摘要:記錄一下自己在10月份參加DataWhale組隊學習transformer的所得,這篇博客主要關于transformer基本原理的學習和一個輸入序列轉換的簡單demo,并補充了一些transformer在CV領域的variants,希望本次組隊學習能幫助自己快速入門,有機會將transformer用在透過散射成像或者PAM成像相關領域中,以下內容主要參照Datawhale開源資料《動手學CV-Pytorch》第六章,感謝DataWhale開源組織,也歡迎大家點進去多多學習~
2017年谷歌在一篇名為Attention Is All You Need [1]的論文中,提出了一個基于self-attention (自注意力機制)結構來處理序列相關的問題的模型,名為Transformer,
Transformer在很多不同NLP任務中獲得了成功,例如:文本分類、機器翻譯、閱讀理解等,在解決這類問題時,Transformer模型摒棄了固有的定式,并沒有用任何CNN或者RNN的結構,而是使用了自注意力機制,自動捕捉輸入序列不同位置處的相對關聯,善于處理較長文本,并且該模型可以高度并行地作業,訓練速度很快,
從2020年開始,transformer被移植到CV領域并大放異彩,包括流行的識別任務(例如影像分類,目標檢測,動作識別和分割),生成模型,多模式任務(例如視覺問題解答和視覺推理),視頻處理(例如活動識別,視頻預測),low-level視覺(例如影像超解析度和影像復原等),具體可參見兩篇綜述:A Survey on Visual Transformer [2] 和Transformers in Vision: A Survey [3].
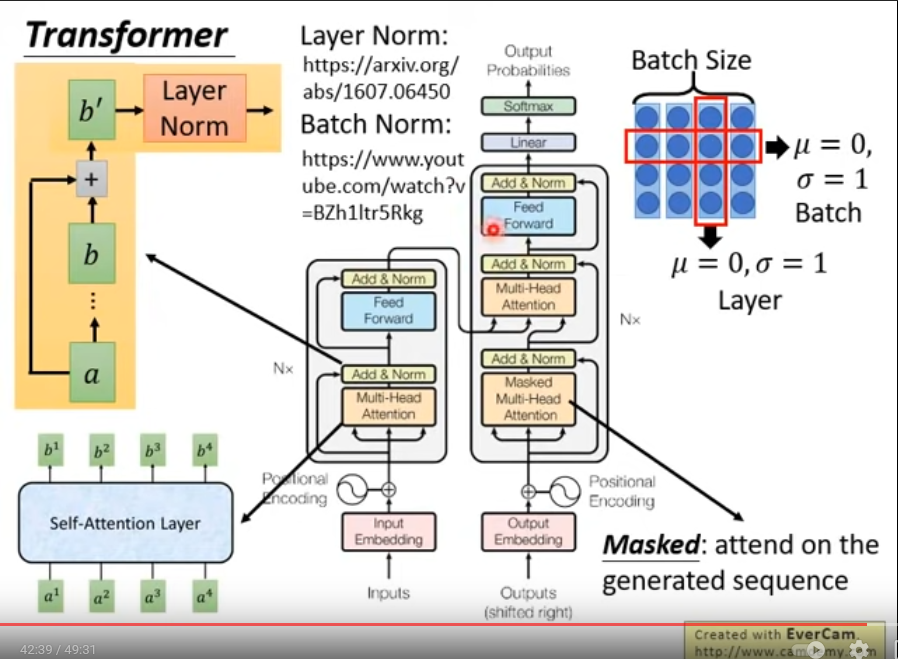
Transformer模型結構
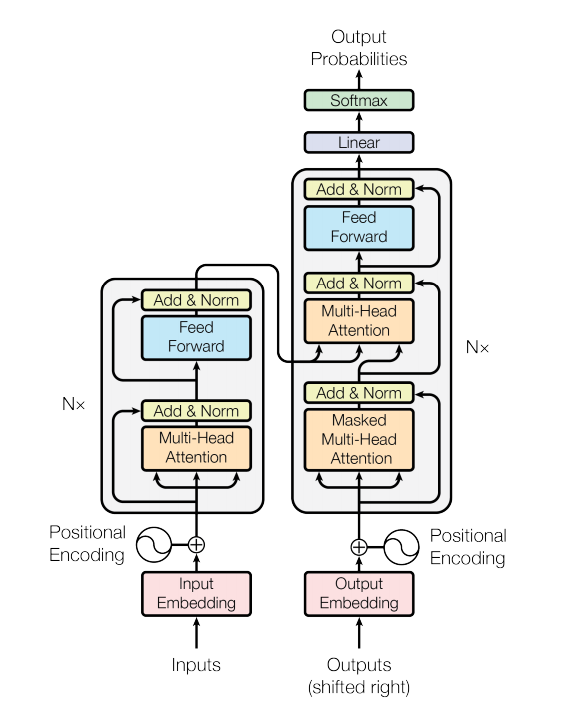
-
編碼器(Encoder):N個相同層堆疊在一起,每一層又包含2個子層;第1個子層是Multi-Head Attention(多頭的自注意機制),第2個子層是一個簡單的Feed Foward網路,兩個子層都添加了一個residual 結構和Layer normalization,
-
譯碼器(Decoder):同樣堆疊N個相同層,每一層結構除了也有Multi-Head Attention和Feed Foward網路,還包括一個子層Masked Multi-Head Attention,每個子層同樣使用residual 結構和Layer normalization; N層堆疊后加上全連接+Softmax層得到預測概率輸出,
- 第一個子層Masked Multi-Head Attention在多頭注意力機制的基礎上多了掩碼mask,用于屏蔽掉無效的padding區域,以及屏蔽來自“未來”的資訊,將注意力集中在當前生成序列上(上次預測結果作為輸入);
- 第二個子層Multi-Head Attention中,query來自譯碼器的上一個子層,key 和 value 來自編碼器的輸出,可以這樣理解,就是第二層負責,利用譯碼器已經預測出的資訊作為query,去編碼器提取的各種特征中,查找相關資訊并融合到當前特征中,來完成預測,
模型輸入
由Input Embedding和Positional Encoding(位置編碼)兩部分組合而成
- Input Embedding層
將某種格式的輸入資料,例如文本(Word Embedding),轉變為模型可以處理的向量表示,來描述原始資料所包含的資訊(提取特征),構建Embedding層的代碼很簡單,核心是借助torch提供的nn.Embedding,Embedding層輸出的可以理解為當前時間步的特征 - Positional Encoding層
為模型提供當前時間步的前后出現順序的資訊,位置編碼可以有很多選擇,可以是固定的,也可以設定成可學習的引數,這里,我們使用固定的位置編碼,具體地,使用不同頻率的sin和cos函式來進行位置編碼,如下所示:
P E ( p o s , 2 i ) = sin ? ( p o s 1000 0 2 i d m o d e l ) P E ( p o s , 2 i + 1 ) = cos ? ( p o s 1000 0 2 i d m o d e l ) PE_{(pos, 2 i)}=\sin \left(\frac{ pos }{10000^{\frac{2 i}{d_{model }}}}\right) \\ PE_{(pos, 2 i+1)}=\cos \left(\frac{ pos}{10000^{\frac{2 i}{d_{model }}}}\right) PE(pos,2i)?=sin(10000dmodel?2i?pos?)PE(pos,2i+1)?=cos(10000dmodel?2i?pos?)
