論文題目:Learning Deep Features for Discriminative Localization
(Class Activation Mapping)
論文地址:https://arxiv.org/pdf/1512.04150.pdf
完整代碼:https://github.com/metalbubble/CAM
—————————————————————————————————
論文研讀
問題:
1.以前的全監督的CNN方法,會進行標簽標注,導致浪費大量的人力與時間成本,
2.全連接層
a) 全連接層被用作分類,所以導致在此層的定位能力丟失(卷積神經網路的全連接層會將最后一層的特征圖拉平來和全連接層相連,這樣破壞了空間位置資訊就破壞了,而全域平均池化層不需要破話空間結構),
b) 全連接層有大量引數,計算成本高,
主要貢獻:
1.使用弱監督目標定位
2.CNN內部表示的可視化
流程圖:
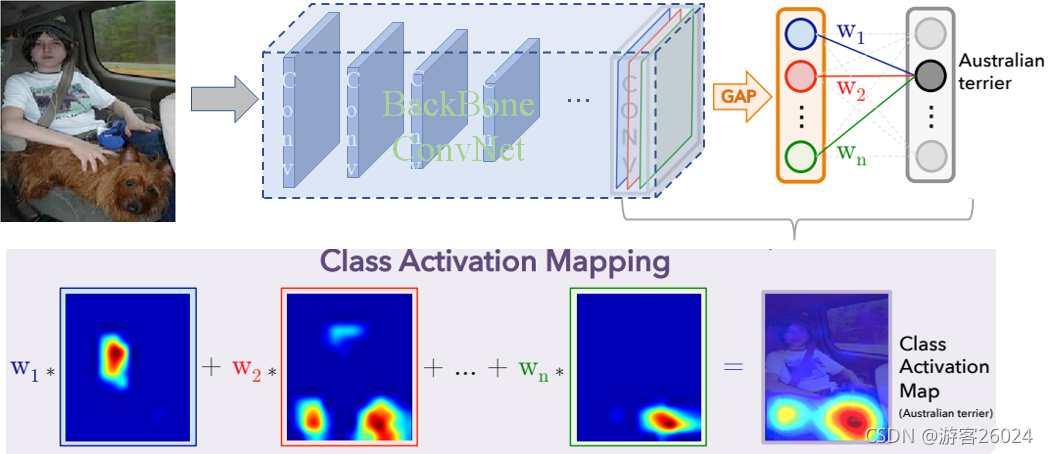 方法:
方法:


使用全域平均池化GAP(Global Average Pooling)與GMP(Global Max Pooling)的區別:
GMP能夠幫助卷積神經網路找到一個不同的區域,而GAP則能夠精確的找到目標在影像中的范圍,對于GAP來說,所有較高的值都會對整體訓練有比較大的貢獻(取平均值),對于GMP來說,只有最大值的那個點會產生貢獻,作者在ImageNet 上測驗了兩種全域池化方式,發現分類結果相近,但是定位的結果GAP遠遠超過GMP,

