【NLP】??學不會打我! 半小時學會基本操作 8?? 新聞分類
- 概述
- TF-IDF 關鍵詞提取
- TF
- IDF
- TF-IDF
- TfidfVectorizer
- 資料介紹
- 代碼實作
概述
從今天開始我們將開啟一段自然語言處理 (NLP) 的旅程. 自然語言處理可以讓來處理, 理解, 以及運用人類的語言, 實作機器語言和人類語言之間的溝通橋梁.

TF-IDF 關鍵詞提取
TF-IDF (Term Frequency-Inverse Document Frequency), 即詞頻-逆檔案頻率是一種用于資訊檢索與資料挖掘的常用加權技術. TF-IDF 可以幫助我們挖掘文章中的關鍵詞. 通過數值統計, 反映一個詞對于語料庫中某篇文章的重要性.
TF
TF (Term Frequency), 即詞頻. 表示詞在文本中出現的頻率.
公式:
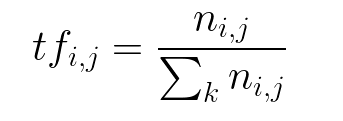
IDF
IDF (Inverse Document Frequency), 即逆檔案頻率. 表示語料庫中包含詞的檔案的數目的倒數.
公式:
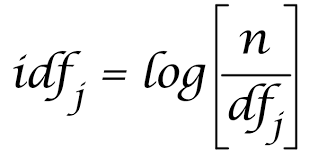
TF-IDF
公式:
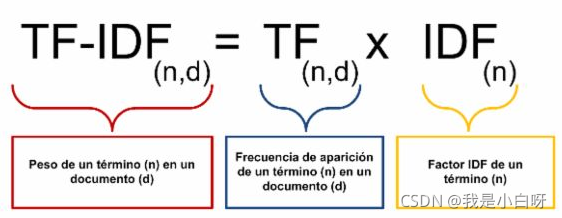
TF-IDF = (詞的頻率 / 句子總字數) × (總檔案數 / 包含該詞的檔案數)
如果一個詞非常常見, 那么 IDF 就會很低, 反之就會很高. TF-IDF 可以幫助我們過濾常見詞語, 提取關鍵詞.
TfidfVectorizer
TfidfVectorizer 可以幫助我們把原始文本轉化為 tf-idf 的特征矩陣, 從而進行相似度計算. sklearn 的TfidfVectorizer 默認輸入文本矩陣每行表示一篇文本. 不同文本中相同詞項的 tf 值不同, 因此 tf 值與詞項所在文本有關.

格式:
tfidfVectorizer(input='content', encoding='utf-8',
decode_error='strict', strip_accents=None, lowercase=True,
preprocessor=None, tokenizer=None, analyzer='word',
stop_words=None, token_pattern=r"(?u)\b\w\w+\b",
ngram_range=(1, 1), max_df=1.0, min_df=1,
max_features=None, vocabulary=None, binary=False,
dtype=np.float64, norm='l2', use_idf=True, smooth_idf=True,
sublinear_tf=False)
引數:
- input: 輸入
- encoding: 編碼, 默認為 utf-8
- analyzer: “word” 或 “char”, 默認按詞 (word) 分析
- stopwords: 停用詞
- ngram_range: ngrame 上下限
- lowercase: 轉換為小寫
- max_features: 關鍵詞個數
資料介紹
資料由 12 個不同網站的新聞資料組成. 如下:
Class ... Content
0 news ... 中廣網唐山6月12日訊息(記者湯一亮 莊勝春)據中國之聲《新聞晚高峰》報道,今天(12日)上...
1 news ... 天津衛視求職節目《非你莫屬》“暈倒門”事件余波未了,主持人張紹剛前日通過《非你莫屬》節目組發...
2 news ... 臨沂(山東),2012年6月4日 夫妻“麥客”忙麥收 6月4日,在山東省臨沂市郯城縣郯城街道...
3 news ... 中廣網北京6月13日訊息(記者王宇)據中國之聲《新聞晚高峰》報道,明天凌晨兩場歐洲杯的精彩比...
