🍅 作者主頁:不吃西紅柿
🍅 簡介:CSDN博客專家、C站總榜第8🏆、HDZ核心組成員,歡迎點贊、收藏、評論
🍅 粉絲專屬福利:知識體系、面試題庫、技識訓助、簡歷模板,文末公眾號領取
🍅 包郵送書(每周1-2次):關注公眾號「資訊技術智庫」回復「送書」
目錄
文章總綱
一、大資料知識體系
大資料工程師必備技能
二、面試題庫
三、資料倉庫知識體系
耗時n年,38頁《資料倉庫知識體系.pdf》
下載PDF
四、mysql知識體系
五、spark知識體系
六、Flink知識體系
七、Python系列
文章總綱
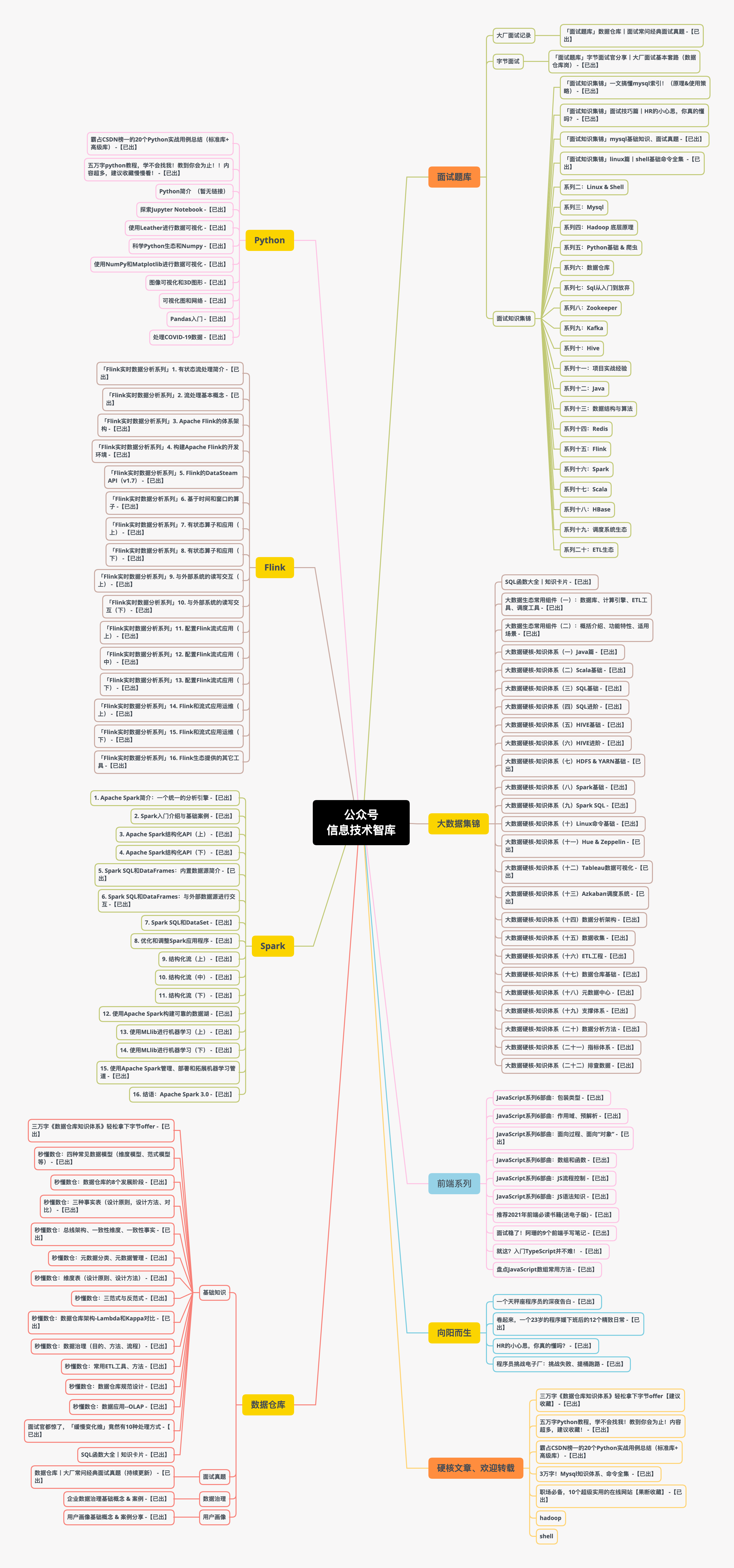
一、大資料知識體系
而大資料時代,有一個關鍵性的崗位不得不提,那就是大資料工程師,想必大家也會好奇,大資料工程師,日常是做什么的呢?
