大家好啊!這次的文章是上一個文章的后續,與上一次不同的是,這一次對數字識別采用的是貝葉斯(Bayes)分類器,貝葉斯在概率論與數理統計這門課講過,下面我們簡單了解一下:
首先,貝葉斯公式是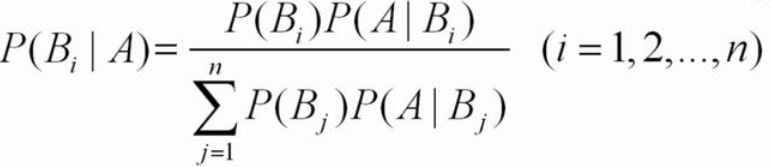
具體的解釋就不說了,我們說一說把貝葉斯用在數字識別的什么位置,除了識別部分,其他的包括遍歷檔案夾和圖片數字化都不變;0到9共十個數,所以分母有十項,P(Bj)(j是下標)相應的是0到9,則每一個的概率是1/10,分子上的P(Bi)是取到0到9中的一個,所以概率也是1/10,(小伙伴如果看不明白建議去看看貝葉斯)所以我們分母可以提出來并約分,然后式子Pi/(P1+P2+P3+P4+P5+P6+P7+P8+P9)(Pi就是P(A|Bi),其他的就是i分別取值),變成這樣后,i取0——9的某個數就是測驗樣本是這個數的概率,比如:i=0,表示測驗用例是0的概率為P1/(P1+P2+P3+P4+P5+P6+P7+P8+P9+P10)(1就是對應數字0),
那么我們該如何找到Pin呢,我們是通過統計樣本每一位為1的概率,這樣說可能不太清楚,也就是假如一張0的圖片的資料化字串為0000000000100000111000010010001010000111000000000(49位),我們一位一位的去統計每一位為1的個數(如下圖,也就是縱向的統計每個樣本的第某位為1的個數),最后除以總數,我的訓練庫一個數字的樣本有100張,假如我們統計到數字0的所有樣本的第一位數字為1的個數為46個,那么數字0的第一位為1的概率為0.46,其他位也是依次統計,其他數字同上,

最終我們可以統計到每個數字的每一位為1的概率形成一個10*49的二維陣列,即10個數字,每個數字49位,然后我們取一個測驗用例,依次與10個數字進行計算概率,最后得到的概率比較大小,那么我們如何去計算測驗用例是某個數字的概率呢?下面我們把49位簡單的看成3位,假如數字0的第一、二、三位為1的概率是0.56、0.05、0.41,而測驗用例的資料字串為101,那么我們取為1的概率直接乘,為0的用1減去這個概率,再乘起來,也就是0.56*0.95*0.41,到這里就差不多使我們的所有思路了,(其他的思路解釋看上次的文章,鏈接放下面)c++基于模板匹配的手寫數字識別(超詳細)_m0_57587079的博客-CSDN博客
下面是我的代碼,首先opencv得自己安裝,這里我給一個鏈接,可以參照上面博主的步驟來
windows下OpenCV安裝教程(小白教程)_HikD_bn的博客-CSDN博客
另外,我的Bayes這個函式太長了,應該分成幾個函式的,這樣會更好除錯和閱讀
詳細的代碼解釋都在注釋里,仔細的看看理解就好了,如果有更好的方法和思路,歡迎交流學習!
#include<iostream>
#include<fstream>
#include<opencv2/opencv.hpp>
#include<opencv2/highgui.hpp>
#include<opencv2/core.hpp>
#include<io.h> //api和結構體
#include<string.h>
#include<string>
#include<sstream> //string 轉 int 資料型別包含
using namespace std;
using namespace cv;
void ergodicTest(string filename, string name); //遍歷函式
string Image_Compression(string imgpath); //壓縮圖片并回傳字串
void Bayes(); //貝葉斯分類器
int turn(char a);
void main()
{
const char* filepath = "E:\\learn\\vsfile\\c++project\\pictureData\\train-images";
ergodicTest(filepath, "train_num.txt"); //處理訓練集
const char* test_path = "E:\\learn\\vsfile\\c++project\\pictureData\\test-images";
ergodicTest(test_path, "test_num.txt");
Bayes();
}
void ergodicTest(string filename, string name) //遍歷并把路徑存到files
{
string firstfilename = filename + "\\*.bmp";
struct _finddata_t fileinfo;
intptr_t handle; //不能用long,因為精度問題會導致訪問沖突,longlong也可
string rout = "E:\\learn\\vsfile\\c++project\\pictureData\\" + name;
ofstream file;
file.open(rout, ios::out);
handle = _findfirst(firstfilename.c_str(), &fileinfo);
if (_findfirst(firstfilename.c_str(), &fileinfo) != -1)
{
do
{
file << fileinfo.name<<":"<< Image_Compression(filename + "\\" + fileinfo.name) << endl;
} while (!_findnext(handle, &fileinfo));
file.close();
_findclose(handle);
}
}
string Image_Compression(string imgpath) //輸入圖片地址回傳圖片二值像素字符
{
Mat Image = imread(imgpath); //輸入的圖片
cvtColor(Image, Image, COLOR_BGR2GRAY);
int Matrix[28][28]; //將digitization轉化為字串型別
for (int row = 0; row < Image.rows; row++) //把圖片的像素點傳給陣列
for (int col = 0; col < Image.cols; col++)
{
Matrix[row][col] = Image.at<uchar>(row, col);
}
string img_str = ""; //用來存盤結果字串
int x = 0, y = 0;
for (int k = 1; k < 50; k++)
{
int total = 0;
for (int q = 0; q < 4; q++)
