kafka目前與很多大資料框架比如spark、flink進行對接,另外在很多業務系統中通過存放上游日志資訊供下流拉取的作用,之前在實習的資金中臺部門中,部門的的計費系統通過拉取kafka存放applog中的計費事件,通過spark streaming的流式處理對計費事件按廣告主進行聚合,再進行接下來的實時計費的流程,
kafka在業界的使用非常廣泛,之前一直沒有深入了解其中的原理,于是目前打算寫一系列的博客來對kafka進行學習,同時也希望能夠和大家一起學習交流,
Kafka簡介
Kafka 是一個分布式的流處理平臺,它具有以下特點:
- 支持訊息的發布和訂閱,類似于 RabbitMQ、ActiveMQ 等訊息佇列,
- 支持資料實時處理,
- 能保證訊息的可靠性投遞,
- 支持訊息的持久化存盤,并通過多副本分布式的存盤方案來保證訊息的容錯,
- 高吞吐率,單 Broker 可以輕松處理數千個磁區以及每秒百萬級的訊息量,
上面都是一些概念性質的東西,其實最本質Kafka就是一個訊息中間件,類似于rocketmq,rabbitmq等,能夠起到異步、解耦、削峰的作用,
- 異步
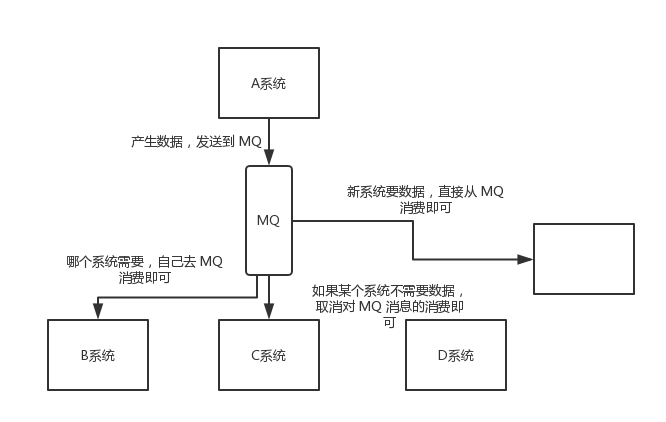
通過訊息佇列可以讓資料在多個系統更加之間進行流通,資料的產生方不需要關心誰來使用資料,只需要將資料發送到訊息佇列,資料使用方直接在訊息佇列中異步獲取資料即可,
- 解耦
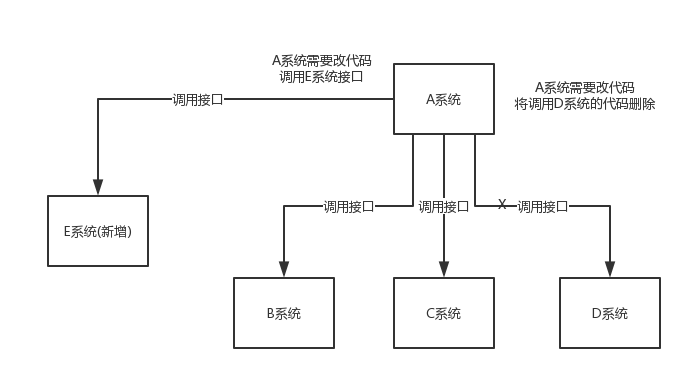
系統的耦合性越高,容錯性就越低,以電商應用為例,用戶創建訂單后,如果耦合呼叫庫存系統、物流系統、支付系統,任何一個子系統出了故障或者因為升級等原因暫時不可用,都會造成下單操作例外,影響用戶使用體驗,
使用訊息佇列解耦合,系統的耦合性就會提高了,比如物流系統發生故障,需要幾分鐘才能來修復,在這段時間內,物流系統要處理的資料被快取到訊息佇列中,用戶的下單操作正常完成,當物流系統回復后,補充處理存在訊息佇列中的訂單訊息即可,終端系統感知不到物流系統發生過幾分鐘故障,
- 削峰
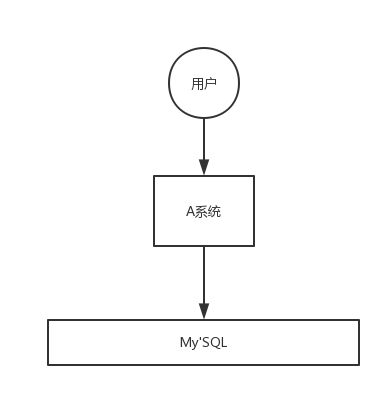
應用系統如果遇到系統請求流量的瞬間猛增,有可能會將系統壓垮,有了訊息佇列可以將大量請求快取起來,分散到很長一段時間處理,這樣可以大大提到系統的穩定性和用戶體驗,
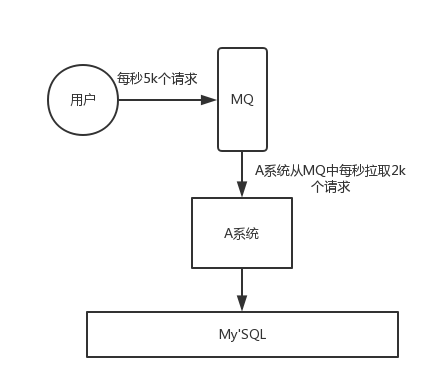
一般情況,為了保證系統的穩定性,如果系統負載超過閾值,就會阻止用戶請求,這會影響用戶體驗,而如果使用訊息佇列將請求快取起來,等待系統處理完畢后通知用戶下單完畢,這樣總不能下單體驗要好,
mac環境下Kafka的安裝與測驗
1.安裝zookeeper
因為kafka要依賴zookeeper所以我們需要提前安裝zookeeper(通過brew方式安裝)
brew install zookeeper
默認安裝位置
啟動檔案:/usr/local/Cellar/zookeeper/3.6.2/bin
