1. Flume 定義
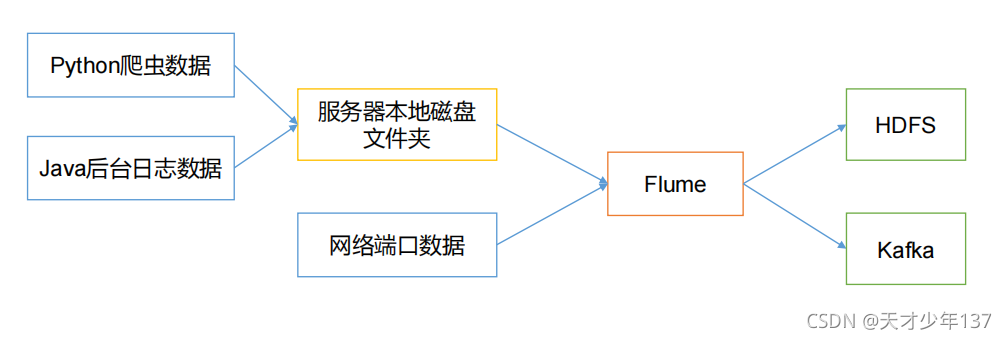
2.Flume的基礎架構
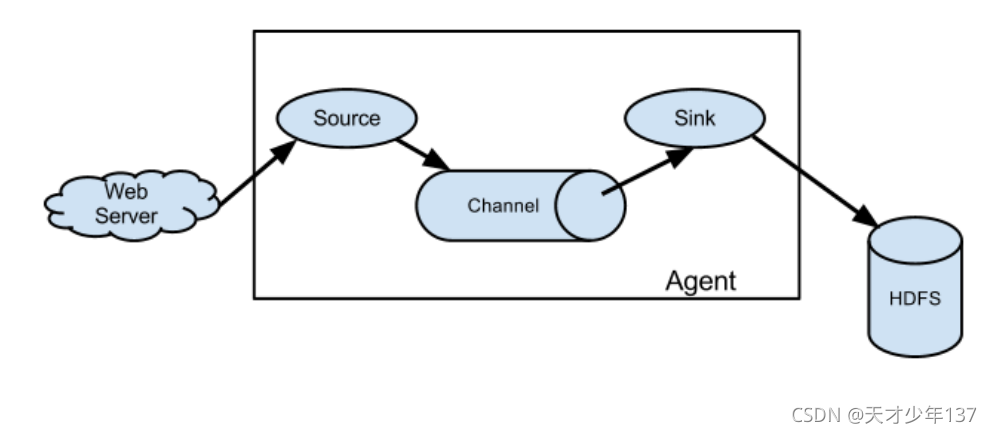
2.1 Agent
2.2 Source
2.3 Sink
2.4 Channel
2.5 Event

3.Flume監控本地檔案上傳到hdfs
說明:需要安裝hadoop配置hadoop環境變數
監控/opt/data/test.log,并且上傳到hdfs,每小時生成一個新的檔案夾,每30秒生成一個新的檔案
[atguigu@hadoop112 data]$ touch test.log
[atguigu@hadoop112 job]$ vim flume-file-hdfs.conf
添加如下內容
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
#監控檔案的路徑
a2.sources.r2.command = tail -F /opt/data/test.log
a2.sources.r2.shell = /bin/bash -c
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://hadoop112:9000/flume/%Y%m%d/%H
#上傳檔案的前綴
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照時間滾動檔案夾
a2.sinks.k2.hdfs.round = true
#多少時間單位創建一個新的檔案夾
a2.sinks.k2.hdfs.roundValue = 1
#重新定義時間單位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地時間戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#積攢多少個 Event 才 flush 到 HDFS 一次
a2.sinks.k2.hdfs.batchSize = 1000
#設定檔案型別,可支持壓縮
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一個新的檔案
a2.sinks.k2.hdfs.rollInterval = 30
#設定每個檔案的滾動大小
a2.sinks.k2.hdfs.rollSize = 134217700
#檔案的滾動與 Event 數量無關
a2.sinks.k2.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
然后進入flume安裝目錄執行下面命令
[atguigu@hadoop112 flume-1.7.0]$bin/flume-ng agent --conf conf/ --name a2 --conf-file job/flume-file-hdfs.conf新開一個終端,不斷向test.log里面追加資料查看是否監控成功
