
圖文混排在帶屏UI場景里,尤其是一些偏運營的動態UI場景里,是非常常用的一個功能,擬在通過圖文混排向用戶展示更加豐富、更加具體、更加有吸引力的UI界面,在Web技術領域,瀏覽器是天然支持圖文行內混排能力的,而在一些中低端的IoT帶屏設備上,瀏覽器是一個非常奢侈的技術,很難在中低端設備上運行完整的瀏覽器程式,所以在這里想要研究下在已有GUI或者圖形系統的IoT帶屏設備上,實作一個圖文行內混排的富文本(小型HTML引擎)的技術方案的探討,

1、Web上的圖文行內
首先看下,圖文行內在Web瀏覽器上的一個效果和寫法,先看效果:

看以上效果,行內有圖片,以及多種樣式文字的布局效果,而這樣的復雜布局的UI效果在瀏覽器中可以用HTML檔案非常簡單的搭建出來:
<span style="font-size:24px;line-height: 26px;color:black;">
<img style="height:24px;" src="./a.png"/>2、HTML與XHTML
HTML的全稱為超文本標記語言,是一種標記語言,是英文HyperText Markup Language的簡稱,它包括一系列標簽.通過這些標簽可以將網路上的檔案格式統一,使分散的Internet資源連接為一個邏輯整體,它是一種松散約束的規范,
XHTML的全稱是可擴展超文本標記語言,英文全稱Extensible HyperText Markup Language,表現方式與超文本標記語言(HTML)類似,不過語法上更加嚴格,從繼承關系上講,XHTML則基于可擴展標記語言(XML),XHTML是一種增強了的HTML,XHTML 是更嚴謹更純凈的 HTML 版本,它的可擴展性和靈活性將適應未來網路應用更多的需求,
從HTML到XHTML過渡的變化比較小,主要是為了適應XML,最大的變化在于檔案必須是良構的,所有標簽必須閉合,也就是說開始標簽要有相應的結束標簽,另外,XHTML中所有的標簽必須小寫,而按照HTML 2.0以來的傳統,很多人都是將標簽大寫,這點兩者的差異顯著,在XHTML中,所有的引數值,包括數字,必須用雙引號括起來(而在SGML和HTML中,引號不是必須的,當內容只是數字、字母及其它允許的特殊字符時,可以不用引號),所有元素,包括空元素,比如img、br等,也都必須閉合,實作的方式是在開始標簽末尾加入斜扛,比如<img … /> 、<br />,省略引數,比如<option selected>,也不允許,必須用<option selected="selected"/>,兩者的詳細差別,可通過W3C XHTML說明來查閱,
HTML的松散約束,意味著程式需要更加復雜的功能和演算法去兼容各種不嚴格的寫法,也意味著更多的資源損耗,而采用基于XML的嚴格約束的XHTML,會使得程式更簡單,專注在處理檔案的核心功能上,所以,這里我們主要基于XML格式的檔案來探討IoT場景的富文本引擎,
3、富文本引擎
本文目標只為探討富文本引擎本身的核心能力,不展開GUI和圖形引擎,所以這里的基本前提是,系統已經具備了有一個較強能力的GUI或者圖形引擎,如QT或者Skia等,
首先,對于Web領域而言,有三大最基礎的核心能力,HTML、CSS以及JS,在這里,不考慮JS動態腳本能力,專注在HTML(傾向于XML)、以及CSS,并且CSS也只考慮行內樣式(直接在標簽內部引入),不考慮頁級CSS和外聯CSS,
就像上面那段國慶季的HTML檔案,就是這類遵循XML,并且只有行內樣式表以及Inline布局的一個檔案結構,這里就是要探索將這樣一個檔案通過一個小型的HTML引擎決議并且排版出來,
3.1、HTML決議
構建富文本引擎的首要步驟,就是需要決議HTML檔案,生成特定的資料結構,在這里稱之為dom樹,一個HTML檔案,可以對應一個樹狀結構的節點樹,所以首先要定義一個dom節點的資料結構,可以類似以下結構來設計:
class HtmlNode
{
protected:
// 節點型別,span、text、br等
std::string type;
// 樣式表
std::map< std::string, std::string > styles;
// 屬性表
std::map< std::string, std::string > attrs;