其中pos代表時間步的下標索引/句子中字的位置,向量 P E p o s PE_{pos} PEpos? ? 也就是第pos個時間步的位置編碼(編碼分奇偶),編碼長度同Input Embedding層輸出向量維度 d m o d e l d_{model} dmodel?
對于最大序列長度為100,字嵌入維度為16的位置編碼可視化如下:
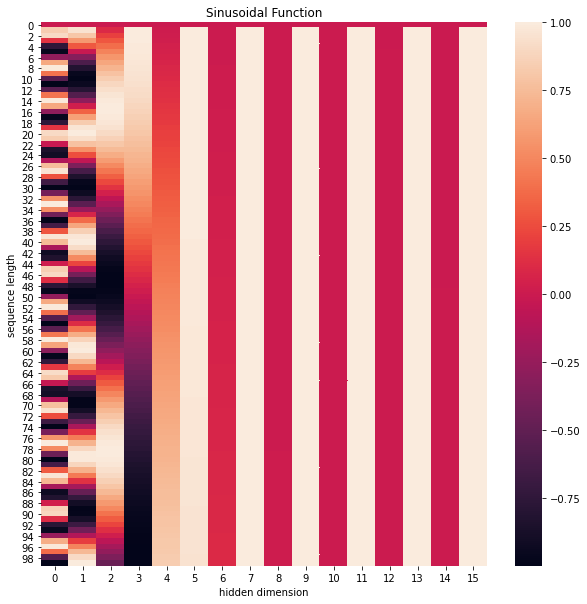
思考:為什么上面的公式可以作為位置編碼?
- 在上面公式的定義下,時間步p和時間步p+k的位置編碼的內積,即 P E ( p ) ? P E ( p + k ) PE_{(p)} \cdot PE_{(p+k)} PE(p)??PE(p+k)? 是與p無關,只與k有關的定值,證明如下, 也就是說,任意兩個相距k個時間步的位置編碼向量的內積都是相同的,這就相當于蘊含了兩個時間步之間相對位置關系的資訊,
P E p = { cos ? ( p 1000 0 2 i d m o d e l ) , sin ? ( p 1000 0 2 i d m o d e l ) } , i = 0 , 1 , 2... P E p + k = { cos ? ( p + k 1000 0 2 i d m o d e l ) , sin ? ( p + k 1000 0 2 i d m o d e l ) } , i = 0 , 1 , 2... P E p ? P E p + k = ∑ i cos ? ( p 1000 0 2 i d m o d e l ) cos ? ( p + k 1000 0 2 i d m o d e l ) ? sin ? ( p 1000 0 2 i d m o d e l ) sin ? ( p + k 1000 0 2 i d m o d e l ) = ∑ i cos ? ( p 1000 0 2 i d m o d e l ? p + k 1000 0 2 i d m o d e l ) = ∑ i cos ? ( ? k 1000 0 2 i d m o d e l ) = c o n s t . PE_{p}=\left \{ \cos \left(\frac{ p }{10000^{\frac{2 i}{d_{model }}}}\right), \sin \left(\frac{ p }{10000^{\frac{2 i}{d_{model }}}}\right) \right \}, i=0, 1, 2... \\ PE_{p+k}=\left \{ \cos \left(\frac{ p+k }{10000^{\frac{2 i}{d_{model }}}}\right), \sin \left(\frac{ p+k }{10000^{\frac{2 i}{d_{model }}}}\right) \right \}, i=0, 1, 2...\\ PE_{p} \cdot PE_{p+k} = \sum_i {\cos \left(\frac{ p }{10000^{\frac{2 i}{d_{model }}}}\right) \cos \left(\frac{ p+k }{10000^{\frac{2 i}{d_{model }}}}\right) - \sin \left(\frac{ p }{10000^{\frac{2 i}{d_{model }}}}\right) \sin \left(\frac{ p+k }{10000^{\frac{2 i}{d_{model }}}}\right) } \\ =\sum_i {\cos \left(\frac{ p }{10000^{\frac{2 i}{d_{model }}}} - \frac{ p+k }{10000^{\frac{2 i}{d_{model }}}} \right)} =\sum_i {\cos \left(\frac{ -k }{10000^{\frac{2 i}{d_{model }}}} \right)} =const. PEp?={cos(10000dmodel?2i?p?),sin(10000dmodel?2i?p?)},i=0,1,2...PEp+k?={cos(10000dmodel?2i?p+k?),sin(10000dmodel?2i?p+k?)},i=0,1,2...PEp??PEp+k?=∑i?cos(10000dmodel?2i?p?)cos(10000dmodel?2i?p+k?)?sin(10000dmodel?2i?p?)sin(10000dmodel?2i?p+k?)=∑i?cos(10000dmodel?2i?p??10000dmodel?2i?p+k?)=∑i?cos(10000dmodel?2i??k?)=const.
