需要指出的是,本文第一部分的文字和代碼完全來自于Datawhale團隊(深入淺出Pytorch),感謝~~第二部分是自己獨立搭建的第一個小的網路模型,
1. FashionMNIST時裝分類

經過前面三節內容的學習,我們完成了以下的內容:
- 對PyTorch有了初步的認識
- 學會了如何安裝PyTorch以及對應的編程環境
- 學習了PyTorch最核心的理論基礎(張量&自動求導)
- 梳理了利用PyTorch完成深度學習的主要步驟和對應實作方式
現在,我們通過一個基礎實戰案例,將第一部分所涉及的PyTorch入門知識串起來,便于大家加深理解,同時為后續的進階學習打好基礎,
我們這里的任務是對10個類別的“時裝”影像進行分類,使用FashionMNIST資料集(https://github.com/zalandoresearch/fashion-mnist ),上圖給出了FashionMNIST中資料的若干樣例圖,其中每個小圖對應一個樣本,
FashionMNIST資料集中包含已經預先劃分好的訓練集和測驗集,其中訓練集共60,000張影像,測驗集共10,000張影像,每張影像均為單通道黑白影像,大小為32*32pixel,分屬10個類別,
下面讓我們一起將第三章各部分內容逐步實作,來跑完整個深度學習流程,
首先匯入必要的包
import os
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
配置訓練環境和超引數
# 配置GPU,這里有兩種方式
## 方案一:使用os.environ
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
# 方案二:使用“device”,后續對要使用GPU的變數用.to(device)即可
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
## 配置其他超引數,如batch_size, num_workers, learning rate, 以及總的epochs
batch_size = 256
num_workers = 4
lr = 1e-4
epochs = 20
資料讀入和加載
這里同時展示兩種方式:
- 下載并使用PyTorch提供的內置資料集
- 從網站下載以csv格式存盤的資料,讀入并轉成預期的格式
第一種資料讀入方式只適用于常見的資料集,如MNIST,CIFAR10等,PyTorch官方提供了資料下載,這種方式往往適用于快速測驗方法(比如測驗下某個idea在MNIST資料集上是否有效)
第二種資料讀入方式需要自己構建Dataset,這對于PyTorch應用于自己的作業中十分重要
同時,還需要對資料進行必要的變換,比如說需要將圖片統一為一致的大小,以便后續能夠輸入網路訓練;需要將資料格式轉為Tensor類,等等,
這些變換可以很方便地借助torchvision包來完成,這是PyTorch官方用于影像處理的工具庫,上面提到的使用內置資料集的方式也要用到,PyTorch的一大方便之處就在于它是一整套“生態”,有著官方和第三方各個領域的支持,這些內容我們會在后續課程中詳細介紹,
# 首先設定資料變換
from torchvision import transforms
image_size = 28
data_transform = transforms.Compose([
transforms.ToPILImage(), # 這一步取決于后續的資料讀取方式,如果使用內置資料集則不需要
transforms.Resize(image_size),
transforms.ToTensor()
])
## 讀取方式一:使用torchvision自帶資料集,下載可能需要一段時間
from torchvision import datasets
train_data = datasets.FashionMNIST(root='./', train=True, download=True, transform=data_transform)
test_data = datasets.FashionMNIST(root='./', train=False, download=True, transform=data_transform)
/data1/ljq/anaconda3/envs/smp/lib/python3.8/site-packages/torchvision/datasets/mnist.py:498: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /opt/conda/conda-bld/pytorch_1623448234945/work/torch/csrc/utils/tensor_numpy.cpp:180.)