4 news ... 環球網記者李亮報道,正在意大利度蜜月的“臉譜”創始人扎克伯格與他華裔妻子的一舉一動都處于媒體...

流程:
- 讀取資料
- 計算資料 tf-idf 值
- 貝葉斯分類
代碼實作
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import classification_report
from sklearn.naive_bayes import MultinomialNB
import jieba
def load_data():
"""讀取資料/停用詞"""
# 讀取資料
data = pd.read_csv("test.txt", sep="\t", names=["Class", "Title", "Content"])
print(data.head())
# 讀取停用詞
stop_words = pd.read_csv("stopwords.txt", names=["stop_words"], encoding="utf-8")
stop_words = stop_words["stop_words"].values.tolist()
print(stop_words)
return data, stop_words
def main():
"""主函式"""
# 讀取資料
data, stop_words = load_data()
# 分詞
segs = data["Content"].apply(lambda x: ' '.join(jieba.cut(x)))
# Tf-Idf
tf_idf = TfidfVectorizer(stop_words=stop_words, max_features=1000, lowercase=False)
# 擬合
tf_idf.fit(segs)
# 轉換
X = tf_idf.transform(segs)
# 分割資料
X_train, X_test, y_train, y_test = train_test_split(X, data["Class"], random_state=0)
# 除錯輸出
print(X_train[:2])
print(y_train[:2])
# 實體化樸素貝葉斯
classifier = MultinomialNB()
# 擬合
classifier.fit(X_train, y_train)
# 計算分數
acc = classifier.score(X_test, y_test)
print("準確率:", acc)
# 報告
report = classification_report(y_test, classifier.predict(X_test))
print(report)
if __name__ == '__main__':
main()
輸出結果:
Class ... Content
0 news ... 中廣網唐山6月12日訊息(記者湯一亮 莊勝春)據中國之聲《新聞晚高峰》報道,今天(12日)上...
1 news ... 天津衛視求職節目《非你莫屬》“暈倒門”事件余波未了,主持人張紹剛前日通過《非你莫屬》節目組發...
2 news ... 臨沂(山東),2012年6月4日 夫妻“麥客”忙麥收 6月4日,在山東省臨沂市郯城縣郯城街道...
3 news ... 中廣網北京6月13日訊息(記者王宇)據中國之聲《新聞晚高峰》報道,明天凌晨兩場歐洲杯的精彩比...
4 news ... 環球網記者李亮報道,正在意大利度蜜月的“臉譜”創始人扎克伯格與他華裔妻子的一舉一動都處于媒體...
[5 rows x 3 columns]
['?', '、', ',', '“', '”', '《', '》', '!', ',', ':', ';', '?', '啊', '阿', '哎', '哎呀', '哎喲', '唉', '俺', '俺們', '按', '按照', '吧', '吧噠', '把', '罷了', '被', '本', '本著', '比', '比方', '比如', '鄙人', '彼', '彼此', '邊', '別', '別的', '別說', '并', '并且', '不比', '不成', '不單', '不但', '不獨', '不管', '不光', '不過', '不僅', '不拘', '不論', '不怕', '不然', '不如', '不特', '不惟', '不問', '不只', '朝', '朝著', '趁', '趁著', '乘', '沖', '除', '除此之外', '除非', '除了', '此', '此間', '此外', '從', '從而', '打', '待', '但', '但是', '當', '當著', '到', '得', '的', '的話', '等', '等等', '地', '第', '叮咚', '對', '對于', '多', '多少', '而', '而況', '而且', '而是', '而外', '而言', '而已', '爾后', '反過來', '反過來說', '反之', '非但', '非徒', '否則', '嘎', '嘎登', '該', '趕', '個', '各', '各個', '各位', '各種', '各自', '給', '根據', '跟', '故', '故此', '固然', '關于', '管', '歸', '果然', '果真', '過', '哈', '哈哈', '呵', '和', '何', '何處', '何況', '何時', '嘿', '哼', '哼唷', '呼哧', '乎', '嘩', '還是', '還有', '換句話說', '換言之', '或', '或是', '或者', '極了', '及', '及其', '及至', '即', '即便', '即或', '即令', '即若', '即使', '幾', '幾時', '己', '既', '既然', '既是', '繼而', '加之', '假如', '假若', '假使', '鑒于', '將', '較', '較之', '叫', '接著', '結果', '借', '緊接著', '進而', '盡', '盡管', '經', '經過', '就', '就是', '就是說', '據', '具體地說', '具體說來', '開始', '開外', '靠', '咳', '可', '可見', '