文章目錄
- 演算法類別
- 回歸演算法-線性回歸分析
- 線性回歸
- 損失函式(誤差大小
- 最小二乘法之正規方程
- 損失函式直觀圖(單變數舉例)
- 最小二乘法之梯度下降
- 正規方程與梯度下降的對比?
- 線性回歸實體
- 波士頓房價資料案例分析流程
- 回歸性能評估
- sklearn回歸評估API
- mean_squared_error
- 1、LinearRegression與SGDRegressor評估
- 問題:訓練資料訓練的很好啊,誤差也不大,為什么在測驗集上 面有問題呢?
- 過擬合與欠擬合
- 欠擬合原因以及解決辦法
- 過擬合原因以及解決辦法
- L2正則化
- 帶有正則化的線性回歸-Ridge
- Ridge
- 線性回歸 LinearRegression與Ridge對比
- 分類演算法-邏輯回歸
- sigmoid函式
- 邏輯回歸公式
- 邏輯回歸的損失函式、優化(了解)
- sklearn邏輯回歸API
- LogisticRegression
- LogisticRegression回歸案例
- 良/惡性乳腺癌腫資料
- pandas使用
- 良/惡性乳腺癌腫分類流程
- LogisticRegression總結
- 多分類問題
- 非監督學習的特點?
- 非監督學習(unsupervised learning)
- k-means步驟
- k-means API
- Kmeans
- k-means對Instacart Market用戶聚類
- Kmeans性能評估指標
- Kmeans性能評估指標API
- silhouette_score
- Kmeans總結
演算法類別
1、回歸演算法-線性回歸分析
2、線性回歸實體
3、回歸性能評估
4、分類演算法-邏輯回歸
5、邏輯回歸實體
6、聚類演算法-kmeans
7、k-means實體
回歸演算法-線性回歸分析
期末成績:0.7×考試成績+0.3×平時成績
西瓜好壞:0.2×色澤+0.5×根蒂+0.3×敲聲
試圖學得一個通過屬性的線性組合來進行預測的函式:
f(x)=w_1x_1+w_2x_2+…+w_dx_d+b
w為權重,b稱為偏置項,可以理解為:w_0×1
線性回歸
定義:線性回歸通過一個或者多個自變數與因變數之間之間進行建模的回歸分析,其中特點為一個或多個稱為回歸系數的模型引數的線性組合
一元線性回歸:涉及到的變數只有一個
多元線性回歸:涉及到的變數兩個或兩個以上
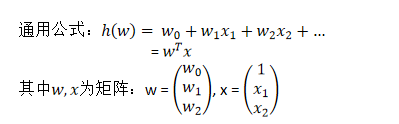
預測結果與真實值是有一定的誤差
損失函式(誤差大小

如何去求模型當中的W,使得損失最小?
(目的是找到最小損失對應的W值)
最小二乘法之正規方程
注:X,y代表著什么?
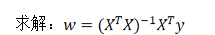
X為特征值矩陣,y為目標值矩陣
缺點:當特征過于復雜,求解速度太慢
對于復雜的演算法,不能使用正規方程求解(邏輯回歸等)
損失函式直觀圖(單變數舉例)
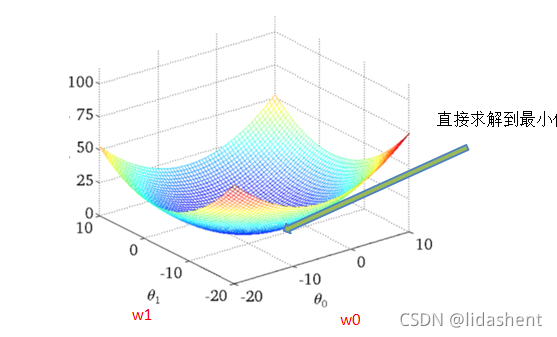
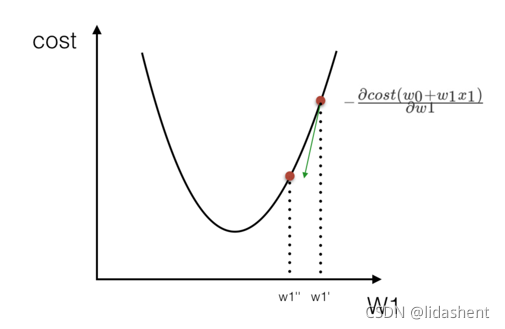
最小二乘法之梯度下降
我們以單變數中的w0,w1為例子:

理解:沿著這個函式下降的方向找,最后就能找到山谷的最低點,然后
更新W值
使用:面對訓練資料規模十分龐大的任務
正規方程與梯度下降的對比?
