目錄
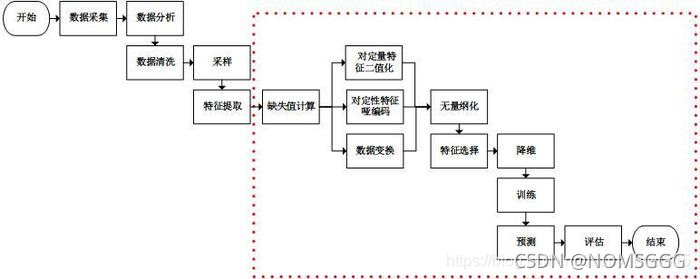
一.流程總覽(本文主要是紅框部分)
二.特征處理部分
1.總體概述
1.1一些常見問題
2.具體處理(具體順序看上面紅框)
2.1缺失值處理(刪or填)
2.2資料格式處理(資料集劃分,時間格式等)
2.3資料采樣(過采樣or下采樣,不均衡時候用)
2.4資料預處理(把原資料 轉更好用形式→標準,歸一,二值)
2.5 特征提取(把文字轉為可以用的→字典,中英文,DNA,TF)
2.6 降維(過濾(低方差,相關系數),PCA)
2.7 特征工程實體:泰坦尼克號生存可能性分析
三.常用SKlearn演算法
1.咋判斷用啥演算法
2.具體演算法與其代碼
2.1分類方法(KNN,邏輯回歸,RF,樸素貝葉斯,SVM)
2.2 回歸方法(KNN,嶺回歸)
2.3 聚類方法(K-means)
四.評估
參考該文章
五.調優
1.先試試資料與預處理
2.然后才是選擇模型,調模型引數
2.1網格搜索(grid search)
2.2隨機尋優方法(隨機試試)
2.3貝葉斯優化方法
2.4基于梯度的優化方法
2.5遺傳演算法(進化尋優)
六.一些實體
1.案例:預測facebook簽到位置
2.案例:20類新聞分類
3.案例:波士頓房價預測
4.案例:癌癥分類預測-良/惡性乳腺癌腫瘤預測
七.模型的保存與加載
一.流程總覽(本文主要是紅框部分)
二.特征處理部分
簡介:本節主要內容來自
【特征工程】嘔心之作——深度了解特征工程_wx:wu805686220-CSDN博客特征工程介紹_遠方-CSDN博客
1.總體概述
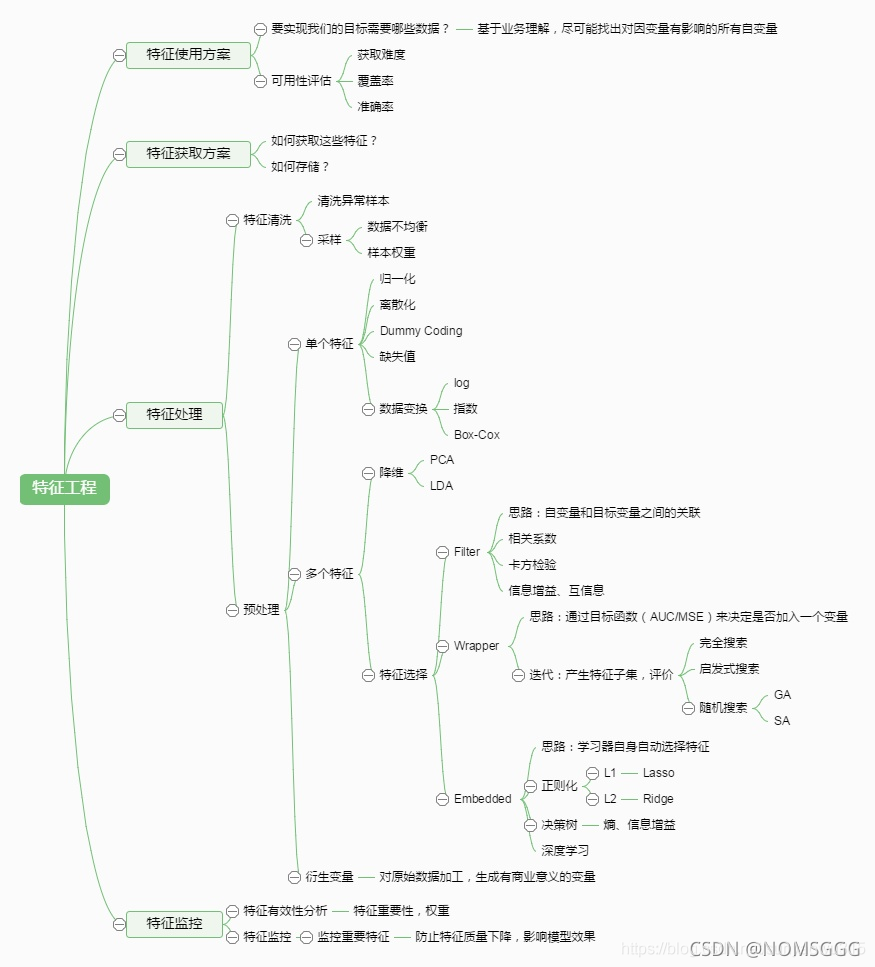
1.1一些常見問題
(1)存在缺失值:缺失值需要補充( .dropna等)
(2)不屬于同一量綱:即特征的規格不一樣,不能夠放在一起比較 (標準化)
(3)資訊冗余:某些定量特征,區間劃分> 如學習成績,若只關心“及格”或不“及格”,那么將考分,轉換成“1”和“0” 表示及格和未及格 (where >60..)
