本文目錄
- 針對詞語
- 針對句子
- 針對文章
針對詞語
關鍵詞提取
TF-IDF
TF-IDF是一種統計方法,用以評估一字詞對于一個檔案集或一個語料庫中的其中一份檔案的重要程度,字詞的重要性隨著它在檔案中出現的次數成正比增加,但同時會隨著它在語料庫中出現的頻率成反比下降,TF-IDF加權的各種形式常被搜索引擎應用,作為檔案與用戶查詢之間相關程度的度量或評級,除了TF-IDF以外,因特網上的搜索引擎還會使用基于鏈接分析的評級方法,以確定檔案在搜尋結果中出現的順序,
詞頻(Term Frequency ): 𝑡𝑓𝑡,𝑑 =𝑐𝑜𝑢𝑛𝑡(𝑡, 𝑑)
逆檔案頻率(Inverse Document Frequency): 𝑖𝑑𝑓𝑡 = log10(𝑁/𝑑𝑓𝑡)
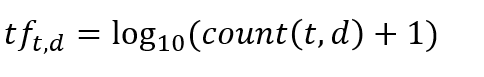

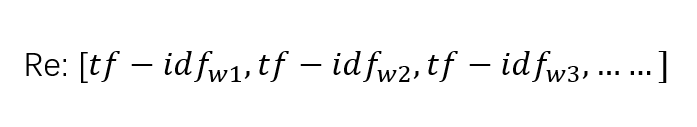
Text-Rank
先介紹下PageRank,
谷歌的兩位創始人的佩奇和布林,借鑒了學術界評判學術論文重要性的通用方法,“那就是看論文的參考次數”,由此想到網頁的重要性也可以根據這種方法來評價,于是PageRank的核心思想就誕生了:
如果一個網頁被很多其他網頁鏈接到的話說明這個網頁比較重要,也就是PageRank值會相對較高
如果一個PageRank值很高的網頁鏈接到一個其他的網頁,那么被鏈接到的網頁的PageRank值會相應地因此而提高
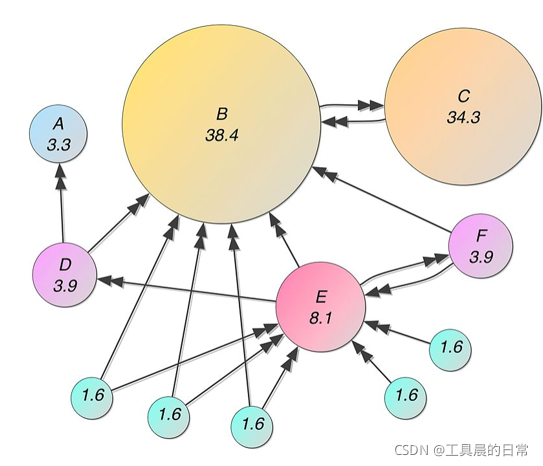
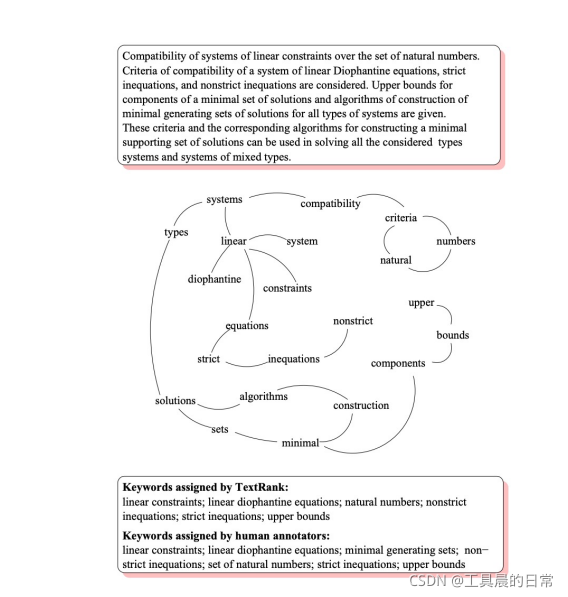
Text-Rank
- 如果一個單詞出現在很多單詞后面的話,那么說明這個單詞比較重要
- 一個TextRank值很高的單詞后面跟著的一個單詞,那么這個單詞的TextRank值會相應地因此而提高
針對句子
分句-NLTP工具
- 輸入:句子或者句子序列的混合物
- 輸出:單個句子的序列
分詞-結巴分詞
使用案例
import sys
sys.path.append("../")
import jieba
import jieba.posseg
import jieba.analyse
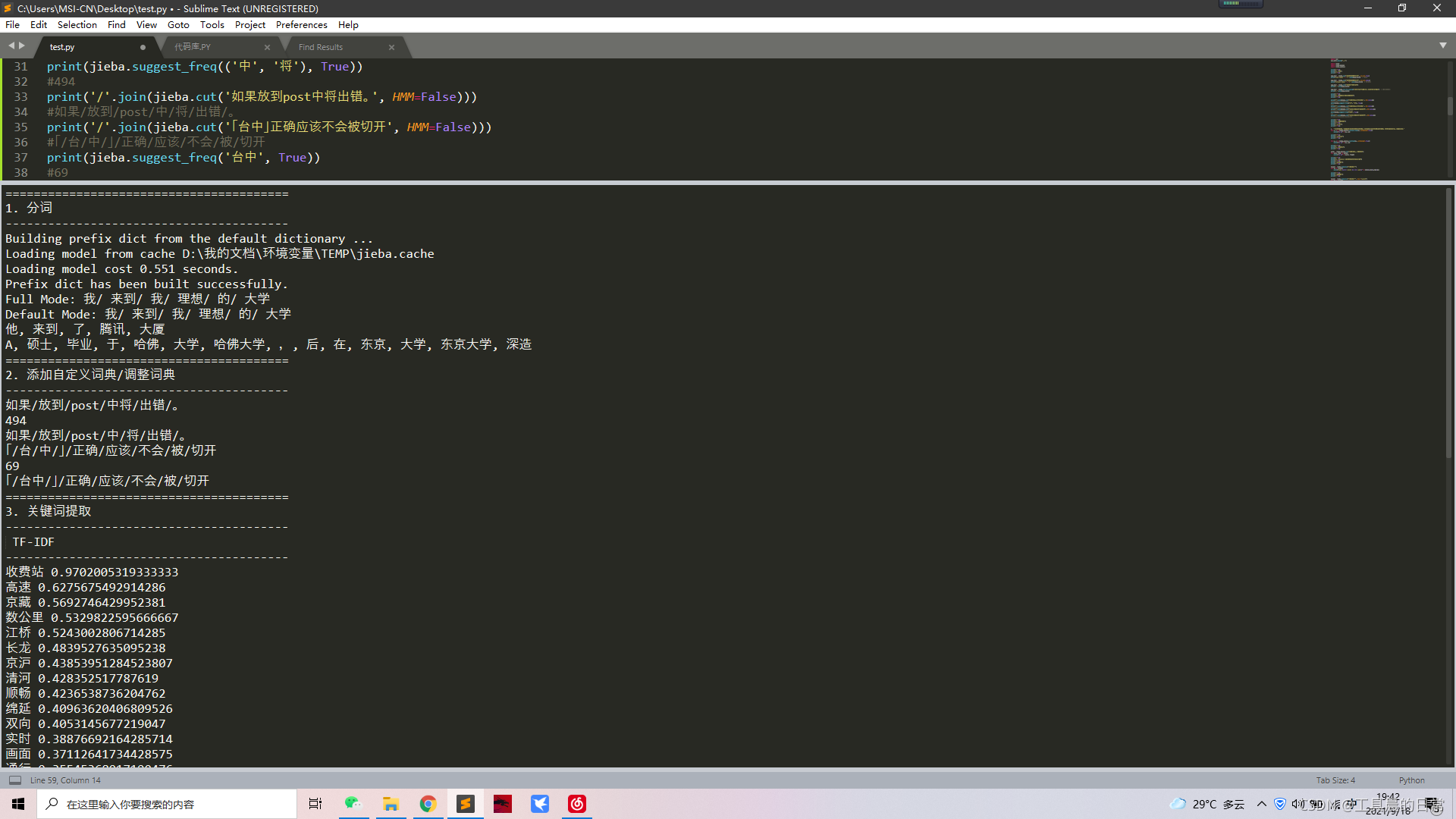
print('='*40)
print('1. 分詞')
print('-'*40)
seg_list = jieba.cut("我來到我理想的大學", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我來到我理想的大學", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 默認模式