| 1.資料采集 | 找出描述用戶或對業務發展有幫助的資料,并將定義相關的資料格式,交由業務開發部門負責收集對應的資料, |
| 2.ETL工程 | 對收集到的資料,進行各種清洗、處理、轉化等操作,完成格式轉換,便于后續分析,保證資料質量,以便得出可以信賴的結果, |
| 3.構建數倉 | 將資料有效治理起來,構建統一的資料倉庫,讓資料與資料間建立連接,碰撞出更大的價值, |
| 4.資料建模 | 基于已有的資料,梳理資料間的復雜關系,建立恰當的資料模型,便于分析出有價值的結論, |
| 5.統計分析 | 對資料進行各種維度的統計分析,建立指標體系,系統性地描述業務發展的當前狀態,尋找業務中的問題,發現新的優化點與增長點, |
| 6.用戶畫像 | 基于用戶的各方面資料,建立對用戶的全方位理解,構建每個特定用戶的畫像,以便針對每個個體完成精細化運營, |
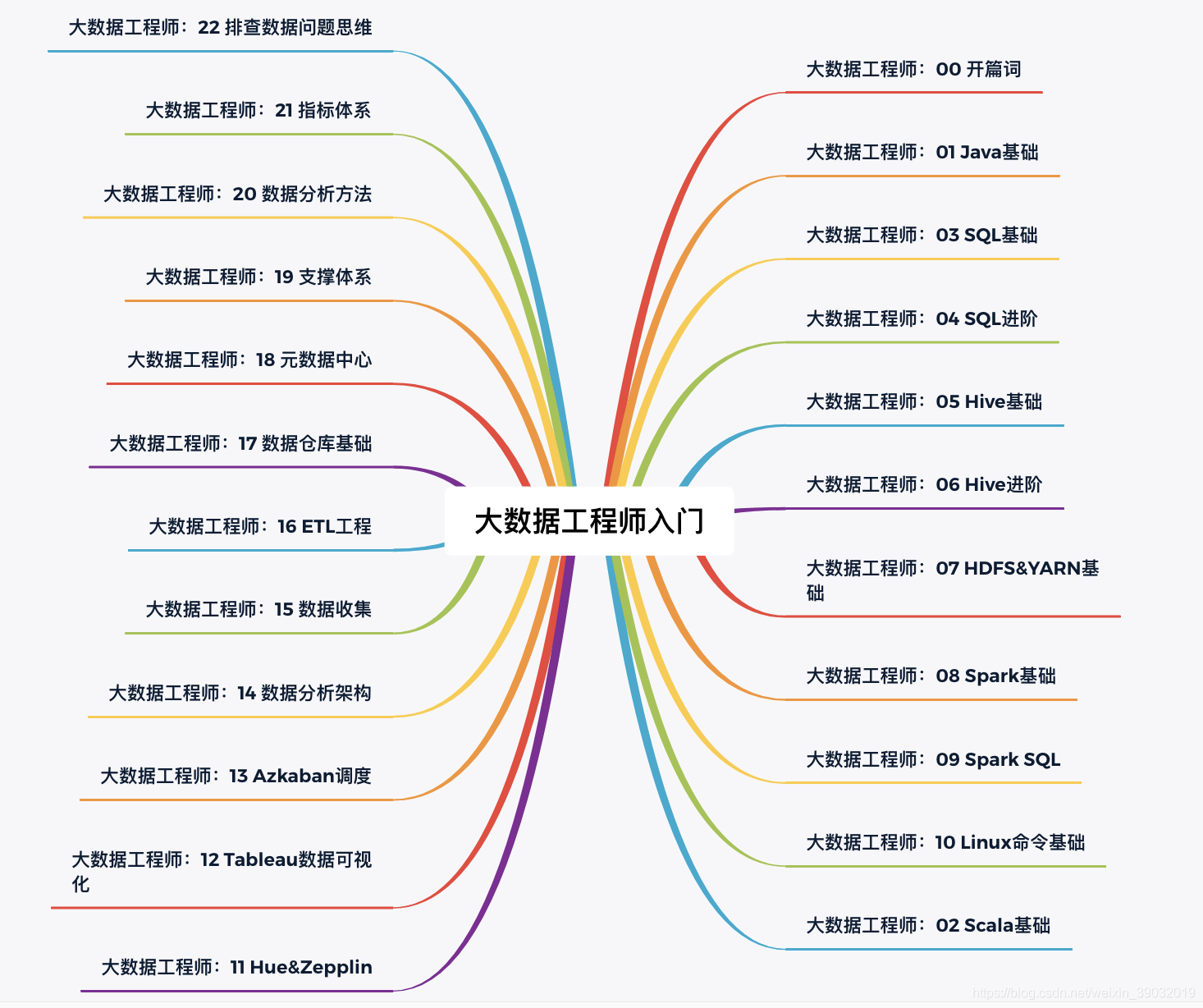
大資料工程師必備技能
| 分類 | 子分類 | 技能 | 描述 |
| 技 術 能 力 | 編程基礎 | Java基礎 | 大資料生態必備的java基礎 |
| Scala基礎 | Spark相關生態的必備技能 | ||
| SQL基礎 | 資料分析師的通用語言 | ||
| SQL進階 | 完成復雜分析的必備技能 | ||
| 大資料框架 | HDFS&YARN | 大資料生態的底層基石 | |
| Hive基礎 | 大資料分析的常用工具 | ||
| Hive進階 | 大資料分析師的高級裝備 | ||
| Spark基礎 | 排查問題必備的底層運行原理 | ||
| Spark SQL | 應對復雜任務的利刃 | ||
| 工具 | Hue&Zeppelin | 通用的探索分析工具 | |
| Azkaban | 作業管理調度平臺 | ||