- 此外,每個時間步的位置編碼又是唯一的,這兩個很好的性質使得上面的公式作為位置編碼是有理論保障的,
-
Encoder和Decoder都包含輸入模塊
編碼器和解碼器兩個部分都包含輸入,且兩部分的輸入的結構是相同的,只是推理時的用法不同,編碼器只推理一次,而解碼器是類似RNN那樣回圈推理,將解碼器上次預測結果再次輸入,來預測下次結果,如此不斷生成預測結果的,
解碼器部分既有編碼器提取特征的輸入,也有上次預測結果經embedding層和position encoding層的輸入,輸出序列的下一個結果, -
模型輸出
輸出部分就很簡單了,每個時間步都過一個 線性層 + softmax層
線性層的作用:通過對上一步的線性變化得到指定維度的輸出,也就是轉換維度的作用,轉換后的維度對應著輸出類別的個數,如果是翻譯任務,那就對應的是文字字典的大小,
自注意力機制 (self-attention)
“把注意力聚焦到最有價值的區域來仔細觀察,從而作出有效判斷,”
注意力計算:它需要三個指定的輸入Q(query), K(key), V(value), 然后通過下面公式得到注意力的計算結果:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
Attention(Q, K, V) = softmax \left(\frac{QK^T}{\sqrt{d_k}} \right)V
Attention(Q,K,V)=softmax(dk?
?QKT?)V
可以這么簡單的理解,當前時間步的注意力計算結果,是一個組系數 * 每個時間步的特征向量value的累加,而這個系數,通過當前時間步的query和其他時間步對應的key做內積得到,這個程序相當于用自己的query對別的時間步的key做查詢,判斷相似度,決定以多大的比例將對應時間步的資訊繼承過來,
這里通過李宏毅老師的Transformer視頻輔助理解,以下有大量視頻截圖+我的零碎筆記~
Transformer: seq2seq model with “self-attention”
? RNN難以并行化,CNN可以
RNN考慮整個輸入(句子序列)才輸出
CNN能輸出相同序列,但filter區域連接,輸出時只能看句子區域
多個filter同時計算
更高層fdilter的感受野更大,能考慮更長句子
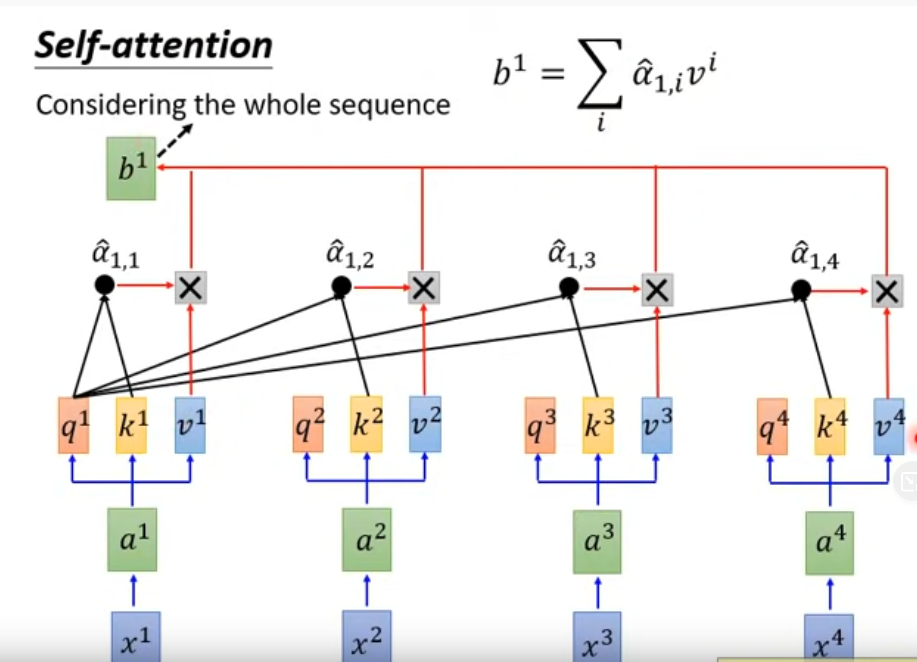
- Self-attention取代RNN
輸入輸出和RNN一樣,都是sequence,每一個輸出都看了整個句子,同時能并行化輸出
- 拿每個query q 對每個key k做attention(吃2個vector吐1個數),得到 α ( 1 , i ) α_{(1,i)} α(1,i)?