return torch.from_numpy(parsed.astype(m[2], copy=False)).view(*s)
## 讀取方式二:讀入csv格式的資料,自行構建Dataset類
class FMDataset(Dataset):
def __init__(self, df, transform=None):
self.df = df
self.transform = transform
self.images = df.iloc[:,1:].values.astype(np.uint8)
self.labels = df.iloc[:, 0].values
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
image = self.images[idx].reshape(28,28,1)
label = int(self.labels[idx])
if self.transform is not None:
image = self.transform(image)
else:
image = torch.tensor(image/255., dtype=torch.float)
label = torch.tensor(label, dtype=torch.long)
return image, label
train_df = pd.read_csv("./FashionMNIST/fashion-mnist_train.csv")
test_df = pd.read_csv("./FashionMNIST/fashion-mnist_test.csv")
train_data = FMDataset(train_df, data_transform)
test_data = FMDataset(test_df, data_transform)
在構建訓練和測驗資料集完成后,需要定義DataLoader類,以便在訓練和測驗時加載資料
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False, num_workers=num_workers)
讀入后,我們可以做一些資料可視化操作,主要是驗證我們讀入的資料是否正確
import matplotlib.pyplot as plt
image, label = next(iter(train_loader))
print(image.shape, label.shape)
plt.imshow(image[0][0], cmap="gray")
torch.Size([256, 1, 28, 28]) torch.Size([256])
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-EEh6LQZK-1634731394350)(output_13_2.png)]
模型設計
由于任務較為簡單,這里我們手搭一個CNN,而不考慮當下各種模型的復雜結構
模型構建完成后,將模型放到GPU上用于訓練
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv = nn.Sequential(
in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0
nn.Conv2d(1, 32, 5),
nn.ReLU(),
nn.MaxPool2d(2, stride=2),
nn.Dropout(0.3),
nn.Conv2d(32, 64, 5),
nn.ReLU(),
nn.MaxPool2d(2, stride=2),
nn.Dropout(0.3)
)
self.fc = nn.Sequential(
nn.Linear(64*4*4, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.conv(x)
x = x.view(-1, 64*4*4)
x = self.fc(x)
# x = nn.functional.normalize(x)
return x
model = Net()
model = model.cuda()
# model = nn.DataParallel(model).cuda() # 多卡訓練時的寫法,之后的課程中會進一步講解
設定損失函式
使用torch.nn模塊自帶的CrossEntropy損失
PyTorch會自動把整數型的label轉為one-hot型,用于計算CE loss
這里需要確保label是從0開始的,同時模型不加softmax層(使用logits計算),這也說明了PyTorch訓練中各個部分不是獨立的,需要通盤考慮
criterion = nn.CrossEntropyLoss()
# criterion = nn.CrossEntropyLoss(weight=[1,1,1,1,3,1,1,1,1,1])
?nn.CrossEntropyLoss # 這里方便看一下weighting等策略
設定優化器
這里我們使用Adam優化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
訓練和測驗(驗證)
各自封裝成函式,方便后續呼叫
關注兩者的主要區別:
- 模型狀態設定
- 是否需要初始化優化器
- 是否需要將loss傳回到網路
- 是否需要每步更新optimizer
此外,對于測驗或驗證程序,可以計算分類準確率
def train(epoch):
model.train()
train_loss = 0
for data, label in train_loader:
data, label = data.cuda(), label.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(output, label)
loss.backward()
optimizer.step()
train_loss += loss.item()*data.size(0)
train_loss = train_loss/len(train_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))
def val(epoch):
model.eval()
val_loss = 0
gt_labels = []
pred_labels = []
with torch.no_grad():
for data, label in test_loader:
data, label = data.cuda(), label.cuda()
output = model(data)
preds = torch.argmax(output, 1)
gt_labels.append(label.cpu().data.numpy())
pred_labels.append(preds.cpu().data.numpy())
loss = criterion(output, label)
val_loss += loss.item()*data.size(0)
val_loss = val_loss/len(test_loader.dataset)
gt_labels, pred_labels = np.concatenate(gt_labels), np.concatenate(pred_labels)
acc = np.sum(gt_labels==pred_labels)/len(pred_labels)
print('Epoch: {} \tValidation Loss: {:.6f}, Accuracy: {:6f}'.format(epoch, val_loss, acc))
for epoch in range(1, epochs+1):
train(epoch)
val(epoch)
/data1/ljq/anaconda3/envs/smp/lib/python3.8/site-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /opt/conda/conda-bld/pytorch_1623448234945/work/c10/core/TensorImpl.h:1156.)
