4.describe()
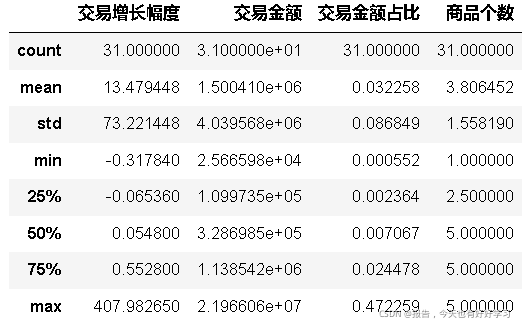
ke41 = block2(ke4)
ke41.describe(percentiles=[0.1,0.9,0.99])
4.6.2 產品結構-科凌蟲控-BCG圖
plotBOG(ke41)
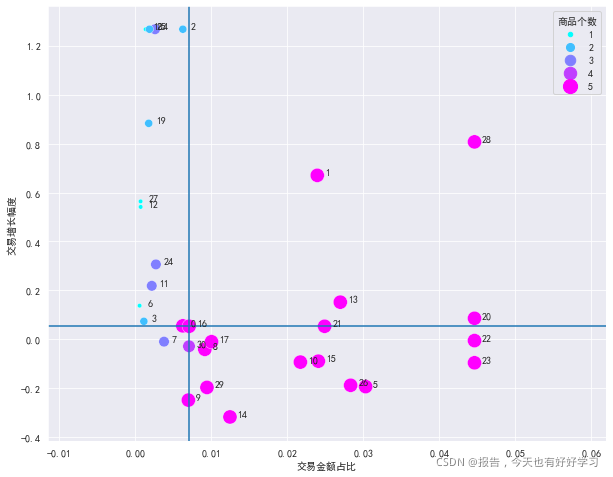
可見奶牛產品足,明星產品少,大部分競爭力強,問題產品部分有潛力,瘦狗產品少,
4.6.3 產品結構-科凌蟲控-明星
kestar,kecow,keque = extractBOG(ke4)
kestar

主要是滅鼠,除螨和殺蟲,
4.6.4 產品結構-科凌蟲控-奶牛
kecow.head()
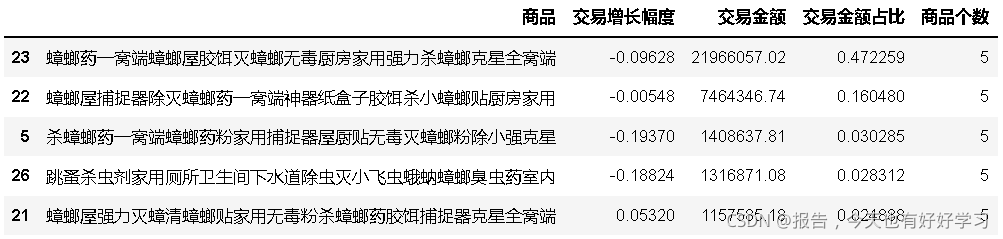
主要是除蟑,有很小部分滅蟲和滅鼠,
4.6.5 產品結構-科凌蟲控-問題
keque.head()
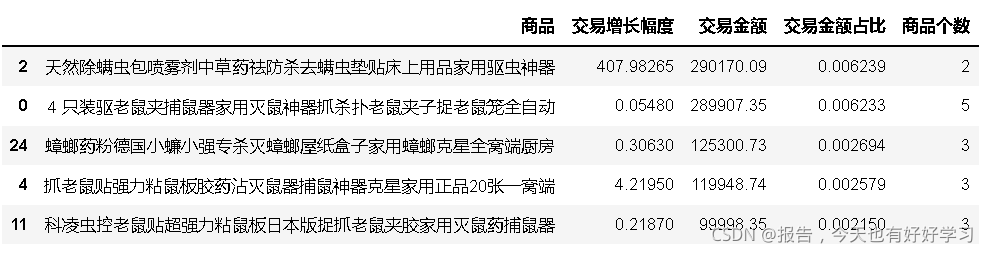
有較大潛力的是除螨,
4.6.6 總結
科凌蟲控積極發展多個產品,然而每個產品結構相對獨立(奶牛除蟑,明星滅鼠,潛力除螨),沒有后續的支持,競爭力不是那么強,
4.7 流量結構-業務邏輯
4.7.1 概述
- 目前的流量主要由三大塊構成:免費流量,付費流量和自主訪問,
?○ 一般的店鋪占比分別是50-60%,30%,10-15%
?○ 免費流量中,搜索流量占60%,即搜索流量只占總流量的30%-40% - 付費流量沒有特定的比例,合理的值是一般不超過40%(正常銷售時期),如果此類目利潤率高競爭激烈,占比80%也有可能,
- 看店鋪付費流量比例是否健康,應該看廣告費用在全店銷售額的占比,一般控制在10%左右,(同樣的廣告費用占比,降低CPC(點擊成本),付費流量占比會上升),
- 付費流量帶動免費流量的前提:
1)引來的流量是否適合你的店鋪和寶貝,
2)引流量要達到一定的數量,
3)寶貝適合市場, - 增加免費流量:一般是以小爆款帶動,而這個時代小爆款層出不窮,一般建議主推兩三個寶貝,輔推三五個寶貝,合理安排推廣預算占比,
- 好的流量結構:
1)合理的產品結構,
2)寶貝標題(搜索流量的入口)的關鍵詞布局,
3)適當的付費廣告占比,
4)盡可能提升流量入口數量,
5)參考同行的流量結構,
- 流量結構-分析問題
流量急劇下降了,怎么分析:
- 先看行業大盤,看是不是全行業如此
- 查看資料是否例外,如果大家的資料都來自第三方,和同行交流看是否也有相同問題
- 后臺分析是主推寶貝單個下滑還是全店寶貝同步下滑
?○ 單個下滑:查看評價或庫存,都沒問題繼續拆分,查看所有流量入口:
???■ 單個入口下滑:針對這個入口補救,如果這個入口是搜索流量入口,查驗是否有強大的競爭對手;
