ABSTRACT:
提出了新的換臉模型,Simple Swap(SimSwap),可以融合任意的source face跟target face,并且保存source face的身份及target face的屬性特征,模型克服了以往模型的缺陷,通過兩個創新點,1,提出了ID Injection Module(IIM)模塊,通過這個模塊,將針對特定的source face的框架擴展到適用任意的source face,2,提出了Weak Feature Matching Loss損失函式,他能幫助我們模型更好的隱性保留面部屬性特征,
1 INTRODUCTION:
face swapping主要分為兩種方法,包括在影像級別上處理source face的source-oriented方法和在特征級別上處理target face的target-oriented方法,source-oriented方法是將target face的屬性(表情和姿態)轉移到source face,并將source face映射到target face上,這個方法對source face的姿態和光照都比較敏感,并且難以復現target face的表情,target-oriented直接修改目標影像的特征,能夠很好地適應source face的變化,基于gan的方法是在特征級別上對source face的身份特征及target face的屬性特征進行融合,并能適應任何source face,最近采用了兩階段框架,并取得了高保真度的結果,然而,這些方法過于注重身份的遷移,它們在屬性保存上應用了弱約束,導致經常遇到表情或姿態不匹配的問題(不理解的話可以繼續往下看詳解),
為了解決泛化跟屬性保留問題,提出了高效的SimSwap,分析了針對特定身份特征的演算法(類似deepfake演算法),發現是由于將身份資訊融合進解碼器,導致缺乏泛化能力,為了解決這個問題,提出了IIM模塊,通過使用source face的身份資訊對target image的特征層面上做修改,從而解耦了身份資訊跟解碼器的權重,因此可以應用于任意身份,此外,身份和屬性資訊在特征級高度耦合,直接對整個特征進行修改,會導致屬性的表現能力下降,因此需要使用loss級訓這種影響,如果使用強約束,針對每個result image的屬性去匹配target image,這會比較難以處理,因此提出了Weak Feature Matching Loss,弱特征匹配損失函式使生成的結果與輸入目標在高語意水平上保持一致,并隱式地幫助我們的體系結構保持目標的屬性,(不理解的繼續往下看對應詳解)
2 RELATED WORK:
Source-oriented Methods,早期方法是使用3d模型轉換source face的姿勢和光照,從需要人工干預,到自動轉換,再到泛化到任何source face,但由于3d資料集的表情資料有限,導致生成的表情精度不理想,于是便提出了二階段的FSGAN,第一階段先進行姿勢表情的生成,第二階段再將生成的face映射到target image,但Source-oriented方法有個缺點,就是對source image敏感,如果source face的表情或者姿勢過于夸張,那將會導致不理想的結果,
Target-oriented Methods,提出了DeepFakes,只要經過訓練,便可以特定的兩張人臉進行換臉,IPGAN通過提取source face的身份向量跟target face的屬性向量,傳遞到解碼器實作換臉,雖然在source face的身份保存中,效果很好,但對于target face的姿勢,表情,卻并不理想,最頂級的兩階段模型FaceShifter,效果很好,但由于對屬性的弱約束,往往導致表情的不匹配,
3 METHOD
3.1 Limitation of the DeepFakes
DeepFakes包括兩部分,一個共同的編碼器Enc和兩個特定身份的解碼器Decs和Dect,在訓練階段,Enc-Decs輸入扭曲的source image并將其復原,Enc-Dect輸入扭曲的target image并將其復原,在測驗階段,target image會被輸入Enc-Decs中,并被Enc-Decs誤以為扭曲的souce image并將其生成具有source image身份資訊和target image屬性的新image,