可是', '可以', '況且', '啦', '來', '來著', '離', '例如', '哩', '連', '連同', '兩者', '了', '臨', '另', '另外', '另一方面', '論', '嘛', '嗎', '慢說', '漫說', '冒', '么', '每', '每當', '們', '莫若', '某', '某個', '某些', '拿', '哪', '哪邊', '哪兒', '哪個', '哪里', '哪年', '哪怕', '哪天', '哪些', '哪樣', '那', '那邊', '那兒', '那個', '那會兒', '那里', '那么', '那么些', '那么樣', '那時', '那些', '那樣', '乃', '乃至', '呢', '能', '你', '你們', '您', '寧', '寧可', '寧肯', '寧愿', '哦', '嘔', '啪達', '旁人', '呸', '憑', '憑借', '其', '其次', '其二', '其他', '其它', '其一', '其余', '其中', '起', '起見', '起見', '豈但', '恰恰相反', '前后', '前者', '且', '然而', '然后', '然則', '讓', '人家', '任', '任何', '任憑', '如', '如此', '如果', '如何', '如其', '如若', '如上所述', '若', '若非', '若是', '啥', '上下', '尚且', '設若', '設使', '甚而', '甚么', '甚至', '省得', '時候', '什么', '什么樣', '使得', '是', '是的', '首先', '誰', '誰知', '順', '順著', '似的', '雖', '雖然', '雖說', '雖則', '隨', '隨著', '所', '所以', '他', '他們', '他人', '它', '它們', '她', '她們', '倘', '倘或', '倘然', '倘若', '倘使', '騰', '替', '通過', '同', '同時', '哇', '萬一', '往', '望', '為', '為何', '為了', '為什么', '為著', '喂', '嗡嗡', '我', '我們', '嗚', '嗚呼', '烏乎', '無論', '無寧', '毋寧', '嘻', '嚇', '相對而言', '像', '向', '向著', '噓', '呀', '焉', '沿', '沿著', '要', '要不', '要不然', '要不是', '要么', '要是', '也', '也罷', '也好', '一', '一般', '一旦', '一方面', '一來', '一切', '一樣', '一則', '依', '依照', '矣', '以', '以便', '以及', '以免', '以至', '以至于', '以致', '抑或', '因', '因此', '因而', '因為', '喲', '用', '由', '由此可見', '由于', '有', '有的', '有關', '有些', '又', '于', '于是', '于是乎', '與', '與此同時', '與否', '與其', '越是', '云云', '哉', '再說', '再者', '在', '在下', '咱', '咱們', '則', '怎', '怎么', '怎么辦', '怎么樣', '怎樣', '咋', '照', '照著', '者', '這', '這邊', '這兒', '這個', '這會兒', '這就是說', '這里', '這么', '這么點兒', '這么些', '這么樣', '這時', '這些', '這樣', '正如', '吱', '之', '之類', '之所以', '之一', '只是', '只限', '只要', '只有', '至', '至于', '諸位', '著', '著呢', '自', '自從', '自個兒', '自各兒', '自己', '自家', '自身', '綜上所述', '總的來看', '總的來說', '總的說來', '總而言之', '總之', '縱', '縱令', '縱然', '縱使', '遵照', '作為', '兮', '呃', '唄', '咚', '咦', '喏', '啐', '喔唷', '嗬', '嗯', '噯', 'a', 'able', 'about', 'above', 'abroad', 'according', 'accordingly', 'across', 'actually', 'adj', 'after', 'afterwards', 'again', 'against', 'ago', 'ahead', "ain't", 'all', 'allow', 'allows', 'almost', 'alone', 'along', 'alongside', 'already', 'also', 'although', 'always', 'am', 'amid', 'amidst', 'among', 'amongst', 'an', 'and', 'another', 'any', 'anybody', 'anyhow', 'anyone', 'anything', 'anyway', 'anyways', 'anywhere', 'apart', 'appear', 'appreciate', 'appropriate', 'are', "aren't", 'around', 'as', "a's", 'aside', 'ask', 'asking', 'associated', 'at', 'available', 'away', 'awfully', 'b', 'back', 'backward', 'backwards', 'be', 'became', 'because', 'become', 'becomes', 'becoming', 'been', 'before', 'beforehand', 'begin', 'behind', 'being', 'believe', 'below', 'beside', 'besides', 'best', 'better', 'between', 'beyond', 'both', 'brief', 'but', 'by', 'c', 'came', 'can', 'cannot', 'cant', "can't", 'caption', 