一、Hadoop簡介
Hadoop是apache軟體基金會下的開源軟體,支持多種編程語言(c,c++,python,java等),
Hadoop兩大核心:HDFS+MapReduce,海量資料的存盤和海量資料的處理,
谷歌大資料的發展:2003年,發布了分布式檔案系統GFS(google file system);2004年,發布了分布式并行編程框架MapReduce,
Hadoop特性:
1、高可靠性:多臺機器構成集群,部分機器發生故障,剩余機器可以繼續對外提供服務,
2、高效性:成百上千的機器并行計算,
3、高擴展性:可以不斷往集群中增加機器,
4、成本低:可以采用普通的PC機來構建一個集群,
5、支持多種編程語言
Hadoop應用現狀:
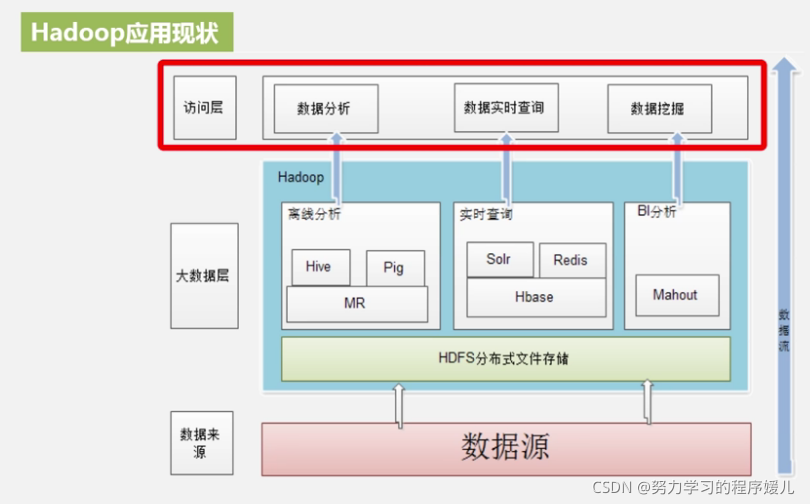
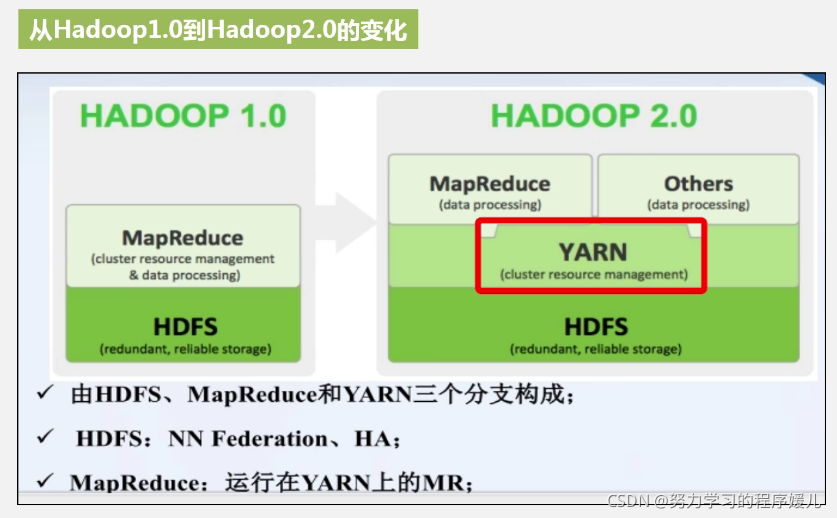
Hadoop版本變化:Hadoop1.0兩大核心:HDFS+MapReduce,
二、Hadoop專案結構
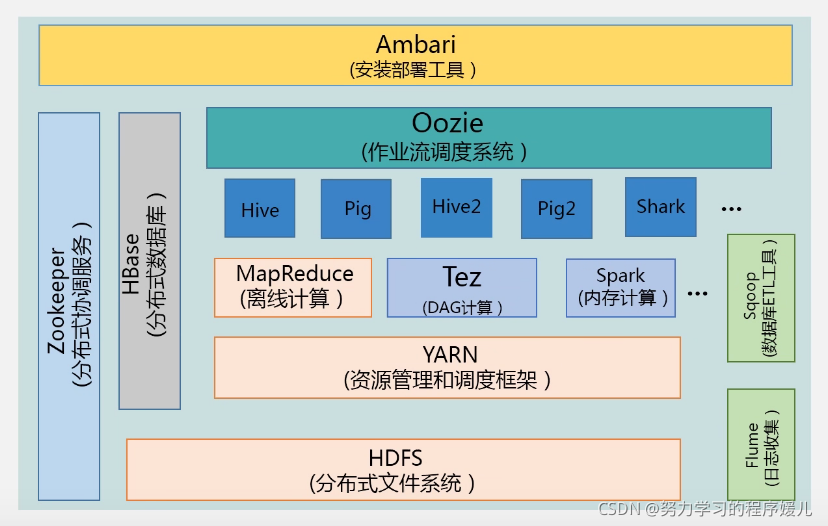
1、HDFS:分布式檔案存盤系統,
2、YARN:資源管理和調度器,
3、MapReduce:離線處理,
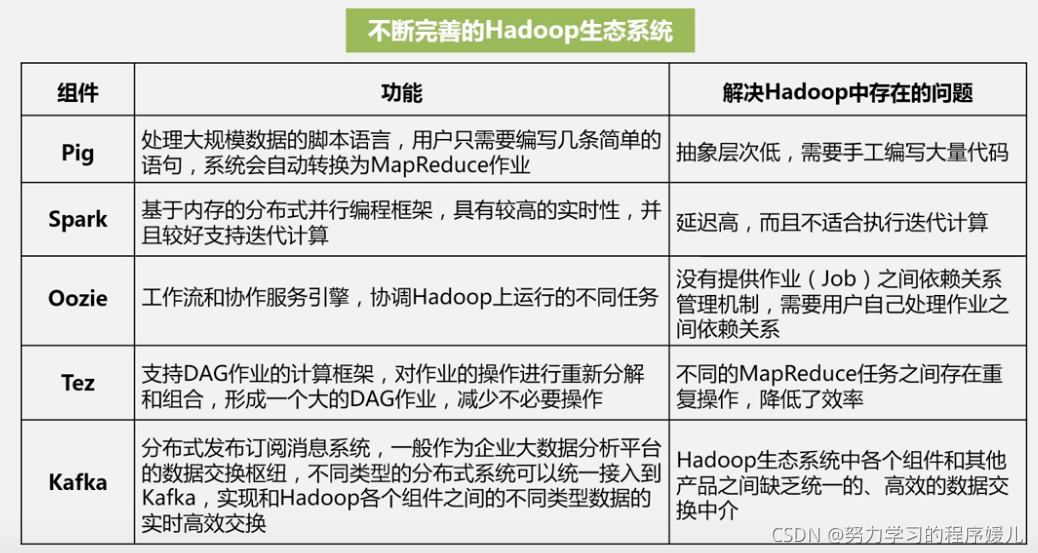
4、Tez:DAG計算,Hadoop查詢處理框架,構建有向無環圖執行任務,