return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
Epoch: 1 Training Loss: 0.659050
Epoch: 1 Validation Loss: 0.420328, Accuracy: 0.852000
Epoch: 2 Training Loss: 0.403703
Epoch: 2 Validation Loss: 0.350373, Accuracy: 0.872300
Epoch: 3 Training Loss: 0.350197
Epoch: 3 Validation Loss: 0.293053, Accuracy: 0.893200
Epoch: 4 Training Loss: 0.322463
Epoch: 4 Validation Loss: 0.283335, Accuracy: 0.892300
Epoch: 5 Training Loss: 0.300117
Epoch: 5 Validation Loss: 0.268653, Accuracy: 0.903500
Epoch: 6 Training Loss: 0.282179
Epoch: 6 Validation Loss: 0.247219, Accuracy: 0.907200
Epoch: 7 Training Loss: 0.268283
Epoch: 7 Validation Loss: 0.242937, Accuracy: 0.907800
Epoch: 8 Training Loss: 0.257615
Epoch: 8 Validation Loss: 0.234324, Accuracy: 0.912200
Epoch: 9 Training Loss: 0.245795
Epoch: 9 Validation Loss: 0.231515, Accuracy: 0.914100
Epoch: 10 Training Loss: 0.238739
Epoch: 10 Validation Loss: 0.229616, Accuracy: 0.914400
Epoch: 11 Training Loss: 0.230499
Epoch: 11 Validation Loss: 0.228124, Accuracy: 0.915200
Epoch: 12 Training Loss: 0.221574
Epoch: 12 Validation Loss: 0.211928, Accuracy: 0.921200
Epoch: 13 Training Loss: 0.217924
Epoch: 13 Validation Loss: 0.209744, Accuracy: 0.921700
Epoch: 14 Training Loss: 0.206033
Epoch: 14 Validation Loss: 0.215477, Accuracy: 0.921400
Epoch: 15 Training Loss: 0.203349
Epoch: 15 Validation Loss: 0.215550, Accuracy: 0.919400
Epoch: 16 Training Loss: 0.196319
Epoch: 16 Validation Loss: 0.210800, Accuracy: 0.923700
Epoch: 17 Training Loss: 0.191969
Epoch: 17 Validation Loss: 0.207266, Accuracy: 0.923700
Epoch: 18 Training Loss: 0.185466
Epoch: 18 Validation Loss: 0.207138, Accuracy: 0.924200
Epoch: 19 Training Loss: 0.178241
Epoch: 19 Validation Loss: 0.204093, Accuracy: 0.924900
Epoch: 20 Training Loss: 0.176674
Epoch: 20 Validation Loss: 0.197495, Accuracy: 0.928300
模型保存
訓練完成后,可以使用torch.save保存模型引數或者整個模型,也可以在訓練程序中保存模型
這部分會在后面的課程中詳細介紹
save_path = "./FahionModel.pkl"
torch.save(model, save_path)
2. 自己搭建的第一個網路模型
這個網路模型主要針對的是一個圖片分類問題,具體是將螞蟻和蜜蜂分開,資料集是來自于B站課程 PyTorch深度學習快速入門教程(絕對通俗易懂!),大家也可以去這個課程學習一些Pytorch的具體操作,
圖片大概是這樣的:


我們要做到的是用CNN將其分開,下面看步驟:
開始的時候是在自己電腦上運行的,但是很小的網路GPU就帶不動了(確實很小,因為我也不會搭建大的網路),所以就去Colab上面運行了,
from google.colab import drive
drive.mount('/content/drive')
匯入包
import os
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torch.utils.data import Dataset, DataLoader
import numpy as np
from PIL import Image
import os
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
from torchvision.utils import make_grid
設定用GPU運行
# 使用“device”,后續對要使用GPU的變數用.to(device)即可
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
因為資料是自己的,所以需要自定義Dataset類
class MyData(Dataset):
def __init__(self, root_dir, image_dir, label_dir, transform):
self.root_dir = root_dir
self.image_dir = image_dir
self.label_dir = label_dir
