目錄
1 匯入庫
2 分析資料
3 構建模型
3.1 定義輸入
3.2 創建模型
3.3 編譯模型
3.4 訓練模型
4 資料預測
1 匯入庫

2 分析資料
我們這次使用資料集是關于廣告與銷量的,名為Advertising

我們打開這個資料集看一下
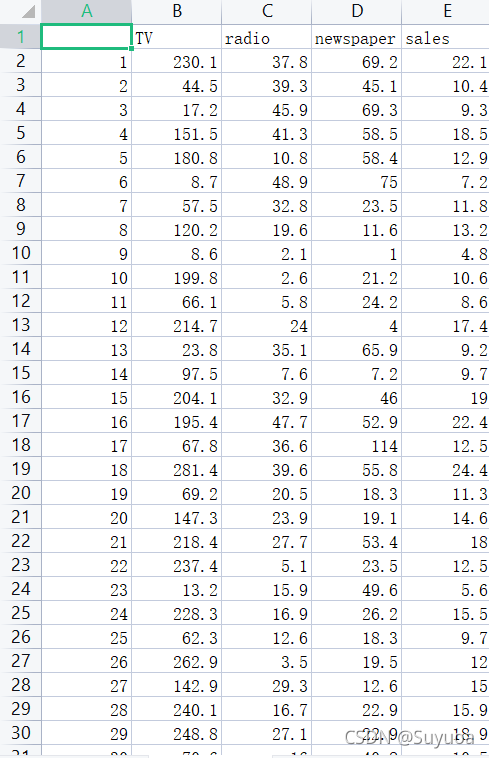
資料為了避免泄露隱私問題,所以資料進行了脫敏處理,所以當前顯示數值中會按照一定計算方法對應另一個現實數值,也就是說當前顯示的數值不直接與顯示掛鉤,今后的資料集大多也都會進行脫敏處理
讀取資料之后我們查看一下前幾行

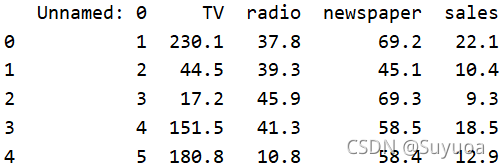
TV,radio,newspaper列下面的數值分別代表電視,廣播,報紙的投放量,sales列代表使用前三種投放量所帶來的銷量
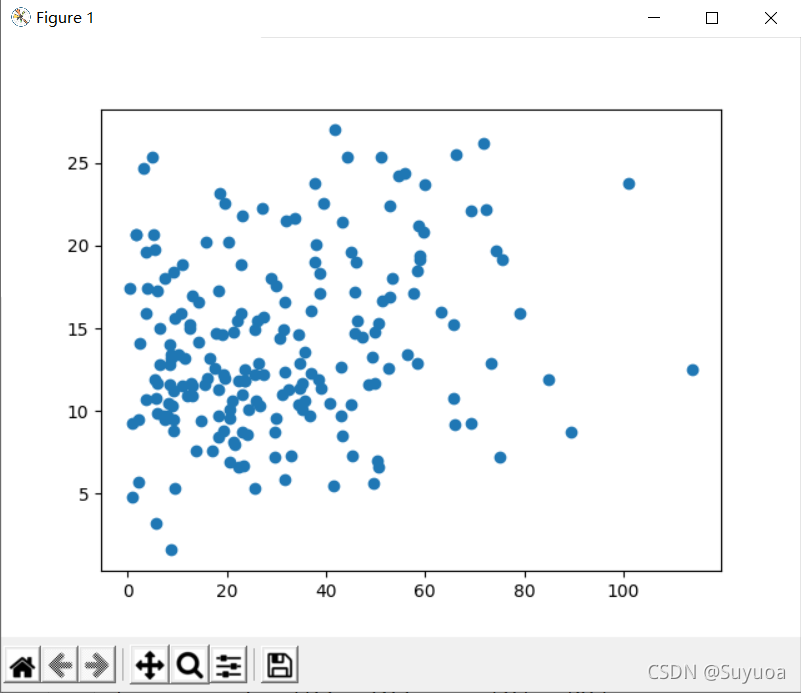
我們從上面的介紹大致能猜一下,如果投放量越多,銷量也就越好,銷量和投放量中有線性的關系,我們下面把資料集作為圖畫出來驗證一下,x軸我們定義為TV的投放量,y軸定義為銷量