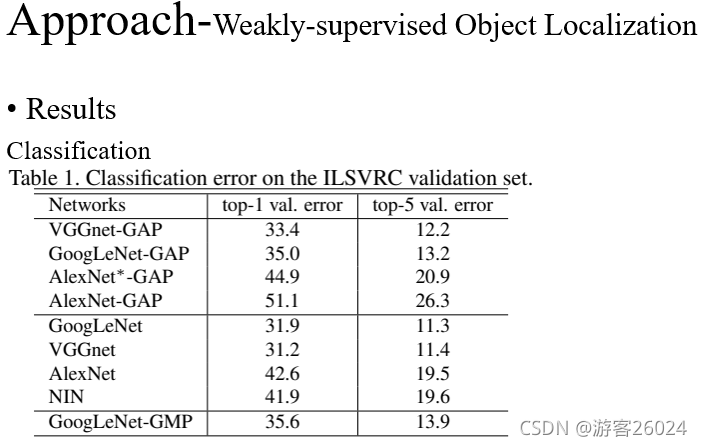
從表1可得,我們的分類error相對于使用全連接層的error來說,相差1-2個百分點,比如VGGnet 31.2 top1 error vs VGGnet-GAP 33.4 top1 error| AlexNet 42.6 top1 error vs AlexNet*-GAP 44.9 top1 error (加*代表在替換fc層之后,又增加2層卷積層,再加了GAP層),我們GAP的分類結果相比與GMP分類來說,效果更好(理由如上),
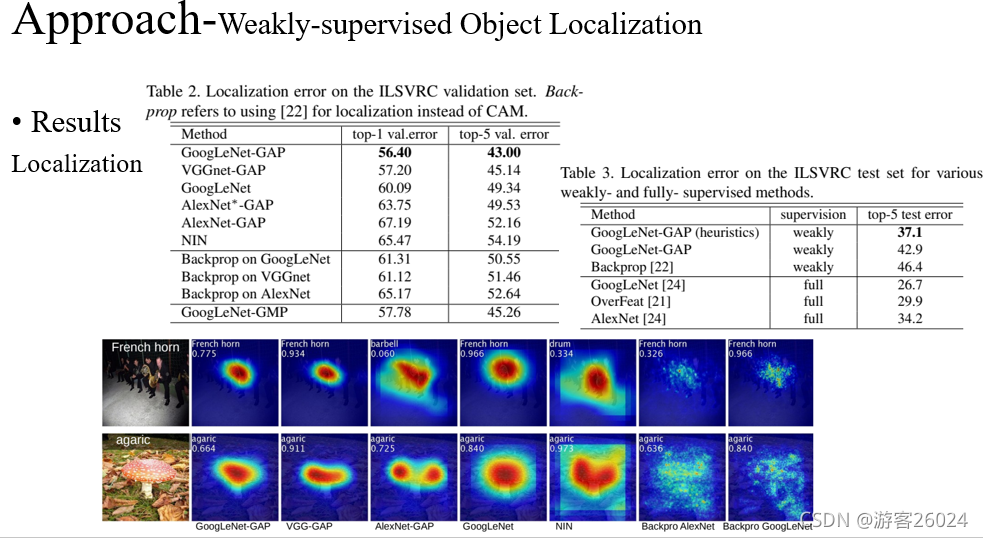
從表2可得,我們使用全域平均池化的方法定位 比 反向傳播的CNN方法定位、全域最大池化的方法定位 效果更好,其中GoogLeNet-GAP最佳為56.40 top1 error | 43.00 top5 error
從表3可得,我們使用的弱監督定位方法 比 全監督定位方法 想過更好,其中GoogLeNet-GAP(啟發式 [修改了 bbox] ) 為 37.1 top5 error
上圖表示,每個BackBone 生成的不同定位方法,使用熱力圖展示,其中BackBone的VGG-GAP效果最好,

