1. 摘要
在OCR處理檔案時,經常會遇到自然拍照場景中由于光照強度不一、拍攝角度不同、相機成像元件差異,因此會導致拍攝的圖片與掃描檔案存在較大區別,為使檔案文字內容更加鮮明,便于后續特征提取,本文目標是對檔案在自然拍照場景下文字與文字背景分離,本文介紹并基于opencv實作了三種文字背景分離方法,最大最小濾波、全域閾值、區域自適應閾值方法,通過實驗驗證得到區域自適應閾值更適合自然照場景圖片文字背景分離的結論,
2. 方法
主要介紹最大最小濾波、全域濾波(閾值、大津法)、區域自適應閾值方法,
2.1 最大最小值濾波
首先要排序周圍像素和中心像素值,然后將中心像素值與最小和最大像素值比較,如果比最小值小,則替換中心像素為最小值,如果中心像素比最大值大,則替換中心像素為最大值,代碼可參考鏈接:python實作影像陰影去除_lowl的博客-CSDN博客:
def max_filter(image,filter_size):
# padding操作,在最大濾波中需要在原影像周圍填充(filter_size//2)個小的數字,一般取-1
# 先生成一個全為-1的矩陣,大小和padding后的影像相同
empty_image = np.full((image.shape[0] + (filter_size // 2) * 2, image.shape[1] + (filter_size // 2) * 2), -1)
# 將原影像填充進矩陣
empty_image[(filter_size // 2):empty_image.shape[0] - (filter_size // 2),
(filter_size // 2):empty_image.shape[1] - (filter_size // 2)] = image.copy()
# 創建結果矩陣,和原影像大小相同
result = np.full((image.shape[0], image.shape[1]), -1)
# 遍歷原影像中的每個像素點,對于點,選取其周圍(filter_size*filter_size)個像素中的最大值,作為結果矩陣中的對應位置值
for h in range(filter_size // 2, empty_image.shape[0]-filter_size // 2):
for w in range(filter_size // 2, empty_image.shape[1]-filter_size // 2):
filter = empty_image[h - (filter_size // 2):h + (filter_size // 2) + 1,
w - (filter_size // 2):w + (filter_size // 2) + 1]
result[h-filter_size // 2, w-filter_size // 2] = np.amax(filter)
return result
def min_filter(image,filter_size):
# padding操作,在最大濾波中需要在原影像周圍填充(filter_size//2)個大的數字,一般取大于255的
# 先生成一個全為-1的矩陣,大小和padding后的影像相同
empty_image = np.full((image.shape[0] + (filter_size // 2) * 2, image.shape[1] + (filter_size // 2) * 2), 400)
# 將原影像填充進矩陣
empty_image[(filter_size // 2):empty_image.shape[0] - (filter_size // 2),
(filter_size // 2):empty_image.shape[1] - (filter_size // 2)] = image.copy()
# 創建結果矩陣,和原影像大小相同
result = np.full((image.shape[0], image.shape[1]), 400)