[atguigu@hadoop112 data]$ echo "你好啊,監控檔案成功" >> test.log
[atguigu@hadoop112 data]$ echo "你好啊,監控檔案成功" >> test.log
[atguigu@hadoop112 data]$ echo "你好啊,監控檔案成功" >> test.log
[atguigu@hadoop112 data]$ echo "你好啊,監控檔案成功" >> test.log
[atguigu@hadoop112 data]$ echo "你好啊,監控檔案成功" >> test.log如果如下圖所示,恭喜你案例成功
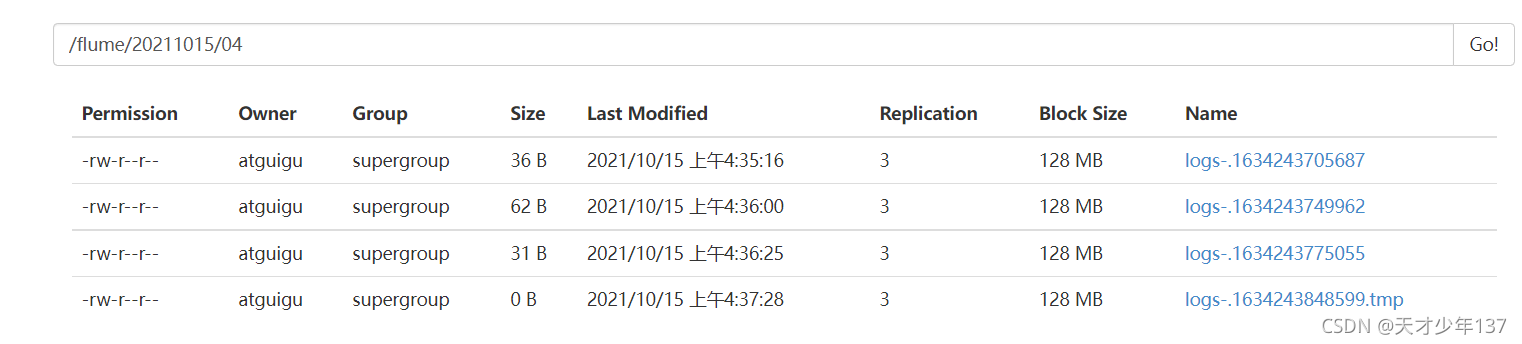
缺點:Exec source 適用于監控一個實時追加的檔案,但不能保證資料不丟失;
4.Flume監控目錄的新檔案上傳hdfs
監控/opt/data目錄,并且上傳到hdfs,每小時生成一個新的檔案夾,每30秒生成一個新的檔案
[atguigu@hadoop112 job]$ vim flume-dir-hdfs.conf
添加如下內容
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
a3.sources.r3.type = spooldir
a3.sources.r3.spoolDir = /opt/data
a3.sources.r3.fileSuffix = .COMPLETED
a3.sources.r3.fileHeader = true
#忽略所有以.tmp 結尾的檔案,不上傳
a3.sources.r3.ignorePattern = ([^ ]*\.tmp)
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://hadoop112:9000/flume/upload/%Y%m%d/%H
#上傳檔案的前綴
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照時間滾動檔案夾
a3.sinks.k3.hdfs.round = true
#多少時間單位創建一個新的檔案夾
a3.sinks.k3.hdfs.roundValue = 1
#重新定義時間單位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地時間戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#積攢多少個 Event 才 flush 到 HDFS 一次
a3.sinks.k3.hdfs.batchSize = 100
#設定檔案型別,可支持壓縮
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一個新的檔案