self.label_path = os.path.join(self.root_dir, self.label_dir)
self.image_path = os.path.join(self.root_dir, self.image_dir)
self.image_list = os.listdir(self.image_path)
self.label_list = os.listdir(self.label_path)
self.transform = transform
# 因為label 和 Image檔案名相同,進行一樣的排序,可以保證取出的資料和label是一一對應的
self.image_list.sort()
self.label_list.sort()
def __getitem__(self, idx):
img_name = self.image_list[idx]
label_name = self.label_list[idx]
img_item_path = os.path.join(self.root_dir, self.image_dir, img_name)
label_item_path = os.path.join(self.root_dir, self.label_dir, label_name)
img = Image.open(img_item_path)
with open(label_item_path, 'r') as f:
label = f.readline()
# img = np.array(img)
img = self.transform(img)
sample = {'img': img, 'label': label}
return sample
def __len__(self):
assert len(self.image_list) == len(self.label_list)
return len(self.image_list)
transform = transforms.Compose([transforms.Resize((256, 256)), transforms.ToTensor()])
root_dir = "/content/drive/MyDrive/Colab Notebooks/資料集/train"
image_ants = "ants_image"
label_ants = "ants_label"
ants_dataset = MyData(root_dir, image_ants, label_ants, transform)
image_bees = "bees_image"
label_bees = "bees_label"
bees_dataset = MyData(root_dir, image_bees, label_bees, transform)
train_dataset = ants_dataset + bees_dataset
使用dataloader將資料load下來,batch_size選的10,害怕太大跑不了
dataloader = DataLoader(train_dataset, shuffle=True,batch_size=10, num_workers=0,drop_last=True)
稍微看了一下資料的樣子
def func1(x):
if x=='ants':
y=1
else:
y=0
return y
for i, j in enumerate(dataloader):
imgs, labels = j['img'],j['label']
labels = list(map(func1,labels))
print(labels)
構建網路(一個很簡單的CNN網路)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=1),
)
self.fc = nn.Sequential(
nn.Linear(3*254*254, 512),
nn.ReLU(),
nn.Linear(512, 2)
)
def forward(self, x):
x = self.conv(x)
#print(x.shape)
x = x.view(-1,3*254*254)
x = self.fc(x)
# x = nn.functional.normalize(x)
return x
model = Net()
model = model.cuda()
# model = nn.DataParallel(model).cuda() # 多卡訓練時的寫法,之后的課程中會進一步講解
建立損失函式,選擇的是交叉熵損失
criterion = nn.CrossEntropyLoss()
優化演算法選擇的是Adam(之前在自己的Blog里面也介紹過)
optimizer = optim.Adam(model.parameters(), lr=0.001)
定義用來訓練的函式
def train(epoch):
model.train()
train_loss = 0
for i, j in enumerate(dataloader):
data, label = j['img'],j['label']
label = list(map(func1,label))
label = torch.Tensor(label)
data, label = data.cuda(), label.cuda()
optimizer.zero_grad()
output = model(data)
#print(output)
loss = criterion(output, label.long())
loss.backward()
optimizer.step()
train_loss += loss.item()*data.size(0)
train_loss = train_loss/len(dataloader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))
開始訓練
for epoch in range(1, epochs+1):
train(epoch)
結果如下:
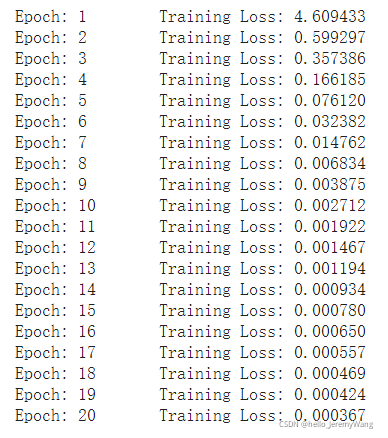
看起來還不錯?但是自己對于究竟該如何搭建網路還是比較生疏,需要后續繼續努力學習啊,加油,小汪!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/330085.html
標籤:AI