我正在嘗試執行相對簡單的代碼,在其中提取影像中某些區域的輪廓并在其上繪制 1 個或多個矩形(通常使用“物件檢測模型”)(作業正常)。但是,然后我需要將在裁剪區域上繪制的矩形的坐標轉換回原始影像(并在其上繪制它們以確保轉換順利)(這不是當前情況)。
我遇到的問題可能與我計算最終“cv2.getPerspectiveTransform”的變換矩陣的方式有關,但我還找不到正確的方法。我嘗試使用原始系統的坐標(如下例所示)或繪制的框的坐標,但似乎都沒有給出預期的結果。
給出的示例是繪制框的簡化案例,因為通常情況下,這些框的坐標將由 AI 模型給出。此外,不能簡單地在繪制的影像上重用“cv2.warpPerspective”,因為主要興趣是獲得繪制框的最終坐標。
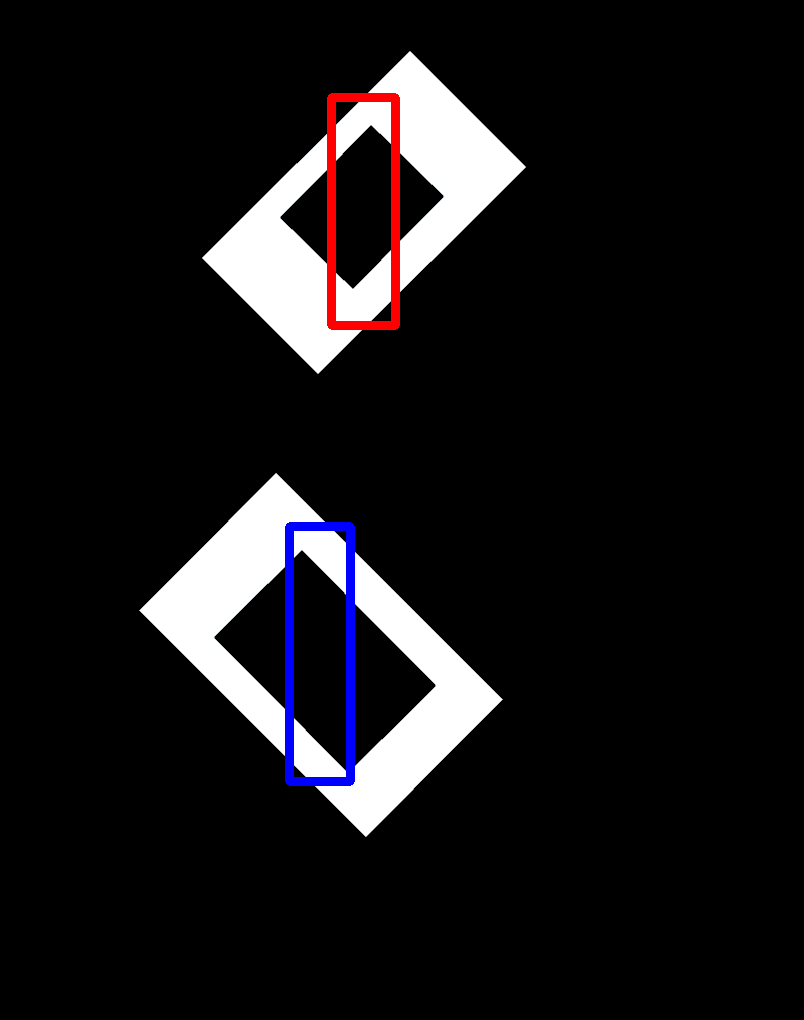
起始影像:

第一個提取矩形的結果(良好):

第二個提取矩形的結果(良好):

繪制矩形的起始影像的結果(錯誤結果):
import numpy as np, cv2, os, copy
#-------------------------
# Starting information
PATH = r"C:\Users\vincentrm\Pictures"
folder_final_dataset = os.path.join(PATH, "Test_folder_2")
if not os.path.isdir(folder_final_dataset): os.mkdir(folder_final_dataset)
img_name = os.path.join(PATH, "Test_img_rot_squarre.png");
mask_name = img_name;
# Used for the images writed during the process:
name_img_wo_extension = os.path.split(img_name)[1]
extension = os.path.splitext(name_img_wo_extension)[1]
name_img_wo_extension = name_img_wo_extension[:-len(extension)]
#-------------------------------------------
# Step #0: Read the image
input_img = cv2.imread(img_name)
mask_output = cv2.imread(mask_name)
mask_output = cv2.cvtColor(mask_output, cv2.COLOR_BGR2GRAY)
ret, mask_output = cv2.threshold(mask_output, 127, 255, 0)
#-------------------------------------------
# Step #1: Identify the elements on the image
#----------------------
if cv2.__version__[0] == 3: # ex. 3.4.1
img2, contours, hierarchy = cv2.findContours(mask_output, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
else: # ex. 4.5.3
contours, hierarchy = cv2.findContours(mask_output, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
#end
#-------------------------------------------
# Step #2: Extraction of the contours of the image with rotated box
#----------------------
tempo_img = input_img
#-----------------------------------
input_img_shape = input_img.shape
for (no, c) in enumerate(contours):
#Method used: Rotated squarre
# Create mask where white is what we want, black otherwise
mask_2 = tempo_img
# Content: ( center (x,y), (width, height), angle of rotation ).
rect = cv2.minAreaRect(c)
# get width and height of the detected rectangle
width = int(rect[1][0])