| Tableau | 資料可視化平臺 | ||
| 業務基礎 | 資料收集 | 資料是如何收集到的? | |
| ETL工程 | 怎么清洗、處理和轉化資料? | ||
| 資料倉庫基礎 | 如何完成面向分析的資料建模? | ||
| 元資料中心 | 如何做好資料治理? | ||
| 分析思維 | 資料分析思維方法論 | 怎么去分析一個具體問題? | |
| 排查問題思維 | 如何高效排查資料問題? | ||
| 指標體系 | 怎么讓資料成體系化? | ||
二、面試題庫
注意:本系列文的目的不是為了面試取巧,而是通過一些經典的面試題,交流技術觀點、提升技術理解、解決作業難題,
查看全部文章搜:資訊技術智庫
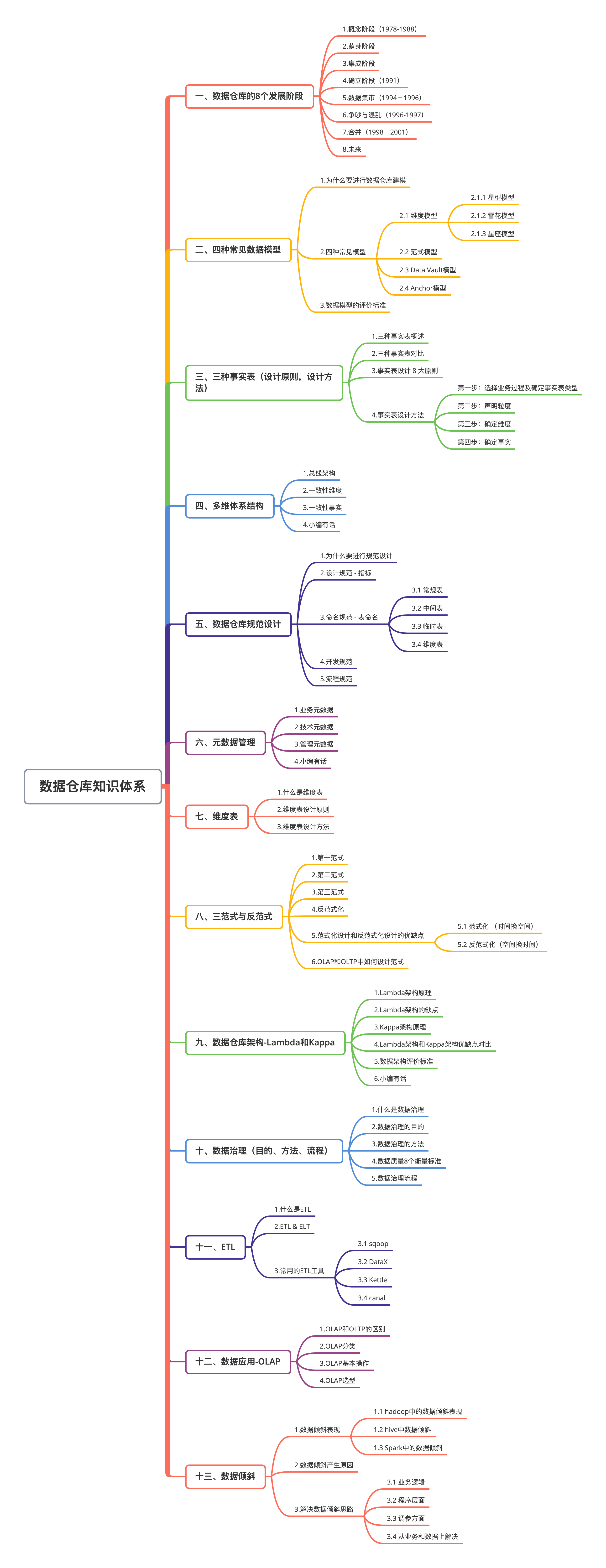
三、資料倉庫知識體系
耗時n年,38頁《資料倉庫知識體系.pdf》
擁有本篇文章,意味著你擁有一本完善的書籍,本篇文章整理了資料倉庫領域,幾乎所有的知識點,文章內容主要來源于以下幾個方面:
- 源于「資料倉庫交流群」資深資料倉庫工程師的交流討論,如《sql行轉列的千種寫法》,
- 源于群友面試大廠遇到的面試真題,整理投稿給我,形成《面試題庫》,
- 源于筆者在系統學習程序中整理的筆記和一點理解,
- 源于技術網站的優質文章和高贊答案,
下載PDF
【下載鏈接】:https://pan.baidu.com/s/1FZrr2pzh1QHGV12D3yjwBg
【提取碼】:98b3
四、mysql知識體系
五、spark知識體系
六、Flink知識體系

七、Python系列

文章鏈接
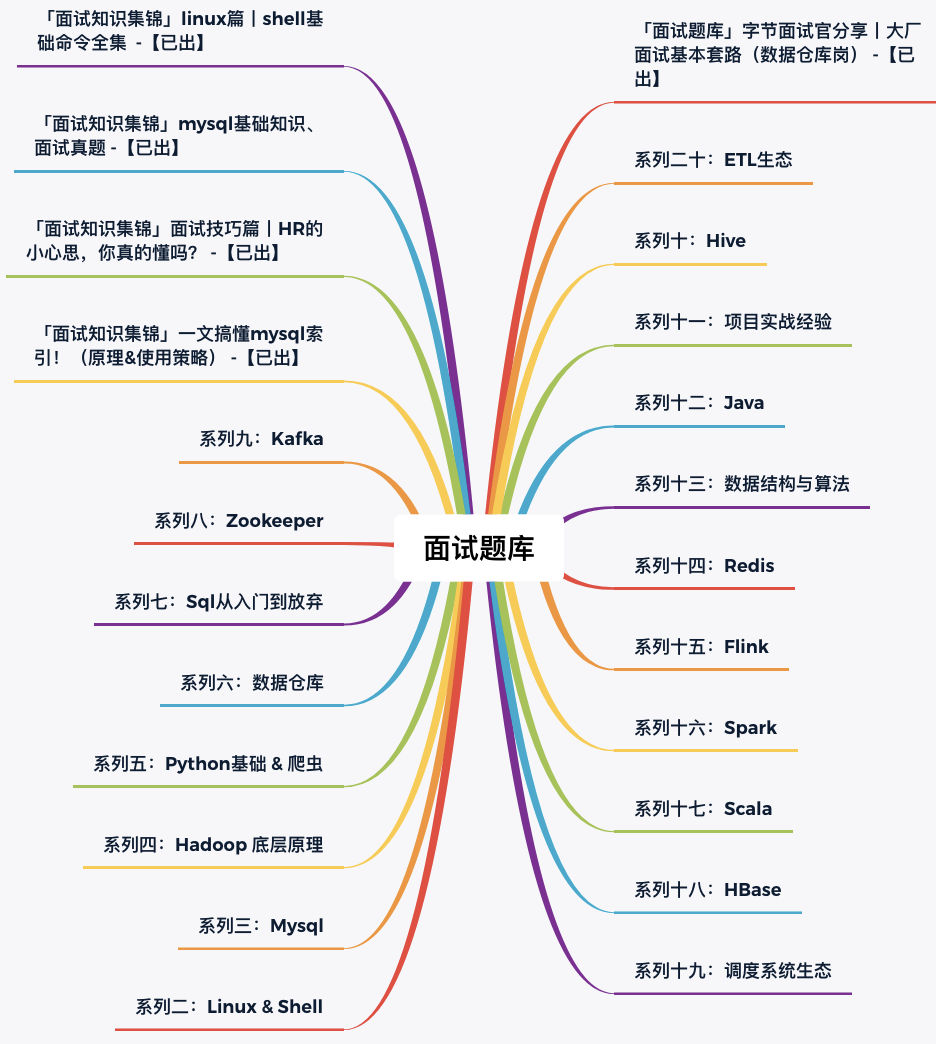
面試知識集錦
-
「面試知識集錦」一文搞懂mysql索引!(原理&使用策略)
-