- α ( 1 , i ) α_{(1,i)} α(1,i)? 經過softmax層
- 產生b1需要已經考慮到整個sequence,依次算出b2, b3, b4
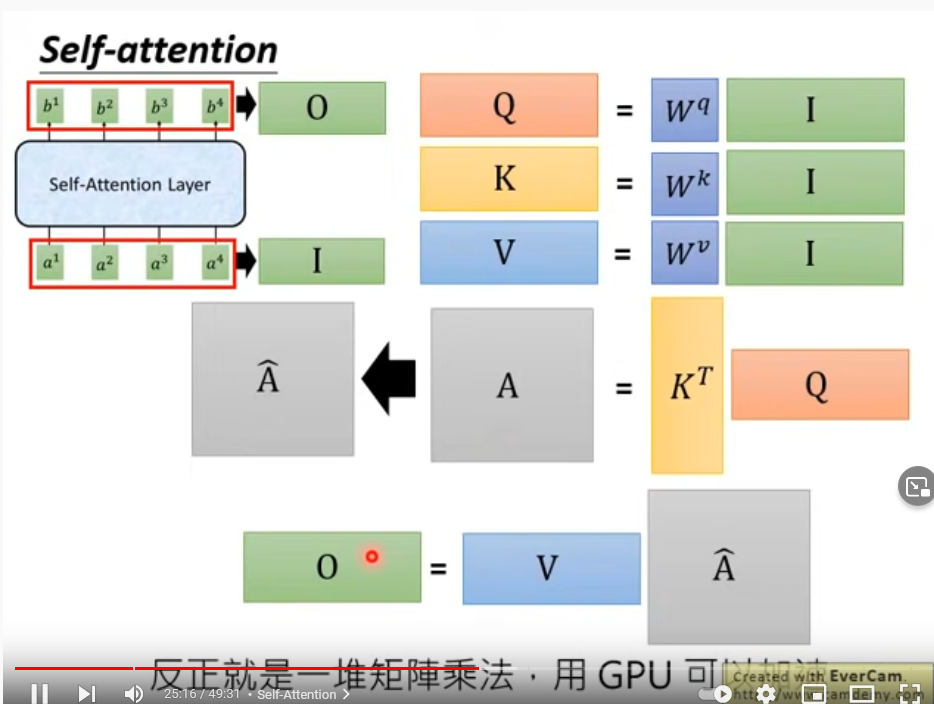
- Self-attention如何做并行化?矩陣運算
計算q, k, v
- 計算 α ( 1 , i ) α_{(1,i)} α(1,i)?為q1與 k i k_i ki?的dot product并計算b1;依次計算 α ( 2 , i ) α_{(2,i)} α(2,i)?和 b 2 b_2 b2?…
- 計算最終輸出:V與α相乘疊加,即向量與矩陣相乘
- 總結:矩陣乘法,GPU加速
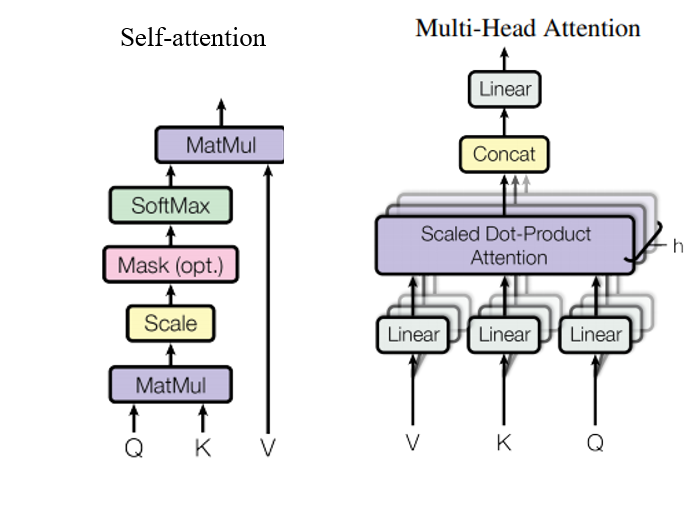
多頭注意力機制 (Mult-Head Attention)
剛剛介紹了attention機制,在搭建EncoderLayer時候所使用的Attention模塊,實際使用的是多頭注意力,可以簡單理解為多個注意力模塊組合在一起,
多頭注意力機制的作用:這種結構設計能讓每個注意力機制去優化每個詞匯的不同特征部分,從而均衡同一種注意力機制可能產生的偏差,讓詞義擁有來自更多元表達,實驗表明可以從而提升模型效果,
實際transformer網路中使用的是均是多頭注意力網路層,self-attention和Multi-head attention的示意圖如下:
 繼續李宏毅視頻補充:
繼續李宏毅視頻補充:
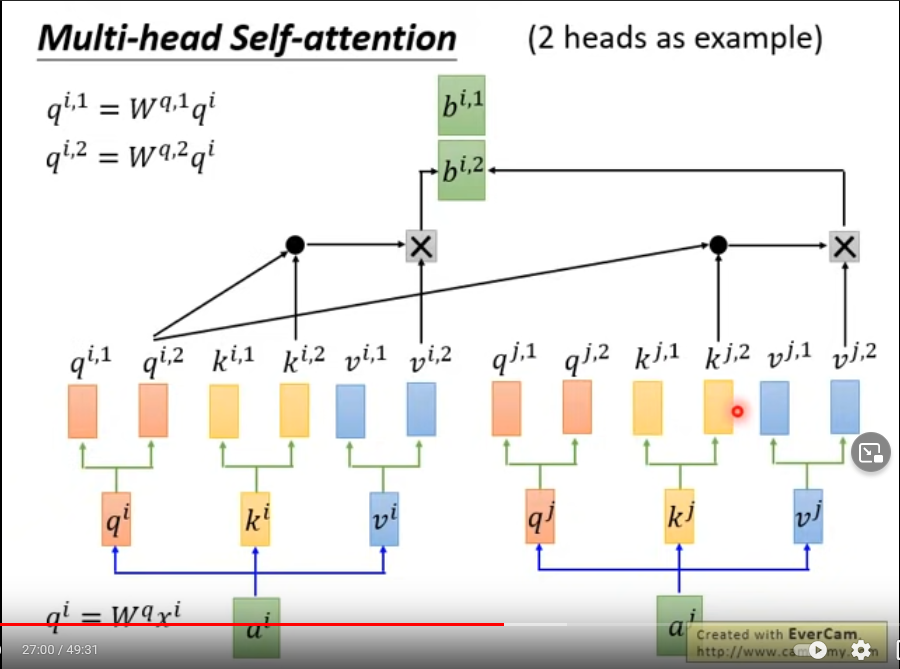
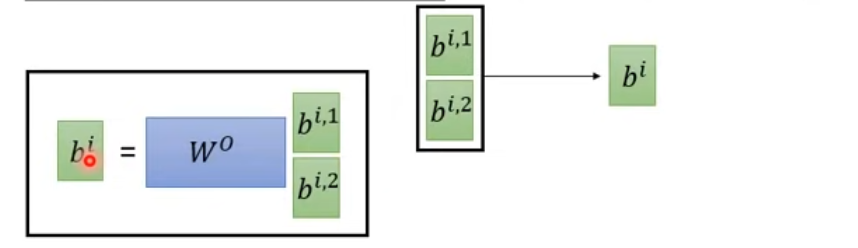
Multi-head self-attention (2 head為例)
不同head,Local/global 感受野,head數目可調
原本self-attention里Input sequence順序不重要,與每個input vector都做attention,與時間點無關,無位置資訊
e i e^i ei與 a i a^i ai 相同維度,以添加位置資訊;為什么是相加(add),而不是連接(catenate)?
