目錄
卷積神經網路學習內容總結
卷積神經網路實戰——貓狗大戰
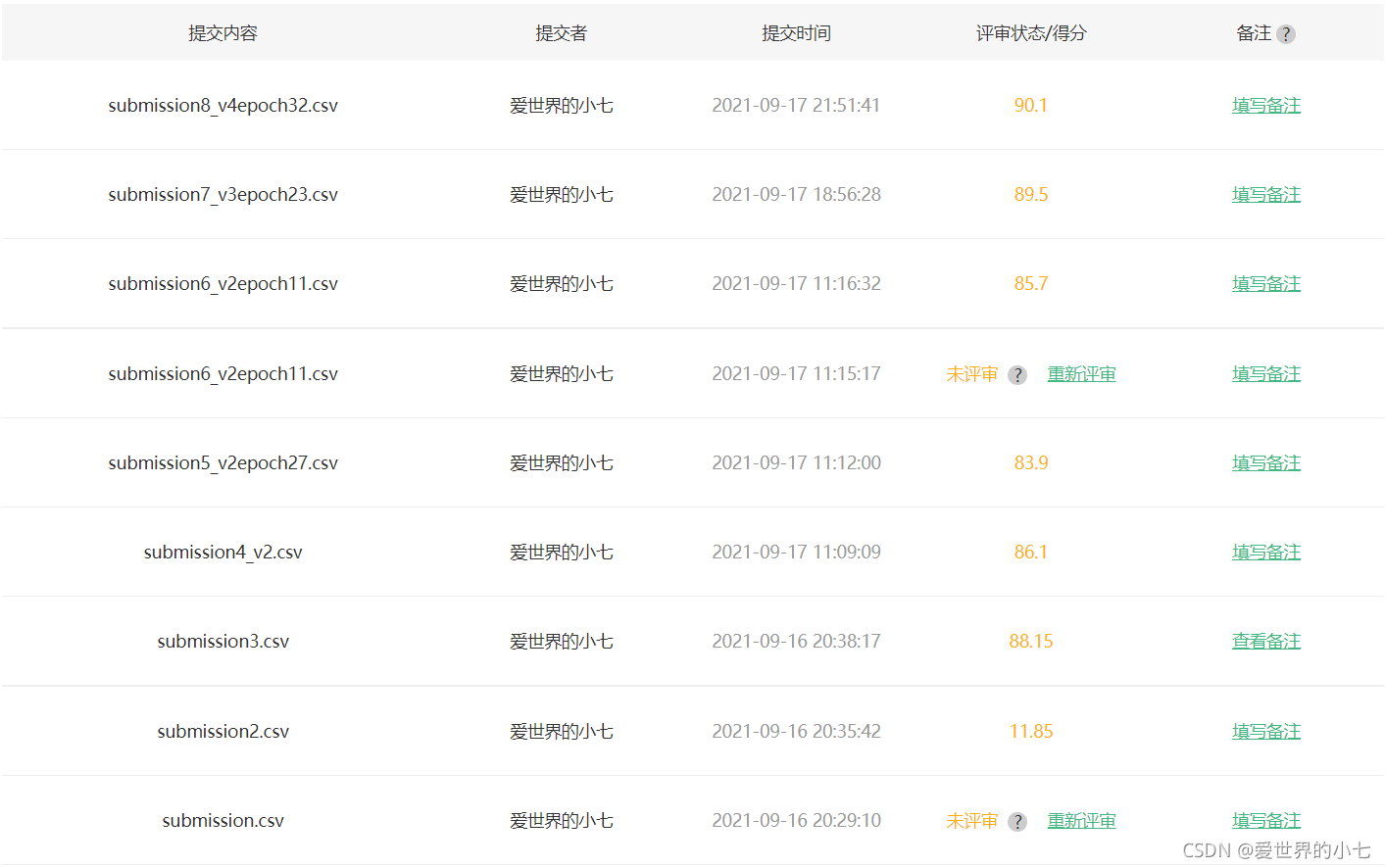
比賽得分
查看資料基本情況
搭建資料處理流程
定義網路
訓練細節
模型測驗/預測代碼
訓程序可視化與分析
還有些改進
卷積神經網路學習內容總結
卷積網路本質上也是一個MLP,不過我們在計算的時候,對原來的計算方式進行了修改,具體來說我們對每一層的神經元進行了特別的索引,每次只選取固定的幾個神經元對輸入進行計算,這樣就實作了“引數共享”的效果,因為不管輸入特征的尺度有多大,我們只采用固定的神經元進行計算,
從更形象的角度來講,卷積是用一組神經元(通常我們為其賦予空間尺度的形象),采用滑動的形式對輸入進行處理,每次滑動處理一個視窗的資訊,視窗的大小即為卷積核的大小(一般而言是這樣,空洞卷積例外),計算的方式是對應位置的卷積核引數與輸入特征進行相乘,最后相加,其計算方式與信號處理中的卷積類似,但是信號處理中的卷積是將卷積核轉置之后再計算,但是因為神經網路的引數具有可學習性,因此轉置這個操作變得沒有必要,
更細節的計算還包括步幅(stride),以及填充(padding),步幅指卷積核在滑動的時候每次以多大的距離移動,如果stride為1,那么卷積核的中心每次平移一個單位(像素),如果stride為2,那么卷積核中心每次隔一個單位移動,一次類推,padding是指在影像的周圍進行補0,其目的在于調整輸出的特征圖(feature map)的尺寸,由于卷積核每次將其視窗內的數值計算出一個值,因次不可避免地會造成輸出尺寸的改變,通過調整步幅和padding我們可以調整輸出的尺寸,大的步幅會減少輸出的尺寸,而大的padding會增大輸出的尺寸,具體的計算公式如下:

圖片來自pytorch官方檔案Page Redirection
其中dilation 是空洞卷積的引數,
提出卷積操作的考慮來自于對影像資料處理的需要,不同于表格資料,影像的每個像素值都是它的一個特征,RGB影像每個像素就有三個特征,而現代影像又擁有巨量的像素值,因此其特征向量的維度例外巨大,如果還采用全連接的方式進行處理,在計算上就會有很大的成本,
第二個原因是影像不同于表格資料,表格資料的特征一般都有明確的語意資訊,比如價格,面積,距離等等,影像的像素值表示的資訊是非常低級的資訊,其語意資訊不直接體現在像素值的大小上,而是在一定的空間范圍內像素值的相互關系上體現,比如一個空間范圍內的像素點構成了一個物體的影像,全連接網路將每個像素值都視作獨立的一個特征,忽略了影像資料在空間上的資訊和聯系,使得全連接網路對影像特征的學習和表示非常困難(但并非不可能,因為我們可以用全連接網路對Fashin_mnist資料進行分類,但是那些影像的尺寸非常之小,而且顏色通道只有一個),
卷積核的引數代表了某種“模式”(pattern),其對輸入進行計算后的輸出可以視作對該模式的識別結果,卷積神經網路通常會采用大量的卷積核,其意義就在于訓練出不同的模式檢測能力,每次計算,卷積核會對輸入的所有特征進行計算,具體而言,對(通道,高,寬)這三個維度的所有資料進行計算,得到一個值,在同一層次的不同卷積核的處理結果最侄訓在通道維度疊加,例如我們對具有形狀(通道=5,高=10,寬=10)的特征進行卷積操作,如果我們采用10個卷積核,而每個卷積核的尺寸為10*10,那么該卷積核有可學習引數10*10*5=500個,其對輸入的計算結果為一個值,10個卷積核的結果在通道的維度拼接,最后產生一個形狀為(10,1,1)的輸出,