// 普通樣式(margin、background-color等)
NormalStyle normalStyle;
// 可繼承樣式(font-size、color等)
InheritedStyle inheritedStyle;
// 父節點
HtmlNode* parent;
// 子節點
std::vector<HtmlNode*> children;
}
可以通過以上的資料結構來存盤HTML檔案決議出來的dom節點樹,并派生出SpanNode、ImageNode、BRNode以及Document類(通過span、image和br就可以排出豐富的富文本效果了,其中span為inline布局,image為inline-block布局),來處理不同節點型別的功能邏輯,
另外,上面以及說過可以采用XHTML來約束HTML的松散規范,而XHTML是基于XML格式的標記語言,所以可以使用一些開源的XML決議庫,直接幫助我們來決議HTML檔案,如tinyxml或者expat等,可以選擇最適合自己應用場景的,
最終,HTML檔案會被決議成類似以下的節點樹:
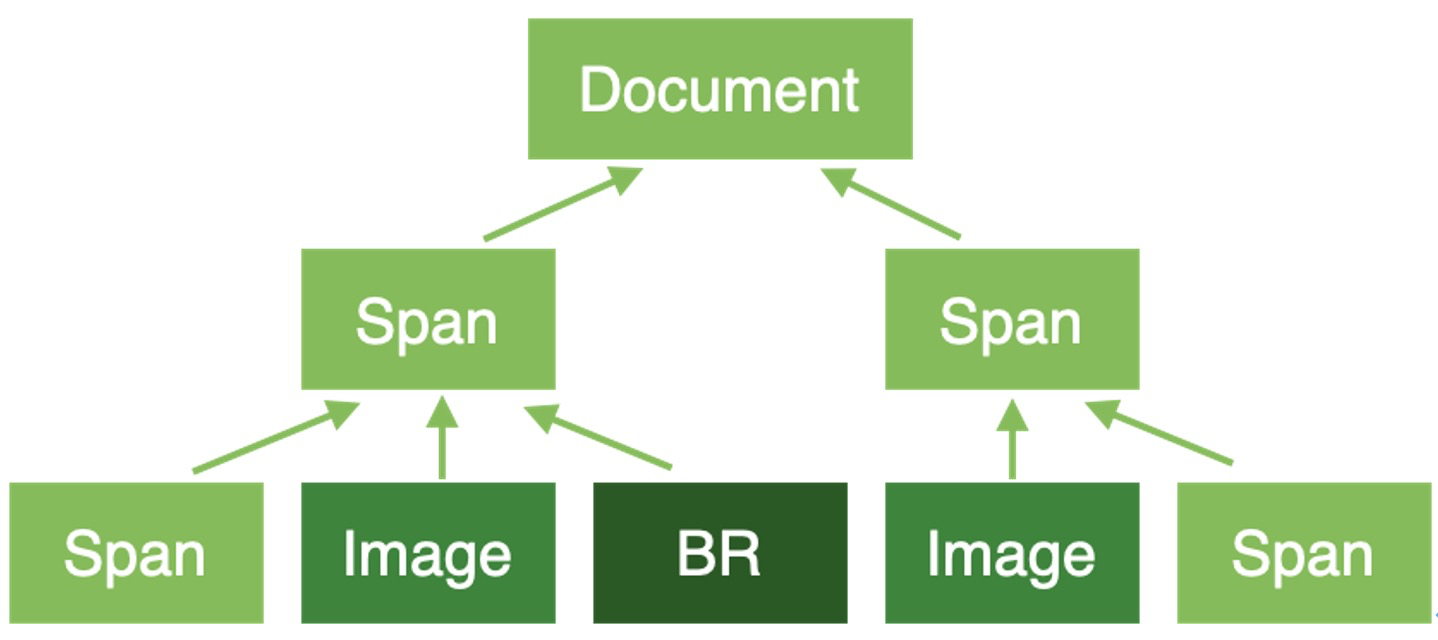
3.2、樣式處理
HTML決議完成之后,還需要對節點樣式進行決議處理,在瀏覽器里,樣式表有多重形態,包括1、行內樣式,定義在節點的style屬性上的樣式資訊;2、頁級樣式,定義在HTML的head中的樣式;3、外聯樣式,通過link方式引入的外部CSS檔案,
這里先只考慮行內樣式,也就是定義在節點的style屬性里的值,在決議dom樹的同時,可以同步將style屬性決議為字典型別的樣式表保存起來,決議規則也比較簡單,就是按照分號分割樣式,再通過冒號分離key-value,
另外,在CSS樣式中,有部分樣式是支持繼承的,也就是子節點會自動繼承父節點的部分樣式資訊,除非子節點自己定義了該樣式,所以在HtmlNode類里面,宣告了兩種樣式表,NormalStyle和InheritedStyle:
// 暫時支持決議以下樣式
struct NormalStyle
{
uint32_t bgColor; // background-color 背景色
float marginLeft; // margin-left
float marginTop; // margin-top
float marginRight; // margin-right
float marginBottom; // margin-bottom
float width; // width 寬度(img節點inline-block使用)
float height; // height 高度(img節點inline-block使用)
}
struct InheritedStyle
{
uint32_t color; // color 顏色
std::string fontFamily; // font-family 字體
float fontSize; // font-size 字號
bool italic; // font-style 斜體
bool bold; // font-weight 先只支持加粗和普通字重
int32_t lineHeight; // line-height 行高
int32_t textDecoration; // text-decoration 1:underline, 2:line-through, 0:none
}
對于普通樣式,處理邏輯比較簡單,也就是遍歷所有節點,然后決議自己的樣式資訊即可;而對于可繼承的樣式,需要先從根節點開始決議樣式,然后子節點先復制父節點的InheritedStyle,再決議自己的樣式:
void HtmlNode::parse()
{
// 1、初始化可繼承樣式表
if (parent != NULL) {
inheritedStyle = parent->inheritedStyle;
} else {
// 根組件設定默認樣式
memset(&inheritedStyle, 0, sizeof(InheritedStyle));
inheritedStyle.color = 0xFF000000;