a i + e i a^i+e^i ai+ei 理解: a i a^i ai拆分為 x i x^i xi和one-hot vector p i p^i pi,W拆分為 W I W^I WI 和 W P W^P WP,則 e i = W P P i e^i=W^PP^i ei=WPPi
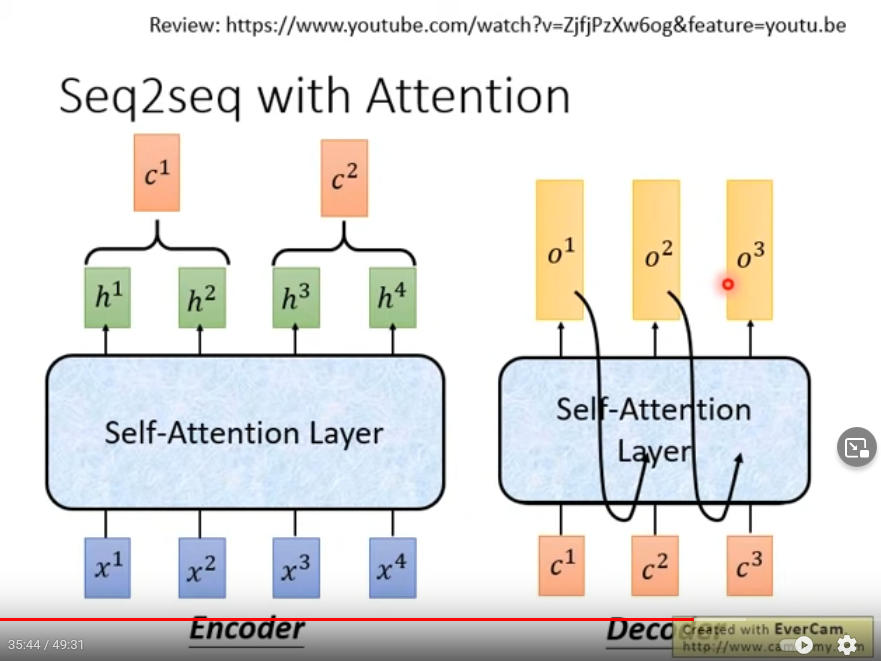
Seq2seq model with Attention:把RNN換成self-attention
decoder既有當前輸入,也有上次輸出,如此回圈預測
前饋全連接層
EncoderLayer中另一個核心的子層是 Feed Forward Layer,我們這就介紹一下,
在進行了Attention操作之后,encoder和decoder中的每一層都包含了一個全連接前向網路,對每個position的向量分別進行相同的操作,包括兩個線性變換和一個ReLU激活輸出:
F
F
N
(
x
)
=
m
a
x
(
0
,
x
W
1
+
b
1
)
W
2
+
b
2
FFN(x) = max(0, xW_1+b_1)W_2 + b_2
FFN(x)=max(0,xW1?+b1?)W2?+b2?
Feed Forward Layer 其實就是簡單的由兩個前向全連接層組成,核心在于,Attention模塊每個時間步的輸出都整合了所有時間步的資訊,而Feed Forward Layer每個時間步只是對自己的特征的一個進一步整合,與其他時間步無關,
掩碼及其作用
掩碼的尺寸不定,里面一般只有0和1,代表位置被遮掩或者不被遮掩,掩碼的作用如下:一個是屏蔽掉無效的padding區域,一個是屏蔽掉來自“未來”的資訊,Encoder中的掩碼主要是起到第一個作用,Decoder中的掩碼則同時發揮著兩種作用,
-
屏蔽掉無效的padding區域:我們訓練需要組batch進行,就以機器翻譯任務為例,一個batch中不同樣本的輸入長度很可能是不一樣的,此時我們要設定一個最大句子長度,然后對空白區域進行padding填充,而填充的區域無論在Encoder還是Decoder的計算中都是沒有意義的,因此需要用mask進行標識,屏蔽掉對應區域的回應,
-
屏蔽掉來自未來的資訊:我們已經學習了attention的計算流程,它是會綜合所有時間步的計算的,那么在解碼的時候,就有可能獲取到未來的資訊,這是不行的,因此,這種情況也需要我們使用mask進行屏蔽,
vanilla transformer代碼實作
import math, copy, time
import numpy as np
import torch
from torch import nn
import torch.nn.functional as F
# Transformer model, see (2017)Attention Is All You Need https://arxiv.org/abs/1706.03762
# The code is from: https://datawhalechina.github.io/dive-into-cv-pytorch/#/chapter06_transformer/6_1_hello_transformer
#Embedding層
class Embeddings(nn.Module):
'''
將輸入序列提取特征+向量化表示 (word embeddings含義)
'''
def __init__(self, d_model, vocab):
'''
d_model: dimension of each embedding vector
vocab: size of the dictionary of embeddings
'''
super(Embeddings, self).__init__()
#呼叫torch.nn.Embedding預定義層, https://pytorch.org/docs/stable/generated/torch.nn.Embedding.html?highlight=nn%20embedding#torch.nn.Embedding
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
embedds = self.lut(x)
return embedds * math.sqrt(self.d_model)
#Position encoding層
class PositionalEncoding(nn.Module):
'''
為輸入文本序列提供當前word/時間步的出現順序資訊
'''
def __init__(self, d_model, dropout, max_len=5000):
'''
d_model: 詞嵌入的維度
dropout: dropout rate
max_len 每個句子最大長度
'''
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
#compute the positional encodings
pe = torch.zeros(max_len, d_model) #(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1) #(max_len, 1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model)) #(1, d_model/2)
pe[:, 0::2] = torch.sin(position * div_term) #(max_len, d_model/2),行向量與列向量遍歷相乘
pe[:, 1::2] = torch.cos(position * div_term) #(max_len, d_model/2)
pe = pe.unsqueeze(0) #(1, max_len, d_model)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:, :x.size(1)].requires_grad_(False)
return self.dropout(x)
# 定義一個clones函式,來更方便的將某個結構復制若干份
def clones(module, N):
"Produce N identical layers."