(4)定性特征不能直接使用:需要將定性特征轉換為定量特征(如one-hot,TF等)
(5)資訊利用率低:不同的機器學習
演算法和模型對資料中資訊的利用是不同的,選個合適的模型
2.具體處理(具體順序看上面紅框)
2.1缺失值處理(刪or填)
1)缺失值洗掉(dropna)
2)缺失值填充(fillna):比較常用,一般用均值or眾數
①用固定值填充
對于特征值缺失的一種常見的方法就是可以用固定值來填充,例如0,-99, 如下面對這一列缺失值全部填充為-99
data['第一列'] = data['第一列'].fillna('-99')②用均值填充
對于數值型的特征,其缺失值也可以用未缺失資料的均值填充,下面對灰度分這個特征缺失值進行均值填充
data['第一列'] = data['第一列'].fillna(data['第一列'].mean()))③用眾數填充
與均值類似,可以用眾數來填充缺失值
data['第一列'] = data['第一列'].fillna(data['第一列'].mode()))其他填充如插值,KNN,RF詳見原博客
2.2資料格式處理(資料集劃分,時間格式等)
1)資料集的劃分
一般的資料集會劃分為兩個部分:
- 訓練資料:用于訓練,構建模型
- 測驗資料:在模型檢驗時使用,用于評估模型是否有效
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def datasets_demo():
# 獲取資料集
iris = load_iris()
print("鳶尾花資料集:\n", iris)
print("查看資料集描述:\n", iris["DESCR"])
print("查看特征值的名字:\n", iris.feature_names)
print("查看特征值:\n", iris.data, iris.data.shape) # 150個樣本
# 資料集劃分 X為特征 Y為標簽
"""random_state亂數種子,不同的種子會造成不同的隨機采樣結果"""
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
return None
if __name__ == "__main__":
datasets_demo()
2)時間格式的處理(主要是轉換成年月日or星期幾,然后找自己要的)
詳見https://blog.csdn.net/kobeyu652453/article/details/108894807
# 處理時間資料
import datetime
# 分別得到年,月,日
years = features['year']
months = features['month']
days = features['day']
# datetime格式
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
dates[:5]
3)表格操作,合并連接or取特征啥的
詳見NP,PD教程
2.3資料采樣(過采樣or下采樣,不均衡時候用)
→多的類別過采樣/少的類別欠采樣,來平衡分布,例:信用卡詐騙,騙子的資料太少了,這個時候用
def over_sample( y_origin, threshold):
y = to_one_hot(y_origin, NUM_LABELS)
y_counts = np.sum(y, axis=0)
sample_ratio = threshold / y_counts * y
sample_ratio = np.max(sample_ratio, axis=1)
sample_ratio = np.maximum(sample_ratio, 1)
index = ratio_sample(sample_ratio)
# x_token_train = [x_token_train[i] for i in index]
return y_origin[index]
def ratio_sample(ratio):
sample_times = np.floor(ratio).astype(int)
# random sample ratio < 1 (decimal part)
sample_ratio = ratio - sample_times
random = np.random.uniform(size=sample_ratio.shape)
index = np.where(sample_ratio > random)
index = index[0].tolist()
# over sample fixed integer times
row_num = sample_times.shape[0]
for row_index, times in zip(range(row_num), sample_times):
index.extend(itertools.repeat(row_index, times))
return index2.4資料預處理(把原資料 轉更好用形式→標準,歸一,二值)
主要轉換方式有以下幾種(常用的 前四個):
1)標準化(很常用)
用在:特征之間資料差距特別大(比如存款金額與銀行周圍小區數,不在一個量級)
from sklearn.preprocessing import StandardScaler
#標準化,回傳值為標準化后的資料
StandardScaler().fit_transform(iris.data)2)歸一化
含義:樣本向量在點乘運算或其他核函式計算相似性時,轉化為“單位向量”,
什么情況下(不)需要歸一化:
- 需要: 基于引數的模型或基于距離的模型,都是要進行特征的歸一化,
- 不需要:基于樹的方法是不需要進行特征的歸一化,例如隨機森林,bagging 和 boosting等
from sklearn.preprocessing import Normalizer
#歸一化,回傳值為歸一化后的資料
Normalizer().fit_transform(iris.data)3)二值化(>60分及格,標為1)
用where或者Binarizer
from sklearn.preprocessing import Binarizer
#二值化,閾值設定為3,回傳值為二值化后的資料
Binarizer(threshold=3).fit_transform(iris.data)其他:區間放縮,等距離散啥的,看看原文
2.5 特征提取(把文字轉為可以用的→字典,中英文,DNA,TF)
1)字典特征提取:(字典轉矩陣)
from sklearn.feature_extraction import DictVectorizer
def dict_demo():
data = [{'city':'北京', 'temperature':100},
{'city':'上海', 'temperature':60},
{'city':'深圳', 'temperature':30}]
# 1、實體化一個轉換器類
#transfer = DictVectorizer() # 回傳sparse矩陣
transfer = DictVectorizer(sparse=False)
# 2、呼叫fit_transform()
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new) # 轉化后的
print("特征名字:\n", transfer.get_feature_names())
return None
if __name__ == "__main__":
dict_demo()結果:
data_new:
[[ 0. 1. 0. 100.]
[ 1. 0. 0. 60.]
[ 0. 0. 1. 30.]]