a3.sinks.k3.hdfs.rollInterval = 30
#設定每個檔案的滾動大小大概是 128M
a3.sinks.k3.hdfs.rollSize = 134217700
#檔案的滾動與 Event 數量無關
a3.sinks.k3.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
注:以后綴.tmp,. COMPLETED結尾的會被忽略不上傳,檔案名字不能相同
然后進入flume安裝目錄執行下面命令
[atguigu@hadoop112 flume-1.7.0]$bin/flume-ng agent --conf conf/ --name a3 --conf-file job/flume-dir-hdfs.conf新開一個終端,不斷向/opt/data里面追加檔案查看是否監控成功
[atguigu@hadoop112 data]$ touch a.txt
[atguigu@hadoop112 data]$ touch b.log
[atguigu@hadoop112 data]$ touch c.tmp
如果如下圖所示,恭喜你案例成功
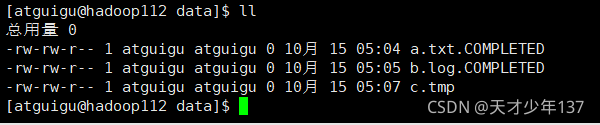
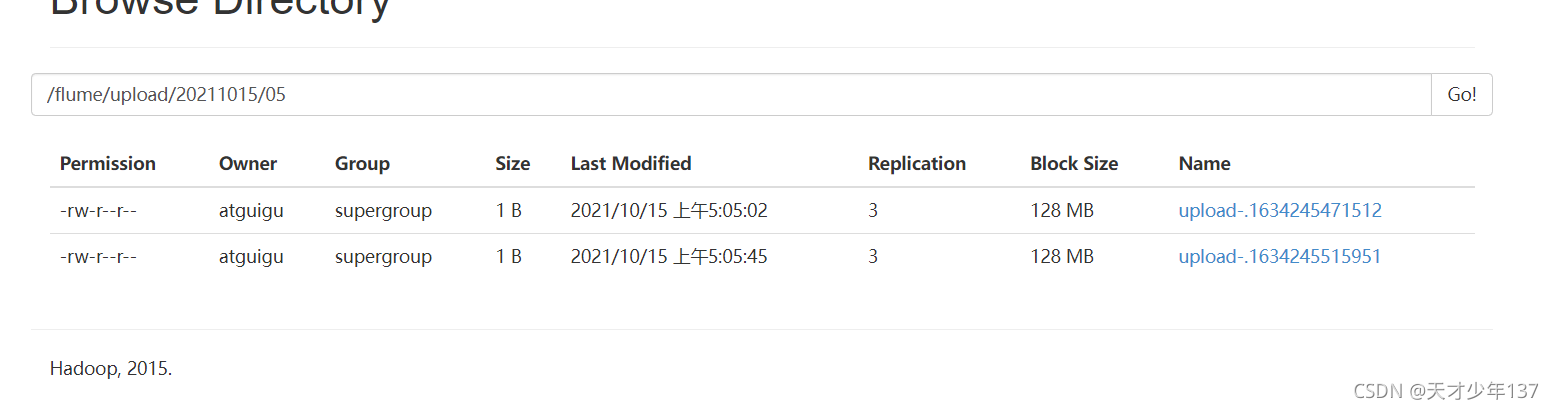
缺點:Spooldir Source 能夠保證資料不丟失,且能夠實作斷點續傳,但延遲較高,不能實時監控
5.Flume實時監控不同目錄的多個追加檔案(斷點續傳)
監控/opt/data和/data/tmpdata目錄下的檔案,并且上傳到hdfs,
創建/opt/data和/opt/tmpdata兩個目錄
# agent名字相同不能同時啟動
[atguigu@hadoop112 job]$ vim flume-taildir-hdfs.conf
添加如下內容
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
a3.sources.r3.type = TAILDIR
# 斷點續傳,保存檔案讀取資訊
a3.sources.r3.positionFile = /opt/module/flume-1.7.0/tail_dir.json
#宣告兩個檔案組
a3.sources.r3.filegroups = f1 f2
a3.sources.r3.filegroups.f1 = /opt/data/.*txt.*
a3.sources.r3.filegroups.f2 = /opt/tmpdata/.*log.*
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://hadoop112:9000/flume/upload2/%Y%m%d/%H
#上傳檔案的前綴
a3.sinks.k3.hdfs.filePrefix = upload2-
#是否按照時間滾動檔案夾