for (int p = 0; p < 4; p++)
if (Matrix[x + q][y + p] > 127) total += 1;
y = (y + 4) % 28;
if (total >= 6) img_str += '1'; //將28*28的圖片轉化為7*7即壓縮
else img_str += '0';
if (k % 7 == 0)
{
x += 4;
y = 0;
}
}
return img_str;
}
int turn(char a) //這個函式是把string型別轉換成int型別
{
stringstream str;
int f = 1;
str << a;
str >> f;
str.clear();
return f;
}
void Bayes()
{
ifstream data_test, data_train; //從兩個資料字串檔案中取資料的檔案流
string temp; //中間暫存字串的變數
double count[10] = { 0 }; //用來計數每個數字樣本1個數
double probability[10][49] = { 0 };
int t = 0; //避免算數溢位
for (int i = 0; i < 49; i++) //按列處理訓練樣本(每一個樣本資料長度位49位)
{
data_train.open("E:\\learn\\vsfile\\c++project\\pictureData\\train_num.txt");
for (int j = 0; j < 1000; j++) //按順序取一千次資料
{
getline(data_train, temp); //順序取每一行資料
if (temp.length() == 57) //本來長度是49,因為我有檔案名所以要跳過檔案名
{
t = i + 8; //用t來代替i+8是因為string的[]中沒有+-多載,好像是這樣
if (turn(temp[t]) == 1) count[turn(temp[0])]++; //相應數字為1計數加1
else continue;
}
else if(temp.length() == 58)
{
t = i + 9; //有的檔案名為8位有的為9位
if (turn(temp[t]) == 1) count[turn(temp[0])]++; //相應數字
else continue;
}
}
data_train.close(); //一定要注意檔案流打開和關閉的時機,打開和關閉一次之間是一次完整的遍歷(getline)
for (int q = 0; q < 10; q++)
{
probability[q][i] =count[q] / 100.0; //計算每個數字資料樣本的每一位1的概率
count[q] = 0;//回圈還要使用count,所以要初始化
}
}
double probab[10] = { 1,1,1,1,1,1,1,1,1,1 }; //該陣列是這個數字的概率(10個數字)
data_test.open("E:\\learn\\vsfile\\c++project\\pictureData\\test_num.txt");
double temp_prob = 0; //對比可能性的中間變數:概率
int temp_num = -1; //對比可能性的中間變數:數字
bool flag = true; //標志拒絕識別,假就拒絕
int num_r = 0, num_f = 0, num_t = 0; //分別表示拒絕,錯誤,正確
for (int d = 0; d < 200; d++) //200個測驗樣本
{
for (int o = 0; o < 10; o++) probab[o] = 1;//初始化概率陣列,雖然前面有初始化,但是我們回圈會多次使用,所以我們要每回圈一次初始化一次
getline(data_test, temp);
for (int y = 0; y < 10; y++) //分別和每個數字得出一個概率,既該測驗用例是這個數字的概率
{
for (int s = 0; s < 49; s++) //49位對應去累乘得到概率
{
if (temp.length() == 57)
{
t = s + 8;
if (turn(temp[t]) == 1) probab[y] *=1+probability[y][s]; //加1是因為零點幾越乘越小,不好比較,而且有的概率可能為0,
else probab[y] *= 2 - probability[y][s]; //同樣的,為0的概率也要加上1
}
else
{
t = s + 9;
if (turn(temp[t]) == 1) probab[y] *=1+probability[y][s]; //相應數字
else probab[y] *= (2 - probability[y][s]);
}
}
}
flag = true; //標志置位真
temp_prob = 0; //重置中間變數
temp_num = -1; //開始前不標識為任何數值
for (int l = 0; l < 10; l++) //比較測驗用例是某個數字的概率,確定最大的那個
{
if (probab[l] > temp_prob)
{
temp_prob = probab[l];
temp_num = l;
flag = true; //不被拒絕
}
else if (probab[l] == temp_prob )
{
flag = false; //拒絕識別
}
}
if (!flag)
{
num_r++;
}
else
{
cout << temp[0] << " " << temp_num << endl;
if (temp_num == turn(temp[0]))
{
cout << "識別為:" << temp_num << endl;
num_t++;
}
else
{
cout << "識別錯誤!" << endl;
num_f++;
}
}
}
data_test.close();
cout << "拒絕識別率為:" << num_r / 200.0 << endl;
cout << "正確識別率為:" << num_t / 200.0 << endl;
cout << "錯誤識別率為:" << num_f / 200.0 << endl;
}注意,我的代碼用的樣本圖片都是處理好的二值bmp圖片,另外代碼里的txt檔案需要手動建,伙伴們可以自行修改,添加創建文本的陳述句,
每日一遍:好好學習,天天向上!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/317714.html
標籤:其他