inheritedStyle.fontSize = 24;
}
// 2、決議樣式
parseStyle();
// 3、決議子組件樣式
if (!children.empty()) {
for (std::vector< HtmlNode* >::iterator it = children.begin(); it != children.end(); it++) {
(*it)->parse();
}
}
}
這樣經過HTML決議以及樣式處理之后,帶有樣式資訊的dom樹就已經搭建起來了,接下來就需要為該dom樹進行布局計算了,
3.3、Inline布局
布局計算的目的就是將上述的dom節點樹,進行一系列的測量和布局,確定每個元素所處的位置以及所占大小,在Web瀏覽器里,主要的排版模式是按行來布局,所以可以布局出行內圖文混排的UI效果,所以這里也考慮使用行布局來設計,
首先先簡單看一下,在瀏覽器里面,節點元素是分為幾種型別的,inline元素、inline-block元素以及block元素,這幾種型別的主要差別為:
inline
- 使元素變成行內元素,擁有行內元素的特性,即可以與其他行內元素共享一行,不會獨占一行.
- 不能更改元素的height,width的值,大小由內容撐開.
- 可以使用padding,margin的left和right產生邊距效果,但是top和bottom就不行.
block
- 使元素變成塊級元素,獨占一行,在不設定自己的寬度的情況下,塊級元素會默認填滿父級元素的寬度.
- 能夠改變元素的height,width的值.
- 可以設定padding,margin的各個屬性值,top,left,bottom,right都能夠產生邊距效果.
inline-block
- 結合了inline與block的一些特點,結合了上述inline的第1個特點和block的第2,3個特點.
- 用通俗的話講,就是不獨占一行的塊級元素,
常用的inline元素有:span, i, b, label, a等;
常用的block元素有:div,ul,li,dl,p,h等;
inline-block元素有img,
目前,暫時只考慮span、img等幾個標簽,所以只需要考慮inline布局和inline-block布局,
最終布局計算的目標如下圖所示:
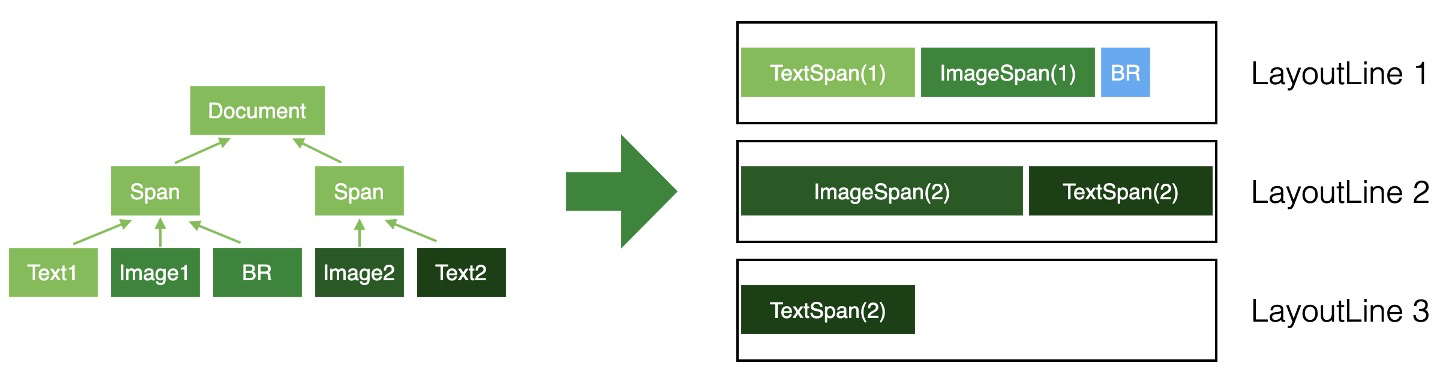
將左邊的dom節點樹,經過布局計算,最終生成右邊的多行的結果,它的基本演算法邏輯可以概括為:1、開始布局,創建新行;2、遍歷節點樹,添加布局元素到當前行;3、當前行滿了,添加新行,重復步驟2和3,
當然,其中的文本測量布局計算需要對接到基礎GUI系統或者圖形系統中,
LayoutContext::LayoutStep HtmlNode::layout(LayoutContext *context)
{
LayoutLine* line = NULL;
if (isBlock()) {
// 如果為block元素,先添加新行,再在新行進行布局計算
line = context->appendNewLine();
} else {
// 非block元素,在當前行進行布局計算
line = context->currentLine();
}
if (line == NULL) {
// 布局結束
return LayoutContext::STOP;
}
// 進行真正的布局計算,不同型別的節點可繼承后處理自己的布局計算邏輯
LayoutContext::LayoutStep step = onLayout(context, line);
if (step == LayoutContext::STOP) {
return step;
}
// 布局子節點
for (std::vector< HtmlNode* >::iterator it = children.begin(); it != children.end(); it++) {
HtmlNode* child = *it;
if (child->layout(context) == LayoutContext::STOP) {
return LayoutContext::STOP;