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class SublayerConnection(nn.Module):
"""
實作子層連接結構的類
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"Apply residual connection to any sublayer with the same size."
# 原paper的方案
#sublayer_out = sublayer(x)
#x_norm = self.norm(x + self.dropout(sublayer_out))
# 稍加調整的版本
sublayer_out = sublayer(x)
sublayer_out = self.dropout(sublayer_out)
x_norm = x + self.norm(sublayer_out)
return x_norm
# Attention
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"Implements Figure 2"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
# We employ a residual connection around each of the two sub-layers, followed by layer normalization
class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, feature_size, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(feature_size))
self.b_2 = nn.Parameter(torch.zeros(feature_size))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
def subsequent_mask(size):
"Mask out subsequent positions."
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
return torch.from_numpy(subsequent_mask) == 0
#編碼器
class Encoder(nn.Module):
"""
Encoder
The encoder is composed of a stack of N=6 identical layers.
"""
def __init__(self, layer, N):
super(Encoder, self).__init__()
# 呼叫時會將編碼器層傳進來,我們簡單克隆N分,疊加在一起,組成完整的Encoder
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
class EncoderLayer(nn.Module):
"EncoderLayer is made up of two sublayer: self-attn and feed forward"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size # embedding's dimention of model, 默認512
def forward(self, x, mask):
# attention sub layer
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
# feed forward sub layer
z = self.sublayer[1](x, self.feed_forward)
return z
# Decoder
# The decoder is also composed of a stack of N=6 identical layers.
class Decoder(nn.Module):
"Generic N layer decoder with masking."
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
"Follow Figure 1 (right) for connections."
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
class Generator(nn.Module):
"Define standard linear + softmax generation step."
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return F.log_softmax(self.proj(x), dim=-1)
# Model Architecture
class EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture.
Base for this and many other models.
Base for this and many other models.
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed # input embedding module(input embedding + positional encode)
self.tgt_embed = tgt_embed # ouput embedding module
self.generator = generator # output generation module
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
memory = self.encode(src, src_mask)
res = self.decode(memory, src_mask, tgt, tgt_mask)
return res
def encode(self, src, src_mask):
src_embedds = self.src_embed(src)
return self.encoder(src_embedds, src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
target_embedds = self.tgt_embed(tgt)
return self.decoder(target_embedds, memory, src_mask, tgt_mask)
# Full Model
def make_model(src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1):
"""
構建模型
params:
src_vocab: encoder輸入序列編碼的詞典數量
tgt_vocab: dncoder輸入序列編碼的詞典數量
N: 編碼器和解碼器堆疊基礎模塊的個數
d_model: 模型中embedding的size,默認512
d_ff: FeedForward Layer層中embedding的size,默認2048
h: MultiHeadAttention中多頭的個數,必須被d_model整除
dropout:
"""
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab))
# This was important from their code.
# Initialize parameters with Glorot / fan_avg.
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model
if __name__ == "__main__":
print("\n-----------------------")
print("test subsequect_mask")
temp_mask = subsequent_mask(4)
print(temp_mask)
print("\n-----------------------")
print("test build model")
tmp_model = make_model(10, 10, 2)
print(tmp_model)
Toy-level task:數字序列轉換
下面我們用一個人造的玩具級的小任務,來實戰體驗下Transformer的訓練,加深我們的理解,并且驗證我們上面所述代碼是否work,
任務描述:針對數字序列進行學習,學習的最終目標是使模型學會輸出與輸入的序列洗掉第一個字符之后的相同的序列,如輸入[1,2,3,4,5],我們嘗試讓模型學會輸出[2,3,4,5],
第一步:構建并生成人工資料集
第二步:構建Transformer模型及相關準備作業
第三步:運行模型進行訓練和評估
第四步:使用模型進行貪婪解碼
‘’’
import time
import numpy as np
import torch
import torch.nn as nn
from models.transformer_basic import make_model, subsequent_mask
import matplotlib.pyplot as plt
'''
#Toy-level number sequence transformation via transformer
@author: anshengmath@163.com
The code is from https://github.com/datawhalechina/dive-into-cv-pytorch/blob/master/code/chapter06_transformer/6.1_hello_transformer/first_train_demo.py
'''
class Batch:
"Object for holding a batch of data with mask during training."
def __init__(self, src, trg=None, pad=0):
self.src = src
self.src_mask = (src != pad).unsqueeze(-2)
if trg is not None:
self.trg = trg[:, :-1] # decoder的輸入(即期望輸出除了最后一個token以外的部分) (2, 9)
self.trg_y = trg[:, 1:] # decoder的期望輸出(trg基礎上再刪去句子起始符)(2, 9)
self.trg_mask = self.make_std_mask(self.trg, pad) #(2, 9, 9)
self.ntokens = (self.trg_y != pad).data.sum()
@staticmethod
def make_std_mask(tgt, pad):
"""
Create a mask to hide padding and future words.
pad 和 future words 均在mask中用0表示
"""
tgt_mask = (tgt != pad).unsqueeze(-2)
tgt_mask = tgt_mask & subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data) #(2, 1, 9) & (1, 9, 9) = (2, 9, 9)
return tgt_mask
# Synthetic Data
def data_gen(V, batch, nbatches, device):
"""
Generate random data for a src-tgt copy task.