從圖6可得,其中在原圖上現實的綠框為Ground Truth,紅框為預測的結果,a)為使用BackBone(GooLeNet-GAP)的結果,b)為GoogLeNet-GAP(upper two)與 the backpropagation using AlexNet (lower two)的結果,
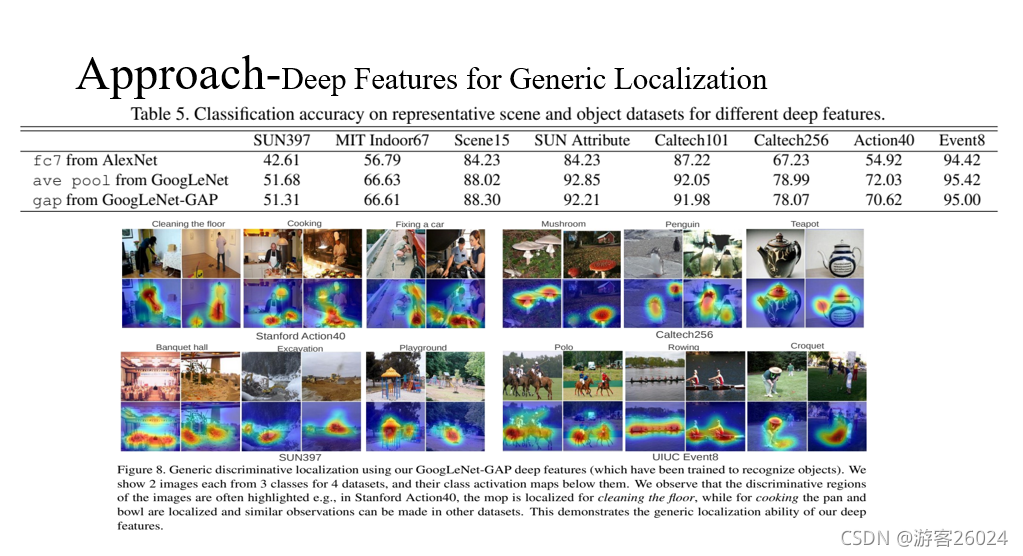
從表5可得,使用不同的資料集與BackBone產生的精度結果,
從圖8可得,使用不同資料集與GoogLeNet-GAP產生的定位結果,
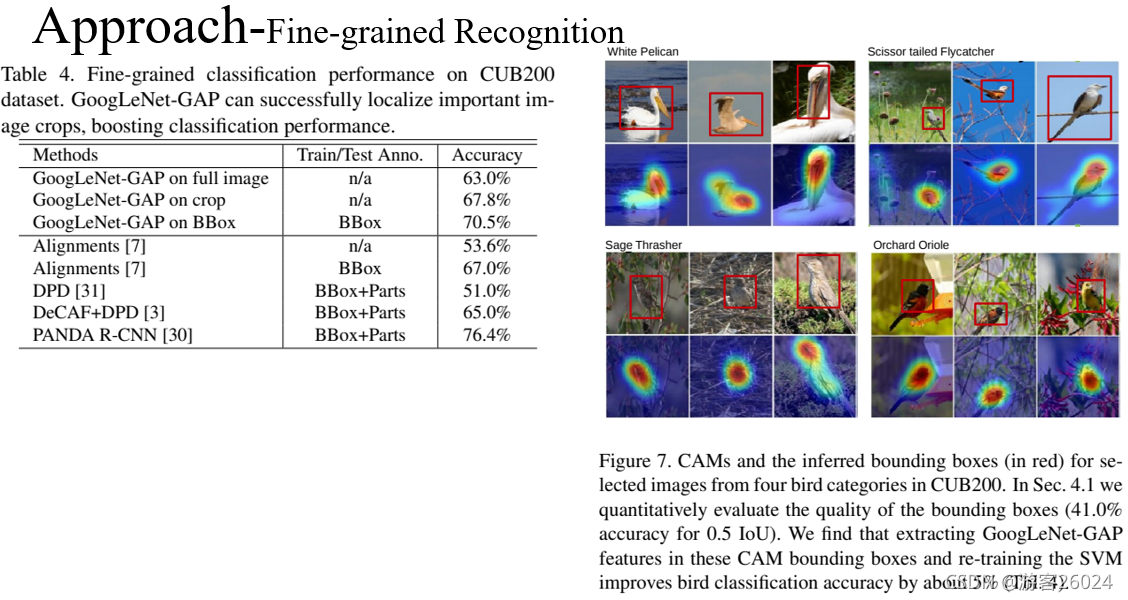
從表4可得,在CUB200資料集與GoogLeNet-GAP產生的細粒度分類性能,并能成功定位重要影像區域,
從圖7可得,使用弱監督定位方法產生的bbox,

