線性搜索方法
梯度下降
在我的文章深度學習中常見的優化器小結中已經提到梯度下降法,這里,將重要的部分提煉過來,
其計算方法是:
給定待優化模型引數
θ
∈
R
d
\theta \in R^d
θ∈Rd和目標函式
J
(
θ
)
J(\theta)
J(θ)后,演算法沿著梯度的相反方向更新
θ
\theta
θ來最小化
J
(
θ
)
J(\theta)
J(θ),學習率
η
\eta
η決定了每一時刻的更新步長,對于每一時刻t用以下步驟來說明梯度下降的流程:
(1)計算目標函式關于引數的梯度
g
t
=
?
θ
J
(
θ
)
g_t=\nabla_\theta J(\theta)
gt?=?θ?J(θ)
(2)更新模型引數
θ
t
+
1
=
θ
?
η
g
t
\theta_{t+1}=\theta-\eta g_t
θt+1?=θ?ηgt?
梯度下降與一階泰勒展開:
假設損失函式是
J
(
θ
)
J(\theta)
J(θ),對其做一階泰勒展開:
J
(
θ
)
=
J
(
θ
0
)
+
(
θ
?
θ
0
)
?
θ
J
(
θ
0
)
J(\theta) = J(\theta_0)+(\theta-\theta_0)\nabla_\theta J(\theta_0)
J(θ)=J(θ0?)+(θ?θ0?)?θ?J(θ0?)
假設,
θ
?
θ
0
=
λ
d
?
\theta-\theta_0=\lambda \vec d
θ?θ0?=λd
,其中
d
?
\vec d
d
是方向向量,
λ
\lambda
λ為標量,描述其長度,不難得出:
(
θ
?
θ
0
)
?
θ
J
(
θ
0
)
=
λ
∣
d
?
∣
∣
?
θ
J
(
θ
0
)
∣
c
o
s
(
α
)
(\theta-\theta_0)\nabla_\theta J(\theta_0) =\lambda |\vec d| |\nabla_\theta J(\theta_0)|cos(\alpha)
(θ?θ0?)?θ?J(θ0?)=λ∣d
∣∣?θ?J(θ0?)∣cos(α),這里的
α
\alpha
α是兩個向量的夾角,如果我們期望梯度下降的方向最大,那么易知,
d
?
\vec d
d
與梯度是反向的,則:
d
?
=
?
?
θ
J
(
θ
0
)
∣
∣
?
θ
J
(
θ
0
)
∣
∣
\vec d=\frac{-\nabla_\theta J(\theta_0)}{||\nabla_\theta J(\theta_0)||}
d
=∣∣?θ?J(θ0?)∣∣??θ?J(θ0?)?,
那么,我們有:
θ
?
θ
0
=
λ
d
?
=
λ
?
?
θ
J
(
θ
0
)
∣
∣
?
θ
J
(
θ
0
)
∣
∣
θ
=
θ
0
?
λ
∣
∣
?
θ
J
(
θ
0
)
∣
∣
?
θ
J
(
θ
0
)
\theta-\theta_0=\lambda \vec d = \lambda \frac{-\nabla_\theta J(\theta_0)}{||\nabla_\theta J(\theta_0)||} \\ \theta = \theta_0 - \frac{\lambda}{||\nabla_\theta J(\theta_0)||}\nabla_\theta J(\theta_0)
θ?θ0?=λd
=λ∣∣?θ?J(θ0?)∣∣??θ?J(θ0?)?θ=θ0??∣∣?θ?J(θ0?)∣∣λ??θ?J(θ0?)
