
這是一篇ICCV2021的文章,提出了一種新的知識蒸餾方式(Holistic Knowledge Distillation)
原文鏈接
代碼鏈接
Figure 1為Individual、Relational、Holistic Knowledge Distillation三種不同的知識蒸餾方式的區別.這里根據Relational Knowledge Distillation解讀以及Relational Knowledge Distillation簡單介紹一下這幾種知識蒸餾方式的區別:
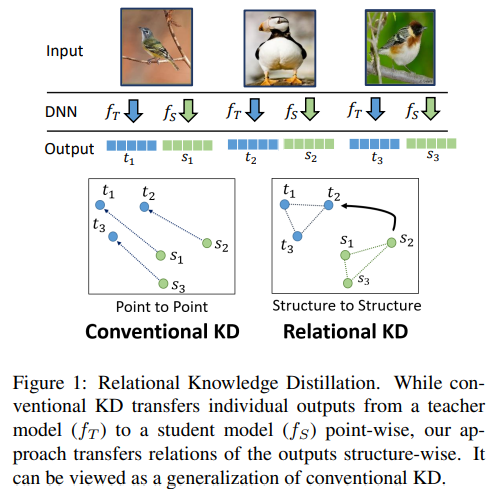
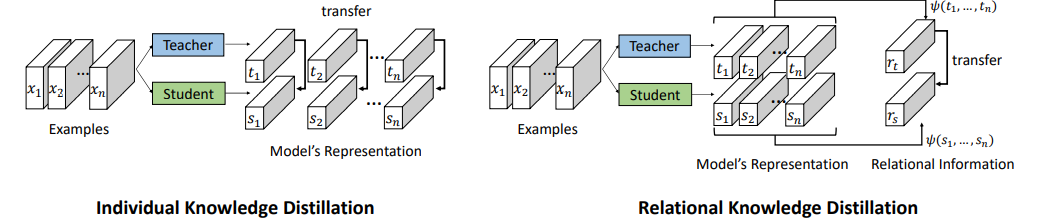
先根據Relational Knowledge Distillation論文中的圖來解釋傳統的知識蒸餾以及Relational Knowledge Distillation,由上圖可以看出傳統KD是對單張圖片分別根據學生和老師模型提取特征向量,并通過KL散度以及其他方法來計算學生和老師模型輸出的差異,所以這里point to point就很好理解了,Relational Knowledge Distillation在傳統KD的基礎上,將多張圖片的特征向量通過distance-wise (second-order) and angle-wise (third-order) distillation losses合在一起進行學習,
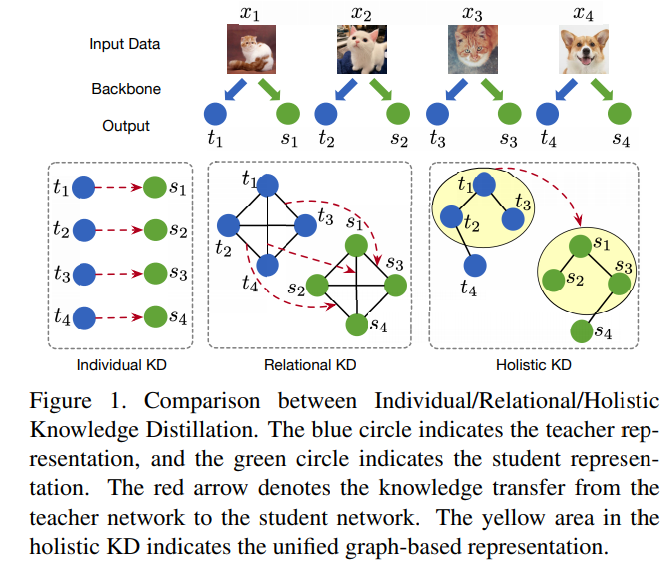
而本文認為單一的提取個體的資訊和單一的提取個體間的資訊是不夠的,因此提出了Holistic Knowledge Distillation,整合了傳統KD和Relational Knowledge Distillation,
先驗知識
給定一個從K類資料集中采樣得到的
X
=
{
x
1
,
x
2
,
.
.
