hive是通過獲取到時間戳的形式來獲取到時間,然后通過函式FROM_UNIXTIME 轉化為日期時間的形式
hive查詢時間
| 查詢當前月份 | | 2021-09 |
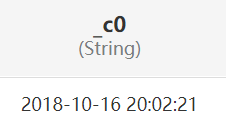
| 2021-09-17 09:51:42 | |
| 獲取當前時間戳bigint unix_timestamp() | |
|
| bigint unix_timestamp(string_date) 將格式“yyyy-MM-dd HH:mm:ss”的字串轉成時間戳,如果格式不對回傳null | |
|
| bigint unix_timestamp(string date,string pattern) 將指定時間字串格式轉成時間戳,如果格式不對回傳null | |
|
| string from_unixtime(bigint,format) 將時間戳轉為format格式,可以為“yyyy-MM-dd HH:mm:ss”,"yyyy-MM-dd HH","yyyy-MM-dd","yyyyMMdd"等 | |
|
| string to_date(string timestamp) 回傳時間字串的日期部分 | |
|
| string datediff(string enddate,string startdate) 計算兩個日期相差的天數 | |
|
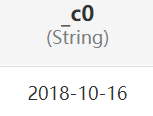
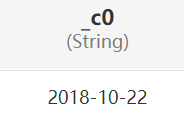
| string date_add(string startdate,int days) select date_sub('2018-10-16',6); 開始時間加上days 開始時間減去days | |
|
| current_date 獲取當前日期 | | |
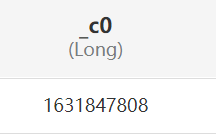
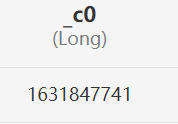
| current_timestamp 獲取當前時間戳 | | |
| year(string date) month(string date) day(string date) hour(string date) minute(string date) second(string date) weekofyear(string date) 回傳日期中的年\月\日\小時\分鐘\秒當前周數 | |
|
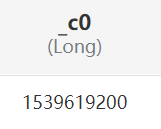

| AND | 語法: A AND B 操作型別:boolean 說明:如果A和B均為TRUE,則為TRUE;否則為FALSE,如果A為NULL或B為NULL,則為NULL | | false |
| OR | 語法: A OR B 操作型別:boolean 說明:如果A為TRUE,或者B為TRUE,或者A和B均為TRUE,則為TRUE;否則為FALSE | | true |
| NOT | 語法: NOT A 操作型別:boolean 說明:如果A為FALSE,或者A為NULL,則為TRUE;否則為FALSE | | true |
| 運算 | 注釋 | 代碼 | 運算結果 |
| is null
is not null | 語法: A IS NULL 操作型別: 所有型別 描述: 如果運算式A的值為NULL,則為TRUE;否則為FALSE 語法: A IS NOT NULL | | true false true false |
| LIKE | 語法: A LIKE B 操作型別: strings 描述: 如果字串A或者字串B為NULL,則回傳NULL;如果字串A符合運算式B 的正則語法,則為TRUE;否則為FALSE,B中字符”_”表示任意單個字符,而字符”%”表示任意數量的字符, | | true ture ture |
| REGEXP | 語法: A REGEXP B (java語法: A RLIKE B | | true |
| 按位與& | 語法: A & B 操作型別:所有數值型別 說明:回傳A和B按位進行與操作的結果,結果的數值型別等于A的型別和B的型別的最小父型別(詳見資料型別的繼承關系), | | 0 |
| 位或操作| | 語法: A | B 操作型別:所有數值型別 說明:回傳A和B按位進行或操作的結果,結果的數值型別等于A的型別和B的型別的最小父型別(詳見資料型別的繼承關系) | | 12 |
| 位異或^ | 語法: A ^ B 操作型別:所有數值型別 說明:回傳A和B按位進行異或操作的結果,結果的數值型別等于A的型別和B的型別的最小父型別(詳見資料型別的繼承關系), | | 12 |
| 位取反操作 | 語法: ~A 操作型別:所有數值型別 說明:回傳A按位取反操作的結果,結果的數值型別等于A的型別, | | -7 -5 |
| 函式 | 語法 | 代碼 | 運算結果 |
| 取整函式round | 語法: round(double a) 回傳值: BIGINT 說明: 回傳double型別的整數值部分 (遵循四舍五入) | | 3 4 |
| 指定精度取整函式round | 語法: round(double a, int d) 回傳值: DOUBLE 說明: 回傳指定精度d的double型別 | | 3.1416 |
| 向下取整函式floor | 語法: floor(double a) 回傳值: BIGINT 說明: 回傳等于或者小于該double變數的最大的整數 | | 3 25 |
| 向上取整函式ceil\ceiling | 語法: ceil(double a) 回傳值: BIGINT 說明: 回傳等于或者大于該double變數的最小的整數 | | 4 46 |
| 取亂數函式 | 語法: rand(),rand(int seed) 回傳值: double 說明: 回傳一個0到1范圍內的亂數,如果指定種子seed,則會等到一個穩定的亂數序列 | | 0.545622741591941 0.000471474603038 0.183029190256739 |