「面試知識集錦」面試技巧篇丨HR的小心思,你真的懂嗎?
-
「面試知識集錦」mysql基礎知識、面試真題
-
「面試知識集錦」linux篇丨shell基礎命令全集,我奶奶的速查手冊!!
更新中系列:
系列一:面試技巧
系列二:Linux & Shell
系列三:Mysql
系列四:Hadoop 底層原理
系列五:Python基礎 & 爬蟲
系列六:資料倉庫
系列七:Sql從入門到放棄
系列八:Zookeeper
系列九:Kafka
系列十:Hive
系列十一:專案實戰經驗
系列十二:Java
系列十三:資料結構與演算法
系列十四:Redis
系列十五:Flink
系列十六:Spark
系列十七:Scala
系列十八:HBase
系列十九:調度系統生態
系列二十:ETL生態
大資料集錦
-
SQL函式大全丨知識卡片
-
大資料生態常用組件(一):資料庫、計算引擎、ETL工具、調度工具
-
大資料生態常用組件(二):概括介紹、功能特性、適用場景
-
大資料硬核-知識體系(一)Java篇
-
大資料硬核-知識體系(二)Scala基礎
-
大資料硬核-知識體系(三)SQL基礎
-
大資料硬核-知識體系(四)SQL進階
-
大資料硬核-知識體系(五)HIVE基礎
-
大資料硬核-知識體系(六)HIVE進階
-
大資料硬核-知識體系(七)HDFS & YARN基礎
-
大資料硬核-知識體系(八)Spark基礎
-
大資料硬核-知識體系(九)Spark SQL
-
大資料硬核-知識體系(十)Linux命令基礎
-
大資料硬核-知識體系(十一)Hue & Zeppelin
-
大資料硬核-知識體系(十二)Tableau資料可視化
-
大資料硬核-知識體系(十三)Azkaban調度系統
-
大資料硬核-知識體系(十四)資料分析架構
-
大資料硬核-知識體系(十五)資料收集
-