???■ 所有流量入口下滑:拆分這個寶貝每一天的資料(收藏率,加購率,轉化率,停留時長等),判斷客戶特征是否發生變化,即進來了和之前不同的人群,導致效果變差從而影響寶貝權重,
?○ 所有寶貝下滑:關注動態評分,尤其是售后評分,可能的原因有:季節,競爭對手,官方 活動,如果都不是,找例外資料:把看寶貝每一項資料的變化曲線,所有影響店鋪權重的因素反推,
聊完分析方法后,下面我們正式用資料來分析一下,
4.7.2 流量結構-拜耳
os.chdir('..')
os.chdir('./流量渠道資料')
filename4 = glob.glob('*.xlsx')
filename4
[‘安速家居旗艦店流量渠道.xlsx’, ‘拜耳官方旗艦店流量渠道.xlsx’, ‘科凌蟲控旗艦店流量渠道.xlsx’]
df5bai = pd.read_excel(filename4[1])
df5bai.head(10)
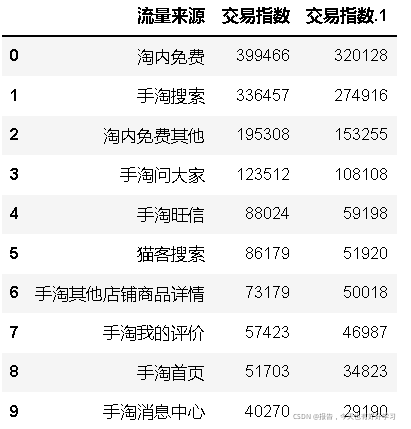
# 只取交易指數排名前十的流量渠道
df0 = df5bai
top10 = df0.sort_values('交易指數',ascending=False).reset_index(drop=True).iloc[:10,:]
#計算交易指數占比,交易指數是銷售額的反映
top10['交易指數占比'] = top10['交易指數']/top10['交易指數'].sum()
top10.set_index('流量來源',inplace=True)
top10
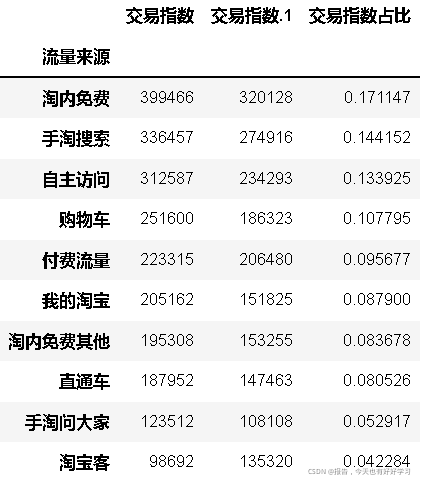
#把付費的渠道 進行標記
paid = ['付費流量','直通車','淘寶客']
ind = np.any([top10.index == i for i in paid],axis=0) #true 為付費的
ind
array([False, False, False, False, True, False, False, True, False, True])
自定義函式-流量結構說明:
def flow(df):
# 只取交易指數排名前十的流量渠道
df0 = df.copy()
top10 = df0.sort_values('交易指數',ascending=False).reset_index(drop=True).iloc[:10,:]
#計算交易指數占比
top10['交易指數占比'] = top10['交易指數']/top10['交易指數'].sum()
top10.set_index('流量來源',inplace=True)
#把付費的渠道 進行標記
paid = ['付費流量','直通車','淘寶客']