'cause', 'causes', 'certain', 'certainly', 'changes', 'clearly', "c'mon", 'co', 'co.', 'com', 'come', 'comes', 'concerning', 'consequently', 'consider', 'considering', 'contain', 'containing', 'contains', 'corresponding', 'could', "couldn't", 'course', "c's", 'currently', 'd', 'dare', "daren't", 'definitely', 'described', 'despite', 'did', "didn't", 'different', 'directly', 'do', 'does', "doesn't", 'doing', 'done', "don't", 'down', 'downwards', 'during', 'e', 'each', 'edu', 'eg', 'eight', 'eighty', 'either', 'else', 'elsewhere', 'end', 'ending', 'enough', 'entirely', 'especially', 'et', 'etc', 'even', 'ever', 'evermore', 'every', 'everybody', 'everyone', 'everything', 'everywhere', 'ex', 'exactly', 'example', 'except', 'f', 'fairly', 'far', 'farther', 'few', 'fewer', 'fifth', 'first', 'five', 'followed', 'following', 'follows', 'for', 'forever', 'former', 'formerly', 'forth', 'forward', 'found', 'four', 'from', 'further', 'furthermore', 'g', 'get', 'gets', 'getting', 'given', 'gives', 'go', 'goes', 'going', 'gone', 'got', 'gotten', 'greetings', 'h', 'had', "hadn't", 'half', 'happens', 'hardly', 'has', "hasn't", 'have', "haven't", 'having', 'he', "he'd", "he'll", 'hello', 'help', 'hence', 'her', 'here', 'hereafter', 'hereby', 'herein', "here's", 'hereupon', 'hers', 'herself', "he's", 'hi', 'him', 'himself', 'his', 'hither', 'hopefully', 'how', 'howbeit', 'however', 'hundred', 'i', "i'd", 'ie', 'if', 'ignored', "i'll", "i'm", 'immediate', 'in', 'inasmuch', 'inc', 'inc.', 'indeed', 'indicate', 'indicated', 'indicates', 'inner', 'inside', 'insofar', 'instead', 'into', 'inward', 'is', "isn't", 'it', "it'd", "it'll", 'its', "it's", 'itself', "i've", 'j', 'just', 'k', 'keep', 'keeps', 'kept', 'know', 'known', 'knows', 'l', 'last', 'lately', 'later', 'latter', 'latterly', 'least', 'less', 'lest', 'let', "let's", 'like', 'liked', 'likely', 'likewise', 'little', 'look', 'looking', 'looks', 'low', 'lower', 'ltd', 'm', 'made', 'mainly', 'make', 'makes', 'many', 'may', 'maybe', "mayn't", 'me', 'mean', 'meantime', 'meanwhile', 'merely', 'might', "mightn't", 'mine', 'minus', 'miss', 'more', 'moreover', 'most', 'mostly', 'mr', 'mrs', 'much', 'must', "mustn't", 'my', 'myself', 'n', 'name', 'namely', 'nd', 'near', 'nearly', 'necessary', 'need', "needn't", 'needs', 'neither', 'never', 'neverf', 'neverless', 'nevertheless', 'new', 'next', 'nine', 'ninety', 'no', 'nobody', 'non', 'none', 'nonetheless', 'noone', 'no-one', 'nor', 'normally', 'not', 'nothing', 'notwithstanding', 'novel', 'now', 'nowhere', 'o', 'obviously', 'of', 'off', 'often', 'oh', 'ok', 'okay', 'old', 'on', 'once', 'one', 'ones', "one's", 'only', 'onto', 'opposite', 'or', 'other', 'others', 'otherwise', 