大資料硬核-知識體系(十六)ETL工程
-
大資料硬核-知識體系(十七)資料倉庫基礎
-
大資料硬核-知識體系(十八)元資料中心
-
大資料硬核-知識體系(十九)支撐體系
-
大資料硬核-知識體系(二十)資料分析方法
-
大資料硬核-知識體系(二十一)指標體系
-
大資料硬核-知識體系(二十二)排查資料
資料倉庫
基礎知識
-
🍅 三萬字《資料倉庫知識體系》輕松拿下位元組offer【建議收藏】
-
秒懂數倉:四種常見資料模型(維度模型、范式模型等)
-
秒懂數倉:資料倉庫的8個發展階段
-
秒懂數倉:三種事實表(設計原則,設計方法、對比)
-
秒懂數倉:總線架構、一致性維度、一致性事實
-
秒懂數倉:元資料分類、元資料管理
-
秒懂數倉:維度表(設計原則、設計方法)
-
秒懂數倉:三范式與反范式
-
秒懂數倉:資料倉庫架構-Lambda和Kappa對比
-
秒懂數倉:資料治理(目的、方法、流程)
-
秒懂數倉:常用ETL工具、方法
-
秒懂數倉:資料倉庫規范設計
-
秒懂數倉:資料應用--OLAP
-
面試官都驚了,「緩慢變化維」竟然有10種處理方式
-
SQL函式大全丨知識卡片
面試真題
-
資料倉庫丨大廠常問經典面試真題(持續更新)
資料治理
-
企業資料治理基礎概念 & 案例
用戶畫像
-
用戶畫像基礎概念 & 案例分享
Spark
-
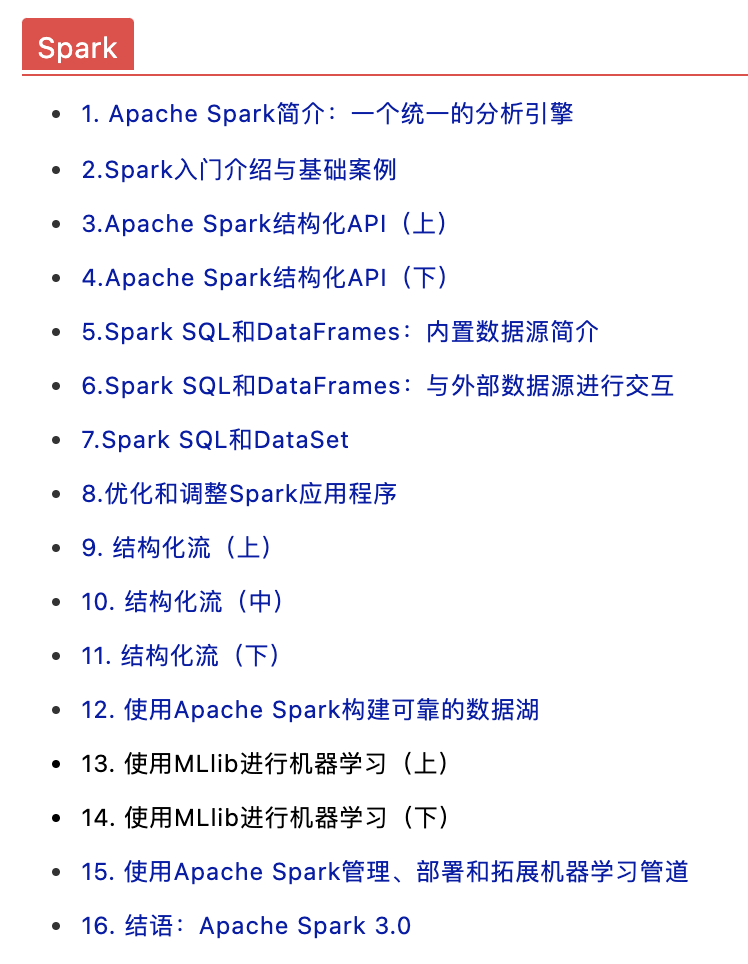
1. Apache Spark簡介:一個統一的分析引擎
-
2.Spark入門介紹與基礎案例
-
3.Apache Spark結構化API(上)
-
4.Apache Spark結構化API(下)
-
5.Spark SQL和DataFrames:內置資料源簡介
-
6.Spark SQL和DataFrames:與外部資料源進行互動
-
