2020年數學建模國賽C題Demo【準確率只有61%,僅供參考】
MPai下載鏈接:www.mpaidata.com
關注公眾號:【萬靈資料】可以看很多很多建模資料噢
附件資料下載:https://mpaidata.lanzoui.com/iC1kAgk03ba
講解視頻:https://www.bilibili.com/video/BV1154y1C7ZC?from=search&seid=8443983732512492584
改進策略:
1,調整模型引數(效果微小)
2,擴充特征指標(效果中等)
3,擴充樣本數量(效果卓越)
思路如下:
該題目可使用評分卡(量化)+機器學習解決
可以使用MPai資料科學平臺 量化分析-AHP或熵權法 與監督機器學習-分類解決
C題 中小微企業的信貸決策
在實際中,由于中小微企業規模相對較小,也缺少抵押資產,因此銀行通常是依據信貸政策、企業的交易票據資訊和上下游企業的影響力,向實力強、供求關系穩定的企業提供貸款,并可以對信譽高、信貸風險小的企業給予利率優惠,銀行首先根據中小微企業的實力、信譽對其信貸風險做出評估,然后依據信貸風險等因素來確定是否放貸及貸款額度、利率和期限等信貸策略,
某銀行對確定要放貸企業的貸款額度為萬元;年利率為4%~15%;貸款期限為1年,附件1~3分別給出了123家有信貸記錄企業的相關資料、302家無信貸記錄企業的相關資料和貸款利率與客戶流失率關系的2019年統計資料,該銀行請你們團隊根據實際和附件中的資料資訊,通過建立數學模型研究對中小微企業的信貸策略,主要解決下列問題:
(1) 對附件1中123家企業的信貸風險進行量化分析,給出該銀行在年度信貸總額固定時對這些企業的信貸策略,
問題可以簡單理解為,對123家企業的信貸風險進行量化(將定類資料轉化為定量資料),然后給出怎么對這些企業進行評級與分配信用貸款,
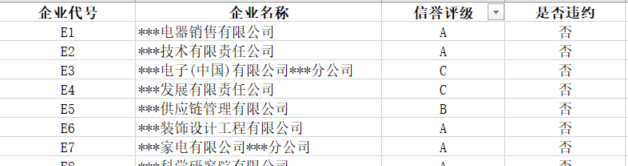
我們可以看到上圖,這是銀行已經對這些企業打的信用評級與確認出來的是否違約,我們需要做的就是把目前所能拿到的資料轉化一個定量的資料用于評價信貸風險,然后根據這個比例來按進行分配貸款,
到這里,大家應該知道要解決什么問題了,那怎么去做這件事情呢?
這里我給大家提出一種解決方案:
Step1:對資料進行缺失值和例外值處理;
(可通過MPai資料科學平臺【特征工程—資料清洗—缺失值處理】、【特征工程—資料清洗—例外值處理】)
Step2:對【是否違約】建立特征工程,以特征工程為X,以【是否違約】為Y, 建立一個信譽評級分類模型,特征工程的里的欄位可以是,【信譽評級】,
(1,需要轉化為數值標簽,可通過MPai資料科學平臺【特征工程—資料清洗—資料標簽轉化】
2,onehot編碼,可通過MPai資料科學平臺【特征工程—資料清洗—獨熱編碼】處理)
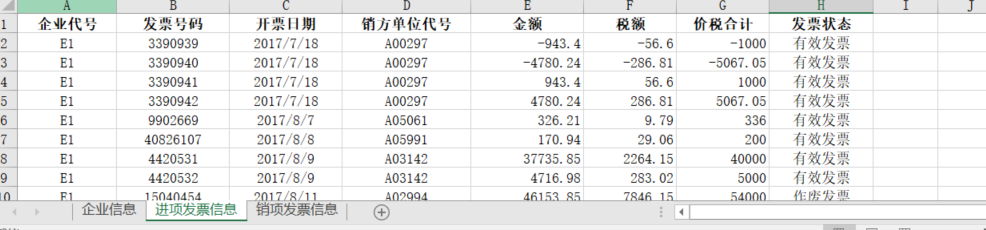
對于【進項發票資訊】,可以構造特征【金額】,【稅額】,【價稅合計】,【發票狀態】這些明面上的指標,也可以是【對企業代號進行分組,拿到的總金額、平均金額、中位數金額】,【對企業代號進行分組,拿到的總稅額、平均稅額、中位數稅額】,【對企業代號進行分組,拿到的總價稅合計、平均價稅合計、中位數價稅合計】,同時還可以是【對開票日期(日周月年)進行分組,拿到開票的頻數(日周月年)】,【累計開票數】,【累計有效發票個數】,【累計無效開票次數】