5、Spark:基于記憶體計算,性能比MapReduce高,
6、Hive:資料倉庫,保存資料的歷史版本,滿足企業的決策需求,支持SQL陳述句查詢分析,將SQL轉換成MapReduce作業,
7、Pig:實作流式資料處理,提供類似SQL的語法pig latin,輕量級的腳本語言,
8、Oczie:作業流調度系統,不同作業環節的調度,
9、zookeeper:提供分布式協調一致性服務,集群管理,
10、HBase:列族資料庫,
11、Flume:日志收集,
12、Sqoop:用于在Hadoop與傳統資料庫之間進行資料傳遞,關系型資料庫到HDFS、HBase、Hive互導,
13、Ambari:Hadoop快速部署工具,支持apache Hadoop集群的供應、管理和監控,
三、HDFS
HDFS:分布式檔案系統,海量資料的存盤,
1、HDFS實作目標:
(1)兼容廉價的硬體設備
(2)實作流資料讀寫
(3)支持大資料集
(4)支持簡單的檔案模型
(5)強大的跨平臺兼容性
2、HDFS自身的局限性:
(1)不適合低延遲資料訪問:不能滿足實時處理需求,
(2)無法高效存盤大量小檔案
(3)不支持多用戶寫入和任意修改檔案:只能追加,
3、HDFS塊
塊設計的好處:
(1)支持大規模檔案存盤
(2)簡化系統設計:塊大小是固定的,
(3)適合資料備份
4、HDFS兩大組件
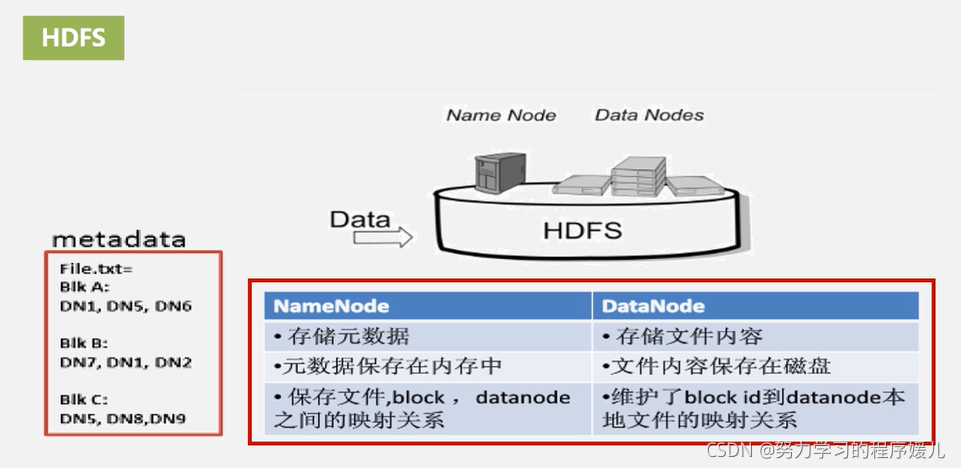
