文章目錄
- 前言
- 1、什么是hadoop
- 2、Hadoop起源
- 3、Hadoop的四大特點
- 4、Hadoop的三大發行版本
- 5、Hadoop的版本迭代
- 6、Hadoop的優點及缺點
- 7、Hadoop組成
前言
上篇文章講述了大資料的發展及歷程,這篇文章就帶大家進入大資料的技術應用,以下文章觀點或描述如有錯誤,請指正!!
1、什么是hadoop
廣義:hadoop代表是大資料的一個技術生態圈,這個生態圈中包含其他很多的技術框架,
例如一下技術框架:
| Hadoop | HDFS+MapReduce+Yarn |
|---|---|
| Hive | 資料倉庫工具 |
| HBase | 海量列式非關系型資料庫 |
| Sqoop | ETL工具 |
| Kafka | 訊息中間件 |
| Flume | 資料采集工具 |
狹義:hadoop是一個分布式存盤和計算的框架平臺,
2、Hadoop起源
那么我們緊接著來說一下hadoop的發展歷程:
Hadoop起源于Apache Nutch專案,始于2002年,是Apache Lucene的子專案之一 ,2004年,Google在“作業系統設計與實作”(Operating System Design and Implementation,OSDI)會議上公開發表了題為MapReduce:Simplified Data Processing on Large Clusters(Mapreduce:簡化大規模集群上的資料處理)的論文之后,受到啟發的Doug Cutting等人開始嘗試實作MapReduce計算框架,并將它與NDFS(Nutch Distributed File System)結合,用以支持Nutch引擎的主要演算法 ,由于NDFS和MapReduce在Nutch引擎中有著良好的應用,所以它們于2006年2月被分離出來,成為一套完整而獨立的軟體,并被命名為Hadoop,到了2008年年初,hadoop已成為Apache的頂級專案,包含眾多子專案,被應用到包括Yahoo在內的很多互聯網公司
從上述程序中,我們可以清楚的了解到Hadoop最初的設計啟發來源于Nutch,而Nutch誕生于2002年,是一個開源Java實作的搜索引擎,其設計目標是花費很少的資金來配置世界一流的Web所有引擎,包括網頁抓取、索引、查詢等功能,但隨著抓取網頁數量的增加,遇到了嚴重的可擴展性問題——如何解決數十億網頁的存盤和索引問題,
2003年、2004年谷歌發表的兩篇論文為該問題提供了可行的解決方案,
- 分布式檔案系統(GFS),可用于處理海量網頁的存盤,
- 分布式計算框架MAPREDUCE,可用于處理海量網頁的索引計算問題,
Google的三篇論文(三駕馬車)
- GFS:Google的分布式檔案系統(Google File System)
- MapReduce:Google的分布式計算框架
- BigTable:大型分布式資料庫
發展演變關系:
- GFS :HDFS(分布式檔案系統)
- Google MapReduce : Hadoop MapReduce(分布式計算模型)
- BigTable : HBase (海量列式非關系型資料庫)
3、Hadoop的四大特點
Hadoop既然經過這么長時間的沉淀,那么它的特性有哪些呢?