正是由于這種疊加的方式,使得卷積神經網路有了強大的模式學習(表示)能力,因為上一層卷積的結果在每個通道上都記錄了一種由該通道的卷積核的引數定義的模式的檢測結果,下一層卷積的操作就可以使這些模式組合起來產生更復雜,更豐富的模式,但是這也造成了卷積神經網路的解釋性困難,盡管其淺層的特征依然保留著人類可以解釋的內容,比如不同的卷積核可以檢測不同的紋理和形狀等,但是其深層特征由于對淺層特征進行了多次抽象,已經無法被人直接理解,
池化可以看作一種特殊的卷積——不帶引數的卷積,其目的是對卷積的特征進行壓縮,操作的方式類似卷積,使用一個滑動視窗對輸入進行處理,在視窗內將資料進行壓縮,具體的方法有取最大值(Max Polling),求平均(Average Polling)等,池化的意義之一是降低卷積核對輸入特征空間平移的敏感性,更實用的意義是對特征進行降采樣,在盡量不損失資訊的情況下降低特征的維度,或者也可以視作一種低級的注意力機制(attention machnism),就像人更容易聽進去聲音大的內容,
卷積神經網路實戰——貓狗大戰
比賽得分
目前筆者最好成績90.1(測驗集正確率90.1%)
查看資料基本情況
貓狗大戰的任務內容是對一張圖片上的物體進行分類,判定其屬于貓或者狗的一種,

我們從比賽網站上下載資料集,查看其形式,

每個檔案夾里都是所有的圖片混在一起,類別在每張圖片的名稱里
搭建資料處理流程
首先我們定義一個函式用來獲得所有圖片的路徑,并從其檔案名中獲得類別資訊,并對類別進行編碼——貓:0 | 狗:1
#資料集的根目錄:path/xxxx.jpg
def get_data(file_path):
file_lst = os.listdir(file_path)#獲得所有檔案名稱 xxxx.jpg
random.shuffle(file_lst)#隨機打亂
data_lst = []
for i in range(len(file_lst)):
clas = file_lst[i][:3] #cat和dog在檔案名的開頭
img_path = os.path.join(file_path,file_lst[i])#將檔案名與路徑合并得到完整路徑,以備讀
#取
if clas == 'cat':
data_lst.append((img_path,0))
else:
data_lst.append((img_path,1))
return data_lst該函式會回傳一個串列,串列元素為元組,元組的第一個元素為圖片路徑,第二個為類別編號
data_lst = [('path/cat_xx.jpg',0) , ('path/dog_xx.jpg',1) , ......, ()]
下面我們定義自定義的資料集類
class catdog_set(torch.utils.data.Dataset):
def __init__(self,path,tsfm):
super(catdog_set).__init__()
self.data_lst = get_data(path)#呼叫剛才的函式獲得資料串列
self.trans = torchvision.transforms.Compose(tsfm)
def __len__(self):
return len(self.data_lst)
def __getitem__(self,index):
(img,cls) = self.data_lst[index]