(1)名稱節點:真個HDFS集群的管家,記錄資訊,記錄資料存盤在哪個機器上,相當于資料目錄,名稱節點資訊保存在記憶體中的,
FsImage:保存系統檔案樹,維護內容:檔案的復制等級、塊大小以及組成檔案的塊、修改和訪問的時間、訪問權限,
EditLog:記錄對資料進行創建、洗掉、重命名等操作的,
第二名稱節點:名稱節點的冷備份,
(2)資料節點:存盤實際資料,
5、HDFS體系結構
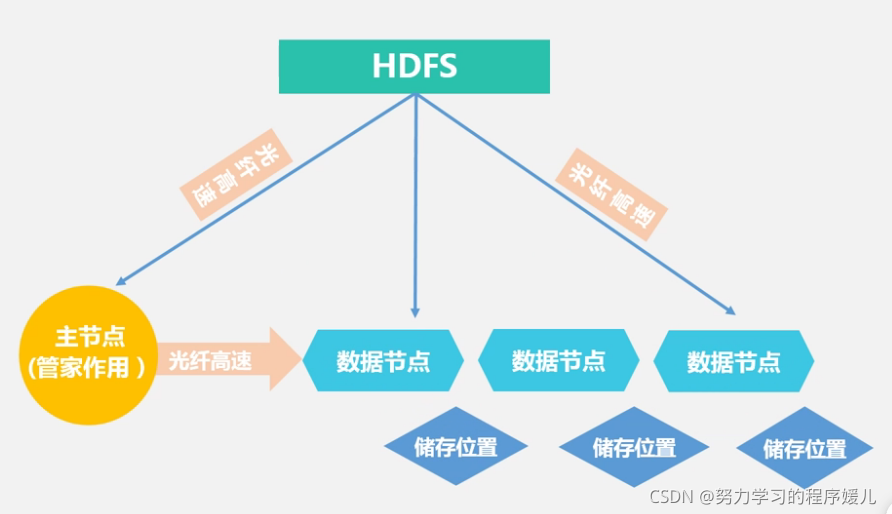
HDFS通信協議:
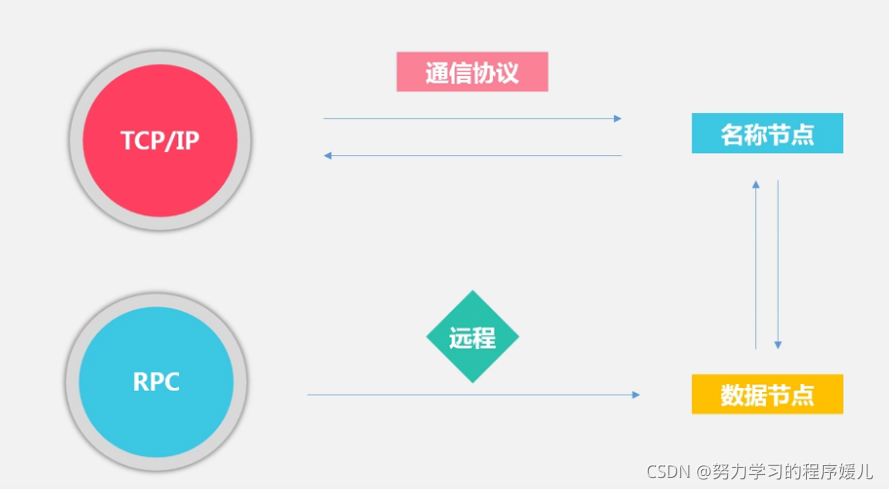
HDFS局限性:
(1)命令空間限制:名稱節點是保存在記憶體中的,因此,名稱節點能夠容納的物件的個數會受到空間大小限制,
(2)性能的瓶頸:整個分布式檔案的吞吐量,受限于單個名稱節點的吞吐量,
(3)隔離問題:由于集群只有一個名稱節點,只有一個命名空間,因此無法對不同應用程式進行隔離,
(4)集群的可用性:一旦這個唯一的名稱節點發生故障,會導致整個集群變得不可用,單點故障,
6、HDFS的存盤原理
(1)冗余資料保存問題:資料冗余保存(默認是3),可以加快資料傳輸速度、很容易檢查資料錯誤、保存資料可靠性,
(2)資料保存策略問題:
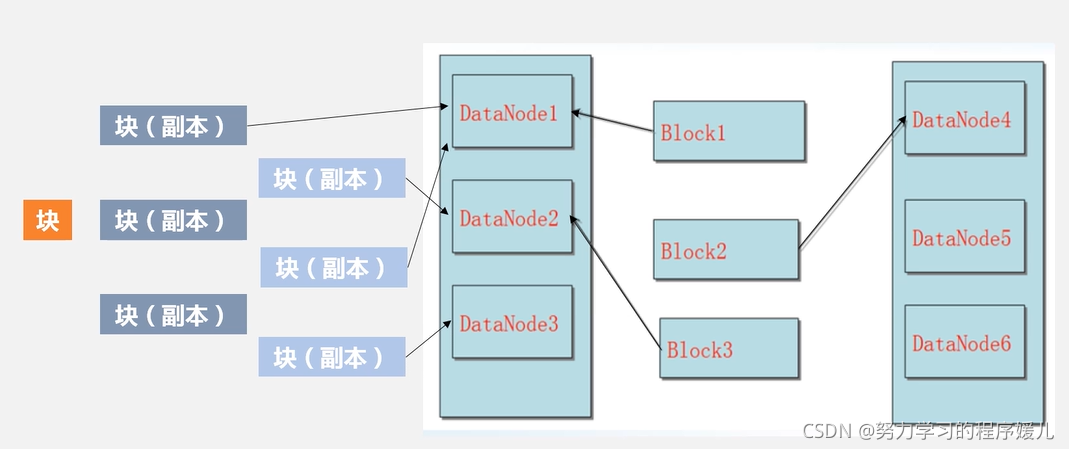
(3)資料恢復問題:名稱節點出錯、資料節點出錯、資料本身出錯,