sklearn線性回歸正規方程、梯度下降API
?sklearn.linear_model.LinearRegression
?正規方程
?sklearn.linear_model.SGDRegressor
?梯度下降
LinearRegression、SGDRegressor
?sklearn.linear_model.LinearRegression()
?普通最小二乘線性回歸
?coef_:回歸系數
?sklearn.linear_model.SGDRegressor( )
?通過使用SGD最小化線性模型
?coef_:回歸系數
線性回歸實體
1、sklearn線性回歸正規方程、梯度下降API
2、波士頓房價資料集分析流程
波士頓房價資料案例分析流程
1、波士頓地區房價資料獲取
2、波士頓地區房價資料分割
3、訓練與測驗資料標準化處理
4、使用最簡單的線性回歸模型LinearRegression和
梯度下降估計SGDRegressor對房價進行預測
回歸性能評估
(均方誤差(Mean Squared Error)MSE) 評價機制:
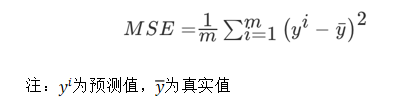
sklearn回歸評估API
?sklearn.metrics.mean_squared_error
mean_squared_error
?mean_squared_error(y_true, y_pred)
?均方誤差回歸損失
?y_true:真實值
?y_pred:預測值
?return:浮點數結果
注:真實值,預測值為標準化之前的值
1、LinearRegression與SGDRegressor評估
2、特點:線性回歸器是最為簡單、易用的回歸模型,
從某種程度上限制了使用,盡管如此,在不知道特征之
間關系的前提下,我們仍然使用線性回歸器作為大多數
系統的首要選擇,
小規模資料:LinearRegression(不能解決擬合問題)以及其它
大規模資料:SGDRegressor
問題:訓練資料訓練的很好啊,誤差也不大,為什么在測驗集上 面有問題呢?
過擬合與欠擬合
過擬合:一個假設在訓練資料上能夠獲得比其他假設更好的擬合, 但是在訓練資料外的資料集上卻不能很好地擬合資料,此時認為這個假設出現了過擬合的現象,(模型過于復雜)
欠擬合:一個假設在訓練資料上不能獲得更好的擬合, 但是在訓練資料外的資料集上也不能很好地擬合資料,此時認為這個假設出現了欠擬合的現象,(模型過于簡單)
欠擬合原因以及解決辦法
?原因:
?學習到資料的特征過少
?解決辦法:
增加資料的特征數量
過擬合原因以及解決辦法
?原因:
?原始特征過多,存在一些嘈雜特征,
?模型過于復雜是因為模型嘗試去兼顧
?各個測驗資料點
?解決辦法:
?進行特征選擇,消除關聯性大的特征(很難做)
?交叉驗證(讓所有資料都有過訓練)
?正則化(了解)

L2正則化
作用:可以使得W的每個元素都很小,都接近于0
優點:越小的引數說明模型越簡單,越簡單的模型則越不
容易產生過擬合現象
帶有正則化的線性回歸-Ridge
?sklearn.linear_model.Ridge
Ridge
?sklearn.linear_model.Ridge(alpha=1.0)
?具有l2正則化的線性最小二乘法
?