特征名字:
['city=上海', 'city=北京', 'city=深圳', 'temperature']
2)文本特征提取(文本轉矩陣)
應用 1.中英文分詞,然后轉矩陣 2.DNAseqs處理,詞袋模型
2.1)英文文本分詞
from sklearn.feature_extraction.text import CountVectorizer
def count_demo():
data = ['life is short,i like like python',
'life is too long,i dislike python']
# 1、實體化一個轉換器類
transfer = CountVectorizer()
#這里還有一個stop_word(),就是 到哪個詞停下來
transfer1 = CountVectorizer(stop_words=['is', 'too'])
# 2、呼叫fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new.toarray()) # toarray轉換為二維陣列
print("特征名字:\n", transfer.get_feature_names())
return None
if __name__ == "__main__":
count_demo()
結果
data_new:
[[0 1 1 2 0 1 1 0]
[1 1 1 0 1 1 0 1]]
特征名字:
['dislike', 'is', 'life', 'like', 'long', 'python', 'short', 'too']2.2)中文分詞
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def count_chinese_demo2():
data = ['一種還是一種今天很殘酷,明天更殘酷,后天很美好,但絕對大部分是死在明天晚上,所以每個人不要放棄今天,',
'我們看到的從很遠星系來的光是在幾百萬年之前發出的,這樣當我們看到宇宙時,我們是在看它的過去,',
'如果只用一種方式了解某件事物,他就不會真正了解它,了解事物真正含義的秘密取決于如何將其與我們所了解的事物相聯系,']
data_new = []
for sent in data:
data_new.append(cut_word(sent))
print(data_new)
1、實體化一個轉換器類(叫人
transfer = CountVectorizer()
2、呼叫fit_transform(干活
data_final = transfer.fit_transform(data_new)
print("data_final:\n", data_final.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
def cut_word(text):
"""
進行中文分詞:“我愛北京天安門” -> "我 愛 北京 天安門"
"""
return ' '.join(jieba.cut(text))
if __name__ == "__main__":
count_chinese_demo2()
#print(cut_word('我愛北京天安門'))
2.3) Tf-idf文本特征提取:找重要的詞,并轉為矩陣
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
import jieba
def tfidf_demo():
"""
用TF-IDF的方法進行文本特征抽取
"""
data = ['一種還是一種今天很殘酷,明天更殘酷,后天很美好,但絕對大部分是死在明天晚上,所以每個人不要放棄今天,',
'我們看到的從很遠星系來的光是在幾百萬年之前發出的,這樣當我們看到宇宙時,我們是在看它的過去,',
'如果只用一種方式了解某件事物,他就不會真正了解它,了解事物真正含義的秘密取決于如何將其與我們所了解的事物相聯系,']
data_new = []
for sent in data:
data_new.append(cut_word(sent))
print(data_new)
1、實體化一個轉換器類
transfer = TfidfVectorizer()
2、呼叫fit_transform
data_final = transfer.fit_transform(data_new)
print("data_final:\n", data_final.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
def cut_word(text):
"""
進行中文分詞:“我愛北京天安門” -> "我 愛 北京 天安門"
"""
return ' '.join(jieba.cut(text))
if __name__ == "__main__":
tfidf_demo()
#print(cut_word('我愛北京天安門'))
結果:
['一種 還是 一種 今天 很 殘酷 , 明天 更 殘酷 , 后天 很 美好 , 但 絕對 大部分 是 死 在 明天 晚上 , 所以 每個 人 不要 放棄 今天 ,', '我們 看到 的 從 很 遠 星系 來 的 光是在 幾百萬年 之前 發出 的 , 這樣 當 我們 看到 宇宙 時 , 我們 是 在 看 它 的 過去 ,', '如果 只用 一種 方式 了解 某件事 物 , 他 就 不會 真正 了解 它 , 了解 事物 真正 含義 的 秘密 取決于 如何 將 其 與 我們 所 了解 的 事物 相 聯系 ,']
data_final:
[[0.30847454 0. 0.20280347 0. 0. 0.
0.40560694 0. 0. 0. 0. 0.
0.20280347 0. 0.20280347 0. 0. 0.
0. 0.20280347 0.20280347 0. 0.40560694 0.
0.20280347 0. 0.40560694 0.20280347 0. 0.
0. 0.20280347 0.20280347 0. 0. 0.20280347
0. ]
[0. 0. 0. 0.2410822 0. 0.
0. 0.2410822 0.2410822 0.2410822 0. 0.
0. 0. 0. 0. 0. 0.2410822
0.55004769 0. 0. 0. 0. 0.2410822
0. 0. 0. 0. 0.48216441 0.
0. 0. 0. 0. 0.2410822 0.
0.2410822 ]
[0.12826533 0.16865349 0. 0. 0.67461397 0.33730698
0. 0. 0. 0. 0.16865349 0.16865349
0. 0.16865349 0. 0.16865349 0.16865349 0.
0.12826533 0. 0. 0.16865349 0. 0.
0. 0.16865349 0. 0. 0. 0.33730698
0.16865349 0. 0. 0.16865349 0. 0.