a3.sinks.k3.hdfs.round = true
#多少時間單位創建一個新的檔案夾
a3.sinks.k3.hdfs.roundValue = 1
#重新定義時間單位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地時間戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#積攢多少個 Event 才 flush 到 HDFS 一次
a3.sinks.k3.hdfs.batchSize = 100
#設定檔案型別,可支持壓縮
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一個新的檔案
a3.sinks.k3.hdfs.rollInterval = 30
#設定每個檔案的滾動大小大概是 128M
a3.sinks.k3.hdfs.rollSize = 134217700
#檔案的滾動與 Event 數量無關
a3.sinks.k3.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
注:監控/opt/data/下的*.txt ,監控/opt/tmpdata/下的*.log
然后進入flume安裝目錄執行下面命令
[atguigu@hadoop112 flume-1.7.0]$ bin/flume-ng agent -c conf/ -n a3 --conf-file job/flume-taildir-hdfs.conf新開一個終端,不斷向/opt/data里面追加檔案查看是否監控成功
[atguigu@hadoop112 data]$ touch a.txt
[atguigu@hadoop112 data]$ echo hello >> a.txt
[atguigu@hadoop112 data]$ cd /opt/tmpdata/
[atguigu@hadoop112 tmpdata]$ touch b.txt
[atguigu@hadoop112 tmpdata]$ touch b.log
[atguigu@hadoop112 tmpdata]$ echo hello >> b.log 如果如下圖所示,恭喜你案例成功
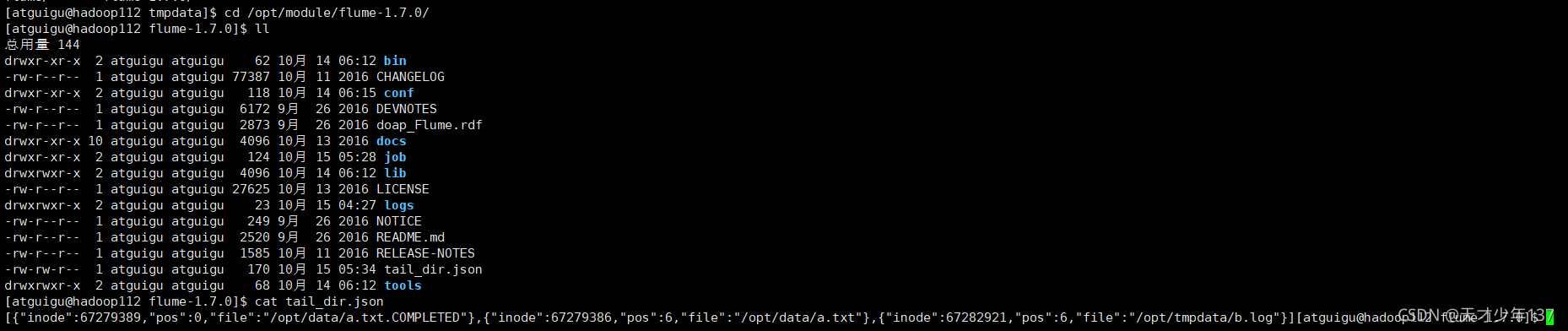

缺點:如果檔案名字改變,那么整個檔案都會重新上傳
優化:1.采用生成日志時自動帶標志,后期不會更改名字的框架,如:logback
2.修改原始碼,flume斷點續傳中,如果{"inode":67279386,"pos":6,"file":"/opt/data/a.txt"}中的inode和file有一個改變,則認為整個檔案發生改變重新上傳,所以我們可以讓inode成為為唯一一個確定整個改變因素,從而優化上述缺點
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/316436.html
標籤:其他