名稱節點出錯:需要暫停服務一段時間,冷備份恢復,
資料節點出錯:資料節點定期通過遠程呼叫的方式向名稱節點發送心跳資訊,名稱節點探測到資料節點不可用之后,資料節點會被標記為宕機,名稱節點再將故障節點資料復制一份,
資料本身出錯:校驗碼校驗資料是否出錯,
四、Hadoop的優化和發展
以前的Hadoop不足點:
1、抽象層次低,需人工編碼
2、表達能力有限:抽象成map和reduce函式,現實中有些實際問題不能用這兩種函式表達,
3、開發者自己管理作業(job)之間的依賴關系
4、難以看到程式整體邏輯
5、執行迭代操作效率低:分階段進行執行任務,執行完成后寫入分布式檔案系統中,供給下一階段使用,但是對于迭代次數較多的情況效率比較低,比如模擬退火演算法,需要多次迭代,
6、資源浪費:整個任務執行嚴格劃分階段,所有map任務執行完成之后才能執行reduce任務,reduce在map任務執行期間必須等待,
7、實時性差:批處理任務,實時性較差,
Hadoop的改進:
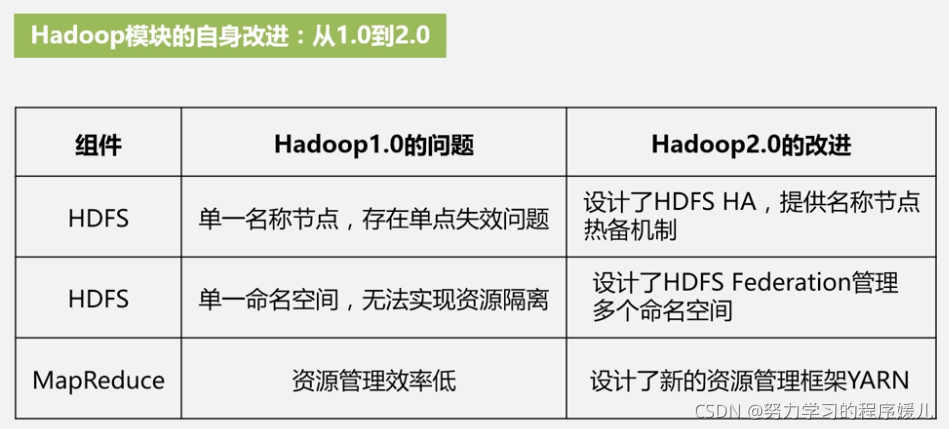
1、Hadoop自身核心組件的改進,MapReduce和HDFS的架構設計改進,
2、Hadoop生態系統其他組件的不斷豐富,包括Pig、Tez、Spark、Kafka等,
五、Hadoop新特性
1、HDFS HA
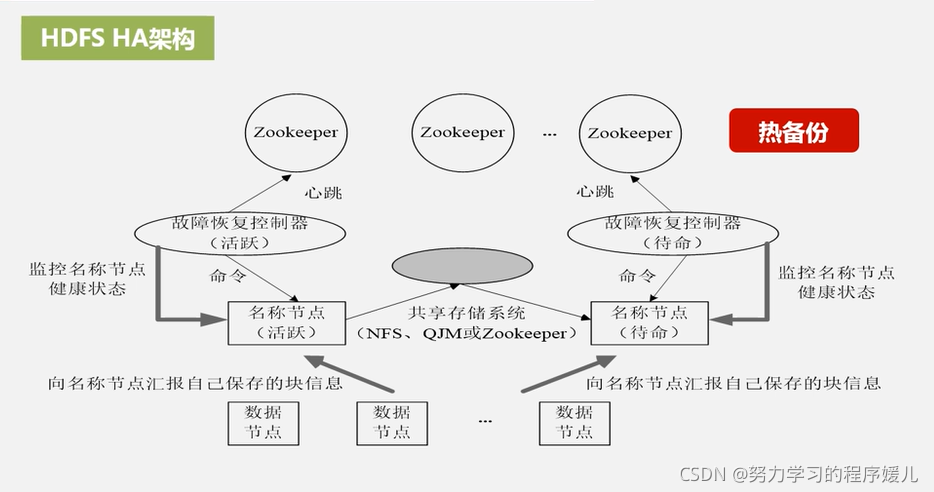
zookeeper