7.Spark SQL和DataSet
-
8.優化和調整Spark應用程式
-
9. 結構化流(上)
-
10. 結構化流(中)
-
11. 結構化流(下)
-
12. 使用Apache Spark構建可靠的資料湖
-
13. 使用MLlib進行機器學習(上)
-
14. 使用MLlib進行機器學習(下)
-
15. 使用Apache Spark管理、部署和拓展機器學習管道
-
16. 結語:Apache Spark 3.0
Flink
-
「Flink實時資料分析系列」1. 有狀態流處理簡介
-
「Flink實時資料分析系列」2. 流處理基本概念
-
「Flink實時資料分析系列」3. Apache Flink的體系架構
-
「Flink實時資料分析系列」4. 構建Apache Flink的開發環境
-
「Flink實時資料分析系列」5. Flink的DataSteam API(v1.7)
-
「Flink實時資料分析系列」6. 基于時間和視窗的算子
-
「Flink實時資料分析系列」7. 有狀態算子和應用(上)
-
「Flink實時資料分析系列」8. 有狀態算子和應用(下)
-
「Flink實時資料分析系列」9. 與外部系統的讀寫互動(上)
-
「Flink實時資料分析系列」10. 與外部系統的讀寫互動(下)
-
「Flink實時資料分析系列」11. 配置Flink流式應用(上)
-
「Flink實時資料分析系列」12. 配置Flink流式應用(中)
-
「Flink實時資料分析系列」13. 配置Flink流式應用(下)
-
「Flink實時資料分析系列」14. Flink和流式應用運維(上)
-
「Flink實時資料分析系列」15. Flink和流式應用運維(下)
-
「Flink實時資料分析系列」16. Flink生態提供的其它工具
-