?alpha:正則化力度
?coef_:回歸系數
觀察正則化程度的變化,對結果的影響?
線性回歸 LinearRegression與Ridge對比
?嶺回歸:回歸得到的回歸系數更符合實際,更可靠,另外,能讓
?估計引數的波動范圍變小,變的更穩定,在存在病態資料偏多的研
?究中有較大的實用價值,
分類演算法-邏輯回歸
邏輯回歸是解決二分類問題的利器
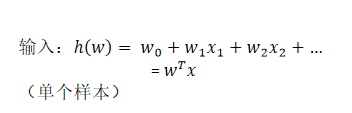
sigmoid函式
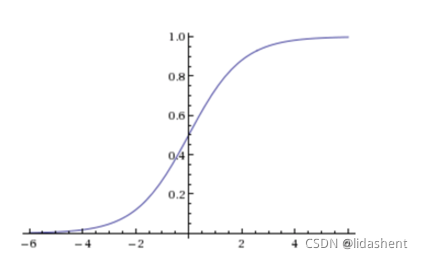
邏輯回歸公式
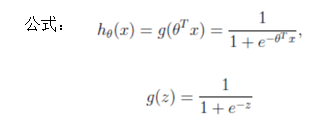
輸出:[0,1]區間的概率值,默認0.5作為閥值
注:g(z)為sigmoid函式
邏輯回歸的損失函式、優化(了解)
與線性回歸原理相同,但由于是分類問題,
損失函式不一樣,只能通過梯度下降求解
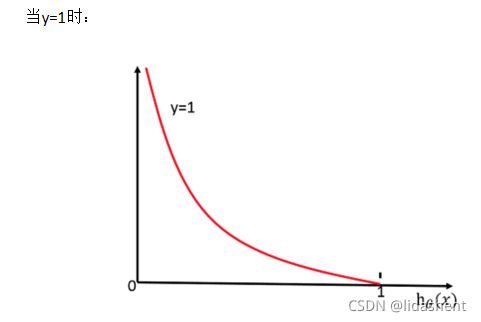
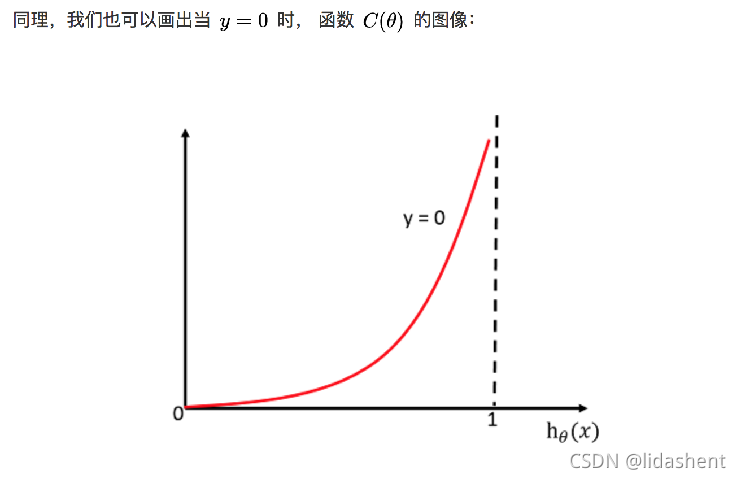
對數似然損失函式:
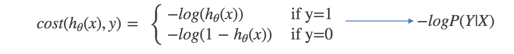
完整的損失函式:
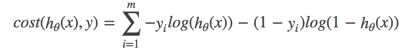
cost損失的值越小,那么預測的類別準確度更高
sklearn邏輯回歸API
?sklearn.linear_model.LogisticRegression
LogisticRegression
?sklearn.linear_model.LogisticRegression(penalty=‘l2’, C = 1.0)
?