ind = np.any([top10.index == i for i in paid],axis=0) #true 為付費的
explode = ind * 0.1 #相當于往外爆0.1的距離
ax = top10['交易指數占比'].plot.pie(autopct='%.1f%%',
figsize=(8,8),colormap='cool',explode = explode)
ax.set_ylabel('')
plt.show()
#輸出占比:總交易指數、付費流量占比、付費流量帶來的交易指數
salesum = top10['交易指數'].sum() #總交易指數
paidsum = top10['交易指數占比'][ind].sum() #付費流量占比
paidsale = salesum * paidsum #付費流量帶來的交易指數
print(f'前十流量中:總交易指數:{salesum:.0f};付費流量占比:{paidsum*100:.2f}%;付費流量帶來的交易指數:{paidsale:.0f}')
return top10
bai5 = flow(df5bai)
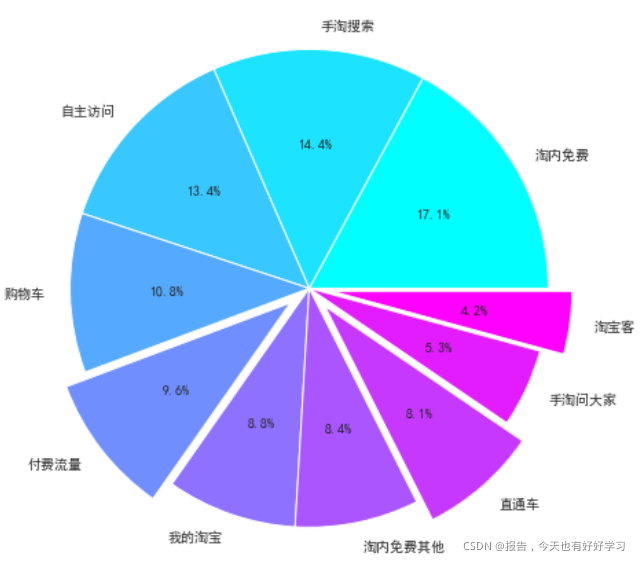
前10流量中:總交易指數:2334051;付費流量占比:21.85%;付費流量帶來交易指數:509959,
4.7.3 流量結構-安速
df5an = pd.read_excel(filename4[0])
df5an.head(10)
# 只取交易指數排名前十的流量渠道
df0 = df5an
top10 = df0.sort_values('交易指數',ascending=False).reset_index(drop=True).iloc[:10,:]
#計算交易指數占比
top10['交易指數占比'] = top10['交易指數']/top10['交易指數'].sum()
top10.set_index('流量來源',inplace=True)
top10
#把付費的渠道 進行標記
paid = ['付費流量','直通車','淘寶客']
ind = np.any([top10.index == i for i in paid],axis=0) #true 為付費的
ind
array([False, False, False, True, False, False, False, True, False, False])
an5 = flow(df5an)
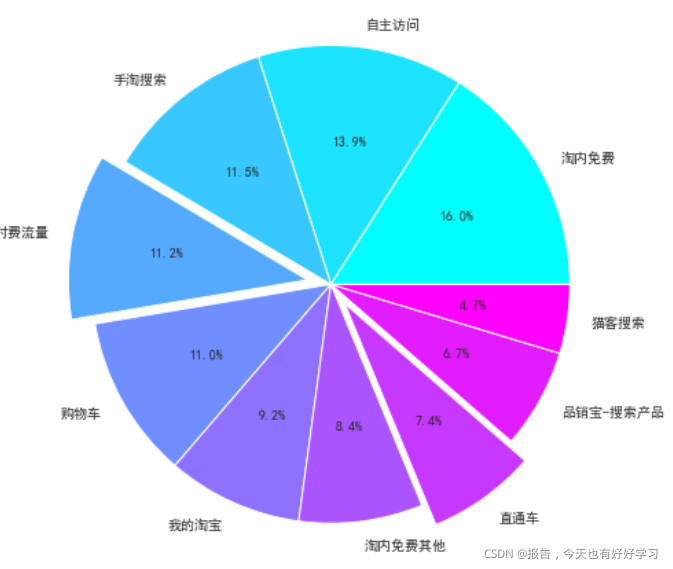
前10流量中:總交易指數:748539;付費流量占比:18.58%;付費流量帶來交易指數:139048,
可見拜耳和安速的流量配比是差不多的,安速的整體流量小很多,即流量效果拜耳明顯優于安速,