V: 詞典數量,取值范圍[0, V-1],約定0作為特殊符號使用代表padding
slen: 生成的序列資料的長度
batch: batch_size
nbatches: number of batches/iterations per epoch
"""
slen = 10
for i in range(nbatches):
data = torch.from_numpy(np.random.randint(1, V, size=(batch, slen)))
# 約定輸出為輸入除去序列第一個元素,即向后平移一位進行輸出,同時輸出資料要在第一個時間步添加一個起始符
# 因此,加入輸入資料為 [3, 4, 2, 6, 4, 5]
# ground truth輸出為 [1, 4, 2, 6, 4, 5]
tgt = data.clone()
tgt[:, 0] = 1
src = data
if device == "cuda":
src = src.cuda()
tgt = tgt.cuda()
yield Batch(src, tgt, 0)
# test data_gen
data_iter = data_gen(V=5, batch=2, nbatches=10, device="cpu")
for i, batch in enumerate(data_iter):
print("\nbatch.src")
print(batch.src.shape) #torch.Size([2, 10])encoder的輸入
print(batch.src)
print("\nbatch.trg")
print(batch.trg.shape) #torch.Size([2, 9])decoder的輸入(第1列置1并舍棄最后1列)
print(batch.trg)
print("\nbatch.trg_y")
print(batch.trg_y.shape) #torch.Size([2, 9])decoder的期望輸出(舍棄第1列)
print(batch.trg_y)
print("\nbatch.src_mask")
print(batch.src_mask.shape) #torch.Size([2, 1, 10])encoder的輸入掩碼,屏蔽無效padding區域
print(batch.src_mask)
print("\nbatch.trg_mask")
print(batch.trg_mask.shape) #torch.Size([2, 9, 9])decoder的輸入掩碼,屏蔽無效padding區域 & “未來”資訊
print(batch.trg_mask)
break
#raise RuntimeError()
class NoamOpt:
"Optim wrapper that implements rate."
def __init__(self, model_size, factor, warmup, optimizer):
self.optimizer = optimizer
self._step = 0
self.warmup = warmup #400
self.factor = factor #1
self.model_size = model_size #d_model
self._rate = 0
def step(self):
"Update parameters and rate"
self._step += 1
rate = self.rate()
for p in self.optimizer.param_groups:
p['lr'] = rate
self._rate = rate
self.optimizer.step()
def rate(self, step = None):
"Implement `lrate` above"
if step is None:
step = self._step
return self.factor * \
(self.model_size ** (-0.5) *
min(step ** (-0.5), step * self.warmup ** (-1.5)))
def get_std_opt(model):
return NoamOpt(model.src_embed[0].d_model, 2, 4000,
torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9))
class LabelSmoothing(nn.Module):
"Implement label smoothing."
def __init__(self, size, padding_idx, smoothing=0.0):
super(LabelSmoothing, self).__init__()
self.criterion = nn.KLDivLoss(size_average=False)
self.padding_idx = padding_idx #0
self.confidence = 1.0 - smoothing
self.smoothing = smoothing #0
self.size = size #詞典數量
self.true_dist = None
def forward(self, x, target):
assert x.size(1) == self.size
true_dist = x.data.clone()
true_dist.fill_(self.smoothing / (self.size - 2))
true_dist.scatter_(1, target.data.unsqueeze(1).type(torch.int64), self.confidence)
true_dist[:, self.padding_idx] = 0
mask = torch.nonzero(target.data == self.padding_idx)
if mask.dim() > 0:
true_dist.index_fill_(0, mask.squeeze(), 0.0)
self.true_dist = true_dist
return self.criterion(x, true_dist.requires_grad_(False))
class SimpleLossCompute:
"A simple loss compute and train function."
def __init__(self, generator, criterion, opt=None):
self.generator = generator
self.criterion = criterion
self.opt = opt
def __call__(self, x, y, norm):
"""
norm: loss的歸一化系數,用batch中所有有效token數即可
"""
x = self.generator(x)
x_ = x.contiguous().view(-1, x.size(-1))
y_ = y.contiguous().view(-1)
loss = self.criterion(x_, y_)
loss /= norm
loss.backward()
if self.opt is not None:
self.opt.step()
self.opt.optimizer.zero_grad()
return loss.item() * norm
def run_epoch(data_iter, model, loss_compute, device=None):
"Standard Training and Logging Function"
start = time.time()
total_tokens = 0
total_loss = 0
tokens = 0
for i, batch in enumerate(data_iter):
out = model.forward(batch.src, batch.trg,
batch.src_mask, batch.trg_mask)
loss = loss_compute(out, batch.trg_y, batch.ntokens)
total_loss += loss
total_tokens += batch.ntokens
tokens += batch.ntokens
if i % 50 == 1:
elapsed = time.time() - start
print("Epoch Step: %d Loss: %f Tokens per Sec: %f" %
(i, loss / batch.ntokens, tokens / elapsed))
start = time.time()
tokens = 0
return total_loss / total_tokens
# Train the model
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('Using {} device'.format(device))
batch_size = 32
V = 11 # 詞典的數量
iter_per_train_epoch = 30 # 訓練時每個epoch多少個batch/iterations
iter_per_valid_epoch = 10 # 驗證時每個epoch多少個batch/iterations
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
model = make_model(V, V, N=2)
model_opt = NoamOpt(model.src_embed[0].d_model, 1, 400,
torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9))
if device == "cuda":
model.cuda()
train_mean_loss = []
valid_mean_loss = []
for epoch in range(20): # 訓練20個epoch
print(f"\nepoch {epoch+1}")
print("train...")
model.train()
data_iter = data_gen(V, batch_size, iter_per_train_epoch, device)
loss_compute = SimpleLossCompute(model.generator, criterion, model_opt)
train_mean_loss.append(run_epoch(data_iter, model, loss_compute, device))
print("valid...")