從圖9可得,不同場景下的帶資訊的目標效果,

從圖10可得,在弱標簽影像的概念定位(鏡子、湖等),

從圖11可得,弱監督文本檢測的結果,

從圖12可得,影像問答的定位結果,

從圖13可得,特殊類別單元的可視化,Mask結果,
—————————————————————————————————
代碼復現
import os
import cv2
from PIL import Image
from torchvision import models, transforms
from torch.autograd import Variable
from torch.nn import functional as F
import numpy as np
from torchvision.models.densenet import densenet161
import json
# input image
# 使用本地的圖片與本地的標簽
labels_file = 'imagenet-simple-labels.json'
image_path = "31.jpg"
# networks such as Googlenet, ResNet,Densent already use global average pooling at the end,
# so CAM could be used directly.
# 選擇使用的網路
model_id = 2
# 選擇網路
if model_id == 1:
net = models.squeezenet1_1(pretrained=True)
finalconv_name = 'features'
elif model_id == 2:
net = models.resnet18(pretrained=True)
finalconv_name = 'layer4'
elif model_id == 3:
net = densenet161()
finalconv_name = "features"
# 有固定引數作用,如norm的引數
net.eval()
# 獲取特定層的feature map
# hook the feature extractor
features_blobs = []
def hook_feature(module, input, output):
features_blobs.append(output.data.cpu().numpy())
net._modules.get(finalconv_name).register_forward_hook(hook_feature)
# get the softmax weight
# 倒數第二層
params = list(net.parameters()) # 將引數變換為串列
weight_softmax = np.squeeze(params[-2].data.numpy()) # 提取softmax層的引數
# 生成CAM圖的函式,完成權重和feature相乘操作
def returnCAM(feature_conv, weight_softmax, class_idx):
# generate the class activation maps upsample to 256x256
size_upsample = (256, 256)
bc, nc, h, w = feature_conv.shape
output_cam = []
# class_idx為預測分數較大的類別數字表示的陣列,一張圖片中有N個類物體,則陣列中N個元素
for idx in class_idx:
# 回到GAP的值
# weight_softmax中預測為第idx類的引數w乘以feature_map,為了相乘reshape map的形狀
cam = weight_softmax[idx].dot(feature_conv.reshape(nc, h * w))
#將feature_map的形狀reshape回去
cam = cam.reshape(h, w)
# 歸一化操作(最小值為0,最大值為1)
# np.min 回傳陣列的最小值或沿軸的最小值
cam = cam - np.min(cam)
cam_img = cam / np.max(cam)
# 轉換為圖片255的資料
# np.uint8() Create a data type object.
cam_img = np.uint8(255 * cam_img)
# resize 圖片尺寸與輸入圖片一致
output_cam.append(cv2.resize(cam_img, size_upsample))
return output_cam
# 資料處理,先縮放尺寸到(224,224),再變換資料型別為tensor,最后normalize
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
preprocess = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
normalize
])
image_path = os.path.expanduser(image_path)
img_pil = Image.open(image_path)
img_pil.save('test.jpg')
# 將圖片資料處理成所需要的可用資料 tensor
img_tensor = preprocess(img_pil)
# 處理圖片為Variable資料
img_variable = Variable(img_tensor.unsqueeze(0))
#將圖片輸入網路得到預測類別分數
logit = net(img_variable)
# 分類標簽串列,并存盤在classes(數字類別,類別名稱)
with open(labels_file) as f:
classes = json.load(f)
# 使用softmax打分
h_x = F.softmax(logit, dim=1).data.squeeze()
# 對分類的預測類別分數排序,輸出預測值和在串列中的位置
probs, idx = h_x.sort(0, True)
# 轉換資料型別
probs = probs.numpy()
idx = idx.numpy()
# 輸出預測分數排名在前5個類別的預測分數和對應的類別名稱
for i in range(0, 5):
print('{:.3f} -> {}'.format(probs[i], classes[idx[i]]))
# 輸出與圖片尺寸一致的CAM圖片
# generate class activation mapping for the top1 prediction
CAMs = returnCAM(features_blobs[0], weight_softmax, [idx[0]])
# render the CAM and output
print("output CAM.jpg")
# 將圖片和CAM拼接在一起展示定位結果
img = cv2.imread("31.jpg")
height, width, _ = img.shape
# 生成熱力圖
heatmap = cv2.applyColorMap(cv2.resize(CAMs[0], (width, height)), cv2.COLORMAP_JET)
result = cv2.addWeighted(img, 0.3, heatmap, 0.5, 0)
cv2.imwrite('CAM.jpg', result)
cv2.imshow("heatmap", result)
cv2.waitKey(0)
cv2.destroyAllWindows()
注意:
1.本地標簽的下載 點擊我
2.使用殘差網路作為BackBone,效果更好
效果展示
原圖:
 ___________________________________________________________
___________________________________________________________
CAM熱力圖展示:
 ___________________________________________________________
___________________________________________________________
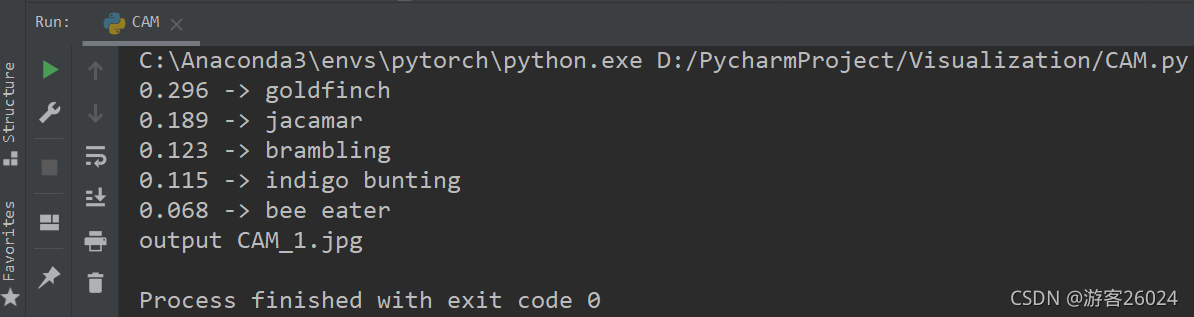
控制臺現實最大的前五個類別的置信度:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/328228.html
標籤:其他