其中,Enc用于提取身份資訊及特征,而Decs則設法將特征合成具有source image身份資訊的新image,而source image的身份資訊被整合在了Decs的權重中,因此,Deepfake只適用于特定人物,
3.2 Generalization to Arbitrary Identity
為了克服上述問題,于是要設法將身份資訊從解碼器中分離出來,于是在編碼器與解碼器之間,插入一個ID Injection Module,結構如下圖,
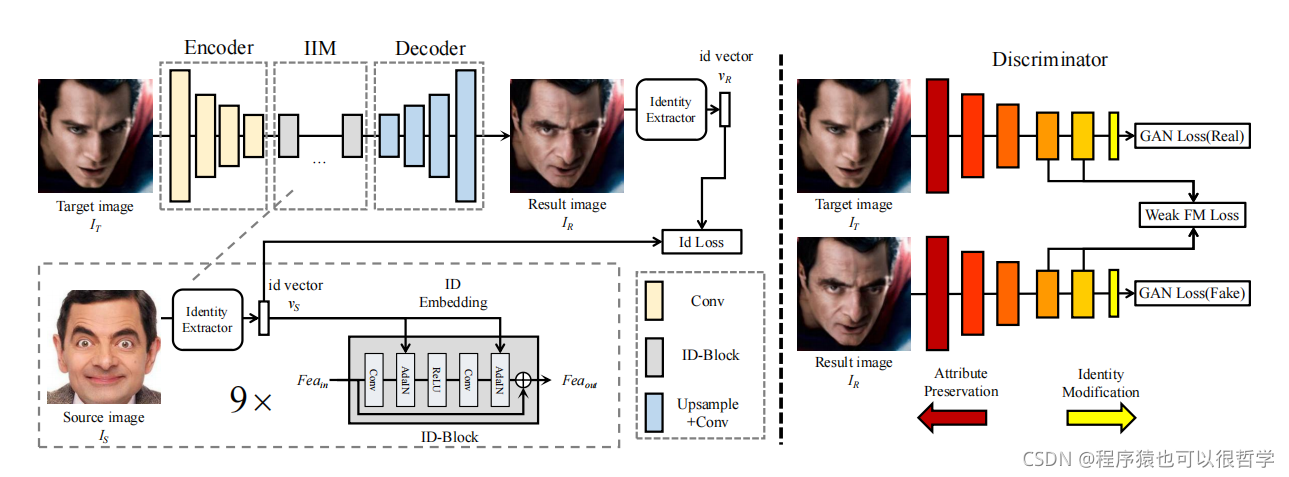
為了將source face變換成target face,并保存source face的身份資訊及target face的屬性,于是,通過編碼器提取target face的特征向量(包括了身份資訊和屬性資訊),然后直接將其全部傳遞給IIM模塊,同時傳入source face的身份特征,由訓練損失去學習修改特征向量,將其target face的身份資訊修改為source face 的身份資訊,
IIM模塊包括兩部分,第一部分是source face的身份特征提取,采用的是一個人臉識別網路進行特征提取,第二部分是特征嵌入,使用的是ID-Blocks將source face的身份資訊注入特征向量中,ID-Blocks是對殘差模塊的改進,將其BN層修改為Adaptive Instance Normalization(AdaIN)(這個沒記錯的話是styleGanV2里面用到),公式如下:
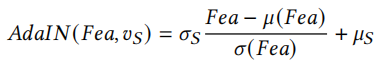
其中𝜇(𝐹𝑒𝑎) and 𝜎(𝐹𝑒𝑎)分別是輸入向量Fea分通道channel-wish的均值和標準差,而𝜎S 和𝜇S是vS經過全連接層生成的變數,其中總共有9個ID-Blocks,
經過IIM模塊,再將輸出特征向量輸入解碼器,生成新的圖片IR,
訓練程序中,提取IR的身份向量vR,并使用身份損失函式計算vR跟vS,為了避免生成圖片喪失target的屬性特征,于是便加了對抗性損失,并能很好的提高圖片質量,其中鑒別器使用的是patchGAN,
3.3 Preserving the Attributes of the Target
由于在IIM模塊中,我們是對target face提取的向量進行修改,所以特征向量中提取的屬性特征也很容易受到影響,于是需要通過損失函式來約束,防止target face的屬性特征受到影響,然而,如果要強制約束每個屬性都不受影響,那么需要對每個特征都單獨訓練一個網路,這是不切實際的,于是提出了Weak Feature Matching Loss,
Feature Matching的想法來源于pix2pixHD,它使用判別器分別提取生成的圖片和真實圖片的多層特征,損失函式如下:
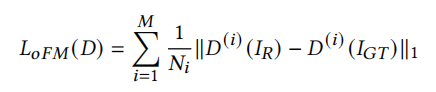
D為鑒別器,M為特征層數,Ni為第i層特征的元素個數,Ir為生成的圖片,IGT為真實的圖片,
在我們模型中,使用target image代替真實圖片,并只使用后面少數幾層的特征層進行計算,公式如下:
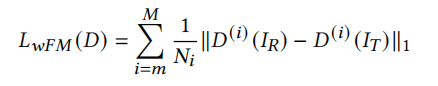
對于原來的Feature Matching損失函式,Weak Feature Matching區別在于只取后面幾層的特征層,原因在于,在淺層特征,往往包含的是像素級別的資訊,如紋理,如果加入,會使生成的圖片趨向于target image,而難于學習source image的身份資訊,于是只提取包含語意資訊的深層特征,
3.4 Overall Loss Function
損失函式包含五個部分,Identity Loss,Reconstruction Loss, Adversarial Loss, Gradient Penalty 和 Weak Feature Matching Loss,
Identity Loss,計算vR和vS的距離,公式如下:
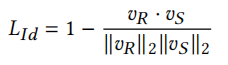
Reconstruction Loss(這個類似FaceShifter里面提到),如果source face跟target face是同個人,那么生成的圖片應該與target image一致,公式如下,如果source face跟target face不是同一個人,則下面損失值為0.