共享存盤系統
2、HDFS Federation
Hadoop1.0中存在的問題:
(1)單點故障問題
(2)不可以水平擴展
(3)系統整體性能受限于單個名稱節點的吞吐量
(4)單個名稱節點難以提供不同程式之間的隔離性
(5)HDFS HA是熱備份,提供高可用性,但是無法解決可擴展性、系統性能、隔離性,
HDFS Federation結構:
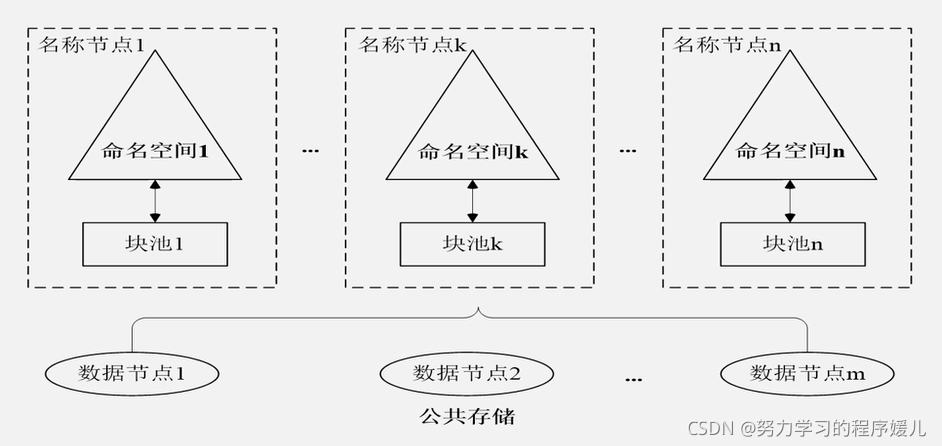
HDFS Federation的優勢:可以解決單名稱節點存在的問題:集群擴展性、性能更高效、良好的隔離性,
3、YARN
YARN與Hadoop集群統一部署,
MapReduce1.0的缺陷:
(1)存在單點故障問題
(2)jobtracker只有一個,任務過重:資源調度、任務調度、任務監控,
(3)容易出現記憶體溢位:按資料分配資源,只看任務數,不看每個任務需要多少資源,
(4)資源劃分不合理:map任務只能提供給map使用,reduce任務只能提供給reduce使用,
YARN設計思路:將原jobtracker三大功能拆解,
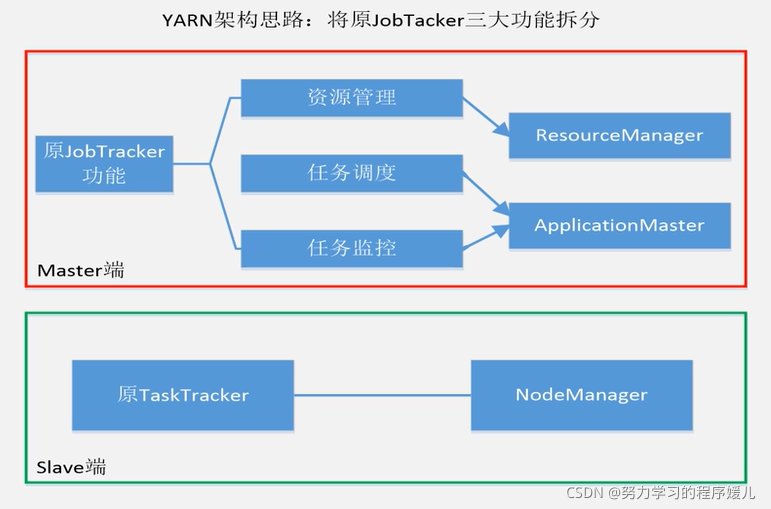
(1)MapReduce1.0,既是計算框架,又是資源調度框架;
(2)YARN,純粹的資源管理調度框架,而不是一個計算框架;
(3)MapReduce2.0,運行在YARN之上的一個純粹的計算框架,
YARN體系結構:
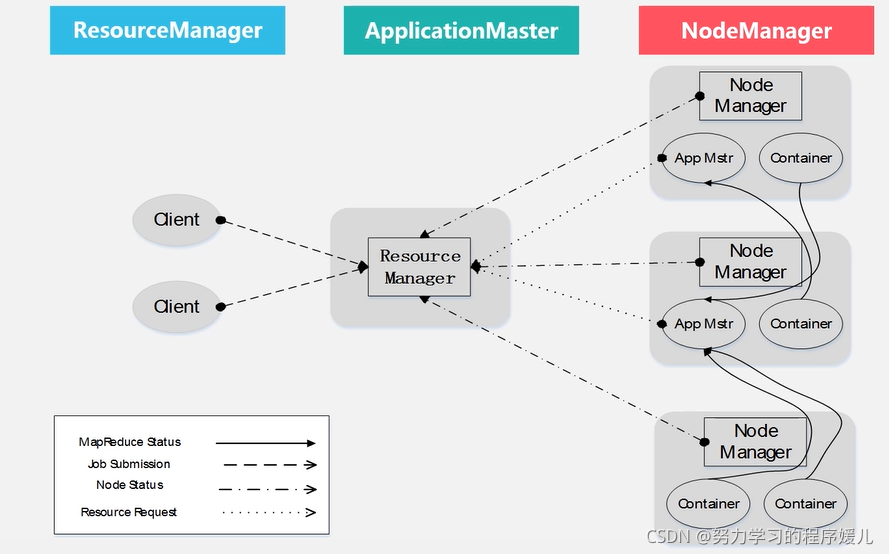
(1)ResourceManager:全域的資源管理器,調度器:接收來自ApplicationMaster應用程式資源請求;容器:以容器的形式分配資源,容器封裝了一定數量的CPU、記憶體、磁盤等資源,從而限定了每個應用程式可以使用的資源量;應用程式管理器:管理所有的應用程式運行,管理ApplicationMaster,
作用:處理客戶端請求、啟動監控ApplicationMaster、監控Node Manager、資源分配與調度,
(2)NodeManager:是每個節點上的代理,容器生命周期管理,只負責管理抽象的容器;監控容器的資源使用情況;以心跳的方式與ResourceManager保持通信;向ResourceManager匯報作業的資源使用情況和每個容器的運行狀態;跟蹤節點的健康狀況;接收來自ApplicationMaster的啟動/停止容器的各種請求,
作用:單個節點上的資源管理、處理來自Resource Manager的命令、處理來自ApplicationMaster的命令,
(3)ApplicationMaster:a.運行在容器中,ResourceManager為它申請容器運行;b.把獲得到的資源進一步分配給內部的某個任務(map或reduce任務),實作資源的二次分配;c.