height = int(rect[1][1])
box = cv2.boxPoints(rect)
box = np.int0(box)
src_pts = box.astype("float32")
# coordinate of the points in box points after the rectangle has been
# straightened
dst_pts = np.array([[0, height-1],
[0, 0],
[width-1, 0],
[width-1, height-1]], dtype="float32")
# the perspective transformation matrix
# - src_pts = coordinate of the rect in the original img
# - dst_pts = coordinate of this rect in the final img.
M = cv2.getPerspectiveTransform(src_pts, dst_pts)
# directly warp the rotated rectangle to get the straightened rectangle
out = cv2.warpPerspective(mask_2, M, (width, height))
#================================================
# Part #3: As as demo, we will simply calculate the points of the box in fonction
# of the extacted rotated box, but normaly, it will be gived by a
# trained "Object Detection Model" on Tensorflow
#------------------------
out_shape = out.shape[0:2] # (H,W) <-> (y,x)
area_box_draw = [0.15]*2
# Format: (y1,x1, y2,x2) - as I normaly have with Tensorflow
boxes = [ int(out_shape[0]*area_box_draw[0]), int(out_shape[1]*area_box_draw[1]),
int(out_shape[0]*(1-area_box_draw[0])), int(out_shape[1]*(1-area_box_draw[1])) ]
boxes = np.expand_dims(boxes, axis=0) # Only used to reproduce Tensorflow format where could have multiple boxes.
color = [(255,0,0), (0,0,255)][no%2] # ["blue", "red"][no%2]
#------------------
boxes = boxes[:, ::-1] # Invert (y,x) to (x,y)
for i in range(0, boxes.shape[0]):
cv2.rectangle(out, tuple(boxes[i, 0:2].tolist()), tuple(boxes[i, 2:4].tolist()), color, 8)
#end
boxes = boxes[:, ::-1] # Revert back from (x,y) to (y,x)
#-----------------------------------------------
# Write the obtain images on the extracted section to verify if it's correct or not.
file_name = os.path.join(folder_final_dataset, name_img_wo_extension "_" str(no) extension)
cv2.imwrite(file_name, out)
#=================================================
# This is the part where it's doesn't work as we want:
#--------------------------------------------
img_shape = np.array(list(out.shape[0:2])*2)
tempo_box = copy.copy(boxes)
#Format of the coordinate at this point: (y1,x1, y2,x2).