0. ]]
特征名字:
['一種', '不會', '不要', '之前', '了解', '事物', '今天', '光是在', '幾百萬年', '發出', '取決于', '只用', '后天', '含義', '大部分', '如何', '如果', '宇宙', '我們', '所以', '放棄', '方式', '明天', '星系', '晚上', '某件事', '殘酷', '每個', '看到', '真正', '秘密', '絕對', '美好', '聯系', '過去', '還是', '這樣']2.4)DNAseqs處理
1.先把seqs資料切開,6個堿基一組
def Kmers_funct(seq, size=6):
return [seq[x:x+size] for x in range(len(seq) - size + 1)]
2.再用CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(ngram_range=(4,4))
X = cv.fit_transform(textsList)
3.轉換完,丟去訓練2.6 降維(過濾(低方差,相關系數),PCA)
啥意思:降低隨機變數(特征)個數,得到一組主變數的程序(就是減少訓練的列數)
1) 特征選擇(從原特征中找出重要的特征→人與狗的差別:皮膚,身高等)
第一種:低方差過濾(丟掉不重要的
from sklearn.feature_selection import VarianceThreshold
def variance_demo():
"""
低方差特征過濾
"""
# 1、獲取資料
data = pd.read_csv('factor_returns.csv')
print('data:\n', data)
data = data.iloc[:,1:-2]
print('data:\n', data)
# 2、實體化一個轉換器類
#transform = VarianceThreshold()
transform = VarianceThreshold(threshold=10)
# 3、呼叫fit_transform
data_new = transform.fit_transform(data)
print("data_new\n", data_new, data_new.shape)
return None
if __name__ == "__main__":
variance_demo()
第二種:相關系數(也是丟掉不重要的,不過用相關系數來判斷)
from sklearn.feature_selection import VarianceThreshold
from scipy.stats import pearsonr
def variance_demo():
"""
低方差特征過濾 相關系數
"""
# 1、獲取資料
data = pd.read_csv('factor_returns.csv')
print('data:\n', data)
data = data.iloc[:,1:-2]
print('data:\n', data)
# 2、實體化一個轉換器類
transform = VarianceThreshold()
transform1 = VarianceThreshold(threshold=10)
# 3、呼叫fit_transform
data_new = transform.fit_transform(data)
print("data_new\n", data_new, data_new.shape)
# 計算兩個變數之間的相關系數
r = pearsonr(data["pe_ratio"],data["pb_ratio"])
print("相關系數:\n", r)
return None
if __name__ == "__main__":
variance_demo()2)PCA
主要注意n_compnents:小數→表示保留百分之多少的資訊,整數→減少到多少特征
from sklearn.decomposition import PCA
def pca_demo():
"""
PCA降維
"""
data = [[2,8,4,5], [6,3,0,8], [5,4,9,1]]
# 1、實體化一個轉換器類
transform = PCA(n_components=2) # 4個特征降到2個特征
# 2、呼叫fit_transform
data_new = transform.fit_transform(data)
print("data_new\n", data_new)
transform2 = PCA(n_components=0.95) # 保留95%的資訊
data_new2 = transform2.fit_transform(data)
print("data_new2\n", data_new2)
return None
if __name__ == "__main__":
pca_demo()
2.7 特征工程實體:泰坦尼克號生存可能性分析
上述部分我自己比較常用的(本人比較菜),具體別的方法可以看看原文
下面為案例代碼
import pandas as pd
1、獲取資料
path = "C:/DataSets/titanic.csv"
titanic = pd.read_csv(path) #1313 rows × 11 columns
# 篩選特征值和目標值
x = titanic[["pclass", "age", "sex"]]
y = titanic["survived"]
2、資料處理
# 1)缺失值處理
x["age"].fillna(x["age"].mean(), inplace=True)
# 2)轉換成字典
x = x.to_dict(orient="records")
3、資料集劃分
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
4、對x_train,test 字典特征抽取
from sklearn.feature_extraction import DictVectorizer
transfer = DictVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
5.決策樹預估器
from sklearn.tree import DecisionTreeClassifier, export_graphviz
estimator = DecisionTreeClassifier(criterion='entropy')
estimator.fit(x_train, y_train)
6.模型評估
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接必讀真實值和預測值:\n", y_test == y_predict) # 直接比對