與NodeManager保持通信,告訴它應用程式的啟動、運行、監控和停止,并對所有任務的執行進度和狀態進行監控,并在任務發生失敗時進行執行失敗恢復;d.定時向ResourceManager發送心跳資訊,報告資源的使用情況和應用的進度資訊;e.當作業完成后,向ResourceManager注銷容器,執行周期完成,
作用:任務調度、監控與容錯;為應用程式申請資源,并分配給內部任務,
YARN作業流程:
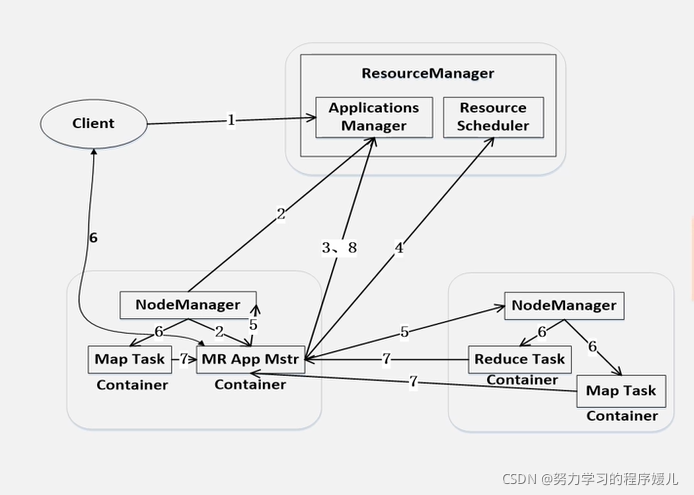
作業流程:
(1)用戶撰寫客戶端應用程式向YARN提交應用程式;
(2)YARN的ResourceManager負責接收和處理來自客戶端的請求,為應用程式分配一個容器,在該容器中啟動一個ApplicationMaster;
(3)ApplicationMaster被創建后會首先向ResourceManager注冊;
(4)ApplicationMaster采用輪詢的方式向ResourceManager申請資源;
(5)ResourceManager以容器的形式向提出申請的ApplicationMaster分配資源;
(6)在容器中啟動任務(運行環境、腳本);
(7)各個任務向ApplicationMaster匯報自己的狀態和進度;
(8)應用程式向運行完成后ApplicationMaster向ResourceManager的應用程式管理器注銷并關閉自己,


YARN中的資源管理比MapReduce1.0更加高效,以容器為單位,不是以slot,不會存在map任務只能map去執行的問題,所以資源利用更高效,
