江山代有才人出,各領風騷數百年 ——清·趙翼 《論詩五首·其二》
長江后浪推前浪,浮事新人換舊人 ——宋·劉斧《青瑣高議》
東西用時間長了就該換新的了,特別是手機,這幾年發展太快,APP是越來越大,記憶體是越來越不夠用了,想要換新的手機,但不知道換什么,那今天就爬一下淘寶,看一下淘寶手機的資料,參考一下
我的開發環境:python3.8
計算機系統:Windows10
開發工具:pycharm
要用的包:selenium、csv、time
網址:https://www.taobao.com/
今天用的是自動化測驗工具selenium,沒有這個包的同學可以用pip install selenium 來安裝
安裝完之后還需要安裝個瀏覽器驅動,我用的是谷歌瀏覽器
http://chromedriver.storage.googleapis.com/index.html
打開這個鏈接,找到你瀏覽器版本所對應的驅動,這是我的瀏覽器版本
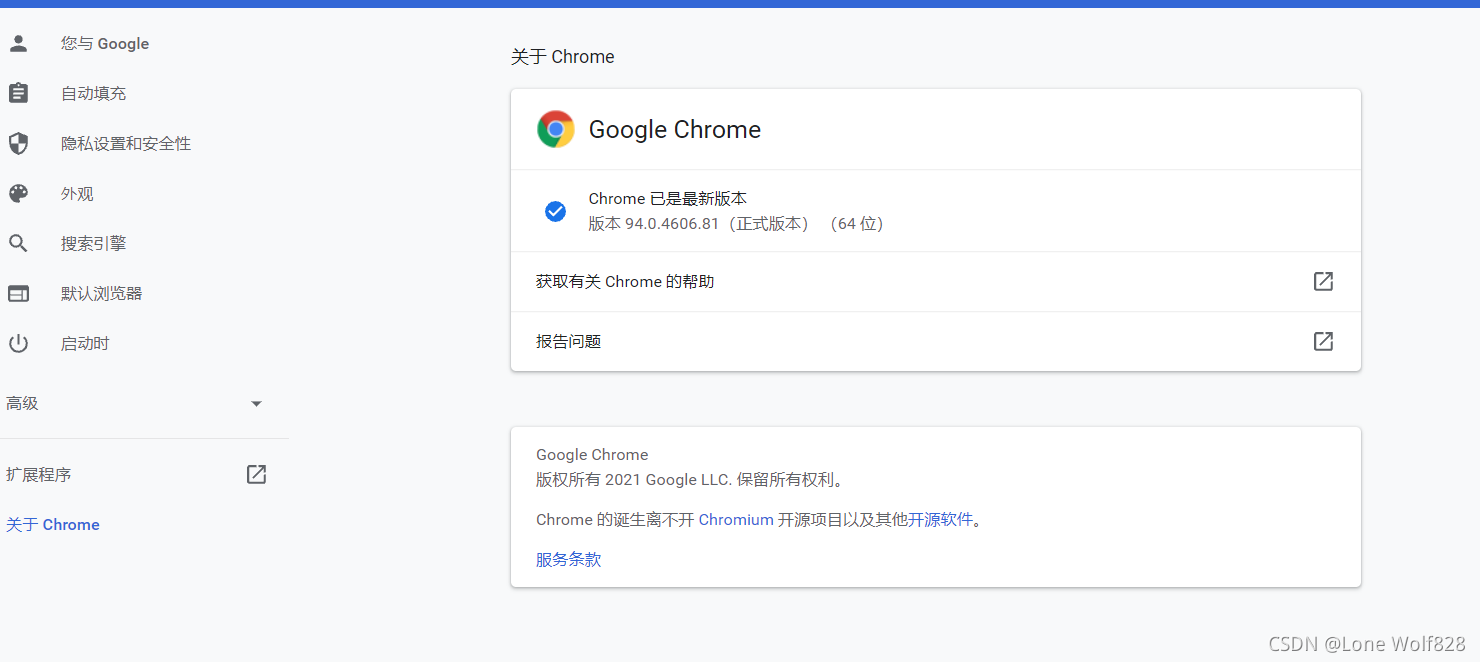
可以看到我的版本是94.0.4606.81 沒有找到一樣的就找低一個版本的
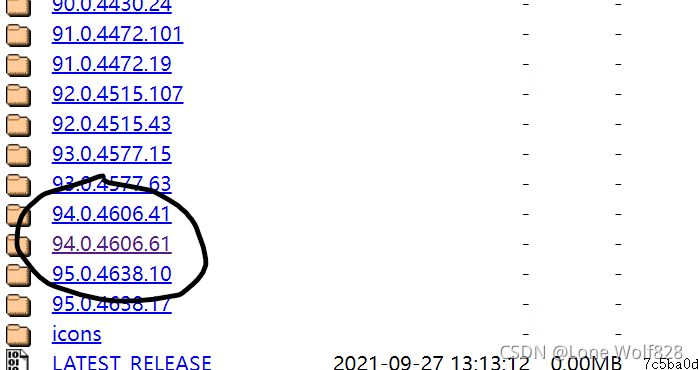
選擇對應的系統,我的是win系統
把下載的壓縮檔案解壓后,放到python解釋器的當前檔案夾下
驗證一下
from selenium.webdriver import Chrome
web = Chrome()
web.get('https://www.baidu.com')
如果正常出現網頁就成功了,注意,一定要和你的版本相匹配,不然就會出現這樣
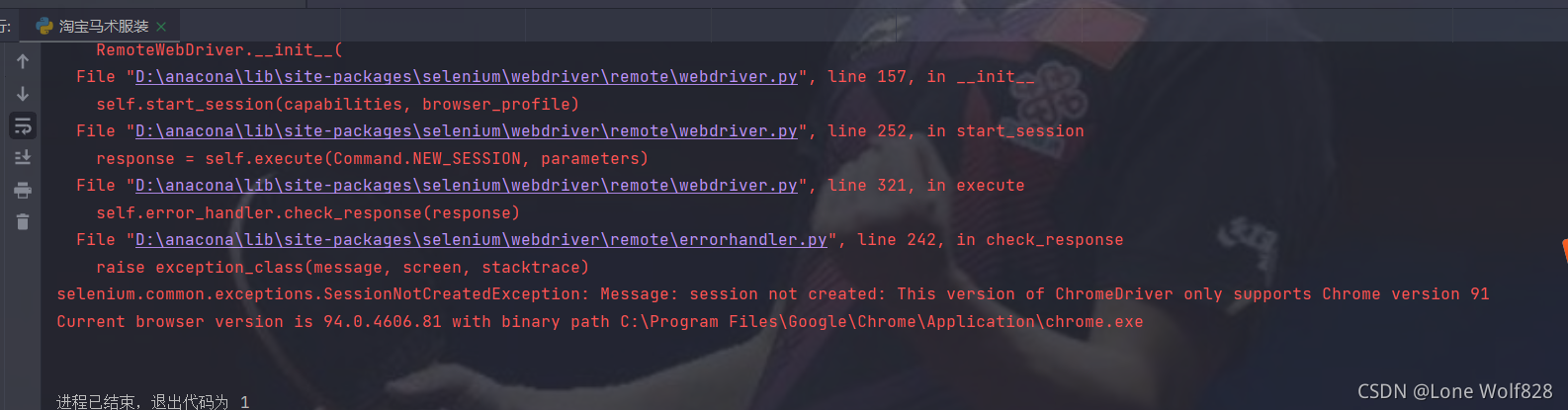
這個是我把瀏覽器更新之后驅動版本太低不支持了
至于其他瀏覽器在這里就不做太多的敘述了,流程大體相同,至于網站可以在網上找一下,下面進入正題
selenium是模擬人正常在瀏覽器上的操作,正常我們打開網頁在搜索框輸入內容點擊搜索
import time
import csv