# 方法2:計算準確率
score = estimator.score(x_test, y_test) # 測驗集的特征值,測驗集的目標值
print("準確率:", score)
# 可視化決策樹(非必要)
export_graphviz(estimator, out_file='titanic_tree.dot', feature_names=transfer.get_feature_names())
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plot_tree(decision_tree=estimator)
plt.show()
三.常用SKlearn演算法
本文主要內容來自 機器學習種9種常用演算法_不凡De老五-CSDN博客_機器學習常用演算法
1.咋判斷用啥演算法
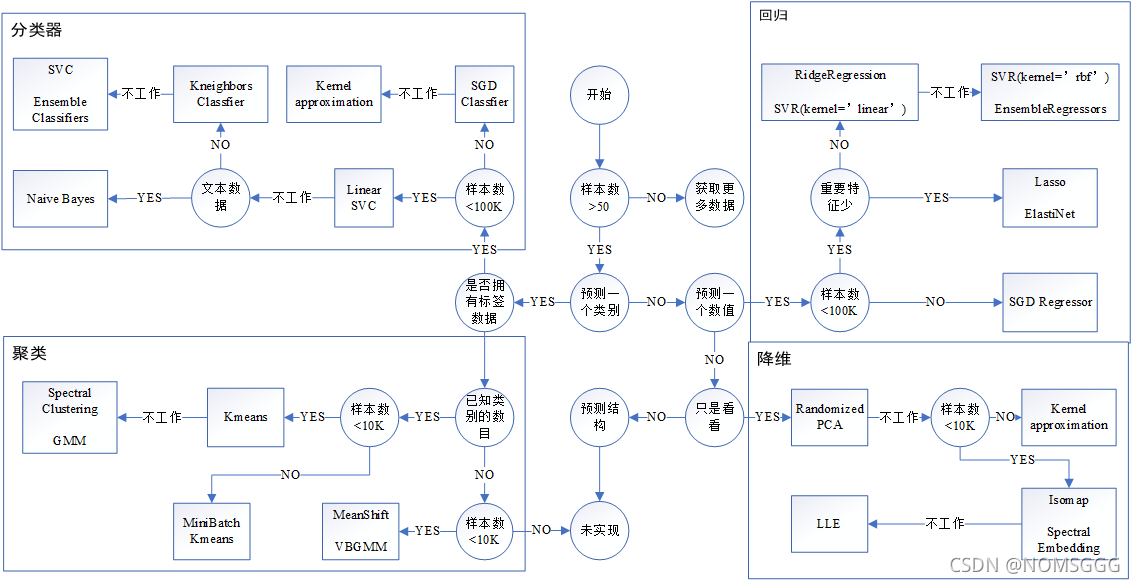
2.具體演算法與其代碼
基本都是四步走:導包(from...),建模(knn=...),訓練與預測(.fit() .predict())
2.1分類方法(KNN,邏輯回歸,RF,樸素貝葉斯,SVM)
2.1.1 KNN(回歸,分類都可以用)
簡介:
k近鄰分類(KNN)演算法,是從訓練集中找到和新資料最接近的k條記錄,然后根據他們的主要分類來決定新資料的類別,
該演算法涉及3個要點:訓練集、距離或相似的衡量、k的大小,
優點:適合多分類問題
簡單,易于理解,易于實作,無需估計引數,無需訓練
適合對稀有事件進行分類(例如當流失率很低時,比如低于0.5%,構造流失預測模型)
特別適合于多分類問題(物件具有多個類別標簽),例如根據基因特征來判斷其功能分類,kNN比SVM的表現要好
缺點:記憶體開銷大,比較慢
懶惰演算法,對測驗樣本分類時的計算量大,記憶體開銷大,評分慢
可解釋性較差,無法給出決策樹那樣的規則,
實作代碼:
1.匯入:
分類問題:
from sklearn.neighbors import KNeighborsClassifier
回歸問題:
from sklearn.neighbors import KNeighborsRegressor
2.創建模型
KNC = KNeighborsClassifier(n_neighbors=5)
KNR = KNeighborsRegressor(n_neighbors=3)
3.訓練
KNC.fit(X_train,y_train)
KNR.fit(X_train,y_train)
4.預測
y_pre = KNC.predict(x_test)
y_pre = KNR.predict(x_test)2.1.2邏輯回歸(logiscic):
簡介:可以看成更準的線性回歸
利用Logistics回歸進行分類的主要思想是:根據現有資料對分類邊界線建立回歸公式,以此進行分類,這里的“回歸” 一詞源于最佳擬合,表示要找到最佳擬合引數集,
訓練分類器時的做法就是尋找最佳擬合引數,使用的是最優化演算法,接下來介紹這個二值型輸出分類器的數學原理
代碼:
1.匯入
from sklearn.linear_model import LogisticRegression
2.創建模型
logistic = LogisticRegression(solver='lbfgs')
注:solver引數的選擇:
“liblinear”:小數量級的資料集 <5~10k
“lbfgs”, “sag” or “newton-cg”:大數量級的資料集以及多分類問題 <30k
“sag”:極大的資料集 >30k
3.訓練
logistic.fit(x_train,y_train)
4.預測
y_pre = logistic.predict(x_train,y_train)
2.1.3隨機森林(很常用)
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import numpy as np
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['is_train'] = np.random.uniform(0, 1, len(df)) <= .75
df['species'] = pd.Factor(iris.target, iris.target_names)
df.head()
train, test = df[df['is_train']==True], df[df['is_train']==False]
features = df.columns[:4]
clf = RandomForestClassifier(n_jobs=2)
y, _ = pd.factorize(train['species'])
clf.fit(train[features], y)
preds = iris.target_names[clf.predict(test[features])]
pd.crosstab(test['species'], preds, rownames=['actual'], colnames=['preds'])簡版:
# 匯入演算法
from sklearn.ensemble import RandomForestRegressor
# 建模
rf = RandomForestRegressor(n_estimators= 1000, random_state=42)
# 訓練
rf.fit(train_features, train_labels)
# 預測
y_pre=rf.predict(test_features)2.1.4樸素貝葉斯
簡介:樸素貝葉斯,就是變數相互獨立情況下的貝葉斯,不要被名字唬住了
-
1、高斯(正態)分布樸素貝葉斯
-
用于一般分類問題
-
使用:
1.匯入 from sklearn.naive_bayes import GaussianNB 2.創建模型 gNB = GaussianNB() 3.訓練 gNB.fit(data,target) 4.預測 y_pre = gNB.predict(x_test)2、多項式分布樸素貝葉斯(還有一個伯努利分布,和這個類似,小數量時候用)
- 適用于文本資料(特征表示的是次數,例如某個詞語的出現次數)
- DNA序列作為特征時候可以用(其實也是文本,只不過是AGCT)
- 常用于多分類問題
-
使用
1.匯入 from sklearn.naive_bayes import MultinomialNB 2.創建模型 mNB = MultinomialNB() 3.字符集轉換為詞頻 from sklearn.feature_extraction.text import TfidfVectorizer #先構建Tf物件(啥是Tf上面有講) tf = TfidfVectorizer() #使用要轉換的資料集和標簽集對tf物件進行訓練 tf.fit(X_train,y_train) #文本集 ----> 詞頻集 X_train_tf = tf.transform(X_train) 4.使用詞頻集對機器學習模型進行訓練 mNB.fit(X_train_tf,y_train) 5.預測 #將字符集轉化為詞頻集 x_test = tf.transform(test_str) #預測 mNB.predict(x_test)