seg_list = jieba.cut("他來到了騰訊大廈")
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("A碩士畢業于哈佛大學,后在東京大學深造") # 搜索引擎模式
print(", ".join(seg_list))
print('='*40)
print('2. 添加自定義詞典/調整詞典')
print('-'*40)
print('/'.join(jieba.cut('如果放到post中將出錯,', HMM=False)))
#如果/放到/post/中將/出錯/,
print(jieba.suggest_freq(('中', '將'), True))
#494
print('/'.join(jieba.cut('如果放到post中將出錯,', HMM=False)))
#如果/放到/post/中/將/出錯/,
print('/'.join(jieba.cut('「臺中」正確應該不會被切開', HMM=False)))
#「/臺/中/」/正確/應該/不會/被/切開
print(jieba.suggest_freq('臺中', True))
#69
print('/'.join(jieba.cut('「臺中」正確應該不會被切開', HMM=False)))
#「/臺中/」/正確/應該/不會/被/切開
print('='*40)
print('3. 關鍵詞提取')
print('-'*40)
print(' TF-IDF')
print('-'*40)
s = "從實時畫面看,京藏高速北京清河收費站雙向順暢,京滬高速上海江橋收費站通行緩慢,車輛已經排起長龍,綿延數公里,"
for x, w in jieba.analyse.extract_tags(s, withWeight=True):
print('%s %s' % (x, w))
print('-'*40)
print(' TextRank')
print('-'*40)
for x, w in jieba.analyse.textrank(s, withWeight=True):
print('%s %s' % (x, w))
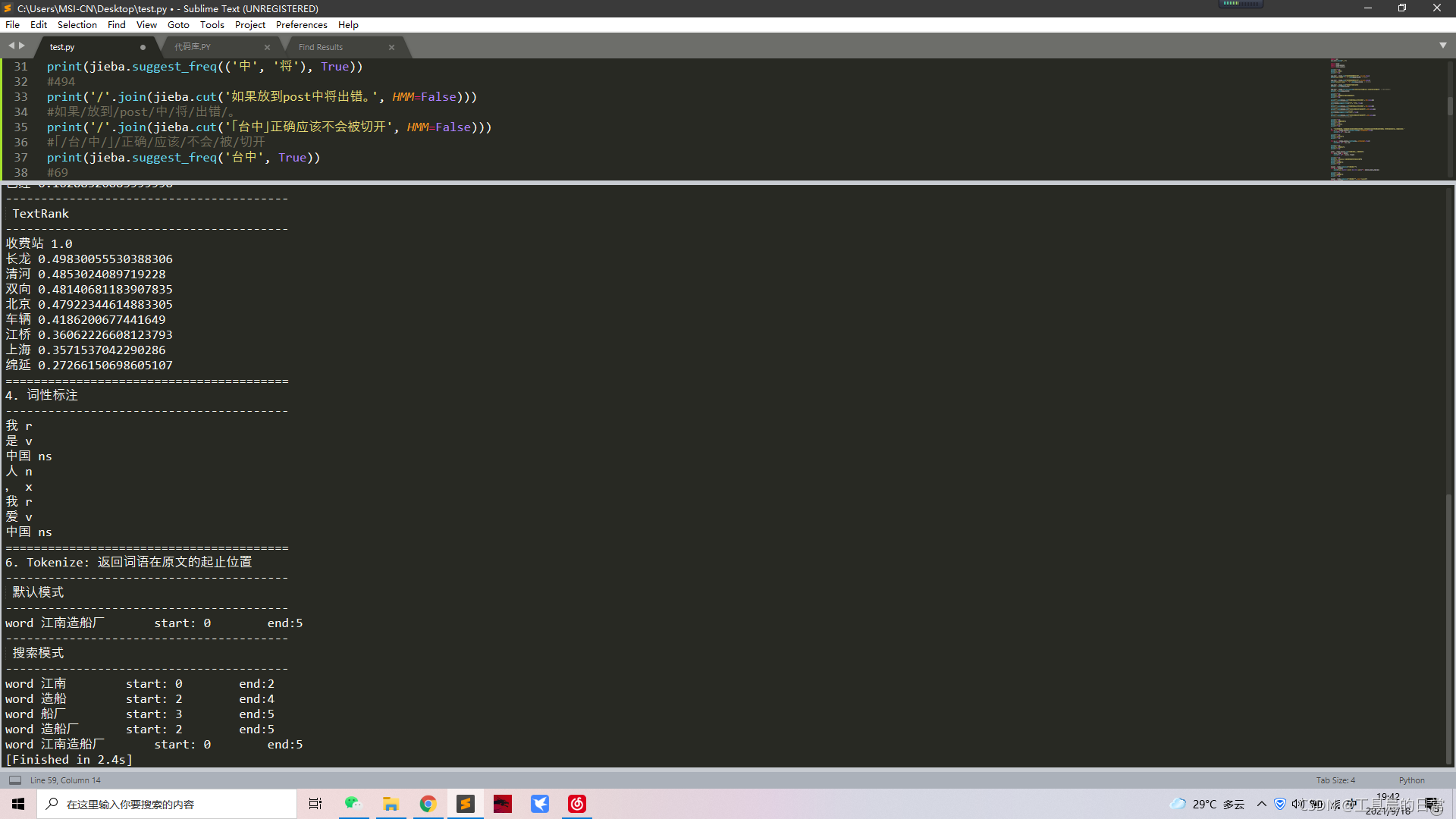
print('='*40)
print('4. 詞性標注')
print('-'*40)
