目錄
一、基礎理論
優缺點
二、程序
1、對每張影像打格
2、損失函式
2-1、損失函式介紹
2-2、引數介紹
2-3、注意事項
一、基礎理論
步驟1:生成備選框,
步驟2:從備選框中找出物體邊框,

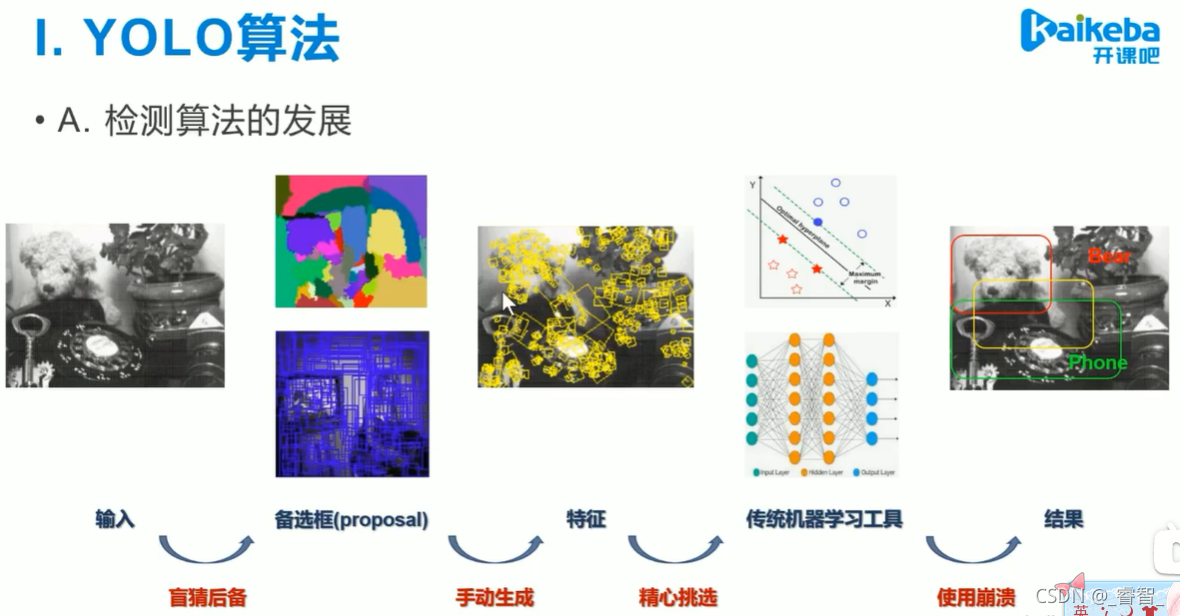
根據像素的突變,進行影像分割,分出不同物體,畫出不同顏色的區域,得到備選框(proposal),我們需要尋找的物體也在備選框中,我們需要把它從備選框中找出來,
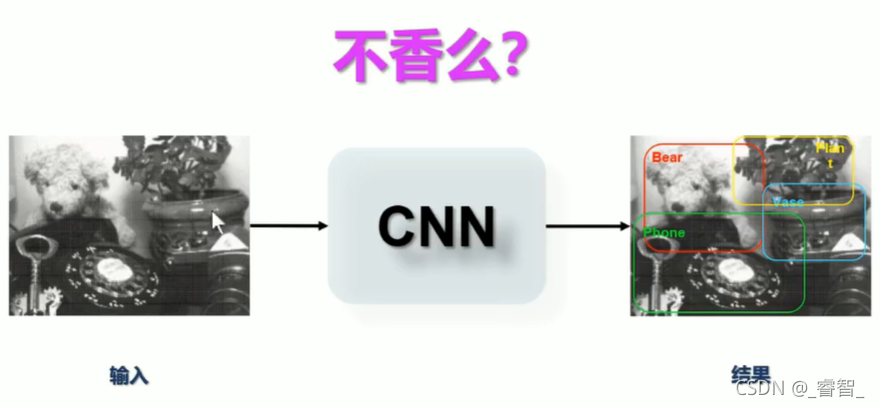
優缺點

二、程序
1、對每張影像打格
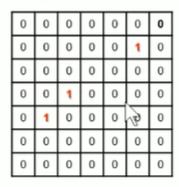
影像打格程序中,物體中心落在哪個格子,那個格子就負責預測哪個物體,

![]()

:預測框,(Yolo v1預測2個邊框,多預測幾個邊框,留下最好的那個)
:置信度(判斷是否靠譜)(考慮兩方面:(1)是某物體的概率;(2)重合的比例))
:是某物體的概率, (最后結果在0~1之間)
:交并比(重合部分越高,交并比越大)
得到的Bounding Box五維資料:x、y、w、h、confidence,(橫、縱坐標、寬、高、置信度)
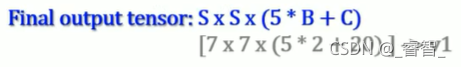 (B不一定得是2)
(B不一定得是2)
以上的五個資料分別為:width * height * (5維 * Box數量B + Confidence)
2、損失函式
由于上面有3個物體,所以獲取3個中心:
2-1、損失函式介紹
損失函式:坐標損失(Coordinate loss)、置信度損失(Confidence loss)、分類損失(Classification loss),
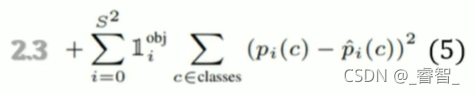
上述4個式子分別計算:坐標、 大小、物體、背景、分類概率的loss,
(這里)誤差 = 預測 - 真實
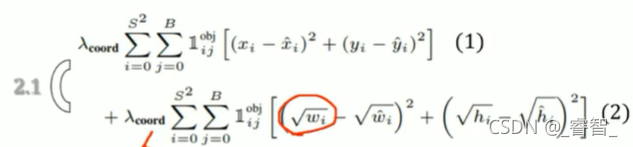
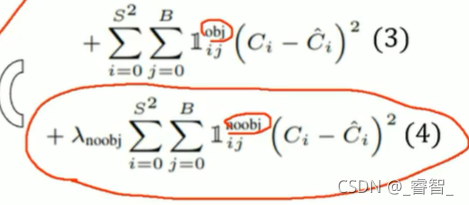
2-2、引數介紹

![]()
 (IoU:交并比)
(IoU:交并比)
object:學習物體: 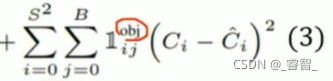
no object:學習背景: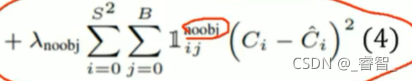
2-3、注意事項
注:
1、(2)式用根號壓縮物體的原因:
小物體和大物體的差距過大,盡可能壓縮減小差距,(不壓縮的話,loss會被大物體嚴重影響)
2、(4)式noobject(背景)原因:
增強泛化能力,除了要學習物體的資訊,我們還需要學習背景資訊(有時候背景中可能有和原物體比較像的物體,但不是原物體,為了加以區分)(學習非物體的東西,提高泛化能力),
3、(4)式加
的原因:
為了減小背景的權重,因為背景通常更大,實際物體更小,所以背景會產生更多的損失,這樣會導致網路去學習產生大loss的因素,即側重于學習背景,而忽略掉學習物體的特征,這不是我們想要的,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/327862.html
標籤:AI
上一篇:基于OpenCV的輪廓檢測