對于【銷項發票資訊】,同理與上
同時我么也可以根據企業名稱來進行聚類,例如科技公司,地產公司,可以通用詞向量聚類,也可以通過關鍵詞進行聚類,這樣又多了一個指標,【公司類別】
以后還有【(日周月年)均凈收入,凈支出】(收入發票減支出發票)
總之,盡可能擴充特征工程,就我上面列出來的就有共計50特征,當然,我們還是可以盡可能地多擴充,先不管這些特征是否存在共線性,
Step3:接著,我們需要對樣本資料進行均衡處理,因為我們肉眼可以看到【是否違約】存在極大的樣本不均衡,這些直接訓練一個分類模型會導致模型過擬合,例如我有一百個樣本,99個樣本是1,那么即使我瞎分類,全部判為1,準確率也是99%,樣本均衡可以通過上采樣或者下采樣
(可通過MPai資料科學平臺【特征工程—樣本均衡處理】)
Step4:由于構造的特征太多了,我們需要對特征進行篩選,這里我們需要減少特征,可以選擇諸如主成分分析等降維技術進行資料降維,也可以使用遞回消除特征法等篩選方法來進行特征篩選,
(1,可通過MPai資料科學平臺【特征工程—資料降維處理】,
2,可通過MPai資料科學平臺【特征工程—特征篩選處理】)
Step5:準備作業就緒,我們可以把他丟進一個分類模型進行序列,推薦邏輯回歸或者XGBOOST與隨機森林,需要對資料進行切分訓練,評價指標可以選擇F1,可以進行各種自由調參,保證模型的最優
查看模型輸出(這里只看概率),我們可以得到每個模型的【是否違約_否】的概率,這個概率就可以作為信貸風險的量化得分,然后我們這里可以進行歸一化,然后按比例分配貸款,
以上方法簡單粗暴,如果想要更突出的小伙伴可以使用評分卡或者AHP模型,這里舉例AHP模型,信貸風險的評價指標可以分為三個內容:信譽評級,是否違約,企業流水或收入支出比,我們可以設計2個分類模型(是否違約),一個回歸模型(企業流水或收入支出比),采用AHP構建判斷矩陣(用德爾菲法確定輸入,可以不用),然后加權來得出來信貸風險的量化得分
(1,可通過MPai資料科學平臺【監督機器學習—分類】,
2,可通過MPai資料科學平臺【量化分析—層次分析法】)
(2) 在問題1的基礎上,對附件2中302家企業的信貸風險進行量化分析,并給出該銀行在年度信貸總額為1億元時對這些企業的信貸策略,
問題1解決了,問題二不就是重新構建特征工程X,然后把X丟進問題一訓練好的模型,可以得到量化結果,按比例即可分配,
這里注意一點,由于附件2沒有【信譽評級】,那么在問題1種,我們不能把【信譽評級】放入特征工程,
(3) 企業的生產經營和經濟效益可能會受到一些突發因素影響,而且突發因素往往對不同行業、不同類別的企業會有不同的影響,綜合考慮附件2中各企業的信貸風險和可能的突發因素(例如:新冠病毒疫情)對各企業的影響,給出該銀行在年度信貸總額為1億元時的信貸調整策略,
這里要求給出信貸調整策略,原因是突發因素會對不同行業、不同類別的企業會有不同的影響,例如對互聯網行業,新冠病毒疫情是促進的,但是對于旅游業,新冠病毒疫情則導致了其大蕭條,因此這里需要分不同行業來進行調整:
基于企業名的關鍵詞同過問題1的方法可以得到行業的區分,可以通過AHP或者熵值法(需要自行爬取資料)等量化模型對不同行業構建判斷矩陣,得到他們的權重比,然后加權在問題2的信貸風險量化得分上,即為一個比較有理,簡單的解決方案,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/31888.html
標籤:其他