| 自然指數函式exp | 語法: exp(double a) 回傳值: double 說明: 回傳自然對數e的a次方 | | 7.38905609893065 2 |
| 以10為低的對數函式
以2為低的對數函式 對數函式 | 語法: log10(double a) 回傳值: double 說明: 回傳以10為底的a的對數 語法: log2(double a) 語法: log(double base, double a) | | 2 3 4 |
| 冪運算函式 pow\power | 語法: pow(double a, double p) 回傳值: double 說明: 回傳a的p次冪 | | 16 |
| 開平方函式sqrt | 語法: sqrt(double a) 回傳值: double 說明: 回傳a的平方根 | | 4 |
| 二進制函式bin
十六進制函式hex 反轉十六進制函式unhex | 語法: bin(BIGINT a) 回傳值: string 說明: 回傳a的二進制代碼表示 語法: hex(BIGINT a) 語法: unhex(string a) | | 111
11 616263 abc |
| 進制zh轉換函式conv | 語法: conv(BIGINT num, int from_base, int to_base) 回傳值: string 說明: 將數值num從from_base進制轉化到to_base進制 | | 11 |
| 絕對值函式abs | 語法: abs(double a) abs(int a) 回傳值: double int 說明: 回傳數值a的絕對值 | | 3.9 10.9 |
| 正取余函式pmod
正弦函式sin 反正弦函式asin | 語法: pmod(int a, int b),pmod(double a, double b) 回傳值: int double 說明: 回傳正的a除以b的余數 語法: sin(double a) 語法: asin(double a) | | 3 1 0.7173560908995228 0.8 |
| 余弦函式cos 反余弦函式acos | 語法: cos(double a) 回傳值: double 說明: 回傳a的余弦值 語法: acos(double a) | | 0.6216099682706644
0.9000000000000001 |
| positiveh函式 negativeh函式 | 語法: positive(int a), positive(double a) 回傳值: int double 說明: 回傳a 語法: negative(int a), negative(double a) | | -5 8 5 -8 |
| 函式型別 | 舉例代碼 | 結果 |
| 1.字串A的長度 length(string A) 2.字串反轉函式reverse(string A) 3.字串連接函式concat(string A, string B…) 4.帶分隔符字串連接函式concat_ws(string SEP, string A, string B…),回傳輸入字串連接后的結果,SEP表示各個字串間的分隔符, 5.字串截取函式substr(string A, int start),substring(string A, int start) 回傳字串A從start位置到結尾的字串 | |
|
| 6.字串轉大寫函式upper(string A) ucase(string A) 7.字串轉小寫lower(string A) lcase(string A) | |
|
| 8.去空格函式trim trim(string A)去除字串兩邊的空格 ltrim(string A)去除字串左邊的空格 rtrim(string A)去除字串右邊的空格 | | |
| 9.正則運算式替換函式regexp_replace(string A, string B, string C) | |  |
| 10.正則運算式決議函式regexp_extract(string subject, string pattern, int index) | |
|
| 11.URL決議函式 parse_url(string urlString, string partToExtract [, string keyToExtract]) 回傳URL中指定的部分,partToExtract的有效值為:HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, and USERINFO. | |
|
| 12.json決議函式 get_json_object(string json_string, string path) 決議json的字串json_string,回傳path指定的內容,如果輸入的json字串無效,那么回傳NULL, | |  |
| 13空格字串函式 space(int n) 回傳長度為n的字串 | | NULL
|
| 14.重復字串函式 repeat(string str,int n) 回傳重復n次后的str字串 | | |
| 15.首字符ascii碼函式 ascii(string str) 回傳字串str第一個字符的ascii碼 | | |
| 16.左補足函式 lpad(string str, int len, string pad) 右補足函式 rpad(string str, int len, string pad) 將str進行用pad進行左\右補足到len位 | |
|
| 17.分割字串函式 split(string str, string pat) 按照pat字串分割str,會回傳分割后的字串陣列 | |
|
| 18.集合查找函式 find_in_set(string str, string strList) 回傳值: int 回傳str在strlist第一次出現的位置,strlist是用逗號分割的字串,如果沒有找該str字符,則回傳0 | |