4.7.4 流量結構-科凌蟲控
df5ke = pd.read_excel(filename4[2])
df5ke.head(10)
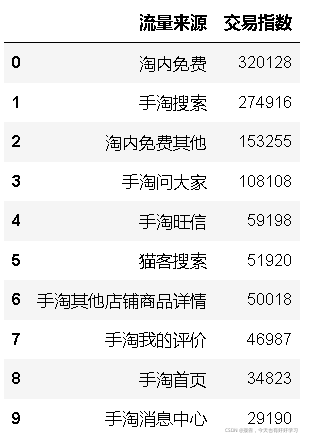
# 只取交易指數排名前十的流量渠道
df0 = df5ke
top10 = df0.sort_values('交易指數',ascending=False).reset_index(drop=True).iloc[:10,:]
#計算交易指數占比
top10['交易指數占比'] = top10['交易指數']/top10['交易指數'].sum()
top10.set_index('流量來源',inplace=True)
top10
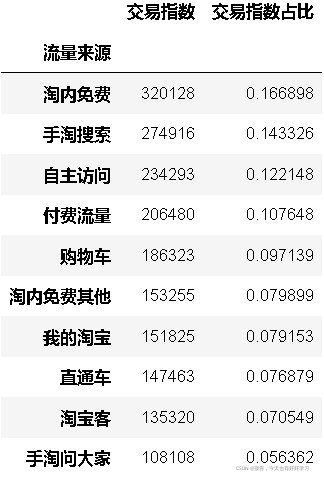
#把付費的渠道 進行標記
paid = ['付費流量','直通車','淘寶客']
ind = np.any([top10.index == i for i in paid],axis=0) #true 為付費的
ind
array([False, False, False, True, False, False, False, True, True, False])
ke5 = flow(df5ke)
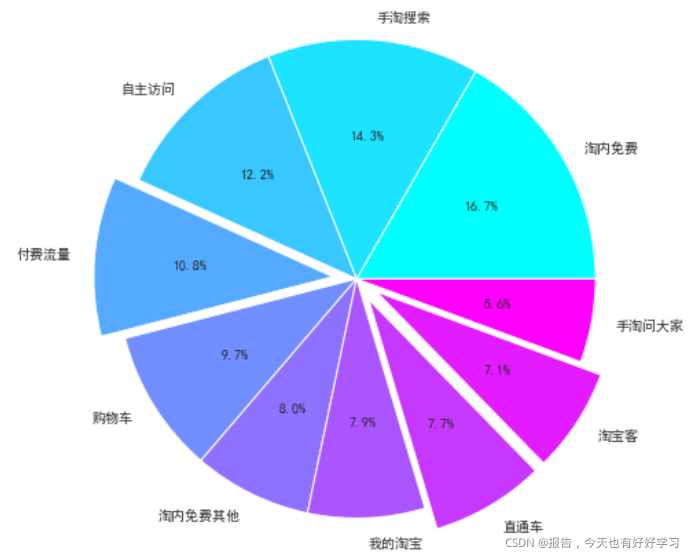
前10流量中:總交易指數:1918111;付費流量占比:25.51%;付費流量帶來交易指數:489263,
- 和拜耳在流量上差不多,科凌蟲控付費占比較高
- 可見拜耳在流量結構上是有優勢的,要保持這個優勢
5 輿情分析
5.1 文本挖掘基本流程
- 使用的資料是評論資料,即文本資料,
- 文本資料的分析程序主要有:清洗,可視,這里針對中文文本,
?○ 清洗基本流程:
???■ 替換非中英文字符為空格;
???■ 分詞(結巴jieba);
???■ 去掉停用詞(對描述和建模無意義的詞);
???■ 篩選高頻詞;此流程需要反復嘗試對比效果, - 可視化:一般都是詞云,可能配合關鍵詞排序等,
- 建模:建模前需要將資料轉成檔案詞矩陣(dtm);有監督的話常用的是貝葉斯,其他偏精度的演算法也可以,要注意特征個數;無監督常用的是主題模型LDA,其他諸如分群,情感分析也可以,
- 清洗流程中,尤其是口語化較強的資料,例如評論資料,需要去除重復陳述句,以及字數少于某個閾值的評論,
- 根據評論資料得到的詞云,
下面開始正式復現上述流程,
os.chdir('..')
os.chdir('./評論輿情資料')
filename = glob.glob('*.xlsx')
filename
[‘安速.xlsx’, ‘德國拜耳.xlsx’, ‘科林蟲控.xlsx’]