}
}
return LayoutContext::CONTINUE;
}
// img元素布局邏輯
LayoutContext::LayoutStep ImageNode::onLayout(LayoutContext *context, LayoutLine *line)
{
if (width > 0 || height > 0) {
float remainWidth = line->remainWidth();
float maxWidth = context->getMaxWidth();
if (width <= remainWidth) {
// 當前行還有空余大小,直接添加到當前行
ImageItem* item = new ImageItem(image, width, height);
line->appendItem(item);
} else {
// 當前行空余大小不夠,創建新行再進行布局
line = context->appendNewLine();
if (line == NULL) {
return LayoutContext::STOP;
}
ImageItem* item = new ImageItem(image, width, height);
line->appendItem(item);
}
}
return LayoutContext::CONTINUE;
}
// span文本元素布局邏輯,偽代碼如下
LayoutContext::LayoutStep SpanNode::onLayout(LayoutContext *context, LayoutLine *line)
{
// 通過樣式設定文本測量環境(需要對接到基礎GUI或者圖形系統上)
int32_t index = 0;
while (index < 文本長度) {
int32_t measuredCount = 0;
float measuredWidth = 0.f;
float remainWidth = line->remainWidth();
呼叫文本測量&斷行
if (remainWidth >= measuredWidth) {
1、添加TextSpan到當前line
2、index += measuredCount;
3、remainWidth -= measuredWidth;
} else {
// 添加新行
line = context->appendNewLine();
1、添加TextSpan到當前line
2、index += measuredCount;
3、remainWidth -= measuredWidth;
}
}
return LayoutContext::CONTINUE;
}
經過以上布局計算,就可以得到布局后的行元素,再對接到GUI或圖形系統的繪制體系中,就可以得到富文本的UI顯示效果了,因為這里沒有涉及具體的GUI或者圖形系統,所以暫時不展開說了,
3.4、效果示例

結語
本文主要內容是在IoT帶屏場景中,探討一個輕量的、小型的HTML引擎的設計思路,僅涉及一些基本的、偏靜態HTML的展示,在很多資源受限的IoT設備上,如果有顯示富文本形態的UI場景需求,因為大型的瀏覽器并不適合運行在這類設備上,一個輕量的小型引擎就會非常重要了,
這里富文本引擎通過HTML決議、CSS樣式處理、以及最重要的輕量Inline布局功能來支撐圖文混排的排版能力,另外如果需要支持div等block布局的功能,還需要再增強一下該layout功能,
通過本文分享這邊的設計思路,希望對大家有所幫助,
開發者支持
如需更多技術支持,可加入釘釘開發者群,或者關注微信公眾號,

更多技術與解決方案介紹,請訪問HaaS官方網站https://haas.iot.aliyun.com,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/317660.html
標籤:其他
上一篇:樹莓派計算模塊CM4搭建軟路由OpenWrt+OpenClash程序記錄
下一篇:基于ESP8266 HX711 克級單位稱重式壓力傳感器(接入阿里云物聯網平臺)—— 看到有點意思,所以我也照著做了一個