'ought', "oughtn't", 'our', 'ours', 'ourselves', 'out', 'outside', 'over', 'overall', 'own', 'p', 'particular', 'particularly', 'past', 'per', 'perhaps', 'placed', 'please', 'plus', 'possible', 'presumably', 'probably', 'provided', 'provides', 'q', 'que', 'quite', 'qv', 'r', 'rather', 'rd', 're', 'really', 'reasonably', 'recent', 'recently', 'regarding', 'regardless', 'regards', 'relatively', 'respectively', 'right', 'round', 's', 'said', 'same', 'saw', 'say', 'saying', 'says', 'second', 'secondly', 'see', 'seeing', 'seem', 'seemed', 'seeming', 'seems', 'seen', 'self', 'selves', 'sensible', 'sent', 'serious', 'seriously', 'seven', 'several', 'shall', "shan't", 'she', "she'd", "she'll", "she's", 'should', "shouldn't", 'since', 'six', 'so', 'some', 'somebody', 'someday', 'somehow', 'someone', 'something', 'sometime', 'sometimes', 'somewhat', 'somewhere', 'soon', 'sorry', 'specified', 'specify', 'specifying', 'still', 'sub', 'such', 'sup', 'sure', 't', 'take', 'taken', 'taking', 'tell', 'tends', 'th', 'than', 'thank', 'thanks', 'thanx', 'that', "that'll", 'thats', "that's", "that've", 'the', 'their', 'theirs', 'them', 'themselves', 'then', 'thence', 'there', 'thereafter', 'thereby', "there'd", 'therefore', 'therein', "there'll", "there're", 'theres', "there's", 'thereupon', "there've", 'these', 'they', "they'd", "they'll", "they're", "they've", 'thing', 'things', 'think', 'third', 'thirty', 'this', 'thorough', 'thoroughly', 'those', 'though', 'three', 'through', 'throughout', 'thru', 'thus', 'till', 'to', 'together', 'too', 'took', 'toward', 'towards', 'tried', 'tries', 'truly', 'try', 'trying', "t's", 'twice', 'two', 'u', 'un', 'under', 'underneath', 'undoing', 'unfortunately', 'unless', 'unlike', 'unlikely', 'until', 'unto', 'up', 'upon', 'upwards', 'us', 'use', 'used', 'useful', 'uses', 'using', 'usually', 'v', 'value', 'various', 'versus', 'very', 'via', 'viz', 'vs', 'w', 'want', 'wants', 'was', "wasn't", 'way', 'we', "we'd", 'welcome', 'well', "we'll", 'went', 'were', "we're", "weren't", "we've", 'what', 'whatever', "what'll", "what's", "what've", 'when', 'whence', 'whenever', 'where', 'whereafter', 'whereas', 'whereby', 'wherein', "where's", 'whereupon', 'wherever', 'whether', 'which', 'whichever', 'while', 'whilst', 'whither', 'who', "who'd", 'whoever', 'whole', "who'll", 'whom', 'whomever', "who's", 'whose', 'why', 'will', 'willing', 'wish', 'with', 'within', 'without', 'wonder', "won't", 'would', "wouldn't", 'x', 'y', 'yes', 'yet', 'you', "you'd", "you'll", 'your', "you're", 'yours', 'yourself', 'yourselves', "you've", 'z', 'zero']
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\Windows\AppData\Local\Temp\jieba.cache
Loading model cost 0.797 seconds.