df6bai = pd.read_excel(filename[1])
df6bai
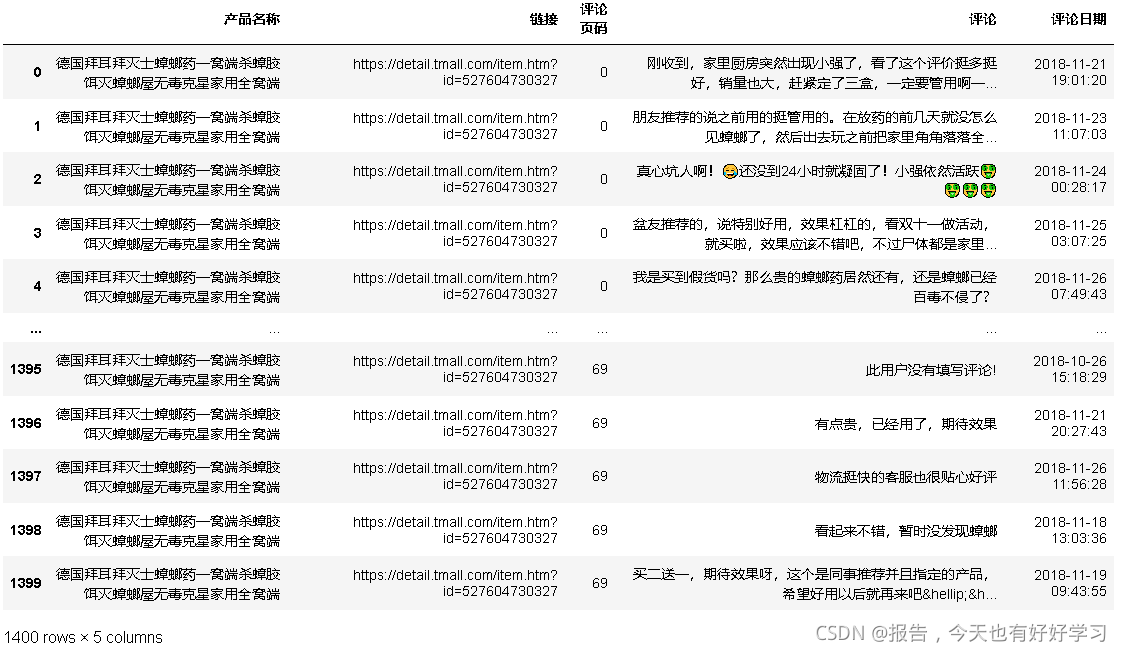
bai6 = list(df6bai['評論'])
bai6[:5] # 提取5條看一看

可見,我們需要一定的資料清洗:非中英文字符的不要、在分詞前逗號、句號不要,
bai61 = [re.sub(r'[^a-z\u4E00-\u9Fa5]+',' ',i,
flags=re.I) for i in bai6]#中文字符 \u4E00-\u9Fa5 flags=re.I 不區分大小寫
清洗完再來看一下:
bai61[:5]

接著我們來去掉停用詞(百度的停用詞庫),不過在此之前,我們得先分一下詞,這里我們用的分詞工具是jieba分詞,先來看一下jieba的使用:
jieba.lcut('真心坑人啊 還沒到 小時就凝固了 小強依然活躍')
輸出結果如下:
['真心',
'坑人',
'啊',
' ',
'還',
'沒到',
' ',
'小時',
'就',
'凝固',
'了',
' ',
'小強',
'依然',
'活躍']
接下來正式進行分詞:
# 先讀取停用詞
stopwords = list(pd.read_csv('E:\Data-analysis-project\電商文本挖掘\data/百度停用詞表.txt',
names=['stopwords'])['stopwords']) #指定列名轉化為串列
stopwords.extend([' ', '蟑螂']) #把空格也去掉 蟑螂
bai62 = []
for i in bai61:
#對每條評論分析
seg1 = pd.Series(jieba.lcut(i))
ind1 = pd.Series([len(j) for j in seg1])>1 #長度大于1的保留
seg2 = seg1[ind1]
#去掉停用詞 isin
ind2 = ~seg2.isin(pd.Series(stopwords))
seg3 = list(seg2[ind2].unique())#去重一下
if len(seg3)>0:
bai62.append(seg3)
bai62[0] #得到的是大串列套小串列
輸出結果如下:
['收到',
'家里',
'廚房',
'小強',
'評價',
'銷量',
'趕緊',
'三盒',
'管用',
'后續',
'效果',
'追加',
'多久',
'才能',
'消滅',
'干凈',
'沒法',
'做飯',
'進去',
'擔心',
'揮發',
'很多',
'試試']
組合多個串列到一個串列:
bai63 = [y for x in bai62 for y in x]
bai63[:5]
[‘收到’, ‘家里’, ‘廚房’, ‘小強’, ‘評價’]