model.eval()
valid_data_iter = data_gen(V, batch_size, iter_per_valid_epoch, device)
valid_loss_compute = SimpleLossCompute(model.generator, criterion, None)
valid_mean_loss.append(run_epoch(valid_data_iter, model, valid_loss_compute, device))
print(f"valid loss: {valid_mean_loss}")
plt.figure()
plt.plot(range(1, 21), train_mean_loss, 'b-o', label="train", linewidth=2)
plt.plot(range(1, 21), valid_mean_loss, 'r-*', label="valid", linewidth=2)
plt.grid(True, linestyle='-')
plt.xlabel('Epochs', fontsize= 14)
plt.legend()
plt.title("loss curve", fontsize= 14)
plt.show()
網路訓練和驗證的loss curve
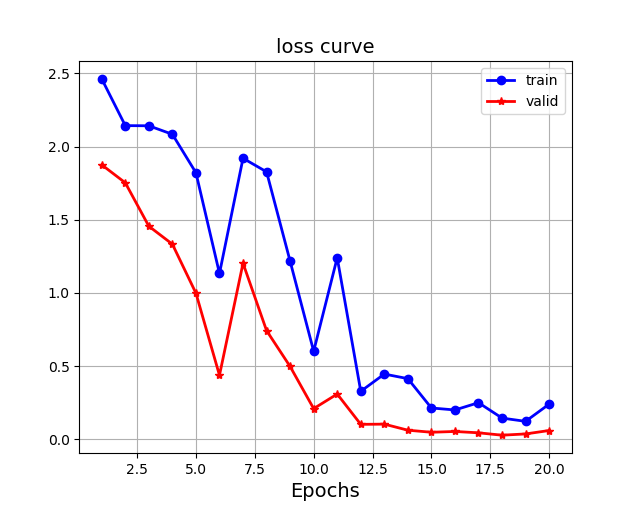
訓好模型后,使用貪心解碼的策略,進行預測,
推理得到預測結果的方法并不是唯一的,貪心解碼是最常用的,我們在 6.1.2 模型輸入的小節中已經介紹過,其實就是先從一個句子起始符開始,每次推理解碼器得到一個輸出,然后將得到的輸出加到解碼器的輸入中,再次推理得到一個新的輸出,回圈往復直到預測出句子的終止符,此時將所有預測連在一起便得到了完整的預測結果,
# Greedy decode to test if the whole input sequence can be predicted to be completely accurate
def greedy_decode(model, src, src_mask, max_len, start_symbol):
memory = model.encode(src, src_mask)
# ys代表目前已生成的序列,最初為僅包含一個起始符的序列,不斷將預測結果追加到序列最后
ys = torch.ones(1, 1).fill_(start_symbol).type_as(src.data)
for i in range(max_len-1):
out = model.decode(memory,
src_mask,
ys, #target
subsequent_mask(ys.size(1)).type_as(src.data)) #target mask
prob = model.generator(out[:, -1])
_, next_word = torch.max(prob, dim = 1)
next_word = next_word.data[0]
ys = torch.cat([ys, torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=1)
return ys
print("greedy decode")
model.eval()
src = torch.LongTensor([[1,2,3,4,5,6,7,8,9,10]]).cuda()
src_mask = torch.ones(1, 1, 10).cuda()
pred_result = greedy_decode(model, src, src_mask, max_len=10, start_symbol=1)
print(pred_result[:, 1:])
最終網路輸出:
greedy decode
tensor([[ 2, 3, 4, 5, 6, 7, 8, 9, 10]], device=‘cuda:0’)
總結:
- 我第一次接觸NLP的訓練任務,看代碼還是花了很久,尤其這里標簽平滑類
LabelSmoothing的構造、優化器的封裝類NoamOpt、輸出iterator的資料生成類data_gen、以及貪婪演算法測驗整個輸入數字序列是否完整預測正確的greedy_decode函式,都寫得比較巧妙,不是很容易看懂, - 接下來多了解一些最近transformer在CV上的作業,尤其是影像增強,分割和重建,
Transformer在CV中的variants
- 知乎上關于視覺transformer對比cnn的特性和優勢的討論
如何看待Transformer在CV上的應用前景,未來有可能替代CNN嗎?
- 視覺Transformer近期很有代表性的作業:
- 影像分類有:iGPT, ViT, DeiT, BiT-L等
- 目標檢測有:DETR
- 語意分割有:SETR, CMSA
- 醫學影像分割有:nnFormer[1](基于自注意力和卷積經驗組合的交錯架構), MedT[2], MISSFormer, TransUNet
- 影像增強(影像超分辨、影像復原)有:IPT[3], TTSR[4], SwinIR[5]
影像生成:iGPT[6], TransGAN[7]
[1] nnFormer: Interleaved Transformer for Volumetric Segmentation
代碼:https://github.com/282857341/nnFormer
論文:https://arxiv.org/abs/2109.03201
[2] Medical Transformer: Gated Axial-Attention for Medical Image Segmentation
github.com/jeya-maria-jose/Medical-Transformer
論文:https://arxiv.org/abs/2102.10662
[3] H. Chen, Y. Wang, T. Guo, C. Xu, Y. Deng, Z. Liu, S. Ma, C. Xu, C. Xu, and W. Gao, “Pre-trained image processing transformer,”arXiv preprint arXiv:2012.00364, 2020
https://arxiv.org/abs/2012.00364
https://github.com/huawei-noah/Pretrained-IPT
https://github.com/ryanlu2240/Pretrained_IPT
[4] F. Yang, H. Yang, J. Fu, H. Lu, and B. Guo, “Learning texture transformer network for image super-resolution,” in CVPR, 2020
https://arxiv.org/abs/2006.04139
https://github.com/researchmm/TTSR
[5]SwinIR: Image Restoration Using Swin Transformer
論文地址:https://arxiv.org/abs/2108.10257
專案地址:https://github.com/JingyunLiang/SwinIR
[6] Chen, Mark, et al. “Generative pretraining from pixels.” International Conference on Machine Learning. PMLR, 2020.
http://proceedings.mlr.press/v119/chen20s/chen20s.pdf
https://github.com/EugenHotaj/pytorch-generative/blob/master/pytorch_generative/models/autoregressive/image_gpt.py
[7]Y. Jiang, S. Chang, and Z. Wang, “Transgan: Two transformers can make one strong gan,” 2021
代碼:VITA-Group/TransGAN
論文:TransGAN: Two Transformers Can Make One Strong GAN
參考文獻
[1]. Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems. 2017.
[2]. Han, Kai, et al. “A survey on visual transformer.” arXiv preprint arXiv:2012.12556 (2020).
[3]. Khan, Salman, et al. “Transformers in vision: A survey.” arXiv preprint arXiv:2101.01169 (2021).
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/321486.html
標籤:其他