Prefix dict has been built successfully.
C:\Users\Windows\Anaconda3\lib\site-packages\sklearn\feature_extraction\text.py:300: UserWarning: Your stop_words may be inconsistent with your preprocessing. Tokenizing the stop words generated tokens ['ain', 'aren', 'couldn', 'daren', 'didn', 'doesn', 'don', 'hadn', 'hasn', 'haven', 'isn', 'll', 'mayn', 'mightn', 'mon', 'mustn', 'needn', 'oughtn', 'shan', 'shouldn', 've', 'wasn', 'weren', 'won', 'wouldn'] not in stop_words.
'stop_words.' % sorted(inconsistent))
C:\Users\Windows\Anaconda3\lib\site-packages\sklearn\metrics\classification.py:1437: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples.
'precision', 'predicted', average, warn_for)
(0, 1) 0.172494787172401
(0, 13) 0.03617578927683419
(0, 19) 0.044685283861169885
(0, 24) 0.04378669110667244
(0, 32) 0.04770060616202845
(0, 37) 0.08714906173699981
(0, 42) 0.03262617791847282
(0, 79) 0.03598272479613044
(0, 80) 0.03384787551537572
(0, 83) 0.105263111952599
(0, 88) 0.1963277784717525
(0, 89) 0.04008970433219022
(0, 90) 0.1412328663779052
(0, 98) 0.03994454517190565
(0, 134) 0.04594067399577792
(0, 142) 0.04422553495980068
(0, 147) 0.05830540319790606
(0, 149) 0.02851184938909845
(0, 163) 0.03588762154160368
(0, 166) 0.11695593718680143
(0, 168) 0.06847746933720501
(0, 170) 0.08047415949662211
(0, 176) 0.03776179057073174
(0, 185) 0.03924979201525634
(0, 200) 0.04184963649844074
: :
(0, 855) 0.04946215984804544
(0, 865) 0.04649241857748127
(0, 869) 0.138252930106818
(0, 870) 0.21384828173878706
(0, 873) 0.1667028225043511
(0, 876) 0.09298483715496254
(0, 885) 0.19784215331311594
(0, 888) 0.04008970433219022
(0, 896) 0.04985458905113395
(0, 897) 0.49416003160549193
(0, 902) 0.03938479984191792
(0, 909) 0.03885574129240138
(0, 910) 0.03911664642497605
(0, 917) 0.05050266101265748
(0, 922) 0.03966061581314387
(0, 933) 0.02711876416903459
(0, 947) 0.0329697338326223
(0, 955) 0.15044205095521537
(0, 972) 0.03255891003473477
(0, 998) 0.1578946679288985
(1, 196) 0.37511948551579166
(1, 224) 0.21966463546937165
(1, 420) 0.24197656045436386
(1, 460) 0.49133294291978213
(1, 787) 0.7148930709574247
1394 news.cn
1365 news.cn
Name: Class, dtype: object
準確率: 0.7176165803108808
precision recall f1-score support
1688.autos.cn 0.00 0.00 0.00 3
autos.cn 1.00 0.22 0.36 9
biz.cn 0.63 0.73 0.68 45
cpc 0.00 0.00 0.00 8
dangshi 0.48 0.77 0.59 13
ent.cn 0.86 0.57 0.68 44
henan 0.98 0.77 0.86 69
news 0.00 0.00 0.00 16
news.cn 0.64 0.93 0.76 131
society 0.00 0.00 0.00 5
sports.cn 0.86 0.86 0.86 37
theory 0.00 0.00 0.00 6
accuracy 0.72 386
macro avg 0.45 0.40 0.40 386
weighted avg 0.69 0.72 0.68 386
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301429.html
標籤:AI
上一篇:深度學習神經網路學習筆記-自然語言處理方向-自然語言處理基礎(一)
下一篇:決策樹演算法