image = self.trans(Image.open(img))
label = torch.tensor(cls,dtype=torch.float32)
return image,label創建這個類的實體需要提供引數(path:圖片檔案的目錄;tsfm:對圖片進行的變換)
然后定義資料加載器
train_iter = torch.utils.data.DataLoader(catdog_set(train_datapath,
[transforms.Resize((224,224)),transforms.ToTensor()]),batch_size=4,
shuffle=False)
val_iter = torch.utils.data.DataLoader(catdog_set(val_datapath,
[transforms.Resize((224,224)),transforms.ToTensor()]),batch_size=4,
shuffle=False)使用pytorch的DataLoader高級API,接受的第一個引數為Dataset類的實體,bach_size以及隨機打亂shuffle,由于我們在前面已經隨機打亂了資料,因此這里設定為False
定義網路
class conv_net(nn.Module):
def __init__(self):
super(conv_net,self).__init__()
self.body=nn.Sequential(
nn.Conv2d(3,16,5,2,2),
nn.ReLU(),
nn.Conv2d(16,64,5,2,2),
nn.ReLU(),
#nn.MaxPool2d(2,2),#輸出的維度,batch_size*64*55*55
nn.Conv2d(64,64,3,1,1),
nn.ReLU(),
nn.Conv2d(64,64,3,1,1),
nn.ReLU(),
nn.MaxPool2d(2,2),#28*28
nn.Conv2d(64,64,3,1,1),
nn.ReLU(),
nn.Conv2d(64,64,3,1,1),
nn.ReLU(),
nn.MaxPool2d(2,2),#14*14
nn.Conv2d(64,64,3,1,1),
nn.ReLU(),
nn.Conv2d(64,64,3,1,1),
nn.ReLU(),
nn.MaxPool2d(2,2),#7*7
nn.Conv2d(64,64,3,1,1),
nn.ReLU(),
nn.Conv2d(64,64,3,1,1),
nn.ReLU(),
nn.MaxPool2d(2,2),#3*3
)
self.classify = nn.Sequential(
nn.Flatten(),
nn.Linear(576,200),#576 = 3*3*64
nn.Linear(200,1)
)
self.out = nn.Sigmoid()
def forward(self,x):
features = self.classify(self.body(x))
return self.out(features)
由于LeNet架構是串行的網絡,資料在其中順序流通,因此我們直接采用Sequential類對我們的網路進行定義,
搭建的網路本質上是類LeNet架構,由一系列串聯的卷積層和池化層進行特征提取,最后拉平為特征向量,交給由全連接網路組成的分類器進行分類,
