文章目錄
- 決策樹
- 1. 決策樹的整體理解
- 2. 決策樹的構造
- 2.1 決策樹----熵
- 2.2 構造決策樹
- 3. C4.5演算法
- 4. 決策樹剪枝
決策樹
1. 決策樹的整體理解
? 決策樹,顧名思義,首先它是一棵樹,其次,這棵樹可以起到決策的作用(即可以對一些問題進行判斷),
? 現通過下面的例子來理解決策樹的作用,(注:決策樹既可以做分類也可以做回歸,此處主要討論分類的決策樹)圖中共有五個人,現需要從中挑選出可能喜歡打籃球的人,那么我們就可以通過年齡和性別這兩個指標去進行選擇,第一步篩選出年齡小于15歲的兩人,第二步通過性別就可以挑選出可能喜歡打籃球的人,[這里的年齡和性別被稱為決策屬性]
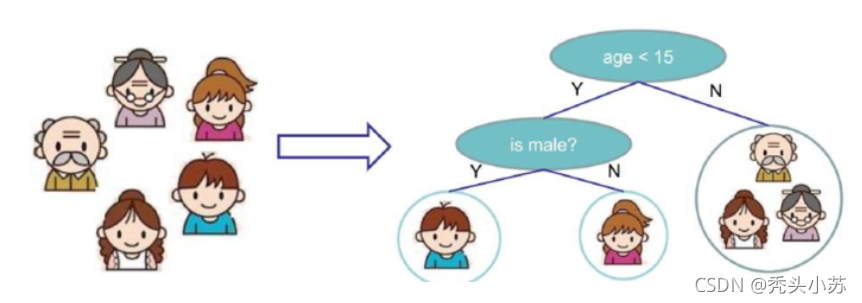
? 通過上面的例子,我們可能會想決策樹也太簡單了,這不就是if陳述句進行判斷嗎?我早就會了,其實不然,上面的例子只是告訴我們決策樹的使用,決策樹更多的作業應該是在決策樹的創建上,我們可以仔細想想這些問題,這個樹為什么是這樣的呢?為什么大于15歲就被分到不喜歡打籃球的一類呢?為什么女生就被分到不喜歡打籃球的一類呢?為什么要先對年齡屬性進行判斷呢,先判斷性別屬性可不可以呢?其實這些都是通過先前對決策樹的構造來決定的,下面來介紹決策樹的構造方法,
2. 決策樹的構造
2.1 決策樹----熵
? 首先我們需要對熵有一個了解,高中化學中其實就有這樣一個概念,他表示的是物體內部的混亂程度,或者說表示隨機變數不確定性的度量,熵越大,表示物體內部越混亂,隨機變數越不確定,即隨機變數不確定性越大,
? 若用H(X)表示事件X的不確定性,則
? P(幾率越大) --> H(X)值越小 【如夏天很熱發生幾率很大,那么它的不確定性(H(X)就很小)】
? P(幾率越小) --> H(X)值越大 【如冬天很熱發生幾率很小,那么它的不確定性(H(X)就很大)】
? 下面為熵的公式:
熵
=
?
∑
i
=
1
n
P
i
I
n
(
P
i
)
熵 = - \sum\nolimits_{i = 1}^n {{P_i}} In({P_i})
熵=?∑i=1n?Pi?In(Pi?)
? 我們可以從宏觀上理解上面的熵公式:

上圖的1>,2>反應了熵表示事件的不確定性,即一個事件發生的概率大,其不確定性H(x)越小,熵越小,
下面為Gini系數Gini§的公式,其表示的含義與熵類似,
G
i
n
i
(
p
)
=
∑
k
=
1
k
P
k
(
1
?
P
k
)
=
1
?
∑
k
=
1
k
P
k
2
Gini(p) = \sum\limits_{k = 1}^k {{P_k}(1 - {P_k})} = 1 - \sum\limits_{k = 1}^k {P_k^2} \
Gini(p)=k=1∑k?Pk?(1?Pk?)=1?k=1∑k?Pk2?