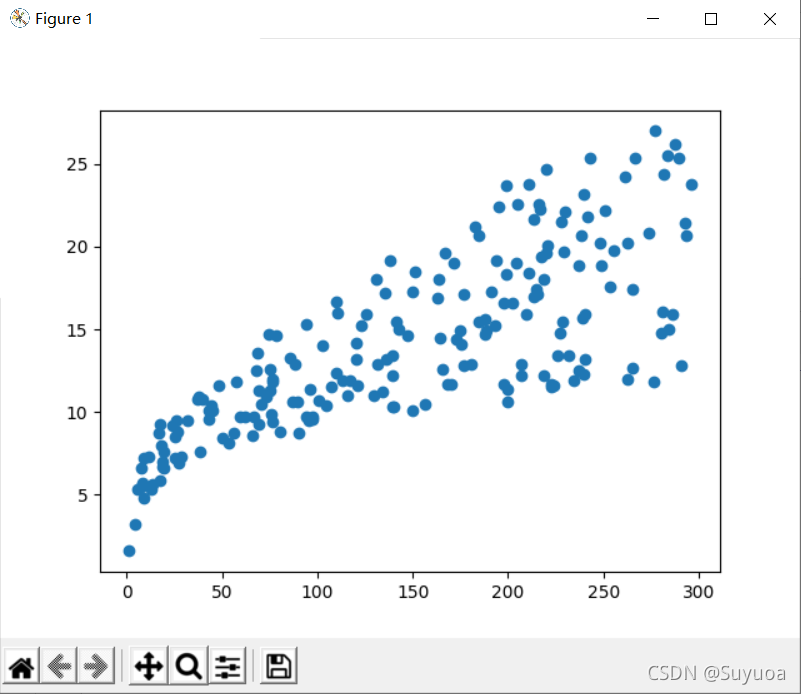
我們通過圖可以看出我們的猜想是基本正確的TV的投放量,銷量也就越高
我們下面再看一下radio與newspaper

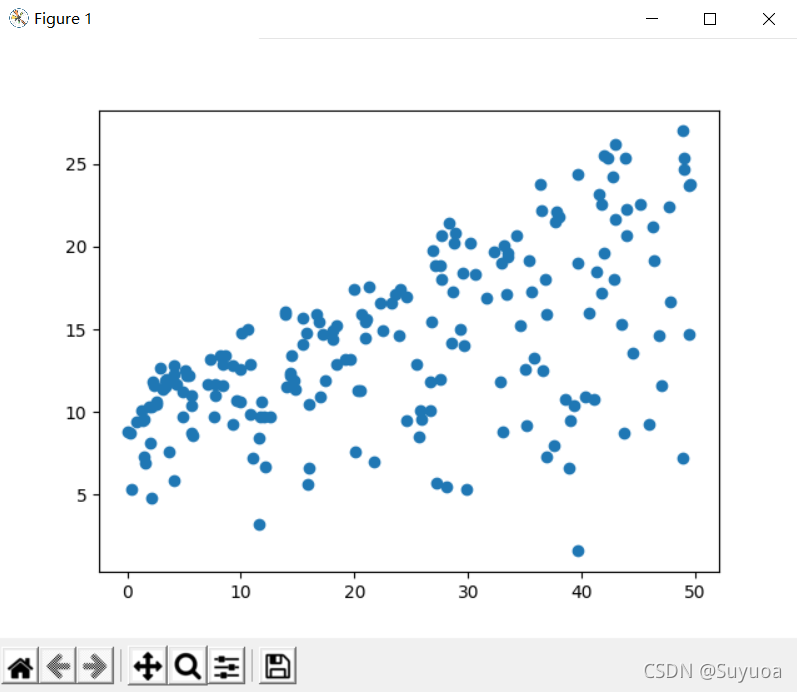
- 廣播投放與銷量隱約也有一種線性關系

- 報紙投放與銷量的線性關系就不是很好
3 構建模型
3.1 定義輸入
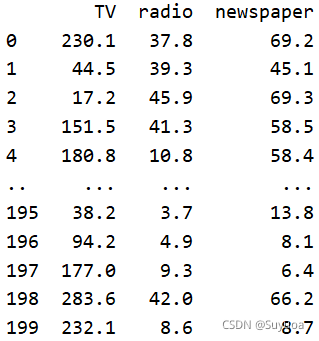
我們的輸入為電視廣播報紙的投放量,我們先把這三列的值取出來
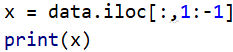
- 上面這個陳述句的意思是除去第一列和最后一列的所有列
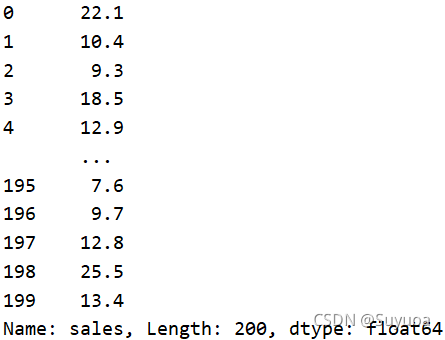
之后我們定義輸入,輸出為csv檔案中的最后一列,這個是我們的銷量

