語意分割網路對影像中的每個像素進行分類,從而對影像進行分割,語意分割的應用包括用于自動駕駛的道路分割和用于醫療診斷的癌細胞分割,本文展示了如何使用 MATLAB 訓練語意分割網路 Deeplab v3+,實作了自動駕駛場景下的全景分割,
本例使用劍橋大學的CamVid資料集進行訓練,這個資料集是一個影像集合,包含駕駛時獲得的街道視圖,該資料集提供了32個語意類的像素級標簽,包括汽車、行人和道路,如下圖所示:

文章目錄
- 一、下載預訓練模型
- 二、資料集準備
- 1、資料集下載
- 2、加載 CamVid 影像
- 3、創建影像、標簽資料存盤
- 4、劃分資料集
- 二、創建 Deeplab v3+ 網路
- 1、引數初始化
- 2、創建網路
- 三、訓練網路
- 1、使用類權重來平衡類
- 2、設定訓練選項
- 3、開始訓練
- 四、全景分割測驗
一、下載預訓練模型
這個例子創建了Deeplab v3+網路,權值由預先訓練的Resnet-18網路初始化,ResNet-18是一個高效的網路,非常適合處理資源有限的應用程式,根據應用需求,還可以使用其他預先訓練過的網路,如MobileNet v2或ResNet-50,
使用ResNet-18前,需要打開附加功能資源管理器,并點擊安裝Deep Learning Toolbox Model for ResNet-18 Network,
安裝完后,可以開始下載預訓練模型:
if ~exist('pretrainedNetwork/deeplabv3plusResnet18CamVid.mat','file')
disp('Downloading pretrained network (58 MB)...');
pretrainedURL = 'https://www.mathworks.com/supportfiles/vision/data/deeplabv3plusResnet18CamVid.mat';
websave('pretrainedNetwork/deeplabv3plusResnet18CamVid.mat', pretrainedURL);
end
二、資料集準備
1、資料集下載
本次實驗使用的是CamVid資料集,下面我們進行下載和解壓:
imageURL = 'http://web4.cs.ucl.ac.uk/staff/g.brostow/MotionSegRecData/files/701_StillsRaw_full.zip';
labelURL = 'http://web4.cs.ucl.ac.uk/staff/g.brostow/MotionSegRecData/data/LabeledApproved_full.zip';
outputFolder = 'CamVid';
labelsZip = fullfile(outputFolder,'labels.zip');
imagesZip = fullfile(outputFolder,'images.zip');
if ~exist(outputFolder,'file')
mkdir(outputFolder);
end
if ~exist(labelsZip, 'file')
disp('Downloading 16 MB CamVid dataset labels...');
websave(labelsZip, labelURL);
disp('Complete Download CamVid dataset labels!');
unzip(labelsZip, fullfile(outputFolder,'labels'));
disp('Complete Unzip CamVid dataset labels!');
end
if ~exist(imagesZip,'file')
disp('Downloading 557 MB CamVid dataset images...');
websave(imagesZip, imageURL);
disp('Complete Download CamVid dataset images!');
unzip(imagesZip, fullfile(outputFolder,'images'));
disp('Complete Unzip CamVid dataset images!');
end
2、加載 CamVid 影像
imgDir = fullfile(outputFolder,'images');
imds = imageDatastore(imgDir);
Img = readimage(imds,559);
Img = histeq(Img);
imshow(Img)
3、創建影像、標簽資料存盤
classes = [
"Sky"
"Building"
"Pole"
"Road"
"Pavement"
"Tree"
"SignSymbol"
"Fence"
"Car"
"Pedestrian"
"Bicyclist"
];
% 標簽轉換
labelIDs = camvidPixelLabelIDs();
% 使用類和標簽id創建pixelLabelDatastore
labelDir = fullfile(outputFolder,'labels');
pxds = pixelLabelDatastore(labelDir,classes,labelIDs);
4、劃分資料集
[imdsTrain, imdsVal, pxdsTrain, pxdsVal] = partitionCamVidData(imds, pxds);
二、創建 Deeplab v3+ 網路
1、引數初始化
% 輸入影像尺寸
imageSize = [720 960 3];
% 類別數
numClasses = numel(classes);
2、創建網路
% Create DeepLab v3+.
lgraph = deeplabv3plusLayers(imageSize, numClasses, "resnet18");
三、訓練網路
1、使用類權重來平衡類
tbl = countEachLabel(pxds);
imageFreq = tbl.PixelCount ./ tbl.ImagePixelCount;
classWeights = median(imageFreq) ./ imageFreq;
pxLayer = pixelClassificationLayer('Name','labels','Classes',tbl.Name,'ClassWeights',classWeights);
lgraph = replaceLayer(lgraph,"classification",pxLayer);
2、設定訓練選項
dsVal = combine(imdsVal,pxdsVal);
dsTrain = combine(imdsTrain, pxdsTrain);
% Define training options.
options = trainingOptions('sgdm', ...