.
x
N
}
X=\{x_1,x_2,...x_N\}
X={x1?,x2?,...xN?},帶有相應的標簽
Y
=
{
y
1
,
y
2
,
.
.
.
y
N
}
Y=\{y_1,y_2,...y_N\}
Y={y1?,y2?,...yN?},其中N表示采樣的個數,
W
t
W^t
Wt和
W
s
W^s
Ws分別表示固定引數的優化好的教師模型和可訓練引數的學生模型,老師模型和學生模型的特征表示(經常用于Relational Knowledge Distillation)分別為
f
t
∈
R
d
t
f^t \in R^{d^{t}}
ft∈Rdt和
f
s
∈
R
d
s
f^s \in R^{d^{s}}
fs∈Rds,其中
d
t
d^{t}
dt和
d
s
d^{s}
ds在模型結構不同時可能不同,
z
t
z^{t}
zt和
z
s
z^{s}
zs分別是老師和學生模型的logits預測,
p
i
(
z
;
r
)
=
S
o
f
t
m
a
x
(
z
;
r
)
=
e
z
i
r
∑
k
=
1
K
e
z
k
r
p_i(z;r)=Softmax(z;r)=\frac{e^{\frac{z_i}{r}}}{\sum_{k=1}^{K}{e^\frac{z_k}{r}}}
pi?(z;r)=Softmax(z;r)=∑k=1K?erzk??erzi???
上式初始溫度
r
=
1
r=1
r=1,隨著
r
r
r的逐漸增大,softmax的output probability distribution越趨于平滑,其分布的熵越大,負標簽攜帶的資訊會被相對地放大,模型訓練將更加關注負標簽,
L
K
D
(
p
s
,
p
t
)
=
1
N
∑
i
=
1
N
K
L
(
p
s
,
p
t
)
L_{KD}(p^s,p^t)=\frac{1}{N}\sum_{i=1}^{N}{}KL(p^s,p^t)
LKD?(ps,pt)=N1?i=1∑N?KL(ps,pt)
上式為老師模型的軟標簽概率和學生模型的概率分布求KL散度,
在vanilla KD中,學生模型的損失表示為:
L
=
L
C
E
(
p
s
,
y
)
+
λ
L
K
D
(
p
s
,
p
t
)
L = L_{CE}(p^s,y) + \lambda L_{KD}(p^s,p^t)
L=LCE?(ps,y)+λLKD?(ps,pt)
Attributed Context Graph Construction
輸入batch組圖片到老師和學生模型得到特征表示
f
t
f^t
ft,
f
s
f^s
fs以及預測概率
p
t
p^t
pt,
p
s
p^s
ps,接著構建兩個屬性圖
G
t
=
{
A
t
,
F
t
}
G^t=\{ A^t, F^t \}
Gt={At,Ft}和
G
s
=
{
A
s
,
F
s
}
G^s=\{ A^s, F^s \}
Gs={As,Fs}, 其中
F
t
∈
R
N
×
d
t
F^t \in R^{N \times d^t}
Ft∈RN×dt,
F
s
∈
R
N
×
d
s
F^s \in R^{N \times d^s}
Fs∈RN×ds是圖中節點的屬性,
A
t
,
A
s
A^t, A^s
At,As基于
p
t
,
p
s
p^t, p^s
pt,ps得到的
A
t
=
?
(
p
t
)
,
A
s
=
?
(
p
s
)
A^t=\phi(p^t), A^s=\phi(p^s)
At=?(pt),As=?(ps)
其中
?
(
.
)
\phi(.)