self.body是一系列卷積層,進行影像特征提取,self.classify是兩層全連接網路,,第一層將影像特征映射到分類的語意空間,第二層進行分類,輸出一個值,self.out是sigmoid激活函式,用于接受最后一層神經網路的輸出,得到一個0-1的概率預測,超過0.5我們認為是1,否則為0,
訓練細節
def init_weight(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net = conv_net()
device = torch.device('cuda')
net.to(device)
net.apply(init_weight)
criterion = nn.BCELoss()
optimizer = torch.optim.SGD(net.parameters(),lr=0.02,momentum=0.2,weight_decay=1e-4)
def acc(y_hat,y):
with torch.no_grad():
y_hat = y_hat >= 0.5
y_hat.type(y.dtype)
return torch.sum(y_hat==y)
loss_lst = []
train_acc = []
val_acc = []
num_epochs = 50
for epoch in range(num_epochs):
loss_tmp_lst = []
tic = time.time()
for X,y in train_iter:
X_tensor = X.to(device)
y = y.view(-1,1)
label = y.to(device)
output = net(X_tensor)
loss = criterion(output,label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_tmp_lst.append(loss.item())
loss_lst.append(sum(loss_tmp_lst)/len(loss_tmp_lst))
with torch.no_grad():
num_train = 0
num_hits = 0
for X,y in train_iter:
X_tensor = X.to(device)
y = y.view(-1,1)
label = y.to(device)
output = net(X_tensor)
hits = acc(output,label)
num_train += len(y)
num_hits += hits
train_accuracy = num_hits/num_train
train_acc.append(train_accuracy)
num_val = 0
num_hits = 0
for X,y in val_iter:
X_tensor = X.to(device)
y = y.view(-1,1)
label = y.to(device)
output = net(X_tensor)
hits = acc(output,label)
num_val += len(y)
num_hits += hits
val_accuracy = num_hits/num_val
val_acc.append(val_accuracy)
if (epoch+1)%4==0:
state_dict = {'net':net.state_dict(),'optimizer':optimizer.state_dict(),'epoch':epoch}
torch.save(state_dict,f'./ckpt/epoch{epoch}_loss{sum(loss_lst)/len(loss_lst)}_tacc{train_accuracy}_vacc{val_accuracy}.pth')
print(f'time:{time.time()-tic:.3f} loss on epoch:[{epoch+1}]/[{num_epochs}]: ',sum(loss_tmp_lst)/len(loss_tmp_lst),
f'train acc:{train_accuracy:.3f}', f'val acc:{val_accuracy:.3f}')
init_weight函式用來對模型的引數進行初始化,我們采用Xavier初始化,可以盡量保證模型在訓練初期不爆炸,
criterion是我們的損失函式,我們采用Binary Cross Entropy(本質上就是CrossEntropyLoss)
優化器optimizer我們采用SGD(隨機梯度下降),學習率設定為0.02,weight_decay設定為0.0001,momentum設定為0.2,
acc函式是我們定義的用來計算正確率的函式,它回傳一個批次里預測正確的數量,
loss_lst,train_acc,val_acc三個串列用于記錄訓練程序中模型的損失,訓練集正確率與驗證集正確率,用來可視化訓練程序,方便后面分析,
訓練進行50個epoch,在每個epoch我們回圈的從資料加載器中取出一個batchsize的資料進行預測,與label求loss,進行反向傳播更新引數,基程序與房價預測一致,每個epoch結束,我們使用with torch.no_grad()來避免計算梯度(不需要保存計算圖的中間結果),然后分別對訓練集和驗證機進行遍歷,求得正確率,結束后輸出一次訓練情況,用于對模型的訓練進行觀察分細和判斷 ,每4個epoch我們保存一次模型的權重,
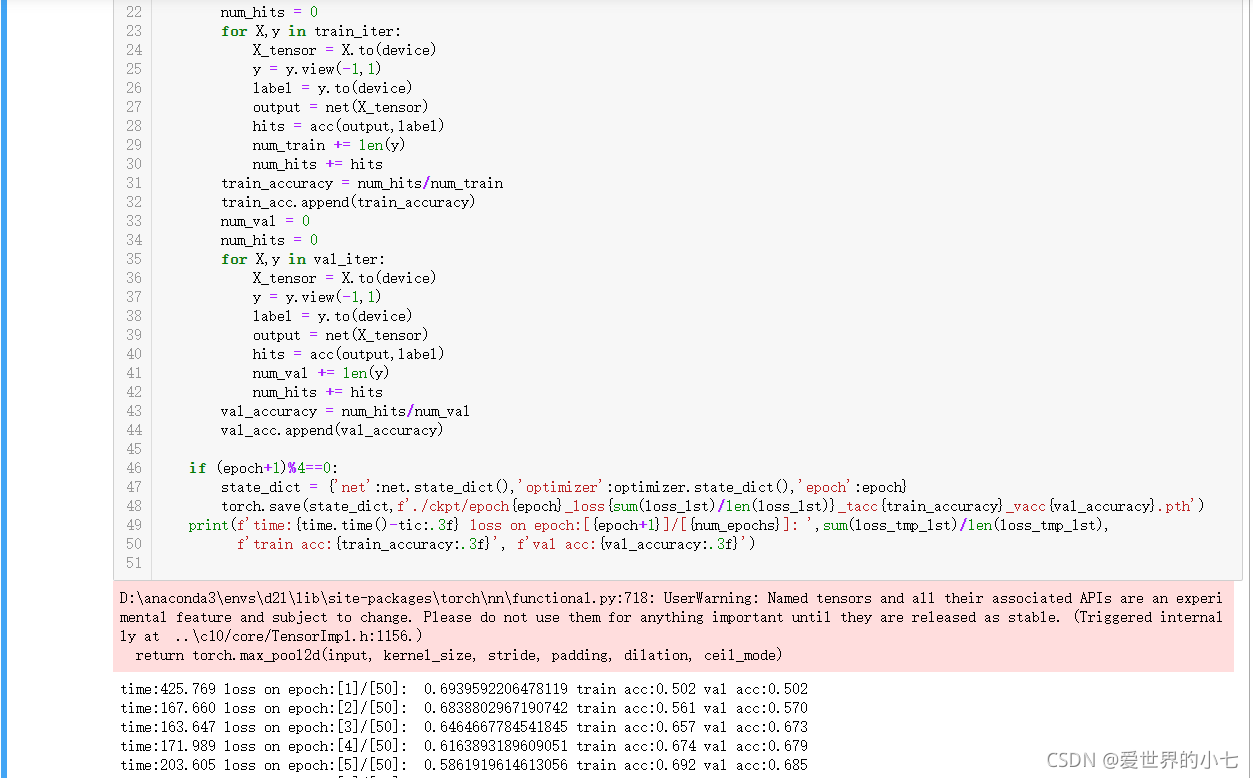
筆者共試驗了2種網路引數,第一種網路引數較少,表現為中間的卷積層有很多32通道的卷積,第二種網路引數較多,所有的卷積層通道數都為64,除此之外,兩種模型的其它方面一樣,
首先我們將所有的輸入資料縮放到224*224的尺寸,保證在最后一層的特征數一樣,之后,我們在前兩層,我們采用大卷積核,大步幅來快速提取底層特征并對輸入進行降采樣,具體來說,第一個卷積層用16個5*5卷積,步幅為2,padding為2,將輸入尺寸降采樣到112*112,通道數升至16,之后再經過64個5*5卷積,步幅為2,padding為2,將輸入尺寸降采樣到56*56,通道升至64,
之后經過多個3*3卷積,步幅為1,padding為1,不改變輸出大小,經過視窗為2*2,步幅為2的maxpolling進行降采樣,具體形狀如下
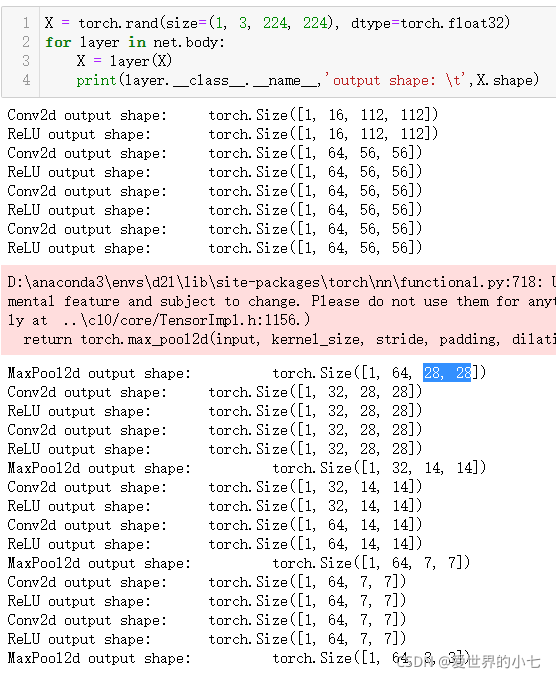
卷積部分最后的特征在拉成向量后,有3*3*64=576維,
模型測驗/預測代碼
我們查看保存的模型權重,選擇在訓練集和驗證機上表現都較好的模型對測驗集進行預測,代碼如下
import pandas as pd
def get_testdata(file_path):
file_lst = os.listdir(file_path)