'LearnRateSchedule','piecewise',...
'LearnRateDropPeriod',10,...
'LearnRateDropFactor',0.3,...
'Momentum',0.9, ...
'InitialLearnRate',1e-3, ...
'L2Regularization',0.005, ...
'ValidationData',dsVal,...
'MaxEpochs',30, ...
'MiniBatchSize',8, ...
'Shuffle','every-epoch', ...
'CheckpointPath', tempdir, ...
'VerboseFrequency',2,...
'Plots','training-progress',...
'ValidationPatience', 4);
3、開始訓練
doTraining = false;
if doTraining
[net, info] = trainNetwork(dsTrain,lgraph,options);
else
data = load(pretrainedNetwork);
net = data.net;
end
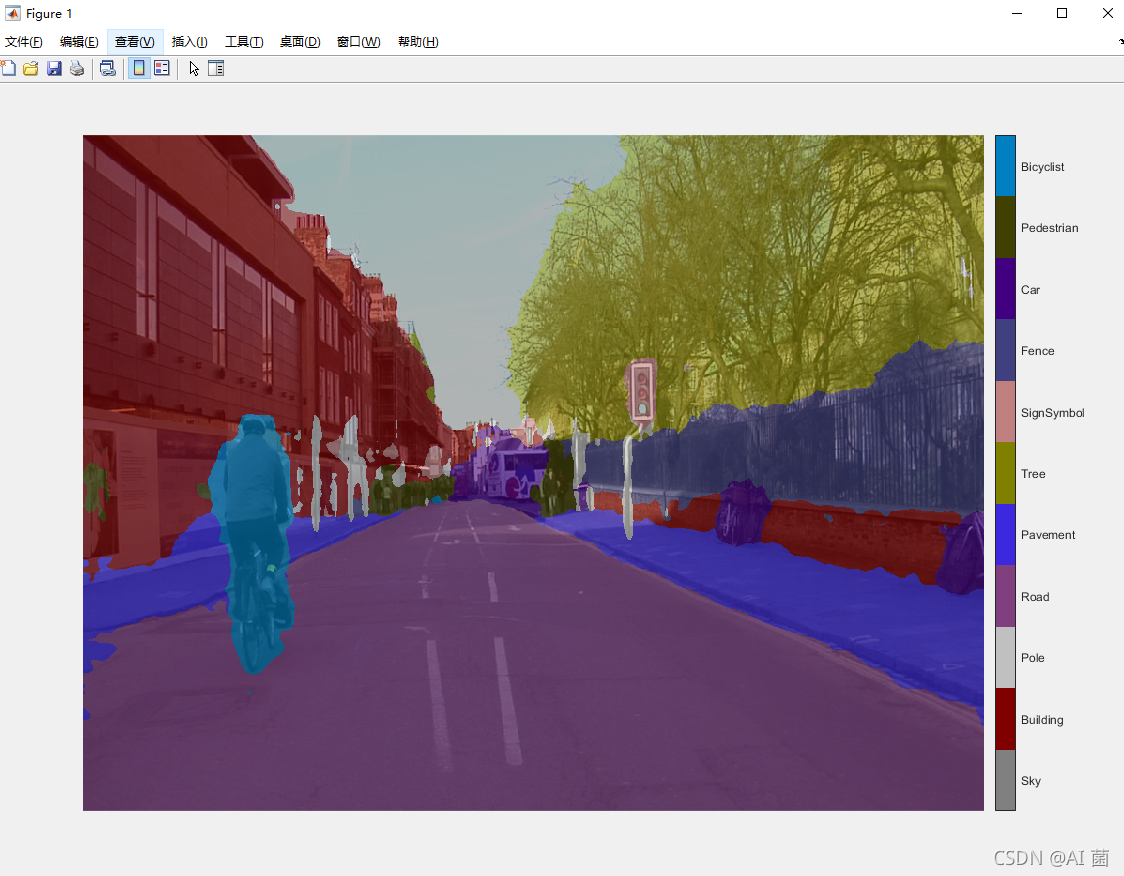
四、全景分割測驗
I = readimage(imdsVal,35);
C = semanticseg(I, net);
cmap = camvidColorMap;
B = labeloverlay(I,C,'Colormap',cmap,'Transparency',0.4);
imshow(B);
pixelLabelColorbar(cmap, classes);
測驗效果如下:
戳戳下方公眾號,更多干貨第一時間送達!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/330084.html
標籤:AI
下一篇:Pytorch實戰(1)