舉個例子進一步理解一下熵:假設現在有兩個集合A = [1,2],B = [1,1]
先分別計算兩個集合中元素的熵,
A:熵 = - [1/2*In(1/2)+1/2*In(1/2)] = 0.693
B:熵 = - [1*In(1)+1*In(1)] = 0
通過計算可以發現熵A>熵B,即A比較混亂,從直觀上我們也可以看出集合A比集合B混亂,這進一步驗證了上面的結論,
2.2 構造決策樹
? 首先,我們需要知道構建決策樹的基本思想,即隨著樹深度的增加,節點的熵迅速的降低,熵降低的速度越快,這樣我們就有望得到一顆高度最矮的決策樹,
? 根據這個思想,我們舉一個實體來說明,下表為根據outlook,temperature,humidity,
windy幾個屬性來決定是否打球的統計表,(表中共有14行資料,每個資料4個特征屬性)
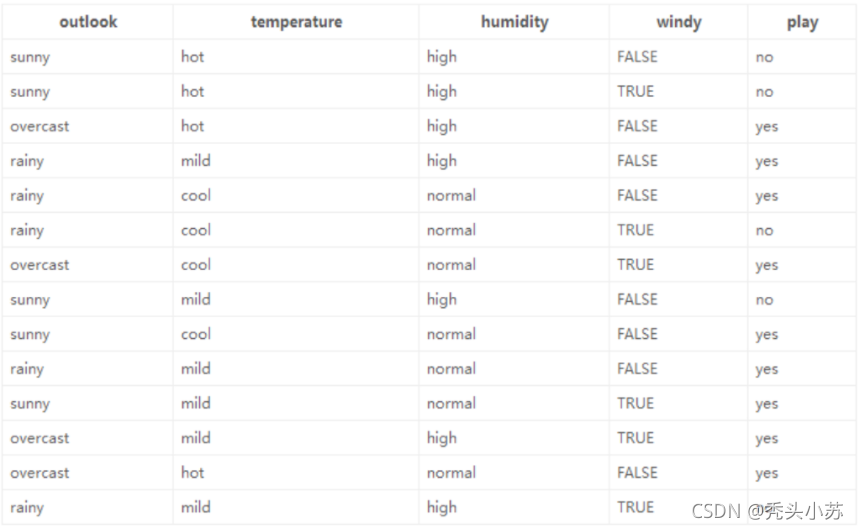
? 在沒有給定任何天氣資訊時,根據歷史資料,我們得知新的一天中打球的概率為9/14,不打的概率為5/14,此時的熵為:
9
14
log
?
2
9
14
?
5
14
log
?
2
5
14
=
0.940
\frac{9}{{14}}{\log _2}\frac{9}{{14}} - \frac{5}{{14}}{\log _2}\frac{5}{{14}} = 0.940
149?log2?149??145?log2?145?=0.940
? 0.94就是我們初始時刻的熵值,前面說到構建決策樹的基本思想就是使節點的熵迅速的下降,那么現在有4個屬性(outlook, temperature, humidity,windy),每個屬性都可以充當第一個節點,即根節點,這時我們就需要分別計算出4個屬性充當根節點時的熵值,然后選擇熵值下降最快的屬性作為當前節點,
? 首先,我們選擇從outlook屬性開始分析,從表中可以看出,outlook = sunny 共有5行資料(play標簽欄有2個yes , 3個no); outlook = overcast 共有4行資料(play標簽欄全為yes );outlook = rainy共有5行資料(play標簽欄有3個yes , 2個no);其示意圖如下:
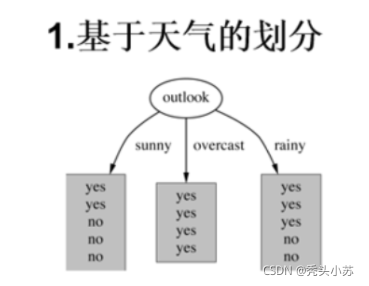
? 下面計算其熵值(Entropy):
? 當outlook = sunny 時,Entropy = -2/5*log(2/5) - 3/5*log(3/5) = 0.971
? 當outlook = overcast 時,Entropy = -1*log(1) - 0*log(0) = 0
? 當outlook = rainy 時,Entropy = -3/5*log(3/5) - 2/5*log(2/5) = 0.971
?