- 擴容能力(Scalable):顧名思義hadoop作為分布式存盤和計算的框架平臺是在計算機集群內分配資料并行完成計算任務,而集群可以隨時擴展到成百上千個節點上,
- 低成本(Economical):Hadoop通過普通且廉價的機器組成服務器集群來分發以及處理資料,以至于成本很低,
- 高效率(Efficient):Hadoop可以在節點之間動態并行的移動資料,速度非常之快,
- 可靠性(Rellable):能自動維護資料的多份復制,并且可以在任務失敗后能自動的重新部署(redeploy)計算任務,所以說Hadoop的按位存盤和處理資料的能力值得信賴,
4、Hadoop的三大發行版本
- Apache Hadoop (最原始版本,所有的發行版均基于這個版本進行改進維護)
優點:擁有全世界的開源貢獻,代碼更新版本比較快,
缺點:版本的升級,版本的維護,以及版本之間的兼容性,學習非常方便,但是在實際的生產環境中盡量不要使用,
Apache所有軟體的下載地址(包括各種歷史版本):http://archive.apache.org/dist/ - 軟體收費版本ClouderaManager CDH (生產環境使用)
Cloudera主要是美國一家大資料公司在Apache開源Hadoop的版本上,通過自己公司內部的各種補丁,實作版本之間的穩定運行,大資料生態圈的各個版本的軟體都提供了對應的版本,解決了版本的升級困難,版本兼容性等各種問題,生產環境強烈推薦使用 - 免費開源版本HortonWorks HDP(生產環境使用)
hortonworks主要是雅虎主導Hadoop開發的副總裁,帶領二十幾個核心成員成立Hortonworks,核心產品軟體HDP(ambari),HDF免費開源,并且提供一整套的web管理界面,供我們可以通過web界面管理我們的集群狀態,web管理界面軟體HDF網址(http://ambari.apache.org/)
5、Hadoop的版本迭代
0.x 系列版本:Hadoop當中最早的一個開源版本,在此基礎上演變而來的1.x以及2.x的版本
1.x 版本系列:Hadoop版本當中的第二代開源版本,主要修復0.x版本的一些bug等
2.x 版本系列:架構產生重大變化,引入了yarn平臺等許多新特性
3.x 版本系列:EC技術、YARN的時間軸服務等新特性
| 組件 | Hadoop1.0 | Hadoop2.0 |
|---|---|---|
| HDFS | 存在單點故障問題,且資源不能進行隔離(后邊進行詳細介紹) | 設計了HA,提供了節點熱備 |
| MapReduce | 資源管理效率低下 | 設計了新的資源管理框架-YARN |
詳細版本之間的區別以及差異
6、Hadoop的優點及缺點
Hadoop的優點
- Hadoop具有存盤和處理資料能力的高可靠性,
- Hadoop通過可用的計算機集群分配資料,完成存盤和計算任務,這些集群可以方便地擴展到數以千計的節點中,具有高擴展性,
- Hadoop能夠在節點之間進行動態地移動資料,并保證各個節點的動態平衡,處理速度非常快,具有高效性,
- Hadoop能夠自動保存資料的多個副本,并且能夠自動將失敗的任務重新分配,具有高容錯性,
Hadoop的缺點
- Hadoop不適用于低延遲資料訪問,
- Hadoop不能高效存盤大量小檔案,
- Hadoop不支持多用戶寫入并任意修改檔案,
7、Hadoop組成
Hadoop = HDFS(分布式檔案系統)+MapReduce(分布式計算框架)+Yarn(資源協調框架)+Common模塊
- HDFS:一個高可靠、高吞吐量的分布式檔案系統(分而治之)
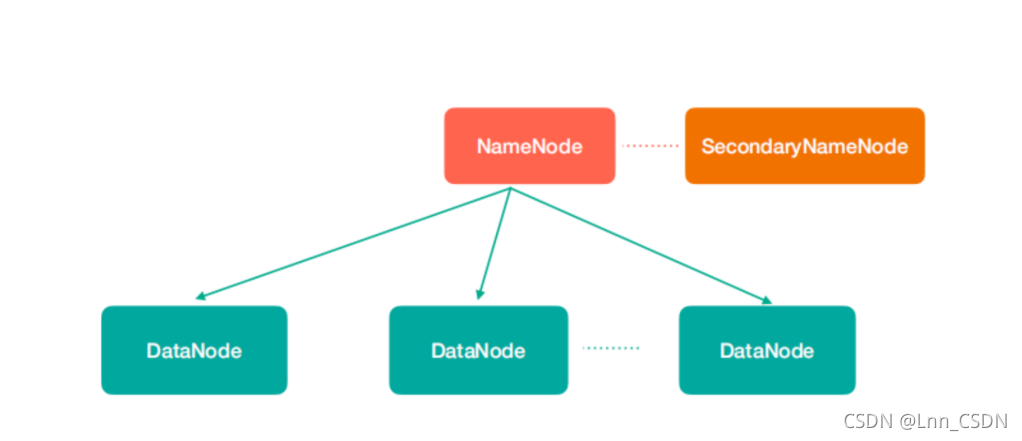
1、NameNode(nn):存盤檔案的元資料,比如檔案名、檔案目錄結構、檔案屬性(生成時間、副本數、檔案權限),以及每個檔案的塊串列和塊所在的DataNode等,
2、SecondaryNameNode(2nn):輔助NameNode更好的作業,用來監控HDFS狀態的輔助后臺程式,每隔一段時間獲取HDFS元資料快照,
3、DataNode(dn):在本地檔案系統存盤檔案塊資料,以及塊資料的校驗
注意:NN,2NN,DN這些既是角色名稱,行程名稱,代指電腦節點名稱!!