2.1.5支持向量機SVM
簡介:SVM的思路是找到離超平面的最近點,通過其約束條件求出最優解,
使用
1.匯入
處理分類問題:
from sklearn.svm import SVC
處理回歸問題:
from sklearn.svm import SVR
2.創建模型(回歸時使用SVR)
svc = SVC(kernel='linear')
svc = SVC(kernel='rbf')
svc = SVC(kernel='poly')
3.訓練
svc_linear.fit(X_train,y_train)
svc_rbf.fit(X_train,y_train)
svc_poly.fit(X_train,y_train)
4.預測
linear_y_ = svc_linear.predict(x_test)
rbf_y_ = svc_rbf.predict(x_test)
poly_y_ = svc_poly.predict(x_test)
2.2 回歸方法(KNN,嶺回歸)
2.2.1KNN(同上)
2.2.2嶺回歸(ridge)
簡介:就是改良的最小二乘法配上線性回歸,一定程度避免過擬合與欠擬合
#1.匯入
from sklearn.linear_model import Ridge
#2.創建模型
# alpha就是縮減系數lambda,可以自己二分法試試效果
# 如果把alpha設定為0,就是普通線性回歸
ridge = Ridge(alpha=0)
#3.訓練
ridge.fit(data,target)
#4.預測
target_pre = ridge.predict(target_test)2.2.3lasso回歸
2.2.4RF(同上)
2.2.5支持向量機SVM(同上)
2.3 聚類方法(K-means)
K均值演算法(K-means) (無監督學習)
原理
- 聚類的概念:一種無監督的學習,事先不知道類別,自動將相似的物件歸到同一個簇中,
- K-Means演算法是一種聚類分析(cluster analysis)的演算法,其主要是來計算資料聚集的演算法,主要通過不斷地取離種子點最近均值的演算法,
代碼:
1.匯入
from sklearn.cluster import KMeans
2.創建模型
# 構建機器學習物件kemans,指定要分類的個數
kmean = KMeans(n_clusters=2)
3.訓練資料
# 注意:聚類演算法是沒有y_train的
kmean.fit(X_train)
4.預測資料
y_pre = kmean.predict(X_train)
四.評估
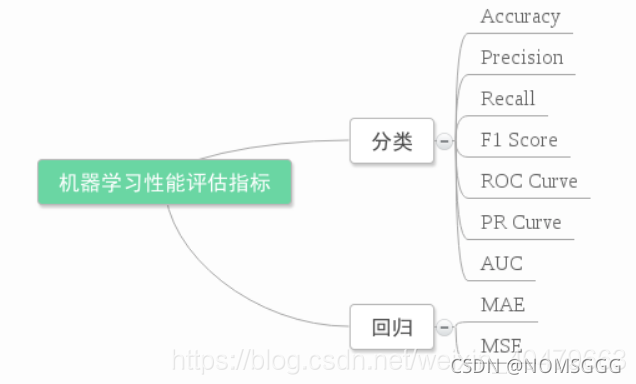
參考該文章
機器學習訓練建模、集成模型、模型評估等代碼總結(2019.05.21更新)_呆萌的代Ma-CSDN博客
五.調優
1.先試試資料與預處理
優先在資料本身和預處理,特征工程方面下功夫(選更鮮明的特征,資料夠干凈,壓縮程度等)
2.然后才是選擇模型,調模型引數
2.1網格搜索(grid search)
簡介:Grid search 是一種暴力的調參方法,通過遍歷所有可能的引數值以獲取所有所有引陣列合中最優的引陣列合,(就是一個個引數試)
代碼:
#y = data['diagnosis']
#x = data.drop(['id','diagnosis','Unnamed: 32'],axis =1)
from sklearn.model_selection import train_test_split,GridSearchCV
#from sklearn.pipeline import Pipeline
#from sklearn.linear_model import LogisticRegression
#from sklearn.preprocessing import StandardScaler
#train_X,val_X,train_y,val_y = train_test_split(x,y,test_size=0.2,random_state=1)
pipe_lr = Pipeline([('scl',StandardScaler()),('clf',LogisticRegression(random_state=0))])
param_range=[0.0001,0.001,0.01,0.1,1,10,100,1000] 要試啥數字
param_penalty=['l1','l2']
param_grid=[{'clf__C':param_range,'clf__penalty':param_penalty}]
gs = GridSearchCV(estimator=pipe_lr,
param_grid=param_grid,
scoring='f1',
cv=10,
n_jobs=-1)
gs = gs.fit(train_X,train_y)
print(gs.best_score_)
print(gs.best_params_)
2.2隨機尋優方法(隨機試試)
代碼:
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestRegressor
iris = load_iris()
rf = RandomForestRegressor(random_state = 42)
from sklearn.model_selection import RandomizedSearchCV
random_grid = {'n_estimators': n_estimators,
'max_features': max_features,
'max_depth': max_depth,
'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf,
'bootstrap': bootstrap}
rf_random = RandomizedSearchCV(estimator = rf, param_distributions = random_grid, n_iter = 100, cv = 3, verbose=2, random_state=42, n_jobs = -1)# Fit the random search model
rf_random.fit(X,y)
#print the best score throughout the grid search
