關注公眾號,發現CV技術之美
本文分享 ICCV 2021 oral 論文『A Hybrid Video Anomaly Detection Framework via Memory-Augmented Flow Reconstruction and Flow-Guided Frame Prediction』,由華工&京東&中大聯合設計重構+預測方法,雙管齊下提升視頻例外檢測性能,
詳細資訊如下:

論文鏈接:https://arxiv.org/abs/2108.06852
專案鏈接:https://github.com/LiUzHiAn/hf2vad
01
動機
視頻例外檢測(Video Anomaly Detection,VAD)是一項具有開放特征且具有挑戰性的任務,因為例外事件通常要比正常事件發生的少,但是在實際場景中,例外事件的型別是不可預知的,現有針對視頻例外檢測任務的方法大多以自動編碼器為基干模型,這類方法往往使用同一場景中所有的正常事件訓練自動編碼器,在模型測驗階段,對于例外事件,模型會給出較大的重構誤差,以該誤差作為標準來判斷當前輸入是否包含例外事件,
本文方法也是遵循以上設定,在普通自動編碼器的基礎上進行改進,加入了一系列的記憶模塊來對正常事件進行建模,同時整合幀預測任務和光流重建任務,本文的一個亮點是,以重構的光流作為條件,設計了一個條件變分自動編碼器(Conditional Variational Autoencoder,CVAE),用來捕獲視頻幀與光流場之間的相關性,并以此相關性來影響幀預測的質量,當模型遇到例外事件時,光流重建帶來的誤差會進一步影響幀預測的效果,使例外事件更易于檢測,
下圖展示了本文方法在CUHK Avenue資料集上的檢測效果,其中藍色框線代表例外事件的ground truth,前兩行分別為單獨光流重建任務和幀預測任務的檢測效果,最后一行為本文集成方法的效果,
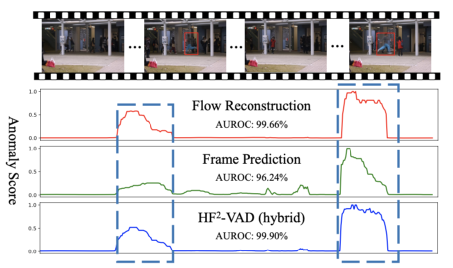
02
方法
下圖為本文整體的框架圖,整體框架主要由兩部分構成:多級記憶增強自動編碼器和條件變分自動編碼器,整個框架只使用正常資料進行訓練,在測驗階段,根據重構得到的光流和預測得到的幀計算誤差來判斷例外情況,
模型首先輸入一系列的光流序列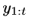 ,經過多級記憶增強自動編碼器得到重構的光流序列
,經過多級記憶增強自動編碼器得到重構的光流序列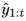 ,隨后將相同時間的視頻幀序列
,隨后將相同時間的視頻幀序列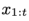 和上一步重構的
和上一步重構的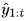 一起輸入到條件變分自動編碼器進行未來幀的預測,當遇到例外事件時,首先重構得到的光流序列就會有較大的重構誤差,并以此為條件進行下一步的幀預測,會進一步增大預測的誤差,以此來提高檢測性能,
一起輸入到條件變分自動編碼器進行未來幀的預測,當遇到例外事件時,首先重構得到的光流序列就會有較大的重構誤差,并以此為條件進行下一步的幀預測,會進一步增大預測的誤差,以此來提高檢測性能,
2.1 多級記憶增強自動編碼器
本文提出的多級記憶增強自動編碼器是在ICCV2019提出的MemAE[1]和CVPR2020提出的MNAD[2]基礎上進行改進,本文作者發現僅使用單個記憶模塊難以建模和記憶所有的正常模式(normal patterns),但是如果暴力的增加的記憶模塊的數量,會帶來過度的資訊過濾,使網路的性能退化以記住最具代表性的正常模式,而忽略了其他表象不明顯的正常模式,
為了解決該問題,本文加入了多級跳連(Skip Connections)將編碼資訊直接傳遞給解碼器,為不同層次的記憶模塊提供資訊來發現更多的正常模式,下圖為上述三種記憶增強自動編碼器的示意圖,