?(.)是基于KNN的圖重構函式(不是很懂這個圖是怎么構建出來的),
G
t
G^t
Gt是fixed,相比于全連接的graph,KNN的graph可以濾除不相關的樣本對,插播KNN學習(關于KNN的學習基本按照一文搞懂k近鄰(k-NN)演算法(一)和Python—KNN分類演算法(詳解)來講解的)
KNN又叫K Nearest Neighbors,即通過與待預測節點的K個最近節點來預測當前節點,如圖所示: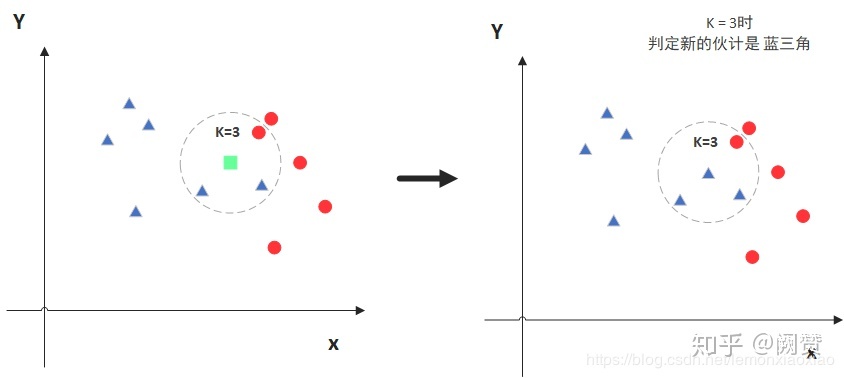
對于KNN而言,K的選取很重要,因為K取小了會導致過擬合:
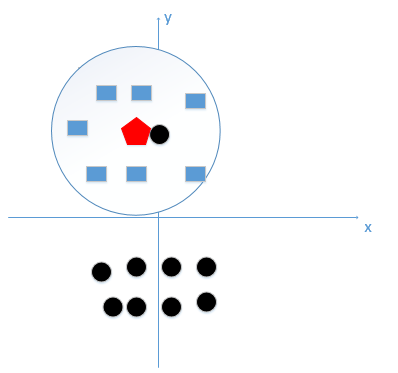
因為對于上圖來說正確的方式應該是藍色的圈內的節點數做K值,而如果K值過小,極端情況為1時,待預測的紅色節點最近的節點是黑色,而這顯然不正確,它學到的完全是個噪聲,
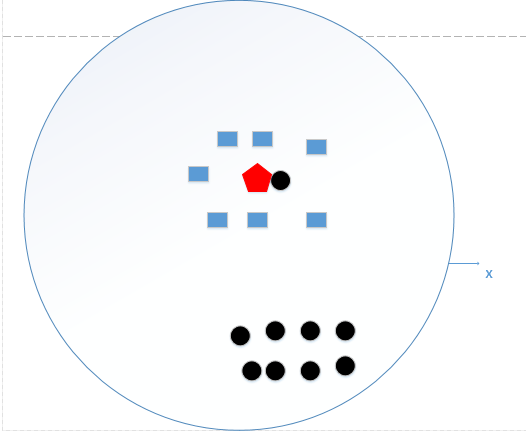
相反當K值過大時,如上圖所示,其預測值是在全域的范圍內尋找點數量最多的那個即可,上述程序中待預測的節點應該是黑色,因為黑色點比藍色方塊多,然而顯然是有問題的,下圖才是真正正確的K值選取范圍:
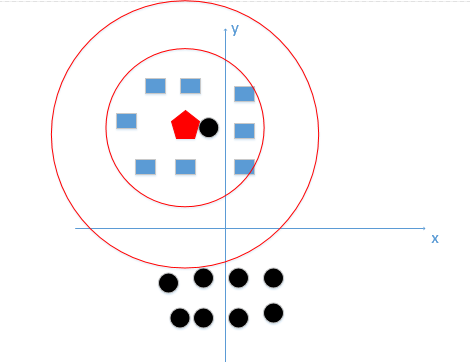
說完K值對KNN的影響,再來看看距離度量的選取(畢竟有那么多種度量方式),一般KNN都選擇歐式距離作為度量的方式,
最后需要對所給特征進行歸一化,因為特征不同,不歸一化會導致預測時會有特征偏好,具體例子詳見一文搞懂k近鄰(k-NN)演算法(一),
附上論文knn_graph部分源代碼和dgl官網代碼Source code for dgl.transform:
def cos_distance_softmax(x):
soft = F.softmax(x, dim=2)
w = soft.norm(p=2, dim=2, keepdim=True)
# L2范數
print(B.swapaxes(soft, -1, -2)) # 將soft轉置
return 1 - soft @ B.swapaxes(soft, -1, -2) / (w @ B.swapaxes(w, -1, -2)).clamp(min=eps) # soft * soft^{T}
def knn_graph(x, k):
if B.ndim(x) == 2:
x = B.unsqueeze(x, 0)
n_samples, n_points, _ = B.shape(x)
dist = cos_distance_softmax(x) # 這里不太清楚為什么要用這個distance
fil = 1 - torch.eye(n_points, n_points)
dist = dist * B.unsqueeze(fil, 0).cuda()
dist = dist - B.unsqueeze(torch.eye(n_points, n_points), 0).cuda()
k_indices = B.argtopk(dist, k, 2, descending=False)
dst = B.copy_to(k_indices, B.cpu())
src = B.zeros_like(dst) + B.reshape(B.arange(0, n_points), (1, -1, 1))
per_sample_offset = B.reshape(B.arange(0, n_samples) * n_points, (-1, 1, 1))