Adversarial Loss and Gradient Penalty,對抗損失采用的是Hinge版本,使用的是多尺寸的判別器,對于大角度的姿勢有更好的效果表現,并使用了梯度懲罰項防止梯度損失,
Weak Feature Matching Loss,由于使用的是多尺度的判別器,于是Feature Matching Loss也應該在所有判別器上做計算,公式如下:
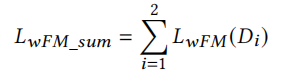
最終公式如下:
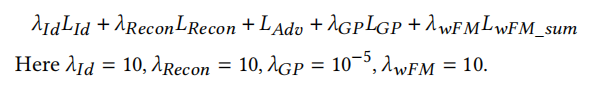
4 EXPERIMENTS
Implementation Detail,使用VGGFace2資料集,為了保證圖片質量,去除了小于250*250的圖片,并將其統一縮放到224*224,并使用了與訓練好的Arcface模型,
4.1 Qualitative Face Swapping Results
4.2 Comparison with Other Methods

可以看出,deepfakes生成的的光照,姿勢并不匹配,而FaceShifter生成的臉的表情和注視方向不完全符合目標臉的表情和注視方向,
Additional Comparison with FaceShifter,更多的比較結果如下圖:

faceshiffter具有很強的身份修改能力,然而,它過于關注身份部分,往往無法保持表情和注視方向等屬性,如第二行中的結果,
4.3 Analysis of SimSwap
使用消融實驗去驗證換臉中,對人物身份特征與人物屬性保持平衡的表現能力,
Efficient Id Embedding,隨機從Forensics++中在每一張人臉中隨機抽選十幀,使用另外一個人臉識別網路去提取生成的frame跟original frame的特征向量,對于生成的每一frame,在原來的frames中去尋找最相似的人臉,來判斷是否為用于合成的original frame,這個正確率稱為ID retrieval,可以用于衡量身份資訊注入的表現能力,并且使用pose estimator對合成的frame和original frame的姿勢進行L2距離計算,
為了進一步比較,訓練另外2個網路,叫做SimSwap-oFM使用了原始的Feature Matching,和SimSwap-nFM沒有使用Feature Matching,對這兩個網路進行了相同的定量實驗,對比結果見,
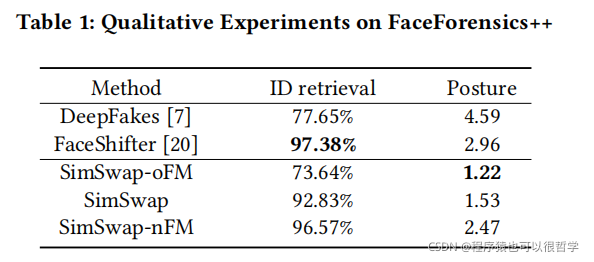
可以看出,SimSwap-oFM具有較小的ID retrieval,因為正如上文分析,采用了淺層特征,使身份資訊難以注入,而SimSwap-nFM有很接近FaceShifter的ID retrieval準確率,SimSwap對比FaceShifter在身分資訊保存略弱,但在屬性資訊的表現更優,
Keeping a Balance between Identity and Attribute,在我們的框架中,有兩種方法來調整身份和屬性之間的平衡,第一種,通過修改𝜆ID的權重,第二種,就是通過修改在Feature Matching Loss選擇的層數,
我們又訓練了四個網路,SimSwap-𝑤𝐹𝑀,SimSwap-oFM-FM-,SimSwap-oFM-id+和SimSwap-wFM-id+,對于wFM,在原始Feature Matching中,保持前幾層,但去掉最后的幾層特征,對于oFM-FM-,保持原始的Feature Matching,但將𝜆𝑜𝐹𝑀減小的5,對于oFM-id+,則保持原始的Feature Matching,但將𝜆𝑜𝐹𝑀增加到20,對于wFM-id+,使用Weak Featture Matching Loss并將
𝜆𝐼𝑑提高到20,實驗結果如下圖:
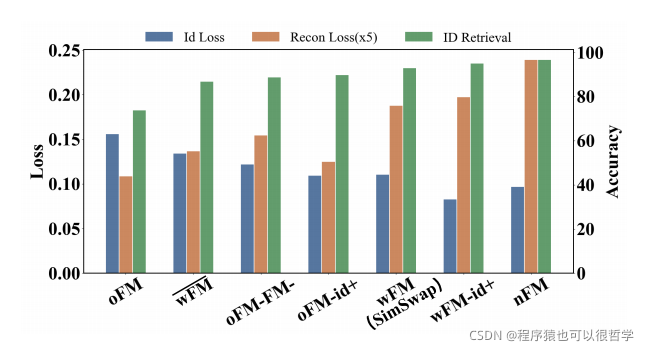

可以看到,第三四列結果相似,可以得出,提高𝜆𝐼𝑑對結果的影響是有限的,nFM也有更好的身份屬性,但也漸漸失去了屬性資訊,比如眼神方向偏離,
5 CONCLUSION
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/310673.html
標籤:其他