? 根據資料統計, outlook取值分別為sunny,overcast,rainy的概率分別為:5/14 , 4/14 , 5/14 ,則其熵值為5/14*0.971 + 4/14*0 + 5/14*0.971 = 0.693,
? 我們知道我們需要的節點是要使熵迅速下降的,那么我們不妨把熵下降的幅度定義為一個新的引數:資訊增益gain,這樣我們就可以通過比較資訊增益的大小來判斷選擇什么節點作為當前節點,那么當選擇outlook屬性時的資訊增益就是初始熵 - 變化熵:gain(outlook) = 0.940 - 0.693 = 0.247,
? 同理我們可以得到其它屬性的資訊增益:
? gain(temperature) = 0.029 ; gain(humidity) = 0.152 ; gain(windy) = 0.048
? 我們發現屬性outlook的資訊增益最大,因此此時就選擇outlook作為當前節點,確定好outlook作為根節點后,我們就可以對14條資料進行一些劃分,然后在劃分的資料中再采用相同的方法選擇一個屬性(除去outlook)作為這次劃分的節點,以此往復,就可以得到一顆決策樹,
3. C4.5演算法
? 上面通過資訊增益來決定當前節點選擇的演算法稱為ID3演算法,但這種演算法是存在缺陷的,我們舉個例子 ,現在將前面的題增加一個ID屬性,如圖:
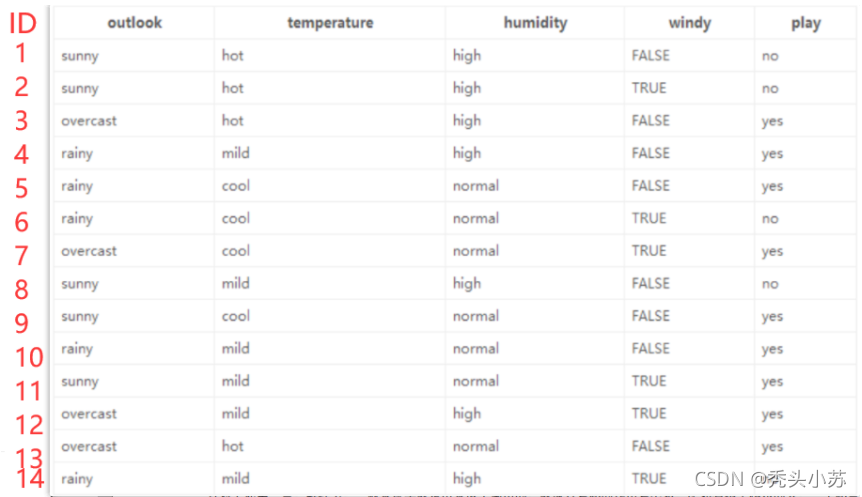
? 現在計算ID屬性的資訊增益我們發現其資訊增益為9.40,因為每個ID的play標簽只有一個,都是確定的,其熵都為0,既然資訊增益最大,是否可以說我們選擇ID屬性來進行劃分是最優的呢?顯然這是不合適的,因為ID屬性和play標簽是完全沒有任何關系的,因此使用資訊增益的ID3演算法是有一定缺陷的,這里我們選擇改進的C4.5演算法,其是通過資訊增益率GainRatio來實作的,資訊增益率公式如下:
G
a
i
n
R
a
t
i
o
(
S
,
A
)
=
g
a
i
n
(
S
,
A
)
S
p
l
i
t
I
n
f
o
r
m
a
t
i
o
n
(
S
,
A
)
% MathType!MTEF!2!1!+- % feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn % hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr % 4rNCHbWexLMBbXgBd9gzLbvyNv2CaeHbl7mZLdGeaGqiVu0Je9sqqr % pepC0xbbL8F4rqqrFfpeea0xe9Lq-Jc9vqaqpepm0xbba9pwe9Q8fs % 0-yqaqpepae9pg0FirpepeKkFr0xfr-xfr-xb9adbaqaaeGaciGaai % aabeqaamaabaabauaakeaacaqGhbGaamyyaiaadMgacaWGUbGaamOu % aiaadggacaWG0bGaamyAaiaad+gacaGGOaGaam4uaiaacYcacaWGbb % Gaaiykaiabg2da9maalaaabaGaam4zaiaadggacaWGPbGaamOBaiaa % cIcacaWGtbGaaiilaiaadgeacaGGPaaabaGaam4uaiaadchacaWGSb % GaamyAaiaadshacaWGjbGaamOBaiaadAgacaWGVbGaamOCaiaad2ga % caWGHbGaamiDaiaadMgacaWGVbGaamOBaiaacIcacaWGtbGaaiilai % aadgeacaGGPaaaaaaa!65EA! {\rm{G}}ainRatio(S,A) = \frac{{gain(S,A)}}{{SplitInformation(S,A)}}\