dst += per_sample_offset
src += per_sample_offset
dst = B.reshape(dst, (-1,))
src = B.reshape(src, (-1,))
adj = sparse.csr_matrix((B.asnumpy(B.zeros_like(dst) + 1), (B.asnumpy(dst), B.asnumpy(src))))
g = DGLGraph(adj, readonly=True)
return g
Holistic Knowledge Distillation
用Topology Adaptive Graph Convolution Network (TAGCN)提取
G
t
G^t
Gt,
G
s
G^s
Gs的holistic knowledge,用
H
t
∈
R
N
×
g
t
H^t \in R^{N \times g^{t}}
Ht∈RN×gt和
H
s
∈
R
N
×
g
s
H^s \in R^{N \times g^{s}}
Hs∈RN×gs
H
t
=
∑
l
=
0
L
(
D
t
?
1
/
2
A
t
D
t
?
1
/
2
)
l
F
t
θ
l
t
H^t = \sum_{l=0}^{L}{(D_t^{-1/2}A^tD_t^{-1/2})^lF^t\theta_l^t}
Ht=l=0∑L?(Dt?1/2?AtDt?1/2?)lFtθlt?
H
s
=
∑
l
=
0
L
(
D
s
?
1
/
2
A
s
D
s
?
1
/
2
)
l
F
s
θ
l
s
H^s = \sum_{l=0}^{L}{(D_s^{-1/2}A^sD_s^{-1/2})^lF^s\theta_l^s}
Hs=l=0∑L?(Ds?1/2?AsDs?1/2?)lFsθls?
其中
g
t
g^t
gt,
g
s
g^s
gs是圖表示的維度,
D
t
=
∑
j
A
i
j
t
D_t=\sum_j{A_{ij}^t}
Dt?=∑j?Aijt?是教師模型的對角線度矩陣,
θ
l
t
\theta_l^t
θlt?,
θ
l
s
\theta_l^s
θls?是可學習的權重,
使用互資訊來蒸餾學生模型,使其最大化
H
t
H^t
Ht和
H
s
H^s
Hs之間的互資訊,
L
H
O
L
W
s
,
θ
t
,
θ
s
=
?
I
(
H
t
,
H
s
)
\underset {W^s,\theta^t,\theta^s}{L_{HOL}} = -I(H^t, H^s)
Ws,θt,θsLHOL??=?I(Ht,Hs)其中
I
(
H
t
,
H
s
)
I(H^t, H^s)
I(Ht,Hs)用InfoNCE estimator來計算
I
(
H
t
,
H
s
)
≥
E
[
1
N
∑
i
=
1
N
l
o
g
e
f
(
h
i
t
,
h
i
s
)
1
N
∑
j
=
1
N
e
f
(
h
i
t
,
h
i
s
)
]
I(H^t, H^s) \geq E[\frac{1}{N}\sum_{i=1}^N{log\frac{e^{f(h_i^t, h_i^s)}}{\frac{1}{N}\sum_{j=1}^N{e^{f(h_i^t, h_i^s)}}}}]
I(Ht,Hs)≥E[N1?i=1∑N?logN1?∑j=1N?ef(hit?,his?)ef(hit?,his?)?]
f
(
.