YARN的發展目標:實作一個集群多個框架,

一個集群一個框架導致的問題:集群資源利用率低、資料無法共享、維護代價高,
YARN解決:YARN實作一個集群多個框架,在一個集群上部署一個統一的資源調度管理框架YARN,在YARN上可以部署其他各種計算框架;由YARN進行統一的資源調度管理服務,并且能夠根據各種計算框架的負載需求,調整各自占用的資源,實作集群資源共享和資源彈性收縮;可以實作一個集群上的不同應用負載混搭,有效提高了集群的利用率;不同計算框架可以共享底層存盤,避免了資料集跨集群移動,

4、Pig
(1)pig簡介:降低編碼資料量,


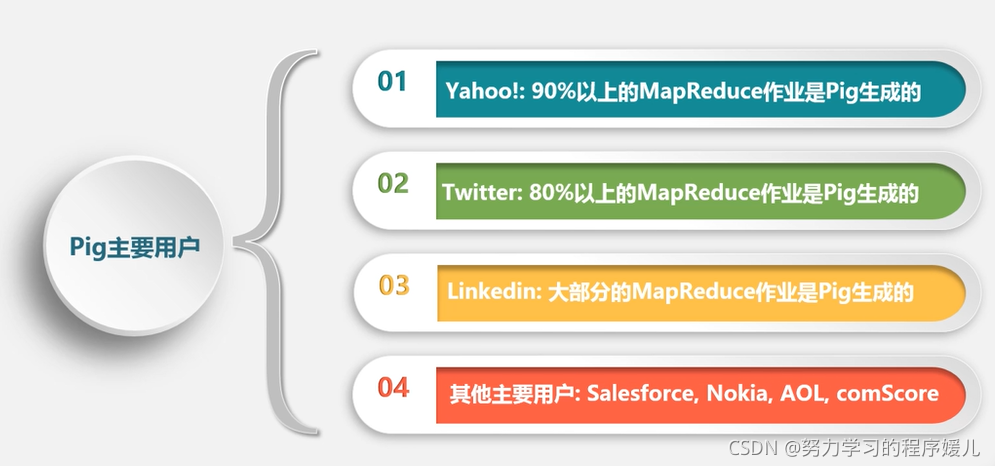
(2)pig主要用戶
5、Tez
Tez:支持DAG作業的計算框架,直接源于MapReduce框架,把map和reduce任務繼續拆分,分解后的元操作可以任意靈活組合,產生新的操作,

Tez的優化主要體現在:
(1)去除連續兩個作業之間的寫入HDFS
(2)去除每個作業流中多余的Map階段
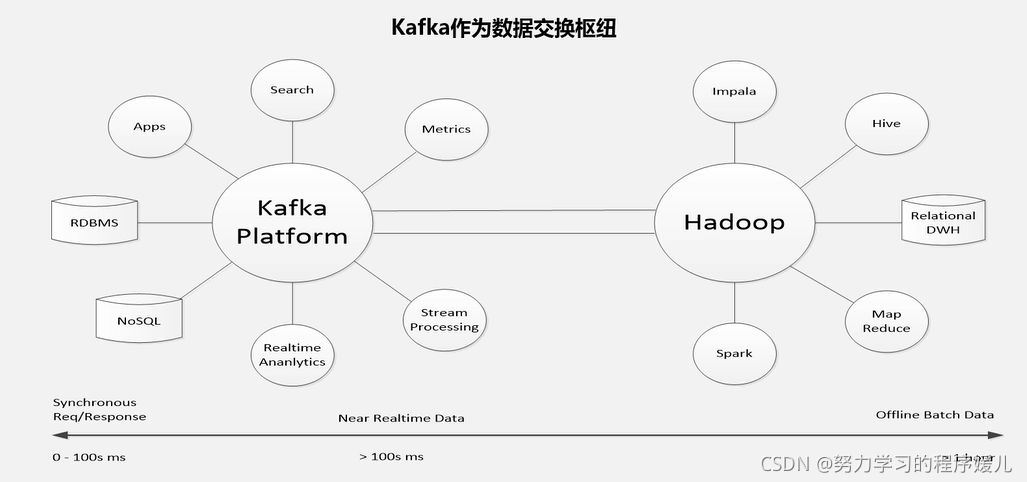
6、Spark和Kafka



轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/310526.html
標籤:其他