3.2 創建模型
我們可以把層直接寫在Sequential()中,10是意思是該層的神經元個數,input_shape輸入為三維輸入(電視,廣播,報紙分別占一個),后面的一層是輸出層,我們只需要回歸一個結果

我們看一下當前的模型,dense層我們可以理解為該神經元在執行 y = ax + b 這個操作
![]()

這個dense我們可以這樣理解,之前我們做線性回歸的時候,一個dense的神經元有兩個引數,這時因為我們的輸入是一維的,那么我們dense的運算就為 y = ax + b
當前我們的輸入為3維,那么dense的運算就為 y = a1x1 + a2x2 + a3x3 + b,a1,a2,a3是電視,廣播,報紙輸入對應的權重,b是偏置,這樣我們一個神經元就有a1,a2,a3,b這四個引數,我們當前定義了10個神經元,所以第一層的引數為40
那么我們第二個dense層的就是進行了這個操作 y = a1x1 + a2x2 + a3x3 + a4x4 + a5x5 + a6x6 + a7x7 + a8x8 + a9x9 + a10x10 + b,一共有10個引數
3.3 編譯模型
優化器使用adam,損失值使用loss
![]()
3.4 訓練模型
輸入為之前定義的x,輸出為之前定義的y,訓練100次,一個epoch是一次正向轉播加一次反向傳播的程序
![]()
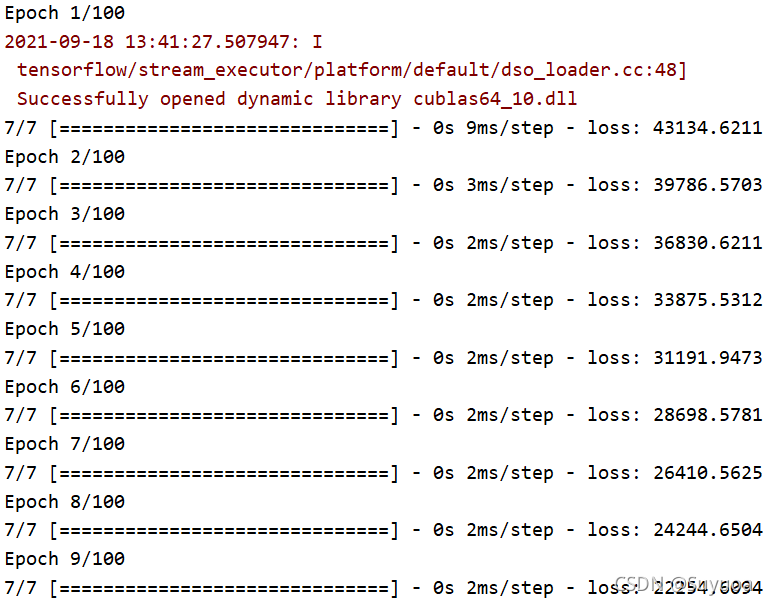
4 資料預測
我們首先定義要預測的資料test,10的意思是我們使用data中的前10行資料,1與-1是從第1列到倒數第2列
![]()
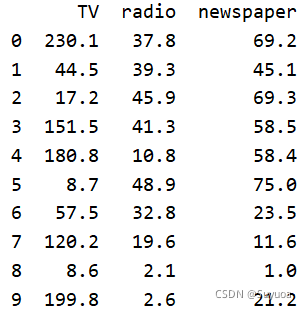
- 寫-1是因為在iloc()中的中括號包含左不包含右
之后我們對test進行預測
![]()

我們再看一下實際的資料,前10行的最后一列
![]()

- 這里的-1與上面的用法不同,我們這個是指定列
我們可以看到預測的資料和原本的資料相似,通過這次的這個代碼和前面的線性回歸我們可以了解到,資料僅僅為數值時,我們使用dense就可以解決問題
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301421.html
標籤:AI
上一篇:Distilling Holistic Knowledge with Graph Neural Networks論文解讀
下一篇:機器學習基礎一站通