)
f(.)
f(.)是余弦相似性,
h
i
t
h^t_i
hit?,
h
i
s
h^s_i
his?是實體i由老師模型和學生模型分別學到的表示,
最終holistic知識蒸餾的目標函式是
L
=
L
C
E
+
β
L
H
O
L
L=L_{CE}+\beta L_{HOL}
L=LCE?+βLHOL?
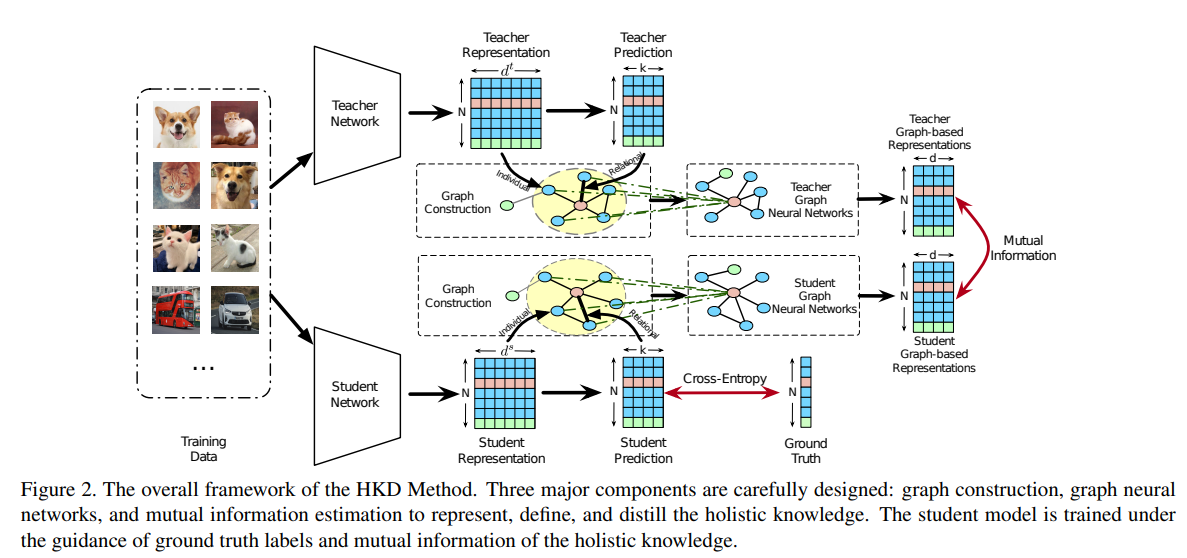
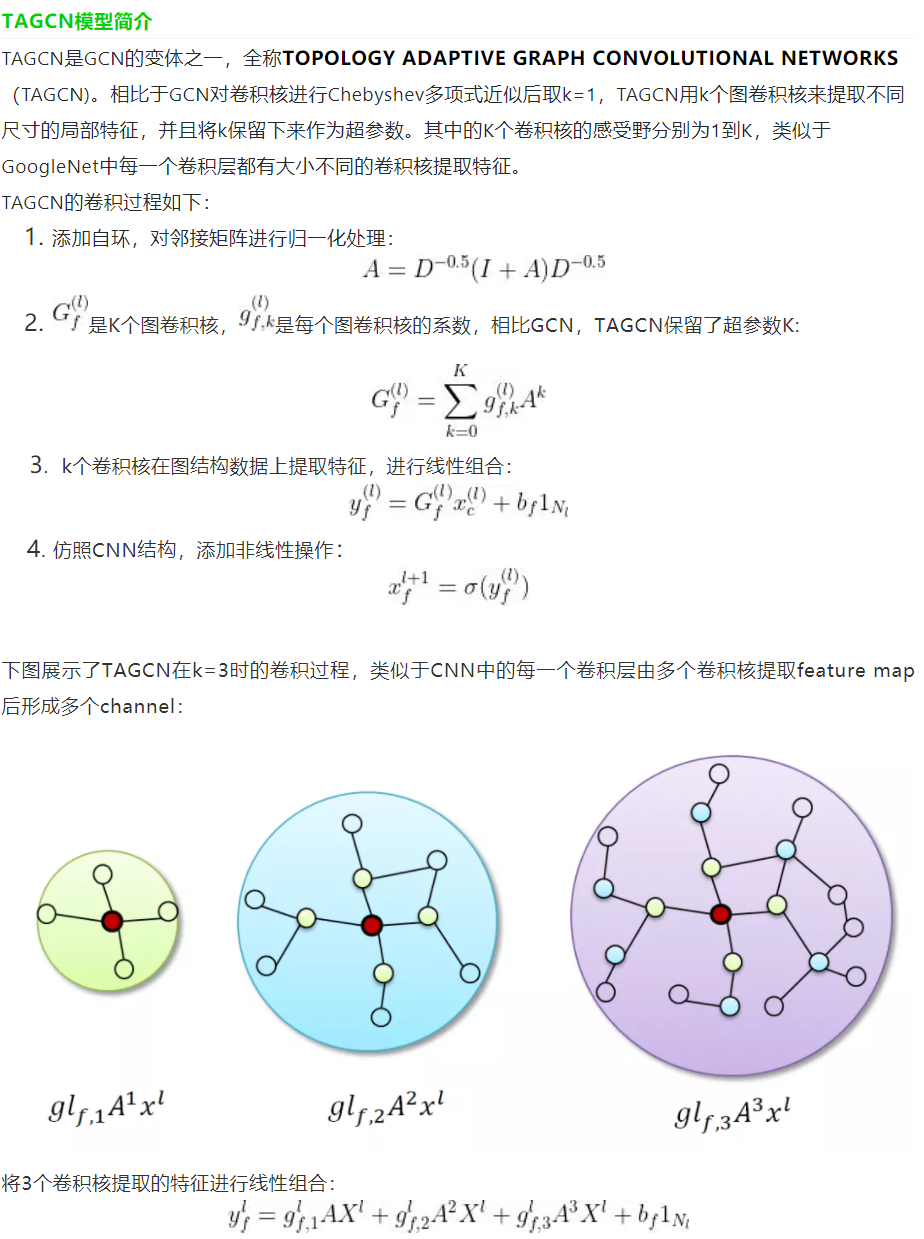
插播TAGCN相關知識(根據參考文獻系列教程GNN-algorithms之六:《多核卷積拓撲圖—TAGCN》):
好吧,不想重復勞動了,直接從參考文獻里截圖了,簡單來說就是把不同階鄰域的特征進行加權聚合,
TAGCN卷積的dgl官方原始碼:
"""Torch Module for Topology Adaptive Graph Convolutional layer"""
import torch as th
from torch import nn
from .... import function as fn
class TAGConv(nn.Module):
def __init__(self,
in_feats,
out_feats,
k=2,
bias=True,
activation=None,
):
super(TAGConv, self).__init__()
self._in_feats = in_feats
self._out_feats = out_feats
self._k = k
self._activation = activation
self.lin = nn.Linear(in_feats * (self._k + 1), out_feats, bias=bias)
self.reset_parameters()
def reset_parameters(self):
gain = nn.init.calculate_gain('relu')
nn.init.xavier_normal_(self.lin.weight, gain=gain)
def forward(self, graph, feat):
with graph.local_scope():
assert graph.is_homogeneous, 'Graph is not homogeneous'
norm = th.pow(graph.in_degrees().float().clamp(min=1), -0.5)
shp = norm.shape + (1,) * (feat.dim() - 1)
norm = th.reshape(norm, shp).to(feat.device) # 貌似就做了個轉置?