組態檔: /usr/local/etc/zookeeper/
2. 啟動zookeeper 服務
nohup zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties &
這里也可以通過brew services的啟動方式brew services start zookeeper來進行啟動,
3. 安裝Kafka
brew install kafka
4. 修改Kafka服務組態檔
#進入到kafka軟體包的 config 目錄
cd /usr/local/etc/kafka
#列出當前 config 檔案下的檔案,可以看到有個 server.properties 檔案
ll
#復制 server.properties 檔案為 server-1.properties
cp server.properties server-1.properties
#復制 server.properties 檔案為 server-2.properties
cp server.properties server-2.properties
到目前為止,我們下載了 Kafka ,復制了 Kafka 組態檔,下一步需要修改這三個組態檔,使其組成集群,
下面在新的命令列終端中編輯 Kafka 的三個組態檔(server.properties、 server-1.properties、server-2.properties),修改檔案名和修改內容說明如下:
| 組態檔名稱 | 修改內容 |
|---|---|
| server.properties | 此檔案不修改,保持默認值 |
| server-1.properties | 修改 broker.id=1,log.dirs=/tmp/kafka-logs-1,新增 listeners=PLAINTEXT://:9093 三個引數值 |
| server-2.properties | 修改 broker.id=2,log.dirs=/tmp/kafka-logs-2 和 listeners=PLAINTEXT://:9094 三個引數值 |
至此,引數修改完成,下一步,啟動 Kafka 集群,上面我們看到的三個 Kafka 組態檔,每個組態檔對應 Kafka 集群中一個節點(稱為 Broker),
5. 啟動集群
依次運行如下命令,啟動 Kafka 集群:
#切換到啟動kafka命令所在目錄
cd /usr/local/Cellar/kafka/2.6.0/bin
#使用組態檔 server.properties 啟動第一個 Kafka Broker,注意:命令最后的 & 符號表示以后臺行程啟動,啟動完成后,按回車鍵,回到命令列,啟動另一個 Kafka Broker,
./kafka-server-start /usr/local/etc/kafka/server.properties &
#使用組態檔 server-1.properties 啟動第二個 Kafka Broker ,啟動完成后,按回車鍵,回到命令列,啟動另一個 Kafka Broker ,