nb_box = tempo_box.shape[0]
new_box_pos = [None for i in range(0, nb_box)]
#------------------------------------------
#Format here: (y1 - 0 ,x1 - 1, y2 - 2, x2 - 3)
height = tempo_box[0, 2] - tempo_box[0, 0]
width = tempo_box[0, 3] - tempo_box[0, 1]
# The rect angligned horizontaly: one behind the other one.
# dst_pts = np.array([[0, height-1], [0, 0], [width-1, 0], [width-1, height-1]], dtype="float32")
# Was worst at my sense: alligned vertically.
# dst_pts = np.array([[0, 0], [width-1, 0], [width-1, height-1], [0, height-1]], dtype="float32")
M_2 = cv2.getPerspectiveTransform(dst_pts, src_pts) # Similar result: cv2.invert(M) # But not always the case...
#M_2 = cv2.invert(M)[1]
# Convert from [ [y1,x1, y2,x2] ] to [ [y1,x1], [y2,x2] ].
tempo_box = tempo_box.reshape(-1,2).astype(np.float32)
tempo_box = tempo_box[:, ::-1] # (y,x) to (x,y) format.
converted = cv2.perspectiveTransform(np.expand_dims(tempo_box, axis=0), M_2)
#converted = converted[:, ::-1] # (x,y) to (y,x) format.
converted = converted.reshape(-1,4) # Return to rect-format
color = [(255,0,0), (0,0,255)][no%2] # ["blue", "red"][no%2]
converted = np.int0(converted)
#converted = converted[:, ::-1] # (y,x) to (x,y)
for i in range(0, converted.shape[0]):
cv2.rectangle(input_img, tuple(converted[i, 0:2].tolist()), tuple(converted[i, 2:4].tolist()), color, 8)
#end
#converted = converted[:, ::-1] # # (y,x) to (x,y)
#end_for_loop_over_all_contour
#Write the final obtain image in order to be able to see it.
file_name = os.path.join(folder_final_dataset, name_img_wo_extension "_Final_version" extension)
cv2.imwrite(file_name, input_img)
uj5u.com熱心網友回復:
正如對問題的評論所建議的,解決方案是只繪制一個帶有 4 個點的多邊形,而不是繼續嘗試繪制帶有 2 個點的矩形。
我正在分享最終解決方案的代碼(以及與我所做的測驗相關的一些代碼),以防其他人遇到類似問題。
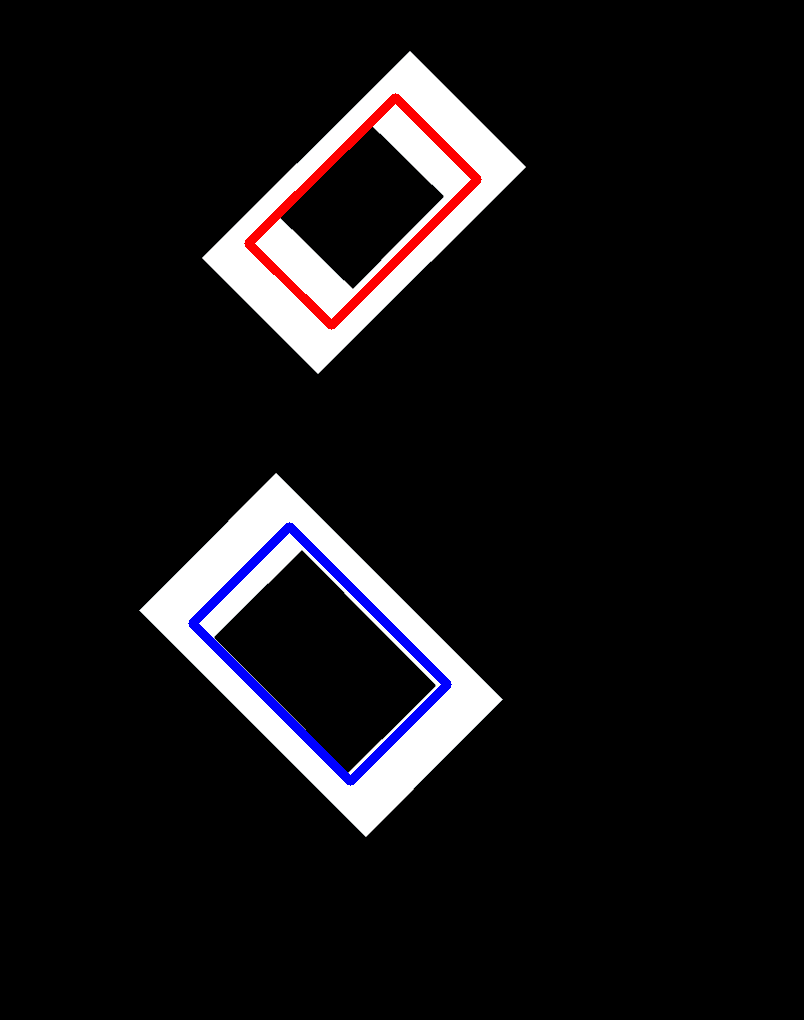
最終結果(與預期結果):
import numpy as np, cv2, os, copy
#-------------------------
# Starting information
PATH = r"C:\Users\vincentrm\Pictures"
folder_final_dataset = os.path.join(PATH, "Test_folder_2")