#詞頻統計
baifreq = pd.Series(bai63).value_counts()
baifreq[:10] # 看下前10個詞
輸出結果如下:
效果 541
蟑螂 409
雙十 145
不錯 144
評論 138
小強 114
收到 106
用戶 100
填寫 100
東西 95
dtype: int64
而構建一個詞云所需要的資料 一個巨大字串 (用空格分隔的詞):
bai64 = ' '.join(bai63)
最后一個步驟,呼叫WordCloud模塊生成詞云:
#讀取照片
mask = imageio.imread(r'E:\Data-analysis-project\電商文本挖掘\data/leaf.jpg')
#如果是中文的詞云---字體
font = r'E:\Data-analysis-project\電商文本挖掘\data/SimHei.ttf'
wc = WordCloud(background_color='white',mask=mask,
font_path=font).generate(bai64)
plt.figure(figsize=(8,8))
plt.imshow(wc)
plt.axis('off')#不要坐標軸
plt.show()

5.2 關鍵字提取
基于 TF-IDF 演算法的關鍵詞抽取:
jieba.analyse.extract_tags(bai64,20,True)
輸出結果如下:
[('效果', 0.29875695025833393),
('雙十', 0.13410500058357974),
('評論', 0.08641902343506376),
('濕巾', 0.08395512199412308),
('填寫', 0.08239762548761781),
('不錯', 0.0823420504295694),
('好評', 0.07553937079103677),
('追評', 0.07069905010031417),
('沒用', 0.06662667991833673),
('收到', 0.06542549350413418),
('用戶', 0.06304136086139346),
('好用', 0.06195551748124191),
('尸體', 0.05744312738244686),
('劃算', 0.057198916923431896),
('濕紙巾', 0.05523277943411569),
('家里', 0.04893045405589909),
('發貨', 0.04800798233693402),
('期待', 0.0452573579284439),
('希望', 0.04377063232686934),