from selenium.webdriver import Chrome
def main():
win.get('https://www.taobao.com/')
win.find_element_by_xpath('//*[@id="q"]').send_keys(commodity) # 點擊搜索框,輸入前面想要搜索的內容
win.find_element_by_xpath('//*[@id="J_TSearchForm"]/div[1]/button').click() # 點擊搜索按鈕
win.maximize_window() # 將網頁放大方便我們掃碼登錄
time.sleep(15) # 等待15秒 讓我們有時間掃碼
if __name__ == '__main__':
commodity = input('想要查詢的商品:')
win = Chrome()
main()
這里需要我們掃碼登錄才讓我們搜索
我們在分析一下搜索界面,發現所有的商品資料都放在div標簽里,可以看到不是所有的div里都有商品資料,是從第四個div開始有資料,這些div都有共同的特征,那就是屬性都是一樣的,可以用xpath通過class定位進行曬選
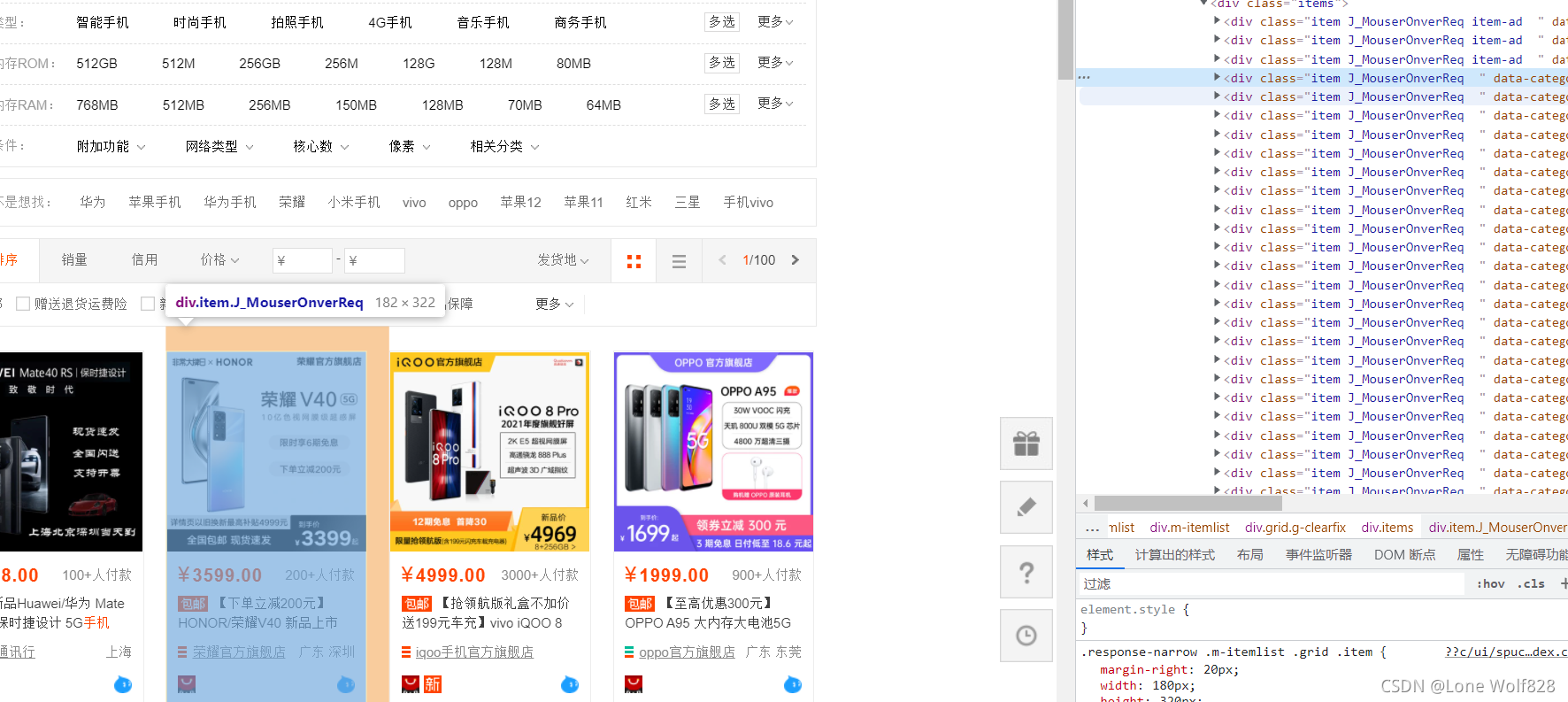
items = win.find_elements_by_xpath('//div[@class="items"]/div[@class="item J_MouserOnverReq "]')
這里需要注意一點因為我們選取了許多個div,所以find_elements_by_xpath里的element一定要加s,這樣才回傳串列,前面選取搜索框和搜索按鈕的時候是不加s的
將獲取的div遍歷取出我們想要資料
for item in items:
# 旗艦店
store = item.find_element_by_xpath('.//div[@class="shop"]/a').text