Flink 基礎知識
前端系列
-
JavaScript系列6部曲:包裝型別
-
JavaScript系列6部曲:作用域、預決議
-
JavaScript系列6部曲:面向程序、面向“物件”
-
JavaScript系列6部曲:陣列和函式
-
JavaScript系列6部曲:JS流程控制
-
JavaScript系列6部曲:JS語法知識
-
推薦2021年前端必讀書籍(送電子版)
-
面試穩了!阿珊的9個前端手寫筆記
-
就這?入門TypeScript并不難!
-
盤點JavaScript陣列常用方法
Python
-
霸占CSDN榜一的20個Python實戰用例總結(標準庫+高級庫)
-
五萬字python教程,學不會找我!教到你會為止!!內容超多,建議收藏慢慢看!
-
Python簡介 (暫無鏈接)
-
探索Jupyter Notebook
-
使用Leather進行資料可視化
-
科學Python生態和Numpy
-
使用NumPy和Matplotlib進行資料可視化
-
影像可視化和3D圖形
-
可視化圖和網路
-
Pandas入門
-
處理COVID-19資料

添加公眾號「資訊技術智庫」:
🍅 硬核資料:20G,8大類資料,關注即可領取(PPT模板、簡歷模板、技術資料)
🍅 技識訓助:技術群大佬指點迷津,你的問題可能不是問題,求資源在群里喊一聲,
🍅 面試題庫:由各個技術群小伙伴們共同投稿,熱乎的大廠面試真題,持續更新中,
🍅 知識體系:含編程語言、演算法、大資料生態圈組件(Mysql、Hive、Spark、Flink)、資料倉庫、前端等,
👇👇送書抽獎丨技識訓助丨粉絲福利👇👇
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/327863.html
標籤:AI
上一篇:Yolo(1)Yolo v1