if not os.path.isdir(folder_final_dataset): os.mkdir(folder_final_dataset)
img_name = os.path.join(PATH, "Test_img_rot_squarre.png");
mask_name = img_name;
# Used for the images writed during the process:
name_img_wo_extension = os.path.split(img_name)[1]
extension = os.path.splitext(name_img_wo_extension)[1]
name_img_wo_extension = name_img_wo_extension[:-len(extension)]
do_create_with_xy_format = False # Original: False - seem to work correctly with both format.
#-------------------------------------------
# Step #0: Read the image
input_img = cv2.imread(img_name)
mask_output = cv2.imread(mask_name)
mask_output = cv2.cvtColor(mask_output, cv2.COLOR_BGR2GRAY)
ret, mask_output = cv2.threshold(mask_output, 127, 255, 0)
#-------------------------------------------
# Step #1: Identify the elements on the image
#----------------------
if cv2.__version__[0] == 3: # ex. 3.4.1
img2, contours, hierarchy = cv2.findContours(mask_output, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
else: # ex. 4.5.3
contours, hierarchy = cv2.findContours(mask_output, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
#end
#-------------------------------------------
# Step #2: Extraction of the contours of the image with rotated box
#----------------------
tempo_img = input_img
#-----------------------------------
input_img_shape = input_img.shape
for (no, c) in enumerate(contours):
#Method used: Rotated squarre
# Create mask where white is what we want, black otherwise
mask_2 = tempo_img
# Content: ( center (x,y), (width, height), angle of rotation ).
rect = cv2.minAreaRect(c)
# get width and height of the detected rectangle
width = int(rect[1][0])
height = int(rect[1][1])
box = cv2.boxPoints(rect)
box = np.int0(box)
src_pts = box.astype("float32")
# coordinate of the points in box points after the rectangle has been
# straightened
dst_pts = np.array([[0, height-1],
[0, 0],
[width-1, 0],
[width-1, height-1]], dtype="float32")
