本文章為學習李宏毅老師視頻的學習筆記,視頻鏈接
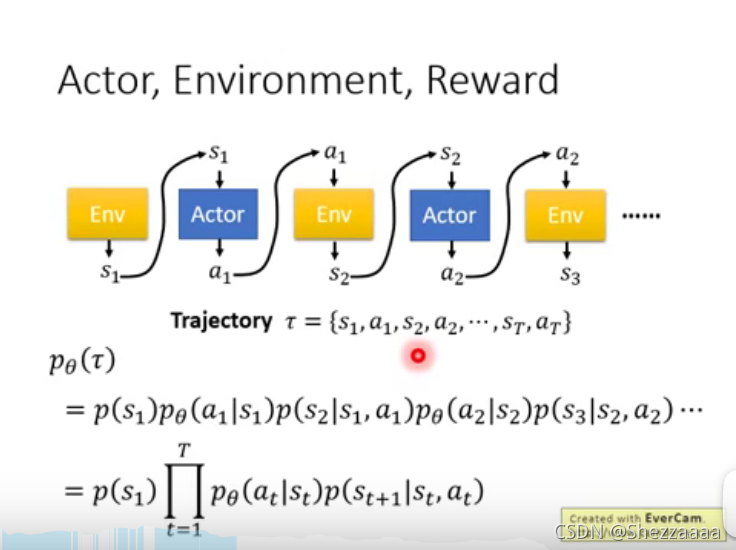
調整theta,就可以調整選擇trajectory的概率
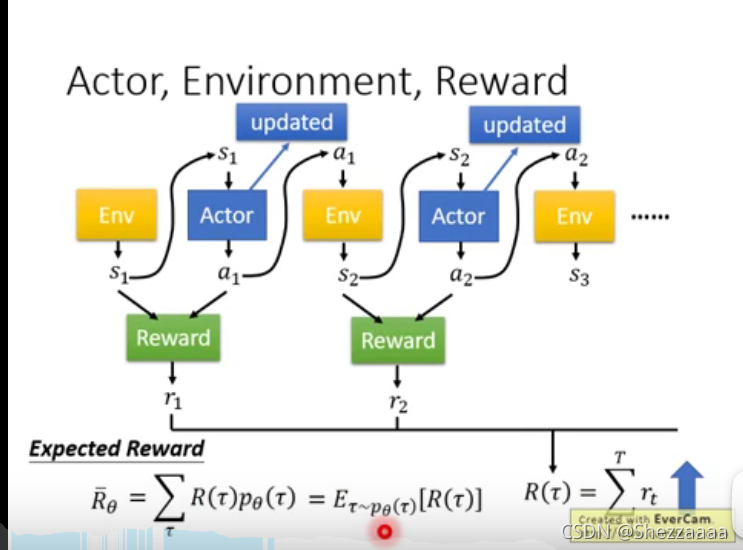
只能求出該路徑獎勵的期望值,方法是窮舉所有路徑并將獎勵值加和

這么復雜的推導,咱們就是說瞟一眼就可以了,就是求reward的梯度

theta更新程序,
η
\eta
η 是學習率
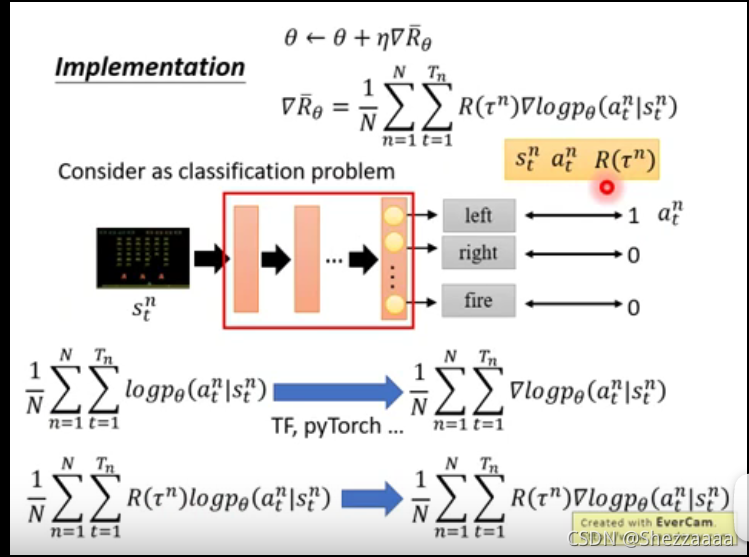
sample的概念,
R
(
τ
n
)
R(\tau ^n)
R(τn) 是整場游戲采取
a
a
a的獎勵

為了增加sample的正確率,可以將某些reward改為負,增添加baseline來實作,即
b
b
b,最簡單的方式即
b
=
E
(
R
(
τ
)
)
b=E(R(\tau))
b=E(R(τ))
講到45:48然后沒聽了,有緣再見家人們
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/323249.html
標籤:其他
上一篇:<2021SC@SDUSC>開源游戲引擎Overload代碼分析三(OvWindowing結束):OvWindowing——Dialogs