print rf_random.best_score_
#print the best parameter used for the highest score of the model.
print rf_random.best_param_下面三種沒有固定代碼,得看具體專案需要
2.3貝葉斯優化方法
2.4基于梯度的優化方法
2.5遺傳演算法(進化尋優)
六.一些實體
1.案例:預測facebook簽到位置

流程分析:
1)獲取資料
2)資料處理
目的:
- 特征值 x:2<x<2.5
- 目標值y:1.0<y<1.5
- time -> 年與日時分秒
- 過濾簽到次數少的地點
3)特征工程:標準化
4)KNN演算法預估流程
5)模型選擇與調優
6)模型評估import pandas as pd # 1、獲取資料 data = pd.read_csv("./FBlocation/train.csv") #29118021 rows × 6 columns # 2、基本的資料處理 # 1)縮小資料范圍 data = data.query("x<2.5 & x>2 & y<1.5 & y>1.0") #83197 rows × 6 columns # 2)處理時間特征 time_value = pd.to_datetime(data["time"], unit="s") #Name: time, Length: 83197 date = pd.DatetimeIndex(time_value) data["day"] = date.day data["weekday"] = date.weekday data["hour"] = date.hour data.head() #83197 rows × 9 columns # 3)過濾簽到次數少的地點 place_count = data.groupby("place_id").count()["row_id"] #2514 rows × 8 columns place_count[place_count > 3].head() data_final = data[data["place_id"].isin(place_count[place_count>3].index.values)] data_final.head() #80910 rows × 9 columns # 篩選特征值和目標值 x = data_final[["x", "y", "accuracy", "day", "weekday", "hour"]] y = data_final["place_id"] # 資料集劃分 from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y) from sklearn.preprocessing import StandardScaler from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import GridSearchCV # 3、特征工程:標準化 transfer = StandardScaler() x_train = transfer.fit_transform(x_train) # 訓練集標準化 x_test = transfer.transform(x_test) # 測驗集標準化 # 4、KNN演算法預估器 estimator = KNeighborsClassifier() # 加入網格搜索與交叉驗證 # 引數準備 param_dict = {"n_neighbors": [3,5,7,9]} estimator = GridSearchCV(estimator, param_grid=param_dict, cv=5) # 10折,資料量不大,可以多折 estimator.fit(x_train, y_train) # 5、模型評估 # 方法1:直接比對真實值和預測值 y_predict = estimator.predict(x_test) print("y_predict:\n", y_predict) print("直接必讀真實值和預測值:\n", y_test == y_predict) # 直接比對 # 方法2:計算準確率 score = estimator.score(x_test, y_test) # 測驗集的特征值,測驗集的目標值 print("準確率:", score) # 查看最佳引數:best_params_ print("最佳引數:", estimator.best_params_) # 最佳結果:best_score_ print("最佳結果:", estimator.best_score_) # 最佳估計器:best_estimator_ print("最佳估計器:", estimator.best_estimator_) # 交叉驗證結果:cv_results_ print("交叉驗證結果:", estimator.cv_results_)2.案例:20類新聞分類
1 步驟分析
1)獲取資料
2)劃分資料集
3)特征工程:文本特征抽取
4)樸素貝葉斯預估器流程
5)模型評估
2 具體代碼
from sklearn.model_selection import train_test_split # 劃分資料集
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer # 文本特征抽取
from sklearn.naive_bayes import MultinomialNB # 樸素貝葉斯
def nb_news():
"""
用樸素貝葉斯演算法對新聞進行分類
:return:
"""
# 1)獲取資料
news = fetch_20newsgroups(subset='all')
# 2)劃分資料集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target)
# 3)特征工程:文本特征抽取
transfer = TfidfVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)樸素貝葉斯演算法預估器流程
estimator = MultinomialNB()
estimator.fit(x_train, y_train)
# 5)模型評估
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接必讀真實值和預測值:\n", y_test == y_predict) # 直接比對
# 方法2:計算準確率
score = estimator.score(x_test, y_test) # 測驗集的特征值,測驗集的目標值
print("準確率:", score)
return None
if __name__ == "__main__":
nb_news()