./kafka-server-start /usr/local/etc/kafka/server-1.properties &
#使用組態檔 server-2.properties 啟動第三個 Kafka Broker,啟動完成后,按回車鍵,回到命令列,
./kafka-server-start /usr/local/etc/kafka/server-2.properties &
#查看當前運行的java行程,如下圖,出現三個 kafka 行程,說明三個 Broker 的 Kafka 集群啟動成功,
jps
到目前為止,單機版三個 Broker 的 Kafka 集群已經安裝成功,
我們簡要說一下Kafka中有關訊息的整體流程,生產者生產訊息,將訊息發送到 Kafka 服務器(實際上訊息存盤到了 Kafka 中的 Topic 里面),消費者消費訊息,從 Kafka 服務器讀取訊息,這里的 Kafka 服務器相當于一個中間人,用于存盤生產者和消費者互動的資料(訊息),下一步我們要在 Kafka 集群上創建一個 Topic ,用于存盤訊息,創建一個訊息生產者,向 Topic 發送訊息,創建一個訊息消費者,從 Topic 讀取訊息,
6. 在集群中創建Topic進行測驗
使用 Shell 命令在 Kafka 集群中創建一個 Topic ,名稱為 myFirstTopic,
在 /opt/kafka/bin 目錄下運行命令創建一個名為 myFirstTopic 的 Topic,
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic myFirstTopic

在 /usr/local/Cellar/kafka/2.6.0/bin 目錄下運行命令,查看 Topic 創建是否成功:
./kafka-topics --zookeeper localhost:2181 --list
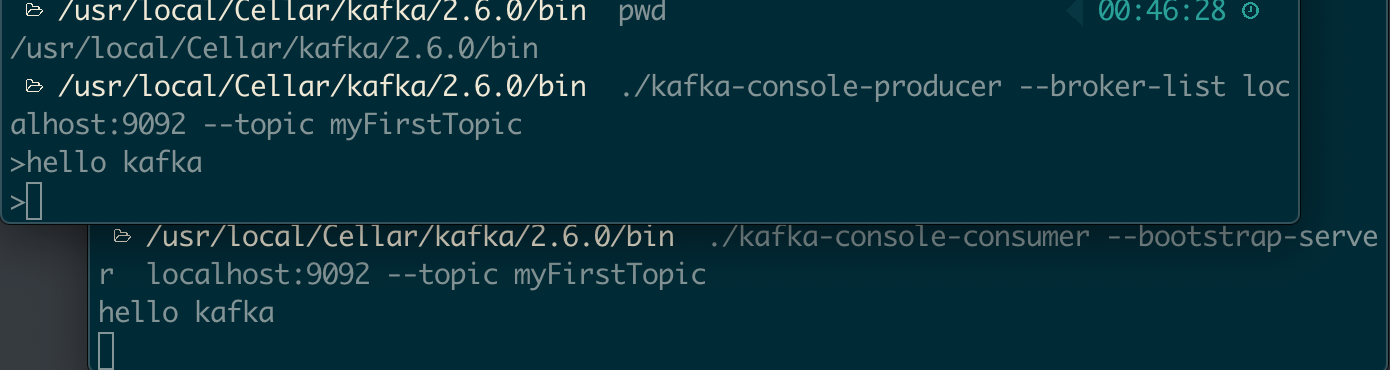
在 /usr/local/Cellar/kafka/2.6.0/bin 目錄下運行命令,啟動訊息生產者,用于向 Topic 發送訊息:
./kafka-console-producer --broker-list localhost:9092 --topic myFirstTopic
重新打開一個新的命令列終端,啟動訊息消費者,用于從 Topic 中讀取訊息:
./kafka-console-consumer --bootstrap-server localhost:9092 --topic myFirstTopic
在訊息生產者所在命令列終端中輸入 hello kafka ,然后按回車鍵,訊息發送到 Topic ,此時在訊息消費者所在的命令列中,可以看到 hello kafka 訊息已經收到了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/316445.html
標籤:其他
下一篇:「大資料成神之路」第三版更新完畢