GainRatio(S,A)=SplitInformation(S,A)gain(S,A)?
? 其中SplitInformation(S,A)為分裂資訊度量,其定義如下:
S
p
l
i
t
I
n
f
o
r
m
a
t
i
o
n
(
S
,
A
)
=
?
∑
i
=
1
c
∣
S
i
∣
∣
S
∣
log
?
2
∣
S
i
∣
∣
S
∣
% MathType!MTEF!2!1!+- % feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn % hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr % 4rNCHbWexLMBbXgBd9gzLbvyNv2CaeHbl7mZLdGeaGqiVu0Je9sqqr % pepC0xbbL8F4rqqrFfpeea0xe9Lq-Jc9vqaqpepm0xbba9pwe9Q8fs % 0-yqaqpepae9pg0FirpepeKkFr0xfr-xfr-xb9adbaqaaeGaciGaai % aabeqaamaabaabauaakeaacaWGtbGaamiCaiaadYgacaWGPbGaamiD % aiaadMeacaWGUbGaamOzaiaad+gacaWGYbGaamyBaiaadggacaWG0b % GaamyAaiaad+gacaWGUbGaaiikaiaadofacaGGSaGaamyqaiaacMca % cqGH9aqpcqGHsisldaaeWbqaamaalaaabaGaaiiFaiaadofacaWGPb % GaaiiFaaqaaiaacYhacaWGtbGaaiiFaaaaaSqaaiaadMgacqGH9aqp % caaIXaaabaGaam4yaaqdcqGHris5aOGaciiBaiaac+gacaGGNbWaaS % baaSqaaiaaikdaaeqaaOWaaSaaaeaacaGG8bGaam4uaiaadMgacaGG % 8baabaGaaiiFaiaadofacaGG8baaaaaa!6A9E! SplitInformation(S,A) = - \sum\limits_{i = 1}^c {\frac{{|Si|}}{{|S|}}} {\log _2}\frac{{|Si|}}{{|S|}}\
SplitInformation(S,A)=?i=1∑c?∣S∣∣Si∣?log2?∣S∣∣Si∣?
? 其中 S1 到 Sc 是 c 個值的屬性 A 分割 S 而形成的 c 個樣例子集, 注意分裂資訊實際上就是 S 關于屬性 A 的各值的熵,
? 其實,資訊增益和資訊增益率就和速度和加速的的區別類似,比如有兩個跑步的人, 一個起點是 10m/s 的人、 其 10s 后為 20m/s; 另一個人起速是 1m/s、 其 1s 后為 2m/s, 如果緊緊算差值那么兩個差距就很大了, 如果使用速度增加率(加速度, 即都是為 1m/s^2)來衡量, 2 個人就是一樣的加速度, 因此, C4.5 克服了 ID3 用資訊增益選擇屬性時偏向選擇取值多的屬性的不足,
? 現用資訊增益率來處理剛剛的ID屬性,雖然ID屬性的資訊增益很大,但是要除以分裂資訊度,SplitInformation(S,A)計算公式為:
S
p
l
i
t
I
n
f
o
r
m
a
t
i
o
n
(
S
,
A
)
=
?