?Logistic回歸分類器
?coef_:回歸系數
LogisticRegression回歸案例
?良/惡性乳腺癌腫瘤預測
良/惡性乳腺癌腫資料
原始資料的下載地址:
https://archive.ics.uci.edu/ml/machine-learning-databases/
資料描述
(1)699條樣本,共11列資料,第一列用語檢索的id,后9列分別是與腫瘤
相關的醫學特征,最后一串列示腫瘤型別的數值,
(2)包含16個缺失值,用”?”標出,
pandas使用
?pd.read_csv(’’,names=column_names)
?column_names:指定類別名字,[‘Sample code number’,‘Clump Thickness’, ‘Uniformity of Cell Size’,‘Uniformity of Cell Shape’,‘Marginal Adhesion’,
‘Single Epithelial Cell Size’,‘Bare Nuclei’,‘Bland Chromatin’,‘Normal Nucleoli’,‘Mitoses’,‘Class’]
?return:資料
?
?replace(to_replace=’’,value=):回傳資料
?dropna():回傳資料
良/惡性乳腺癌腫分類流程
1、網上獲取資料(工具pandas)
2、資料缺失值處理、標準化
3、LogisticRegression估計器流程
LogisticRegression總結
應用:廣告點擊率預測、電商購物搭配推薦
優點:適合需要得到一個分類概率的場景
缺點:當特征空間很大時,邏輯回歸的性能不是很好
(看硬體能力)
多分類問題
邏輯回歸解決辦法:1V1,1Vall

softmax方法-邏輯回歸在多分類問題上的推廣
將在后面的神經網路演算法中介紹
非監督學習的特點?
“物以類聚,人以群分”
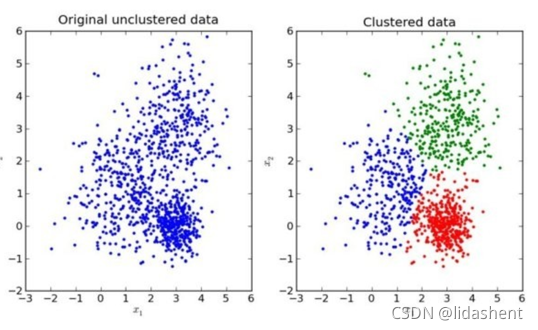
非監督學習(unsupervised learning)
主要方法:k-means
k-means步驟
1、隨機設定K個特征空間內的點作為初始的聚類中心
2、對于其他每個點計算到K個中心的距離,未知的點選擇最近的一個聚類
中心點作為標記類別
3、接著對著標記的聚類中心之后,重新計算出每個聚類的新中心點(平
均值)
4、如果計算得出的新中心點與原中心點一樣,那么結束,否則重新進行
第二步程序
k-means API
?sklearn.cluster.KMeans
Kmeans
?sklearn.cluster.KMeans(n_clusters=8,init=‘k-means++’)
?k-means聚類
?n_clusters:開始的聚類中心數量
?init:初始化方法,默認為’k-means ++’
?
?labels_:默認標記的型別,可以和真實值比較(不是值比較)
k-means對Instacart Market用戶聚類
1、降維之后的資料
2、k-means聚類
3、聚類結果顯示
Kmeans性能評估指標
輪廓系數:
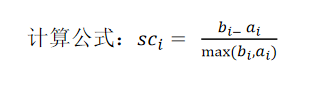
注:對于每個點i 為已聚類資料中的樣本 ,b_i 為i 到其它族群的所有樣本的平均距離,a_i 為i 到本身簇的距離平均值
最終計算出所有的樣本點的輪廓系數平均值

Kmeans性能評估指標API
?sklearn.metrics.silhouette_score
silhouette_score
?sklearn.metrics.silhouette_score(X, labels)
?計算所有樣本的平均輪廓系數
?X:特征值
?labels:被聚類標記的目標值
Kmeans總結
特點分析:
采用迭代式演算法,直觀易懂并且非常實用
缺點:容易收斂到區域最優解(多次聚類)
需要預先設定簇的數量(k-means++解決)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/313512.html
標籤:AI
下一篇:Numpysum搞砸了添加負數