#random.shuffle(file_lst)
data_lst = []
for i in range(len(file_lst)):
img_path = os.path.join(file_path,file_lst[i])
data_lst.append((int(file_lst[i][:-4]),img_path))
return sorted(data_lst)
class catdog_testset(torch.utils.data.Dataset):
def __init__(self,train_path,tsfm):
super(catdog_testset).__init__()
self.data_lst = get_testdata(train_path)
self.trans = torchvision.transforms.Compose(tsfm)
def __len__(self):
return len(self.data_lst)
def __getitem__(self,index):
(name,img) = self.data_lst[index]
image = self.trans(Image.open(img))
#label = torch.tensor(cls,dtype=torch.float32)
return image,name
ckpt =torch.load(model_path)
net = conv_net()
net.load_state_dict(ckpt['net'])
result = []
with torch.no_grad():
for X,name in test_iter:
X_tensor = X.to(device)
pred = net(X_tensor)
pred.to(torch.device('cpu')).numpy()
if pred >= 0.5:
result.append((name[0].numpy(),1))
else:
result.append((name[0].numpy(),0))
dic={}
dic['id'] = [r[0] for r in result]
dic['pred'] = [r[1] for r in result]
df = pd.DataFrame(dic)
df.to_csv('submission.csv')讀取測驗資料與讀取訓練資料有些差異,因為測驗資料并沒有標簽,圖片名稱只有ID資訊,所以我我們稍微修改一下讀取函式,回傳的資料串列元素為元組,元組的第一個元素是影像的路徑,第二個元素是影像的ID,
測驗程序與訓練程序差異不大,只是我們只進行推理不計算loss和反向傳播,輸出的結果我們將其轉到cup并轉化為numpy資料型別,之后我們創建一個字典dic,用id和pred作為key用所有影像的ID和預測值的串列作為value,之后用pandas將字典轉化為dataframe型別,用to_csv方法寫入CSV檔案,
值得注意的是,CSV檔案的第一行和第一列不需要(網站要求的格式是第一列為ID,第二列為預測類別),需要手動洗掉一下再提交網站,
訓程序可視化與分析
開始我將小模型直接在訓練集上訓練,目標設定在50輪,但是通過觀察訓練情況輸出我發現在25輪之后模型基本穩定,開始上下波動,于是我在35輪手動停止了訓練,之后訓練的所有模型也有這種情況,所以所有的模型都只看前35輪的情況,