words = jieba.posseg.cut("我是中國人,我愛中國")
for word, flag in words:
print('%s %s' % (word, flag))
print('='*40)
print('6. Tokenize: 回傳詞語在原文的起止位置')
print('-'*40)
print(' 默認模式')
print('-'*40)
result = jieba.tokenize('江南造船廠')
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
print('-'*40)
print(' 搜索模式')
print('-'*40)
result = jieba.tokenize('江南造船廠', mode='search')
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
命名物體識別
詳見
詞性標注
詞性標注(Part-Of-Speech tagging, POS tagging)也被稱為語法標注(grammatical tagging)或詞類消疑(word-category disambiguation),是語料庫語言學(corpus linguistics)中將語料庫內單詞的詞性按其含義和背景關系內容進行標記的文本資料處理技術 [1-2] ,
詞性標注可以由人工或特定演算法完成,使用機器學習(machine learning)方法實作詞性標注是自然語言處理(Natural Language Processing, NLP)的研究內容,常見的詞性標注演算法包括隱馬爾可夫模型(Hidden Markov Model, HMM)、條件隨機場(Conditional random fields, CRFs)等 [2-3] ,
詞性標注主要被應用于文本挖掘(text mining)和NLP領域,是各類基于文本的機器學習任務,例如語意分析(semantic analysis)和指代消解(coreference resolution)的預處理步驟,
依存分析
基于依存文法的句法分析,分析結果為句子中詞語間依存關系組成的依存樹,
序列標注
序列標注是NLP中一個重要的任務,它包括分詞、詞性標注、命名物體識別等等,一般使用以下方法解決:
- HMM 隱馬爾可夫模型
- CRF 條件隨機場
- BiLSTM+CRF
- Lattice+LSTM+CRF
- BERT+CRF
針對文章
PLSA
PLSA是一個詞袋模型(BOW, Bag Of Word),它不考慮詞在檔案中出現的順序,但可以把詞在檔案中的權重考慮進來,