# 遍歷原影像中的每個像素點,對于點,選取其周圍(filter_size*filter_size)個像素中的最小值,作為結果矩陣中的對應位置值
for h in range(filter_size // 2, empty_image.shape[0]-filter_size // 2):
for w in range(filter_size // 2, empty_image.shape[1]-filter_size // 2):
filter = empty_image[h - (filter_size // 2):h + (filter_size // 2) + 1,
w - (filter_size // 2):w + (filter_size // 2) + 1]
result[h-filter_size // 2, w-filter_size // 2] = np.amin(filter)
return result
def remove_shadow(image_path):
image = cv2.imread(image_path, 0)
max_result=max_filter(image,30)
min_result=min_filter(max_result,30)
result=image-min_result
result=cv2.normalize(result, None, 0, 255, norm_type=cv2.NORM_MINMAX)
return result
if __name__ == '__main__':
#方法:最大最小值濾波
gray = remove_shadow('xxx.jpg')
cv2.imwrite("./xxx_out1.jpg",gray)2.2 全域閾值法
全域閾值主要有閾值法和大津法,閾值法由于影像灰度值受到很多因素影響,不同影像閾值不同,分離效果極大程度受到人工干預,不做過多介紹,大津法針對每幅影像直方圖自動計算全域閾值,在opencv有代碼可以直接呼叫,代碼參考如下:
#方法:大津法
gray = cv2.imread('xxx.jpg',0)
_, gray = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU)
cv2.imwrite("./xxx_out2.jpg",gray)2.3 區域自適應閾值法
區域自適應閾值考慮了影像在不同區域具有不同照明條件時,應進行自適應閾值處理,該演算法為同一影像的不同區域獲得不同的閾值,并且它為具有不同照明的影像提供了更好的結果,在opencv中代碼可以直接呼叫,代碼參考如下:
#方法:區域最適應濾波
gray = cv2.imread('xxx.jpg', 0)
th = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 21, 10)
th = cv2.boxFilter(th,-1,(1,1),normalize=False)
cv2.imwrite("./xxx_out3.jpg", th)在區域自適應閾值方法中,上述引數較適合大多數1080P的圖片處理,
3.實驗
三種方法對比效果如下:
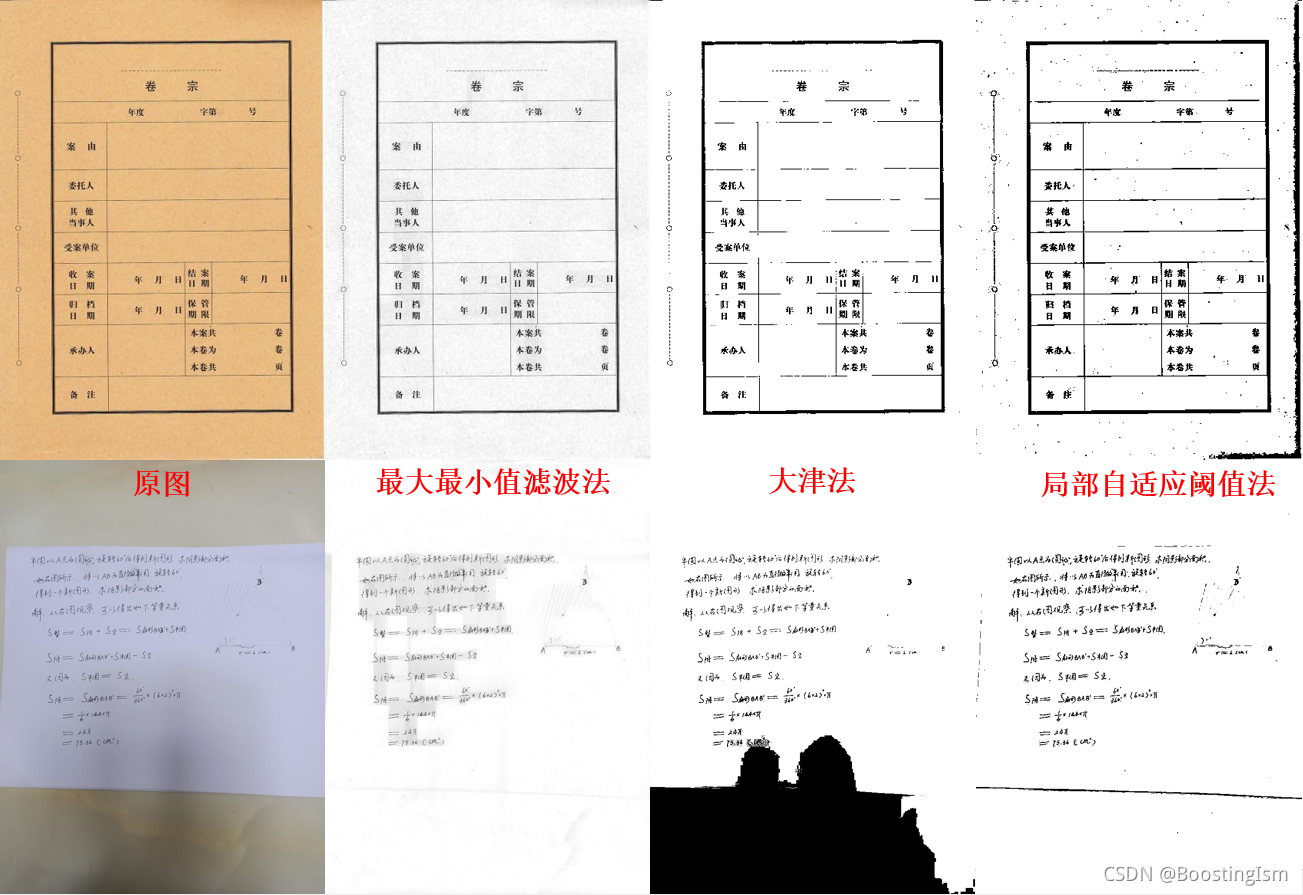
最大最小值濾波法不能完全去除背景,需要后續的閾值二值化操作,但單靠最大最小值濾波不能完全實作文字背景分離效果,大津法在影像有陰影的情況下提取效果差,區域自適應閾值法在文字背景分離任務中,適用場景更加豐富,
4. 總結
最大最小值濾波法適合只去除背景不二值化提取文本的情況,
大津法適合光照漸變差異小、無陰影的檔案,這些檔案圖片在影像直方圖中表現為有雙峰特征(背景、文字分別為峰值),
區域自適應閾值法在圖片梯度變化劇烈,如手機拍攝電腦時產生的莫爾條紋,處理得到的效果較差,適用于拍照場景圖片轉掃描印刷圖片等此類功能需求,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/328229.html
標籤:其他
下一篇:影像處理——輪廓檢測