也就得到了梯度下降的公式,
牛頓法
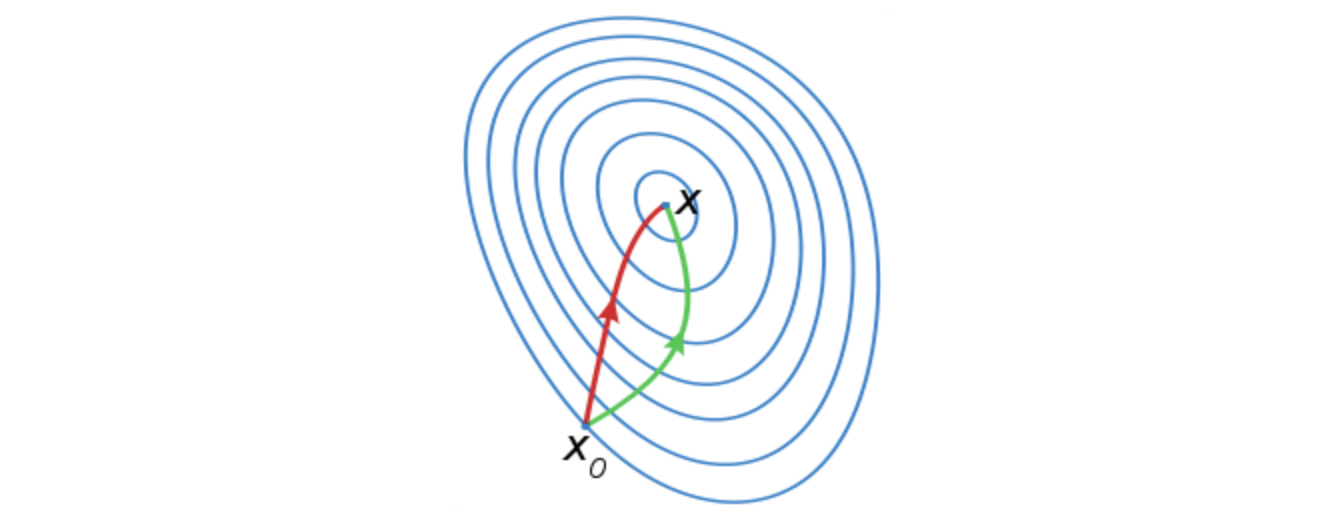
紅色的牛頓法的迭代路徑,綠色的是梯度下降法的迭代路徑,
從幾何的角度出發,牛頓法就是用一個二次曲面去擬合你當前所處位置的區域曲面,而梯度下降法是用一個平面去擬合當前的區域曲面,通常情況下,二次曲面的擬合會比平面更好,所以牛頓法選擇的下降路徑會更符合真實的最優下降路徑,
牛頓法是怎么推匯出來的呢?之前做梯度下降的時候我們對其進行了泰勒一階展開,那么這里我們對其進行二階展開,可得:
J
(
θ
)
=
J
(
θ
0
)
+
(
θ
?
θ
0
)
?
θ
J
(
θ
0
)
+
1
2
(
θ
?
θ
0
)
T
H
(
θ
0
)
(
θ
?
θ
0
)
J(\theta) = J(\theta_0)+(\theta-\theta_0)\nabla_\theta J(\theta_0)+\frac{1}{2}(\theta-\theta_0)^TH(\theta_0)(\theta-\theta_0)
J(θ)=J(θ0?)+(θ?θ0?)?θ?J(θ0?)+21?(θ?θ0?)TH(θ0?)(θ?θ0?)
我們想要在
θ
\theta
θ處取得極值點,那么只需要
?
θ
J
(
θ
)
=
0
\nabla_\theta J(\theta)=0
?θ?J(θ)=0,于是我們對上式求導,易得:
?
θ
J
(
θ
)
=
?
θ
J
(
θ
0
)
+
H
(
θ
0
)
(
θ
?
θ
0
)
=
0
\nabla_\theta J(\theta)=\nabla_\theta J(\theta_0)+H(\theta_0)(\theta-\theta_0)=0
?θ?J(θ)=?θ?J(θ0?)+H(θ0?)(θ?θ0?)=0
有:
θ
t
+
1
=
θ
t
?
H
t
?
1
g
t
\theta_{t+1}=\theta_t-H_t^{-1}g_t
θt+1?=θt??Ht?1?gt?
這就是牛頓法,
擬牛頓法
我們知道求解海瑟矩陣的逆是一個非常復雜的計算,考慮使用一個n階矩陣 G G G 替代 H ? 1 H^{-1} H?1 , 這就是擬牛頓法,
條件1:G 需要滿足正定矩陣:
從牛頓法可知:
θ
t
+
1
=
θ
t
?
H
t
?
1
g
t
\theta_{t+1}=\theta_t-H_t^{-1}g_t
θt+1?=θt??Ht?1?gt?
其實會在其中再增加一個學習率,也就是:
θ
t
+
1
=
θ
t
?
λ
H
t
?
1
g
t
θ
t
+
1
?
θ
t
=
?