('hellip', 0.04308223365487895)]
5.3 總結
- 不管從詞云還是關鍵詞來看,評價偏好評,沒有明顯問題,
- 可以在停用詞中添加好評,可以再看效果,
6 專案總結
最終我們可以把以上總結匯總一下:
| 分析角度 | 結論 |
|---|---|
| 潛力分析 | 1.整體驅蟲市場處于快速增長階段,趨向于成長期到成熟期; 2.滅鼠殺蟲劑市場份額較大(大于60%),約是第二名蚊香液的二倍,市場增長率接近40%,可以認為是明星產品類目,需要持續投資和重點關注; 3.驅蟲市場不存在壟斷,結構不集中,競爭相對激烈,即沒有明顯的來自大公司的壓力, |
| 市場機會點 | 1.滅鼠殺蟲劑市場中,需要重點關注的產品類別是:滅鼠和蟑螂; 2.滅鼠產品: ?○ 最大的市場集中在0-50的價格段,這個價格段競爭也很激烈; ?○ 200-250這個價格段市場份額占10%左右,競爭度很低,是值得挖掘的高價市場; 3.滅鼠0-50價格段的產品市場中: ?○ 10-20價格段市場容量大,競爭度低,值得進一步開發,20-30也不錯; ?○ 店鋪型別方面天貓明顯優于淘寶; ?○ 市場份額高的型號是粘鼠板,然而型號0005市場份額還行,競爭度較低,值得開發; ?○ 產品的物理形態基本都是固體,也是被大眾認可的形態; ?○ 當物理形態為固體,凈含量為1時,市場份額高競爭度低,值得開發, |
| 品類分布-產品類別 | 拜耳只有一個市場,其他的有不同市場,但主要市場都是滅鼠殺蟲劑, |
| 品類分布-適用物件 | 拜耳的主要物件是蟑螂,而另外兩家除此之外還有螨,鼠; 而從之前的分析看滅鼠和蟑螂的整體市場份額都大;應該開拓新市場,尤其是滅鼠,也考察其他兩家都開拓的螨市場, |
| 產品結構 | 拜耳大部分產品集中在除蟑上,殺蟲也有一定的規模,但是明星產品略乏力,可以進一步發展問題產品滅鼠為明星產品, 安速沒有明顯的滅鼠市場;拜耳和安速比較:拜耳殺蟲是老爆款,滅蟑存在一定競爭, 科凌蟲控積極發展多個產品,然而每個產品結構相對獨立(奶牛除蟑,明星滅鼠,潛力除螨),沒有后續的支持,競爭力不是那么強, |
| 流量結構 | 拜耳和安速的流量配比是差不多的,不過安速的整體流量小很多; 科凌蟲控和拜耳在流量上差不多,科凌蟲控付費占比較高,可見拜耳在流量結構上是有優勢的,要保持這個優勢, |
| 輿情分析 | 不管從詞云還是關鍵詞來看,評價偏好評,沒有明顯問題, |
到這里,我們這一個專案也差不多結束啦,希望這篇文章對你能有所幫助!
CSDN@報告,今天也有好好學習
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/300960.html
標籤:AI
上一篇:睿智的目標檢測52——Keras搭建YoloX目標檢測平臺
下一篇:軟體公司要咨詢顧問干什么?