# the perspective transformation matrix
# - src_pts = coordinate of the rect in the original img
# - dst_pts = coordinate of this rect in the final img.
M = cv2.getPerspectiveTransform(src_pts, dst_pts)
# directly warp the rotated rectangle to get the straightened rectangle
out = cv2.warpPerspective(mask_2, M, (width, height))
#================================================
# Part #3: As as demo, we will simply calculate the points of the box in fonction
# of the extacted rotated box, but normaly, it will be gived by a
# trained "Object Detection Model" on Tensorflow
#------------------------
out_shape = out.shape[0:2] # (H,W) <-> (y,x)
area_box_draw = [0.15]*2
# Format: (y1,x1, y2,x2) - as I normaly have with Tensorflow
if not do_create_with_xy_format:
boxes = [ int(out_shape[0]*area_box_draw[0]), int(out_shape[1]*area_box_draw[1]),
int(out_shape[0]*(1-area_box_draw[0])), int(out_shape[1]*(1-area_box_draw[1])) ]
else:
# If create it directly with the (x,y) format.
boxes = [ int(out_shape[1]*area_box_draw[1]), int(out_shape[0]*area_box_draw[0]),
int(out_shape[1]*(1-area_box_draw[1])), int(out_shape[0]*(1-area_box_draw[0])) ]
#end
boxes = np.expand_dims(boxes, axis=0) # Only used to reproduce Tensorflow format where could have multiple boxes.
color = [(255,0,0), (0,0,255)][no%2] # ["blue", "red"][no%2]
#------------------
if not do_create_with_xy_format:
boxes = boxes[:, ::-1] # Invert (y,x) to (x,y)
#end
for i in range(0, boxes.shape[0]):
cv2.rectangle(out, tuple(boxes[i, 0:2].tolist()), tuple(boxes[i, 2:4].tolist()), color, 8)
#end
if not do_create_with_xy_format:
boxes = boxes[:, ::-1] # Revert back from (x,y) to (y,x)
#end
#-----------------------------------------------
# Write the obtain images on the extracted section to verify if it's correct or not.
file_name = os.path.join(folder_final_dataset, name_img_wo_extension "_" str(no) extension)
cv2.imwrite(file_name, out)
#=================================================
# This is the part where it's doesn't work as we want:
#--------------------------------------------
img_shape = np.array(list(out.shape[0:2])*2)
tempo_box = copy.copy(boxes)
#Format of the coordinate at this point: (y1,x1, y2,x2).
nb_box = tempo_box.shape[0]
#------------------------------------------
#Format here: (y1 - 0 ,x1 - 1, y2 - 2, x2 - 3)
if not do_create_with_xy_format:
height = tempo_box[0, 2] - tempo_box[0, 0]
width = tempo_box[0, 3] - tempo_box[0, 1]
else:
#Format: (x1 - 0, y1 - 1, x2 - 2, y2 - 3)
width = tempo_box[0, 2] - tempo_box[0, 0]
height = tempo_box[0, 3] - tempo_box[0, 1]
#end
M_2 = cv2.getPerspectiveTransform(dst_pts, src_pts) # Similar result: cv2.invert(M) # But not always the case...
#M_2 = cv2.invert(M)[1]
if not do_create_with_xy_format:
top_left = tempo_box[0, 0:2].tolist();
top_right = [ top_left[0], top_left[1] width ];
bottom_left = [ top_left[0] height, top_left[1] ];
bottom_right = tempo_box[0, 2:4].tolist();
else:
top_left = tempo_box[0, 0:2].tolist();
top_right = [ top_left[0] width, top_left[1] ] # (x,y) <-> (w,h)
bottom_left = [ top_left[0], top_left[1] height ] # # (x,y) <-> (w,h)
bottom_right = tempo_box[0, 2:4].tolist()
#end
tempo_box = np.array( [top_left, top_right, bottom_right, bottom_left ], dtype = np.float32)
if not do_create_with_xy_format:
tempo_box = tempo_box[:, ::-1] # (y,x) to (x,y) format.
#end
converted = cv2.perspectiveTransform(np.expand_dims(tempo_box, axis=0), M_2)
color = [(255,0,0), (0,0,255)][no%2] # ["blue", "red"][no%2]
converted = np.int0(converted)
# Proposition was to draw 4-point polygons instead of a 2 point rectangle:
for i in range(0, converted.shape[0]):
input_img = cv2.polylines(input_img, [converted[i]], True, color, 8)
#end
#end_for_loop_over_all_contour
#Write the final obtain image in order to be able to see it.
file_name = os.path.join(folder_final_dataset, name_img_wo_extension "_Final_version" extension)
cv2.imwrite(file_name, input_img)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/313200.html