λ
H
t
?
1
g
t
\theta_{t+1}=\theta_t-\lambda H_t^{-1}g_t \\ \theta_{t+1}-\theta_t=-\lambda H_t^{-1}g_t
θt+1?=θt??λHt?1?gt?θt+1??θt?=?λHt?1?gt?
帶入到一階泰勒展開式中,我們有:
J
(
θ
)
=
J
(
θ
0
)
?
λ
g
t
T
H
t
?
1
g
t
J(\theta) = J(\theta_0)-\lambda g_t^TH_t^{-1}g_t
J(θ)=J(θ0?)?λgtT?Ht?1?gt?
因為
H
?
1
H^{-1}
H?1正定,所以,
g
t
T
H
t
?
1
g
t
>
0
g_t^TH_t^{-1}g_t >0
gtT?Ht?1?gt?>0,易知
J
(
θ
)
<
J
(
θ
0
)
J(\theta) < J(\theta_0)
J(θ)<J(θ0?),
那么,要有一個
G
G
G去擬合
H
?
1
H^{-1}
H?1,顯然,他需要是正定的
條件2:
顯然,只有一個正定條件是不行的,首先牛頓法滿足這樣的性質:
?
θ
J
(
θ
)
=
?
θ
J
(
θ
0
)
+
H
(
θ
0
)
(
θ
?
θ
0
)
?
g
t
+
1
=
g
t
+
H
t
(
θ
t
+
1
?
θ
t
)
?
g
t
+
1
?
g
t
=
H
t
(
θ
t
+
1
?
θ
t
)