|
| 1.個數統計函式count 語法: count(*), count(expr), count(DISTINCT expr[, expr_.]) 說明: count(*)統計檢索出的行的個數,包括NULL值的行;count(expr)回傳指定欄位的非空值的個數;count(DISTINCT expr[, expr_.])回傳指定欄位的不同的非空值的個數 2.總和統計函式sum 語法: sum(col), sum(DISTINCT col) 說明: sum(col)統計結果集中col的相加的結果;sum(DISTINCT col)統計結果中col不同值相加的結果 3.平均值統計函式avg 語法: avg(col), avg(DISTINCT col) 說明: avg(col)統計結果集中col的平均值;avg(DISTINCT col)統計結果中col不同值相加的平均值 4.最小值min 語法: min(col) 說明: 統計結果集中col欄位的最小值 5.最大值max 語法: max(col) | select count(*) select count(distinct t) select sum(t) select sum(distinct t) select avg(t) select avg (distinct t) select min(t) select max(t) | |
| 6.非空集合總體變數函式 語法: var_pop(col) 非空集樣本變數函式 語法: var_samp (col) | ||
| 7.總體標準偏離函式stddev_pop(col) 語法: stddev_pop(col) 8.樣本標準偏離函式stddev_samp (col) 語法: stddev_samp (col) | ||
| 9.中位數函式 語法: percentile(BIGINT col, p) | ||
| 10.中位數函式 語法: percentile(BIGINT col, array(p1 [, p2]…)) | ||
| 11.近似中位數函式 語法: percentile_approx(DOUBLE col, p [, B]) | ||
| 12.近似中位數函式 語法: percentile_approx(DOUBLE col, array(p1 [, p2]…) [, B]) | ||
| 13.直方圖 語法: histogram_numeric(col, b) | |


| 條件函式 | 代碼 | 運行結果 |
| 1.IF函式 if(boolean testCondition, T valueTrue, T valueFalseOrNull) 說明: 當條件testCondition為TRUE時,回傳valueTrue;否則回傳valueFalseOrNull | |
|
| 2.非空查找函式 COALESCE(T v1, T v2, …) 回傳引數中的第一個非空值;如果所有值都為NULL,那么回傳NULL | | |
| 3.條件判斷函式 CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END 說明:如果a等于b,那么回傳c;如果a等于d,那么回傳e;否則回傳f | | |
| 4條件判斷函式 CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END | |
|

| 型別 | 注釋 | 代碼 | 運行結果 |
| MAP型別構建函式 | 語法: map (key1, value1, key2, value2, …) | | {"100":"tom","200":"mary"} |
| Struct型別構建函式 | 語法: struct(val1, val2, val3, …) 說明:根據輸入的引數構建結構體struct型別 | | {"col1":"tom","col2": "mary","col3":"tim"} |
| array型別構建函式 | 語法: array(val1, val2, …) 說明:根據輸入的引數構建陣列array型別 | | ["tom","mary","tim"] |
| 型別 | 注釋 | 代碼 | 運行結果 |
| MAP型別訪問 | 語法: M[key] 操作型別: M為map型別,key為map中的key值 說明:回傳map型別M中,key值為指定值的value值,比如,M是值為{'f' -> 'foo', 'b' -> 'bar', 'all' -> 'foobar'}的map型別,那么M['all']將會回傳'foobar' | | tom mary tim |
| Struct型別訪問 | 語法: S.x 操作型別: S為struct型別 說明:回傳結構體S中的x欄位,比如,對于結構體struct foobar {int foo, int bar},foobar.foo回傳結構體中的foo欄位 |
| mary tom |
| array型別訪問 | 語法: A[n] 操作型別: A為array型別,n為int型別 說明:回傳陣列A中的第n個變數值,陣列的起始下標為0,比如,A是個值為['foo', 'bar']的陣列型別,那么A[0]將回傳'foo',而A[1]將回傳'bar' | | tom tim |
| MAP型別長度函式 | arrsy型別長度函式 | cast型別轉換函式 |
| 語法: size(Map<k .V>) | 語法: size(Array<T>) 回傳值: int 說明: 回傳array型別的長度 | 型別轉換函式: cast 語法: cast(expr as <type>) 回傳值: Expected "=" to follow "type" 說明: 回傳轉換后的資料型別 |
| | |
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301468.html
標籤:其他