-
MapReduce:分布式離線并行計算框架
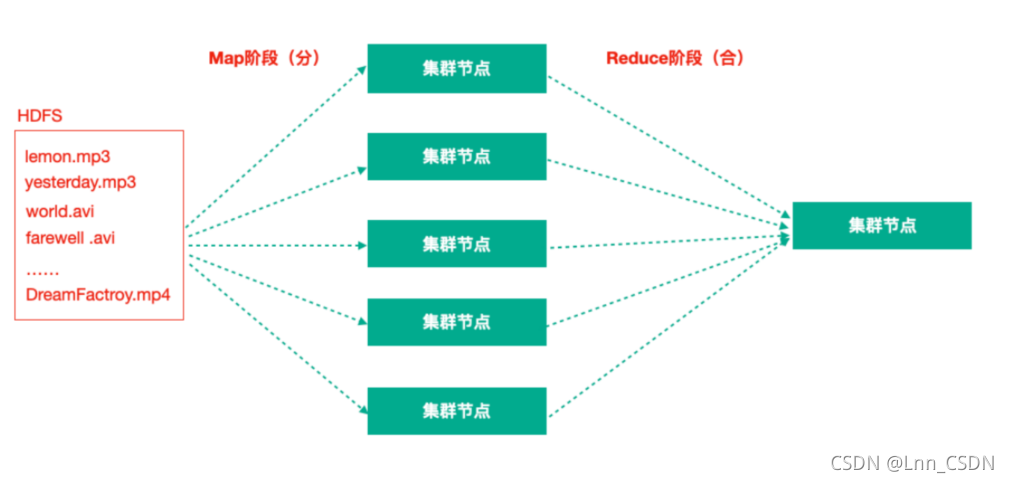
拆解任務、分散處理、匯整結果 MapReduce計算 = Map階段 + Reduce階段 Map階段就是“分”的階段,并行處理輸入資料; Reduce階段就是“合”的階段,對Map階段結果進行匯總; -
Yarn:作業調度于集群資源管理框架
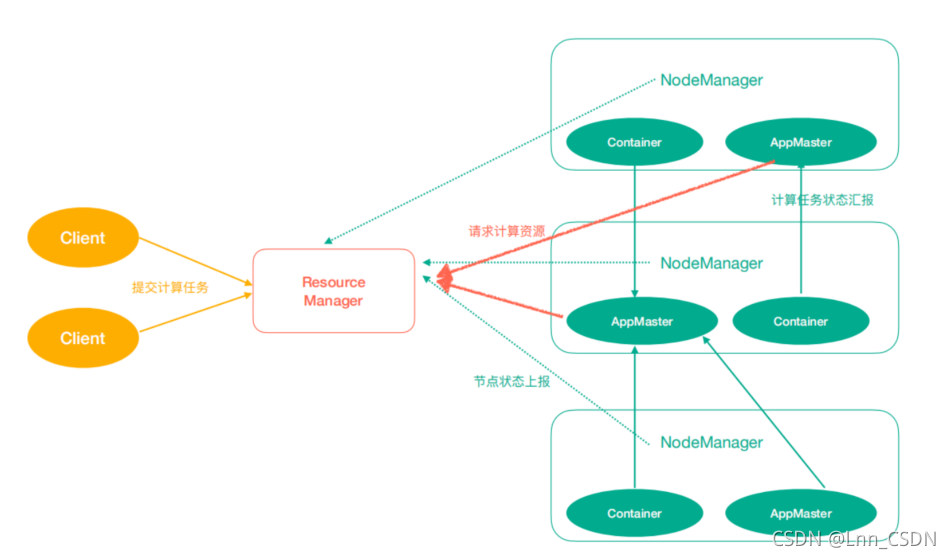
Yarn中有如下幾個主要角色,同樣,既是角色名、也是行程名,也指代所在計算機節點名稱,
1、ResourceManager(rm):處理客戶端請求、啟動/監控ApplicationMaster、監控NodeManager、資源分配與調度;
2、NodeManager(nm):單個節點上的資源管理、處理來自ResourceManager的命令、處理來自ApplicationMaster的命令;
3、ApplicationMaster(am):資料切分、為應用程式申請資源,并分配給內部任務、任務監控與容錯,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/323370.html
標籤:其他
上一篇:rabbitmq集群部署
下一篇:房屋中介管理系統