3.案例:波士頓房價預測
1 基本介紹

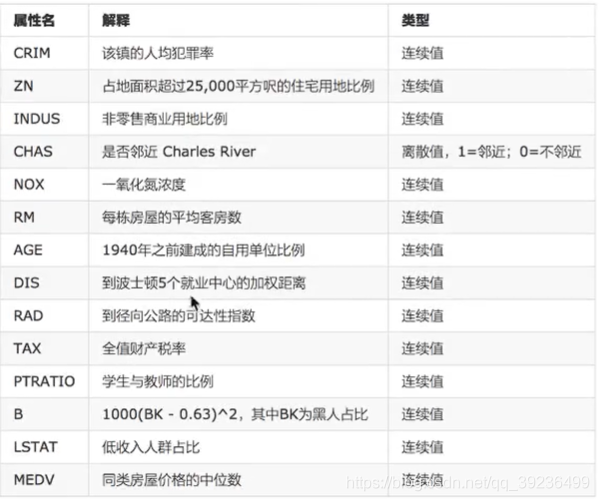
流程:
1)獲取資料集
2)劃分資料集
3)特征工程:無量綱化 - 標準化
4)預估器流程:fit() -> 模型,coef_ intercept_
5)模型評估
2 回歸性能評估
均方誤差(MSE)評價機制
3 代碼
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, SGDRegressor
from sklearn.metrics import mean_squared_error
def linner1():
"""
正規方程的優化方法
:return:
"""
# 1)獲取資料
boston = load_boston()
# 2)劃分資料集
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)
# 3)標準化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)預估器
estimator = LinearRegression()
estimator.fit(x_train, y_train)
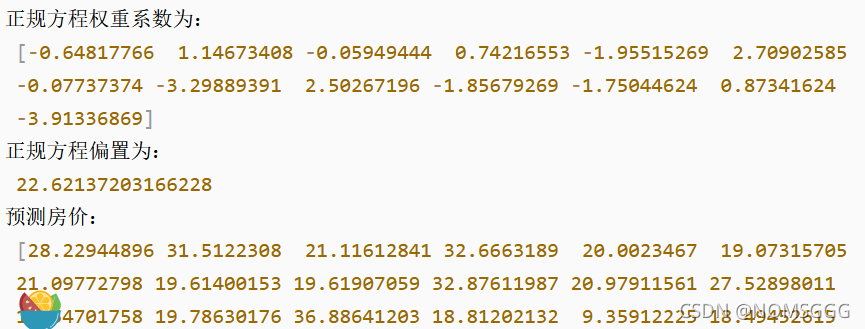
# 5)得出模型
print("正規方程權重系數為:\n", estimator.coef_)
print("正規方程偏置為:\n", estimator.intercept_)
# 6)模型評估
y_predict = estimator.predict(x_test)
print("預測房價:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("正規方程-均分誤差為:\n", error)
return None
def linner2():
"""
梯度下降的優化方法
:return:
"""
# 1)獲取資料
boston = load_boston()
print("特征數量:\n", boston.data.shape) # 幾個特征對應幾個權重系數
# 2)劃分資料集
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)
# 3)標準化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)預估器
estimator = SGDRegressor(learning_rate="constant", eta0=0.001, max_iter=10000)
estimator.fit(x_train, y_train)
# 5)得出模型
print("梯度下降權重系數為:\n", estimator.coef_)
print("梯度下降偏置為:\n", estimator.intercept_)
# 6)模型評估
y_predict = estimator.predict(x_test)
print("預測房價:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("梯度下降-均分誤差為:\n", error)
return None
if __name__ == '__main__':
linner1()
linner2()
4.案例:癌癥分類預測-良/惡性乳腺癌腫瘤預測
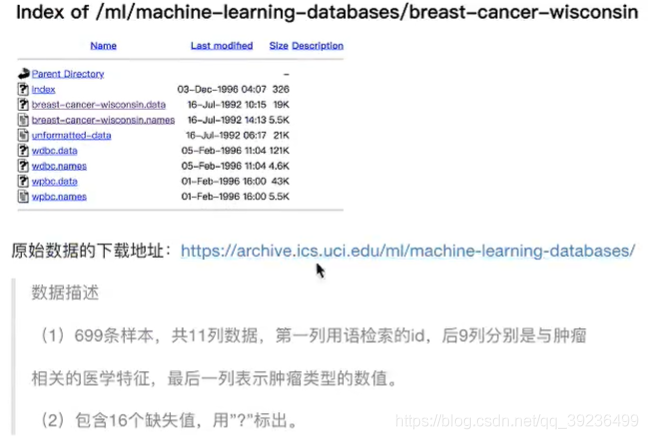
流程分析:
1)獲取資料:讀取的時候加上names
2)資料處理:處理缺失值
3)資料集劃分
4)特征工程:無量綱化處理—標準化
5)邏輯回歸預估器
6)模型評估
具體代碼
import pandas as pd
import numpy as np
# 1、讀取資料
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data"
column_name = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin',
'Normal Nucleoli', 'Mitoses', 'Class']
data = pd.read_csv(path, names=column_name) #699 rows × 11 columns
# 2、缺失值處理
# 1)替換-》np.nan
data = data.replace(to_replace="?", value=np.nan)
# 2)洗掉缺失樣本
data.dropna(inplace=True) #683 rows × 11 columns
# 3、劃分資料集
from sklearn.model_selection import train_test_split
# 篩選特征值和目標值
x = data.iloc[:, 1:-1]
y = data["Class"]
x_train, x_test, y_train, y_test = train_test_split(x, y)
# 4、標準化
from sklearn.preprocessing import StandardScaler
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
from sklearn.linear_model import LogisticRegression
# 5、預估器流程
estimator = LogisticRegression()
estimator.fit(x_train, y_train)
# 邏輯回歸的模型引數:回歸系數和偏置
estimator.coef_ # 權重
estimator.intercept_ # 偏置
# 6、模型評估
# 方法1:直接比對真實值和預測值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比對真實值和預測值:\n", y_test == y_predict)
# 方法2:計算準確率
score = estimator.score(x_test, y_test)
print("準確率為:\n", score)
七.模型的保存與加載
import joblib
保存:joblib.dump(rf, ‘test.pkl’)
加載:estimator = joblib.load(‘test.pkl’)案例:
1、保存模型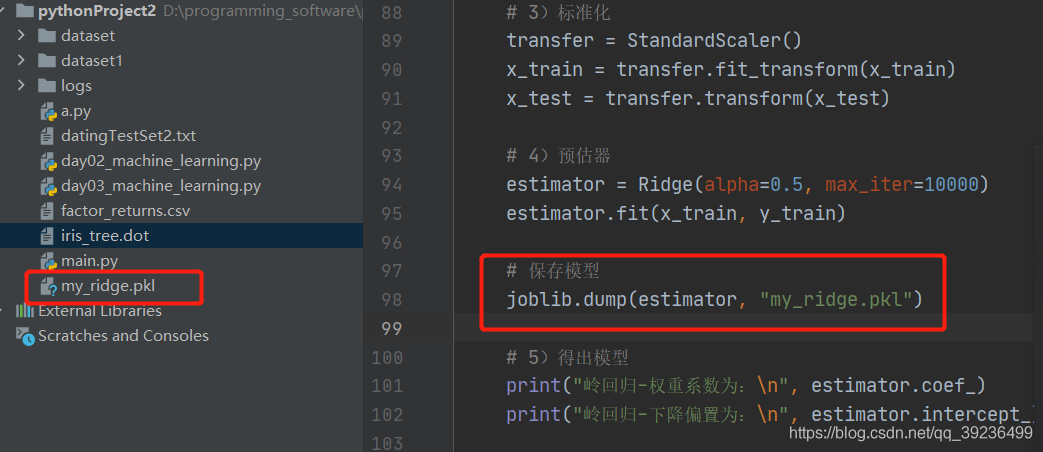
2、加載模型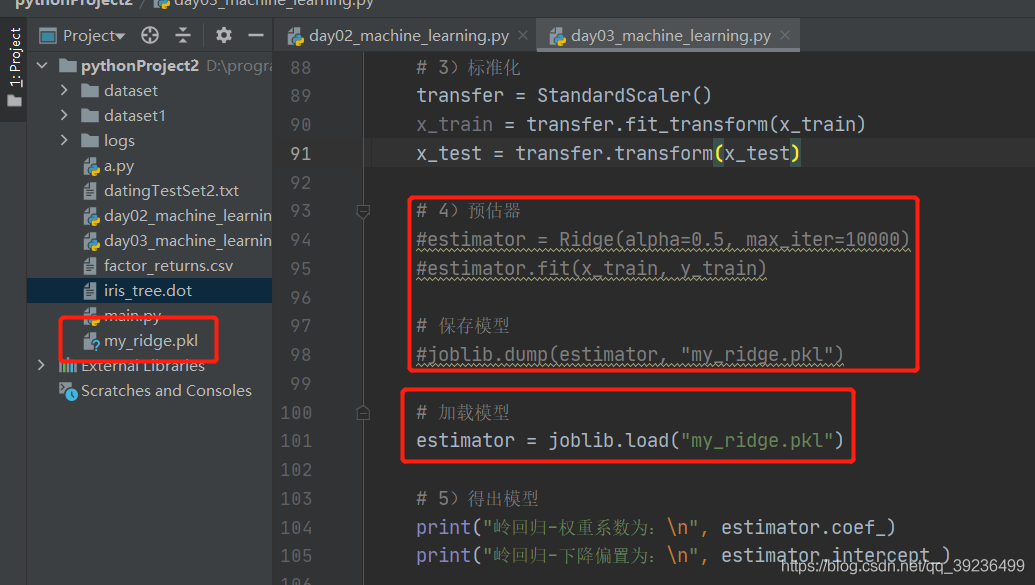
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301422.html
標籤:AI