\nabla_\theta J(\theta)=\nabla_\theta J(\theta_0)+H(\theta_0)(\theta-\theta_0) \\ ? g_{t+1} = g_{t}+H_{t}(\theta_{t+1}-\theta_t) \\ ? g_{t+1}-g_t = H_t(\theta_{t+1}-\theta_t)
?θ?J(θ)=?θ?J(θ0?)+H(θ0?)(θ?θ0?)?gt+1?=gt?+Ht?(θt+1??θt?)?gt+1??gt?=Ht?(θt+1??θt?)
令
y
t
=
g
t
+
1
?
g
t
,
δ
t
=
θ
t
+
1
?
θ
t
y_{t}=g_{t+1}-g_t,\delta_{t}=\theta_{t+1}-\theta_t
yt?=gt+1??gt?,δt?=θt+1??θt?
y
t
=
H
t
δ
t
?
H
t
?
1
y
t
=
δ
t
y_{t}=H_t\delta_{t} \\ ? H_t^{-1}y_{t}=\delta_{t}
yt?=Ht?δt??Ht?1?yt?=δt?
成為擬牛頓條件,因此
G
t
G_t
Gt?需要滿足這樣的擬牛頓條件,則有:
G
t
y
t
=
δ
t
G_ty_t=\delta_t
Gt?yt?=δt?
我們希望有
G
t
+
1
=
G
t
+
Δ
G
t
G_{t+1}=G_t+\Delta G_t
Gt+1?=Gt?+ΔGt?,有以下兩種演算法:
DFP(Davidon-Fletcher-Powell)演算法(DFP algorithm)