SVD奇異值分解
對矩陣分解從而得到特征
對于奇異值,它跟我們特征分解中的特征值類似,在奇異值矩陣中也是按照從大到小排列,而且奇異值的減少特別的快,在很多情況下,前10%甚至1%的奇異值的和就占了全部的奇異值之和的99%以上的比例,
LDA
線性判別式分析(Linear Discriminant Analysis),簡稱為LDA,也稱為Fisher線性判別(Fisher Linear Discriminant,FLD),是模式識別的經典演算法,在1996年由Belhumeur引入模式識別和人工智能領域,
基本思想是將高維的模式樣本投影到最佳鑒別矢量空間,以達到抽取分類資訊和壓縮特征空間維數的效果,投影后保證模式樣本在新的子空間有最大的類間距離和最小的類內距離,即模式在該空間中有最佳的可分離性,
LDA與前面介紹過的PCA都是常用的降維技術,PCA主要是從特征的協方差角度,去找到比較好的投影方式,LDA更多的是考慮了標注,即希望投影后不同類別之間資料點的距離更大,同一類別的資料點更緊湊,
EM演算法
最大期望演算法(Expectation-Maximization algorithm, EM),或Dempster-Laird-Rubin演算法 [1] ,是一類通過迭代進行極大似然估計(Maximum Likelihood Estimation, MLE)的優化演算法 [2] ,通常作為牛頓迭代法(Newton-Raphson method)的替代用于對包含隱變數(latent variable)或缺失資料(incomplete-data)的概率模型進行引數估計 [2-3] ,
EM演算法的標準計算框架由E步(Expectation-step)和M步(Maximization step)交替組成,演算法的收斂性可以確保迭代至少逼近區域極大值 [4] ,EM演算法是MM演算法(Minorize-Maximization algorithm)的特例之一,有多個改進版本,包括使用了貝葉斯推斷的EM演算法、EM梯度演算法、廣義EM演算法等 [2] ,
由于迭代規則容易實作并可以靈活考慮隱變數 [3] ,EM演算法被廣泛應用于處理資料的缺測值 [1-2] ,以及很多機器學習(machine learning)演算法,包括高斯混合模型(Gaussian Mixture Model, GMM) [5] 和隱馬爾可夫模型(Hidden Markov Model, HMM) [6] 的引數估計,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301428.html
標籤:AI