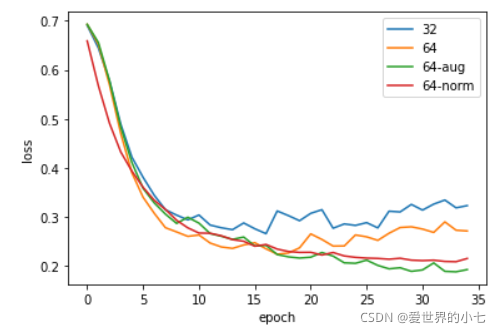
loss曲線
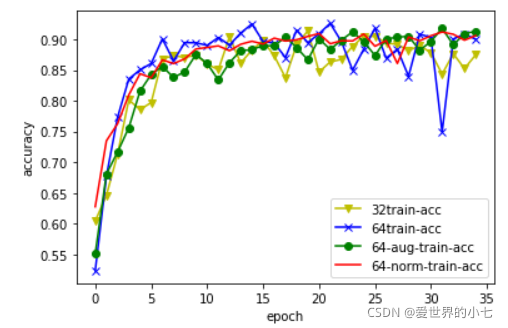
訓練集正確率
驗證集正確率
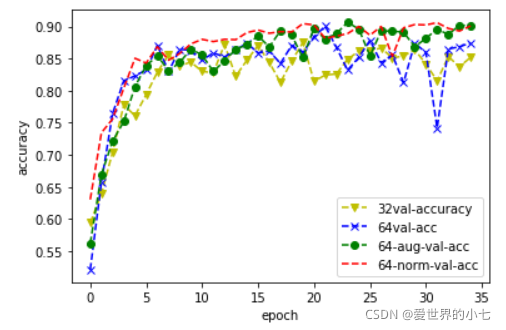
32代表小模型,64代表大模型,aug代表資料增強,norm代表在資料增強的基礎上對影像的三個通道分別進行了歸一化,
可以看到,大模型的訓練損失通常比小模型要更好,但是不使用資料增強的條件下,大模型的正確率表現接近小模型,引入資料增強后,大模型的正確率表現得到提升,loss的水平也進一步下降,
在最初的實驗中,我沒有采取任何影像增強,只用原始資料訓練小模型,在保存下的模型中選擇了最好的模型進行預測,提交之后得到了11.85的好成績(我直接驚呆……),我仔細檢查之后發現原來是我把label搞反了,調整之后重新提交,得到了88.15的成績(100-11.85=88.15),
之后我希望在此基礎上提升,于是我將模型的特征通道增加,也就是使用了大的模型,訓練之后用最好的模型進行預測,得到了86.1分的成績,反而不如小模型(房價預測的情況又上演了……),但是我觀察到這次使用的模型損失比小模型的要小,所以我認為是大模型有點過擬合訓練集,于是我找了保存下來的模型中損失大一點的模型進行預測,得到了83.9分和85.7的成績,而loss越高,正確率越低說明過擬合并不嚴重,二者還基本呈線性關系,那么為什么loss更低的大模型,正確率卻沒有更高呢?我的理解是,因為loss水平不和正確率嚴格成線性關系,也就是說loss越低正確率不一定越高,即使在訓練集上,具體來說,因為我們使用的交叉熵損失函式,計算的是正確類別的模型預測值的負log值,那么有可能出現,在訓練之后,模型對某些類別的預測增強了,也就是“對的更對”,比如之前模型對正確類別的預測為0.6,現在提升到了0.8,這個提升會造成loss的下降,但是模型并沒有因此增加預測正確的數量,因此正確率可以保持不變,甚至因為隨機梯度下降導致在某些類別上預測變錯而導致正確率降低,因此loss只能提供一個總體的概括,不能用來嚴格的確定正確率,
我覺得之所以會這樣是大模型的訓練其實不到位,畢竟引數變得更多,訓練難度也會因此上升,于是后面我采用了資料增強,具體來說,我對訓練集進行了隨機水平翻轉與隨機旋轉,再次訓練,資料增強相當于擴大了資料集,并且引入了隨機性降低了資料的方差,因此通常可以提升模型表現,這次用最好的模型進行預測,得到了89.5分的成績,
最后,我加入了輸入影像的歸一化預處理,將影像調整成接近均值為0,方差為1的正態分布,再次進行訓練,提交后得到了90.1分的成績,
還有些改進
LeNet5為代表的串行卷積神經網路,無法做到很深的層次,因為會面臨梯度爆炸和梯度消失問題,難以訓練,如果采用resnet可以訓練更深的模型,batchnorm也是很有效的穩定訓練的技術,
另外對于現在用的模型,如果在訓練后期進行學習率遞減,可能會取得更好的效果,
此外,學習率,權重衰減,優化演算法等都沒有很多嘗試,一開始選了一組引數,發現效果可以就沒再改了,或許對上述超引數進行搜索可以得到更好的配置,
最后,卷積神經網路雖然比全連接網路更適合處理影像資料,但是其超引數的選擇依然需要謹慎,調參的一些經驗還是不夠,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301619.html
標籤:其他