BFGS(Broyden-Fletcher-Goldfard-Shano)演算法(BFGS algorithm):

置信域方法
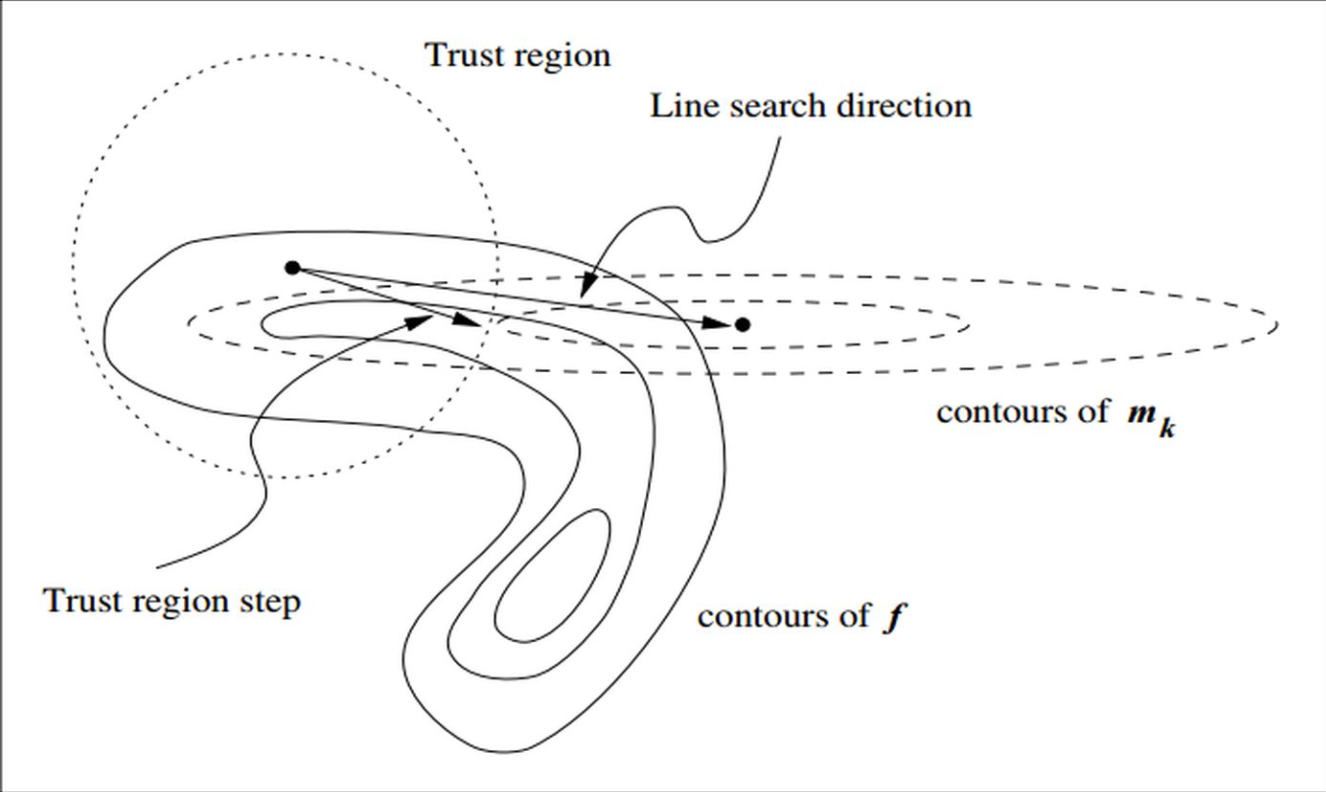
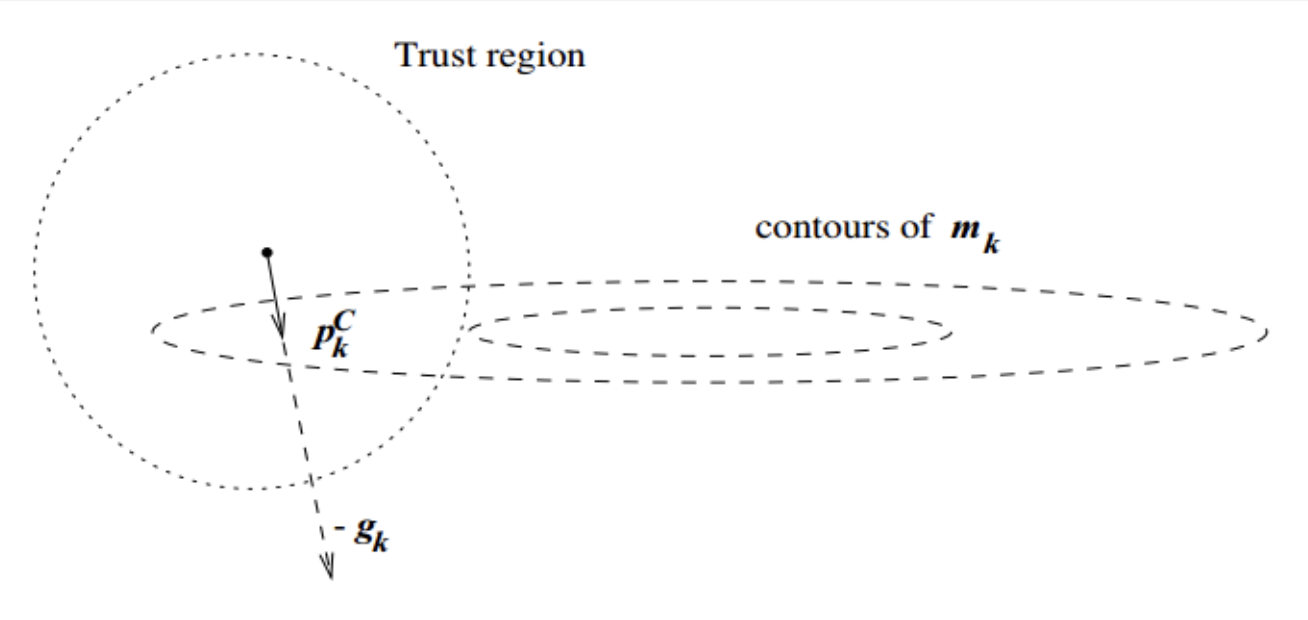
在信賴域方法的每次迭代中,先確定一個信賴域半徑,然后在該半徑內計算目標函式的二階近似的極小值,如果該極小值使得目標函式取得了充分的下降,則進入下一個迭代,并擴大信賴域半徑,如果該極小值不能令目標函式取得充分的下降,則說明當前信賴域區域內的二階近似不夠可靠,需要縮小信賴域半徑,重新計算極小值,如此迭代下去,直到滿足收斂所需的條件,我們結合上圖做進一步的解釋,
圖中,實線表示的是目標函式的等高線,虛線是泰勒二階近似的等高線:
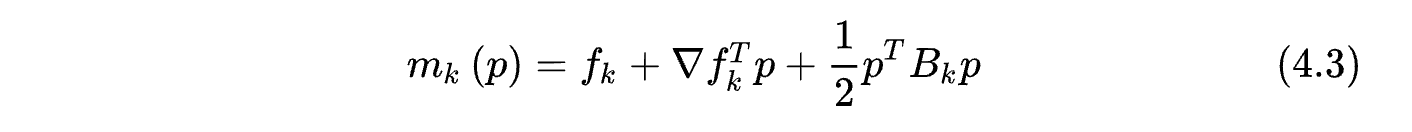
因為泰勒二階近似并不與目標函式完全相同,后面還有個高階無窮小的值,因此他們的等高線不相同,如果我們使用牛頓法,那么他就會走到
m
k
(
p
)
m_k(p)
mk?(p)的極值點,但從圖中不難看出,這個點根本沒有充分的下降,在信頼域內最好的步驟是Trust region step,這個點比牛頓法的結果要好很多(在該例下),
不過,這一現象比較依賴于信賴域半徑的選取,可以想象,如果信賴域半徑非常大,我們仍然會找到
m
k
(
p
)
m_k(p)
mk?(p) 的極小值點,但此時,這一步長是不能接受的,我們不會進入下一次迭代,而是要重新設定信賴域半徑,重新計算步長,那么步長是否可接受的條件是什么呢?定義變數