#D-1/2 A D -1/2 X
fstack = [feat] # 后面說實話沒怎么懂
for _ in range(self._k):
rst = fstack[-1] * norm
graph.ndata['h'] = rst
graph.update_all(fn.copy_src(src='h', out='m'),
fn.sum(msg='m', out='h'))
rst = graph.ndata['h'] # 單個節點的特征
rst = rst * norm
fstack.append(rst)
rst = self.lin(th.cat(fstack, dim=-1))
if self._activation is not None:
rst = self._activation(rst)
return rst
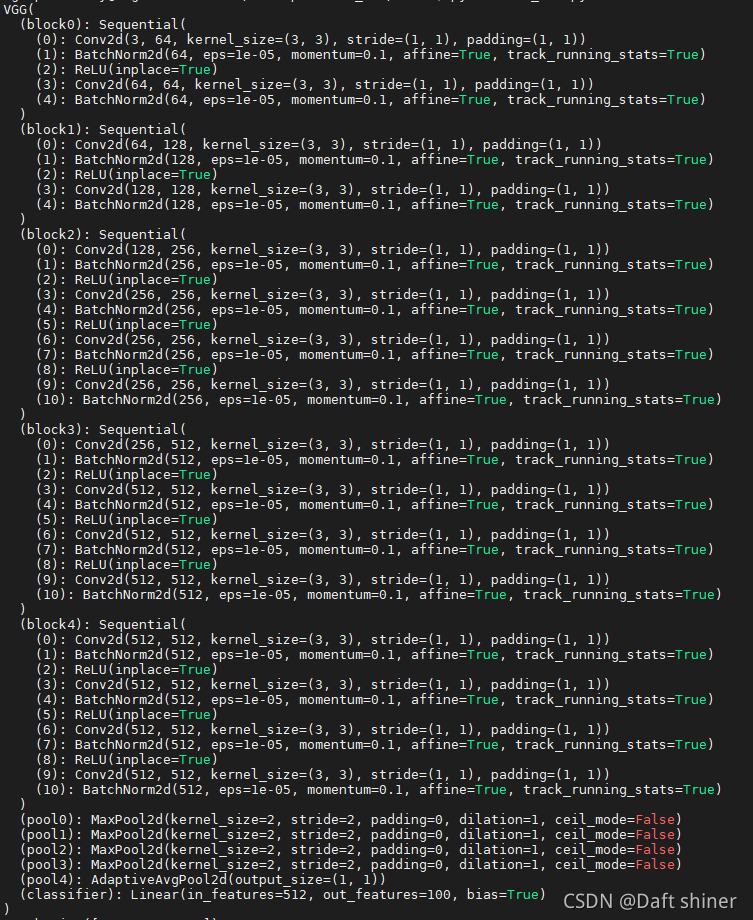
文章所用模型結構VGG19_BN:
Efficient Training
由于InfoNCE estimator需要對資料集中每個樣本作為負樣本計算,對于大資料集成本太高,因此文章使用Memory Bank strategy來儲存,由于文章對mini-batch的樣本進行隨機采樣(吧啦吧啦看不懂,,,不敢亂翻譯,貼原文,如果有人看懂了請評論區踢我一腳)


接著就有了下面的改進版公式:
L
H
O
L
=
∑
i
=
1
N
l
o
g
e
f
(
h
i
t
,
h
i
s
)
e
f
(
h
i
t
,
h
i
s
)
+
∑
j
=
1
,
j
≠
i
N
e
f
(
h
i
t
,
f
j
s
)
+
l
o
g
e
f
(
h
i
s
,
h
i
t
)
e
f
(
h
i
s
,
h
i
t
)
+
∑
j
=
1
,
j
≠
i
N
e
f
(
h
i
s
,
f
j
t
)
L_{HOL}=\sum_{i=1}^N{log\frac{e^{f(h_i^t, h_i^s)}}{e^{f(h_i^t, h_i^s)}+\sum_{j=1,j \neq i}^N{e^{f(h_i^t, f_j^s)}}}}+log\frac{e^{f(h_i^s, h_i^t)}}{e^{f(h_i^s, h_i^t)}+\sum_{j=1,j \neq i}^N{e^{f(h_i^s, f_j^t)}}}
LHOL?=i=1∑N?logef(hit?,his?)+∑j=1,j?=iN?ef(hit?,fjs?)ef(hit?,his?)?+logef(his?,hit?)+∑j=1,j?=iN?ef(his?,fjt?)ef(his?,hit?)?