# 商品簡述
desc = item.find_element_by_xpath('./div[2]/div[2]/a').text
# 價格
price = item.find_element_by_xpath('./div[2]/div/div/strong').text
# 人數
num = item.find_element_by_xpath('.//div[@class="deal-cnt"]').text
# 地址
address = item.find_element_by_xpath('.//div[@class="location"]').text
再將獲取的資料存盤到以搜索名稱命名的csv檔案中
with open(f'{commodity}.csv', mode='a', newline='', encoding='utf-8-sig')as f:
csv_writ = csv.writer(f, delimiter=',')
csv_writ.writerow([store, desc, price, num, address])
附上結果
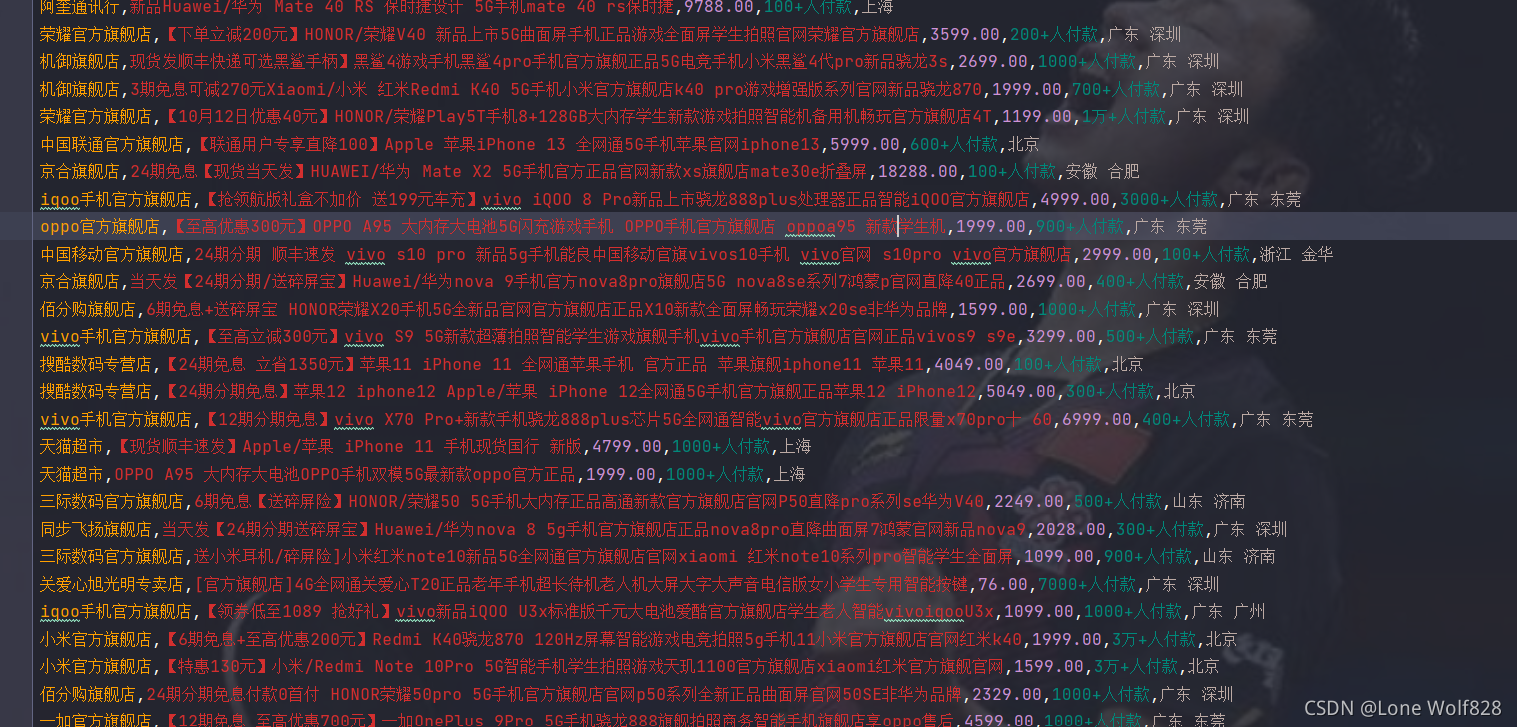
這次先這樣下次再將獲取到的資料進行可視化生成柱狀圖、餅狀圖及地圖分布
全部代碼如下
import time
import csv
from selenium.webdriver import Chrome
def get_data():
items = win.find_elements_by_xpath('//div[@class="items"]/div[@class="item J_MouserOnverReq "]')
for item in items:
# 旗艦店
store = item.find_element_by_xpath('.//div[@class="shop"]/a').text
# 商品簡述
desc = item.find_element_by_xpath('./div[2]/div[2]/a').text
# 價格
price = item.find_element_by_xpath('./div[2]/div/div/strong').text
# 人數
num = item.find_element_by_xpath('.//div[@class="deal-cnt"]').text
# 地址
address = item.find_element_by_xpath('.//div[@class="location"]').text
with open(f'{commodity}.csv', mode='a', newline='', encoding='utf-8-sig')as f:
csv_writ = csv.writer(f, delimiter=',')
csv_writ.writerow([store, desc, price, num, address])
def main():
win.get('https://www.taobao.com/')
win.find_element_by_xpath('//*[@id="q"]').send_keys(commodity) # 點擊搜索框,輸入前面想要搜索的內容
win.find_element_by_xpath('//*[@id="J_TSearchForm"]/div[1]/button').click() # 點擊搜索按鈕
win.maximize_window() # 將網頁放大方便我們掃碼登錄
time.sleep(15) # 等待15秒 讓我們有時間掃碼
get_data()
if __name__ == '__main__':
commodity = input('想要查詢的商品:')
win = Chrome()
main()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/312096.html
標籤:其他
上一篇:第一屆高校大資料專業的小伙伴要出來競爭了,老司機給個就業指導
下一篇:常見的編譯器