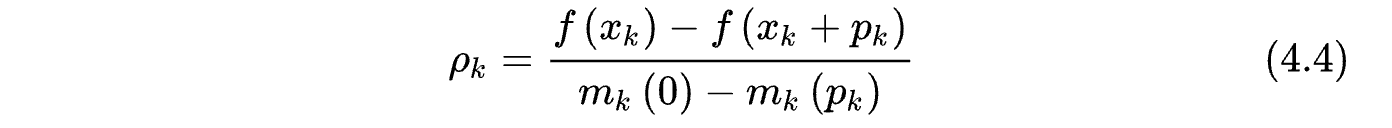
分母表示目標函式的二階近似的減小量,分子表示目標函式的減小量,如果結果接近于1,說明二階近似很接近目標函式,這一步長是可以接受的,如果結果接近于0甚至小于0,說明二階近似與真實的目標函式差距較大,我們需要減小信賴域半徑,并重新計算步長,
那么,問題只剩下,如何找到 m k ( p ) m_k(p) mk?(p)的極小值,這里只介紹Cauchy Point這一種方案,對Dogleg感興趣的同學可以看信頼域這篇文章,
柯西點(Cauchy Point):
這是一種近似求解的方法,固定
p
p
p方向是梯度下降的方向,沿著這個方向尋找極小值,有:
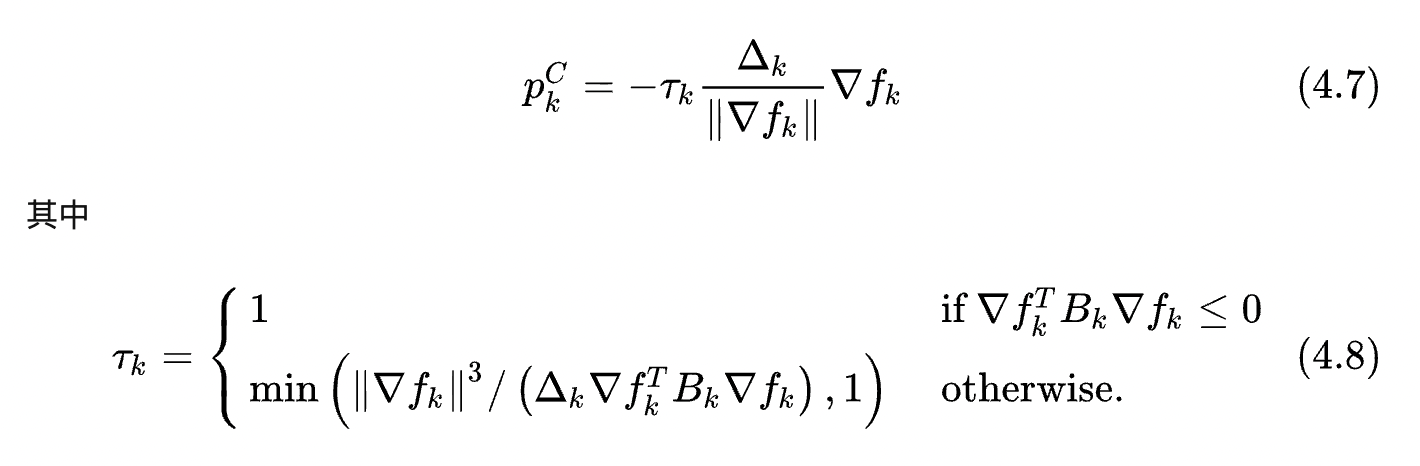
可以看出,步長為
τ
k
Δ
k
\tau_k\Delta_k
τk?Δk?,方向為負梯度方向,至于
τ
k
\tau_k
τk?的來源,可以直接將4.7的結果帶入4.3
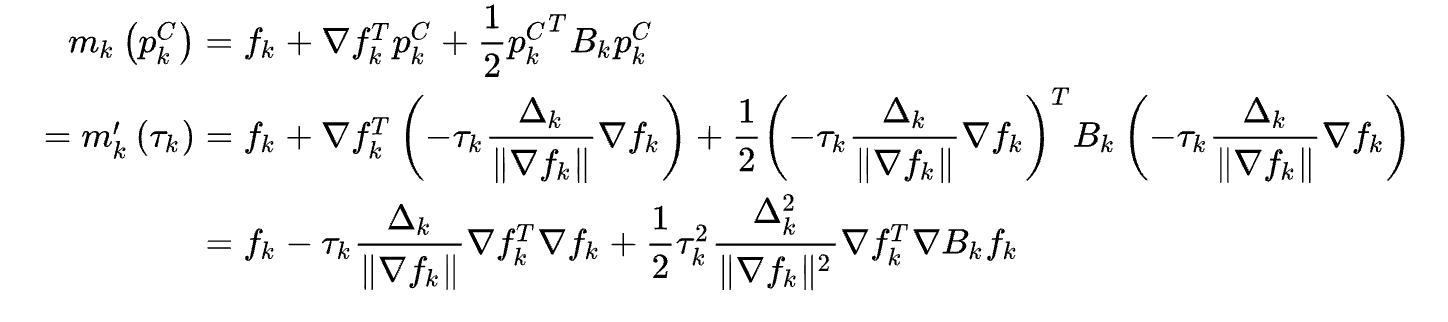

下面展示這種方法在例子中的效果:
啟發式演算法
在我的博文啟發式演算法中已經詳細的介紹了相關演算法,這里就不再贅述,
參考資料
梯度下降與一階泰勒展開的關系
李航:《統計學習方法》,清華大學出版社
梯度下降法、牛頓法和擬牛頓法
信頼域
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/325422.html
標籤:AI