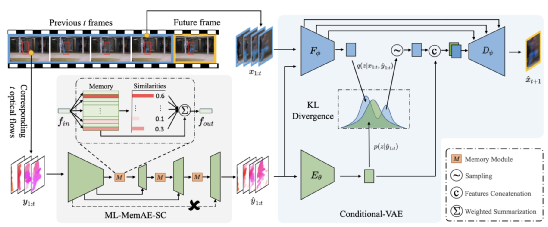
對于上圖中的每個記憶模塊
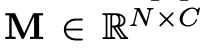
,本質上就是一個存盤矩陣,矩陣的每一行表示一種記憶模式,對于輸入的編碼向量,記憶模塊的操作是通過在整個記憶矩陣中查詢相似的記憶模式,并以加權求和的方式來得到記憶增強向量,進行隨后的重構任務,
多級記憶增強自動編碼器通過重構損失和交叉熵損失聯合優化,其中重構損失如下:
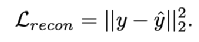
本文同時仿照MemAE中對每個記憶模塊施加匹配概率以計算交叉熵損失:
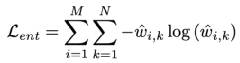
其中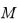 為記憶模塊中存盤的記憶模式的總數,
為記憶模塊中存盤的記憶模式的總數,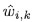 為匹配概率,即為對編碼特征進行記憶增強時的加權權重,整體優化目標由上述兩項聯合得到:
為匹配概率,即為對編碼特征進行記憶增強時的加權權重,整體優化目標由上述兩項聯合得到:
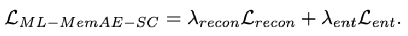
2.2 條件變分自動編碼器
本文提出的條件變分自動編碼器基于這樣的觀察:對于連續的兩個視頻幀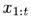 和
和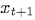 ,由于時間跨度小,所以兩幀的影像內容基本沒有差異,基于變分推斷理論,可以假設這兩幀基于相同的隱變數(hidden variables),根據變分生成模型可以將相同時刻的光流
,由于時間跨度小,所以兩幀的影像內容基本沒有差異,基于變分推斷理論,可以假設這兩幀基于相同的隱變數(hidden variables),根據變分生成模型可以將相同時刻的光流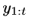 作為條件,對下一幀
作為條件,對下一幀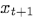 進行生成,運算式為
進行生成,運算式為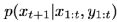 ,
,
如上圖右側所示,本文提出的條件變分自動編碼器包含了兩個編碼器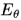 ,
,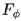 和一個解碼器
和一個解碼器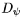 ,其中
,其中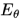 對光流輸入編碼得到基于先驗分布
對光流輸入編碼得到基于先驗分布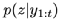 的光流特征,
的光流特征,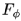 首先對光流輸入 和視頻幀輸入進行拼接,隨后編碼得到基于后驗分布
首先對光流輸入 和視頻幀輸入進行拼接,隨后編碼得到基于后驗分布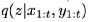 的混合特征,再拼接隱變數作為噪聲,輸入到解碼器
的混合特征,再拼接隱變數作為噪聲,輸入到解碼器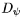 生成下一幀的預測
生成下一幀的預測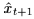 ,這樣就完成了整個流程,作者假設以上分布的引數都遵循高斯分布,可以由最小化KL散度進行編碼器的優化:
,這樣就完成了整個流程,作者假設以上分布的引數都遵循高斯分布,可以由最小化KL散度進行編碼器的優化:
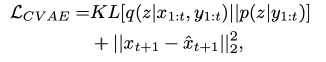
此外為了防止生成的視頻幀出現模糊的情況,本文仿照之前的方法加入了梯度損失來保證生成影像的銳度:
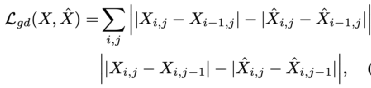
整體優化模板由以上兩項聯合得到:
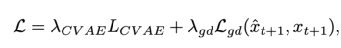
03
實驗效果
本文在三個具有代表性的視頻例外資料集上進行了實驗,分別是UCSD Ped2,CUHK Avenue和ShanghaiTech,其中Ped2和Avenue的場景固定,且資料量較小,ShanghaiTech資料集包含了13個監控場景,視頻長度較長,是目前視頻例外檢測領域中極具挑戰性的資料集,
模型評價指標使用AUROC,指標越高代表模型的例外檢測性能越好,需要注意的一點是,在訓練和測驗階段,輸入模型的并不是視頻幀的整個畫面,作者首先使用預訓練好的目標檢測模型對視頻資料進行前景RoI提取,對于每個RoI構成時空連續事件塊(spatial-temporal cube,STC),隨后進行光流場的重構和幀預測,這樣做可以有效過濾視頻背景噪聲帶來的誤差,
本文方法分別與現有基于重構的方法,基于預測的方法和二者混合的方法進行對比,達到SOTA效果:
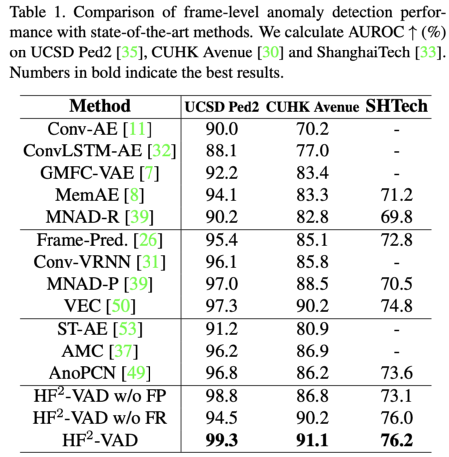
為了進一步展示本文方法可以增大傳統重構和預測方法檢測誤差的能力,作者進行了差分圖的可視化實驗,如下圖所示:

其中(a)為測驗集中例外事件的ground-truth,(b)為本文方法的幀預測結果,(c)為本文預測結果與ground-truth的差分圖,(d)和(e)為其他兩種方法與ground-truth的差分圖,同時也給出了差分圖的平方和誤差作為差異指標,可以看出,本文方法對于例外事件產生的預測誤差明顯高于其他方法,這有效提高了模型的例外檢測效果,
04
總結
本文探索了將重建任務和預測任務結合起來的可能性,實驗表明,所提出的方法優于單獨使用重構和預測任務的方法,此外,本文的集成策略也經過精心設計,通過先對光流場進行重構,再將視頻幀和光流作為輸入來預測未來的幀,可以增大例外事件的預測誤差,
參考文獻
[1] Dong Gong, Lingqiao Liu, Vuong Le, Budhaditya Saha, Moussa Reda Mansour, Svetha Venkatesh, and Anton van den Hengel. Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection. In Proceedings of the IEEE International Conference on Computer Vision, pages 1705–1714, 2019.
[2] HyunjongPark, JongyounNoh, and BumsubHam. Learning memory-guided normality for anomaly detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 14372–14381, 2020.

END
加入「視頻技術」交流群👇備注:vid

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/317712.html
標籤:其他