∑
i
=
1
14
∣
1
∣
∣
14
∣
log
?
2
∣
1
∣
∣
14
∣
% MathType!MTEF!2!1!+- % feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn % hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr % 4rNCHbWexLMBbXgBd9gzLbvyNv2CaeHbl7mZLdGeaGqiVu0Je9sqqr % pepC0xbbL8F4rqqrFfpeea0xe9Lq-Jc9vqaqpepm0xbba9pwe9Q8fs % 0-yqaqpepae9pg0FirpepeKkFr0xfr-xfr-xb9adbaqaaeGaciGaai % aabeqaamaabaabauaakeaacaWGtbGaamiCaiaadYgacaWGPbGaamiD % aiaadMeacaWGUbGaamOzaiaad+gacaWGYbGaamyBaiaadggacaWG0b % GaamyAaiaad+gacaWGUbGaaiikaiaadofacaGGSaGaamyqaiaacMca % cqGH9aqpcqGHsisldaaeWbqaamaalaaabaGaaiiFaiaaigdacaGG8b % aabaGaaiiFaiaaigdacaaI0aGaaiiFaaaaaSqaaiaadMgacqGH9aqp % caaIXaaabaGaaGymaiaaisdaa0GaeyyeIuoakiGacYgacaGGVbGaai % 4zamaaBaaaleaacaaIYaaabeaakmaalaaabaGaaiiFaiaaigdacaGG % 8baabaGaaiiFaiaaigdacaaI0aGaaiiFaaaaaaa!6A5B! SplitInformation(S,A) = - \sum\limits_{i = 1}^{14} {\frac{{|1|}}{{|14|}}} {\log _2}\frac{{|1|}}{{|14|}}\
SplitInformation(S,A)=?i=1∑14?∣14∣∣1∣?log2?∣14∣∣1∣?
? 上式中 SplitInformation(S,A)的值是非常大的,讓其作為分母,會使資訊增益率變得很小,那么就可以判斷ID屬性作為節點的效果不好,
4. 決策樹剪枝
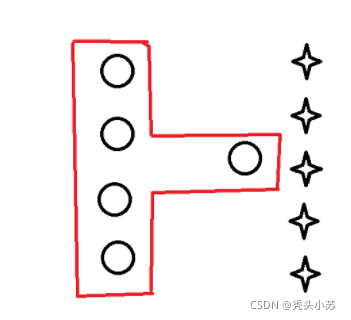
? 我們先來看這樣的例子,如圖:有兩種圖形,我們訓練資料最后達到的效果如下,即紅框內的資料會被認為是圓,其它的資料會被認為是,這種訓練結果好嗎?只能說這個訓練結果對已知的資料劃分好,但是對未知的資料劃分不好,這就是過擬合現象,那么我們怎么有效解決過擬合現象呢,這就需要對決策樹進行剪枝,
? 決策樹剪枝主要有兩種方法,預剪枝和后剪枝:
- 預剪枝:在構建決策樹的程序中,提前停止
- 后剪枝:決策樹構建好后,通過一定的衡量標準,對決策樹進行裁剪
? 決策樹剪枝主要有兩種方法,預剪枝和后剪枝:
- 預剪枝:在構建決策樹的程序中,提前停止
- 后剪枝:決策樹構建好后,通過一定的衡量標準,對決策樹進行裁剪
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301430.html
標籤:AI
上一篇:【NLP】??學不會打我! 半小時學會基本操作 8?? 新聞分類
下一篇:人工智能------>第四天,深度學習,人工神經網路,卷積神經網路,opencv,音頻采集、播放,百度AI平臺的使用