總體偽代碼,這個還是很好懂的:

接著文章還寫了現有的KD方法的介紹以及對比,這里不再詳述,只看方法的機器,
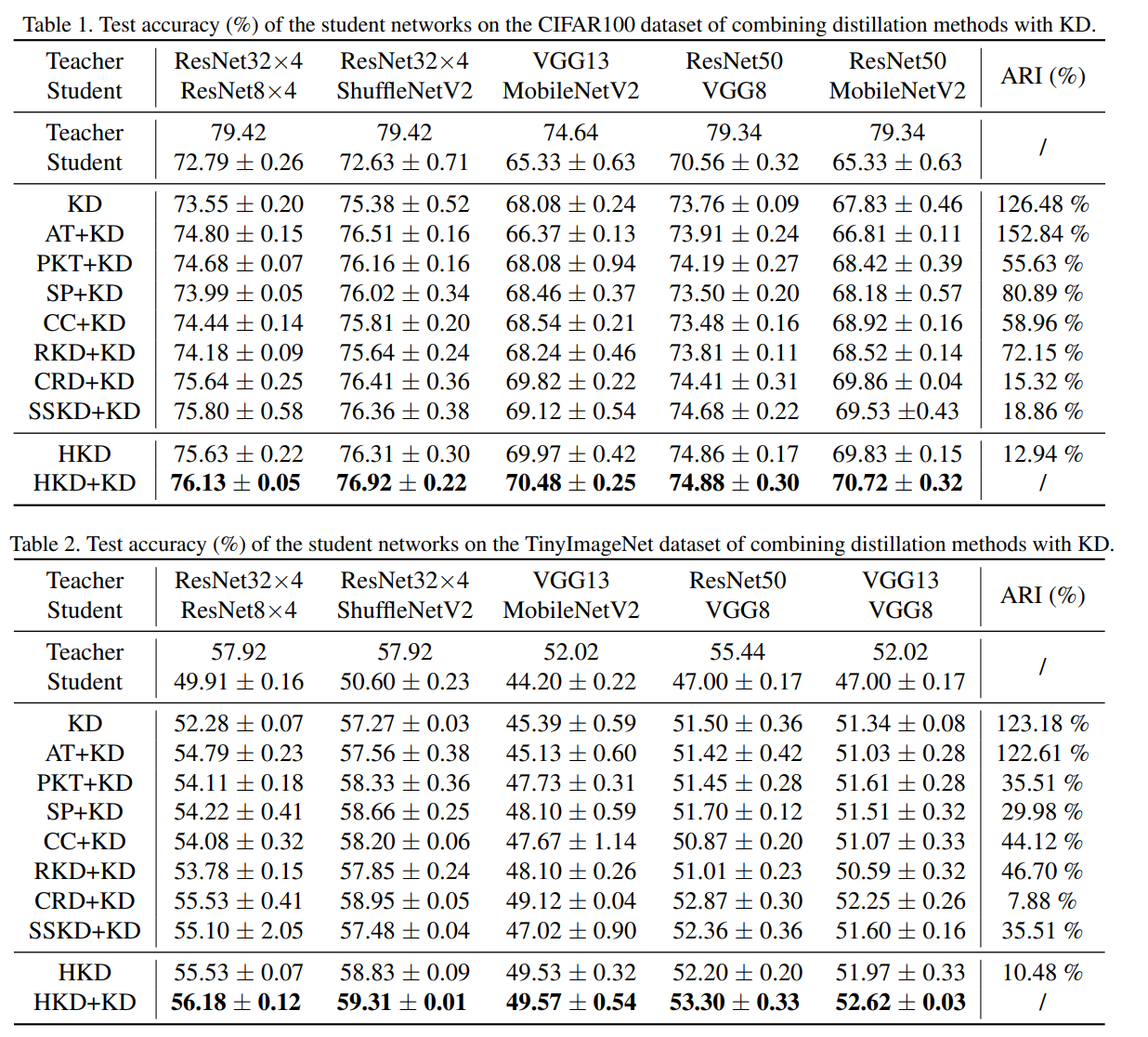
實驗
沒怎么看,這里就隨便放了一個比較的圖,還有其他的一些分析詳見原文,
參考文獻
深度學習中的互資訊:無監督提取特征
Relational Knowledge Distillation解讀
Relational Knowledge Distillation
一文搞懂k近鄰(k-NN)演算法(一)
Python—KNN分類演算法(詳解)
系列教程GNN-algorithms之六:《多核卷積拓撲圖—TAGCN》
Source code for dgl.transform
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301420.html
標籤:AI