Transformer & BERT PPT: https://speech.ee.ntu.edu.tw/~hylee/ml/ml2021-course-data/self_v7.pdf
【李宏毅《機器學習/深度學習》2021課程(國語版本,已授權)-嗶哩嗶哩】https://b23.tv/baegp9
一、問題分析
1. 模型的輸入
無論是預測視頻觀看人數還是影像處理,輸入都可以看作是一個向量,輸出是一個數值或類別,然而,若輸入是一系列向量(序列),同時長度會改變,例如把句子里的單詞都描述為向量,那么模型的輸入就是一個向量集合,并且每個向量的大小都不一樣:
將單詞表示為向量的方法:One-hot Encoding(獨熱編碼),向量的長度就是世界上所有詞匯的數目,用不同位的1(其余位置為0)表示一個詞匯,如下所示:
- apple = [1, 0, 0, 0, 0, …]
- bag = [0, 1, 0, 0, 0, …]
- cat = [0, 0, 1, 0, 0, …]
- dog = [0, 0, 0, 1, 0, …]
- computer = [0, 0, 0, 0, 1, …]
但是它并不能區分出同類別的詞匯,里面沒有任何有意義的資訊,
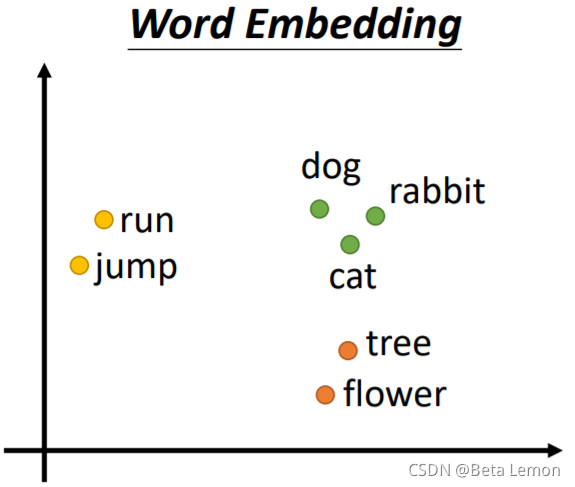
另一個方法是Word Embedding:給單詞一個向量,這個向量有語意的資訊,一個句子就是一排長度不一的向量,將Word Embedding畫出來,就會發現同類的單詞就會聚集,因此它能區分出類別:
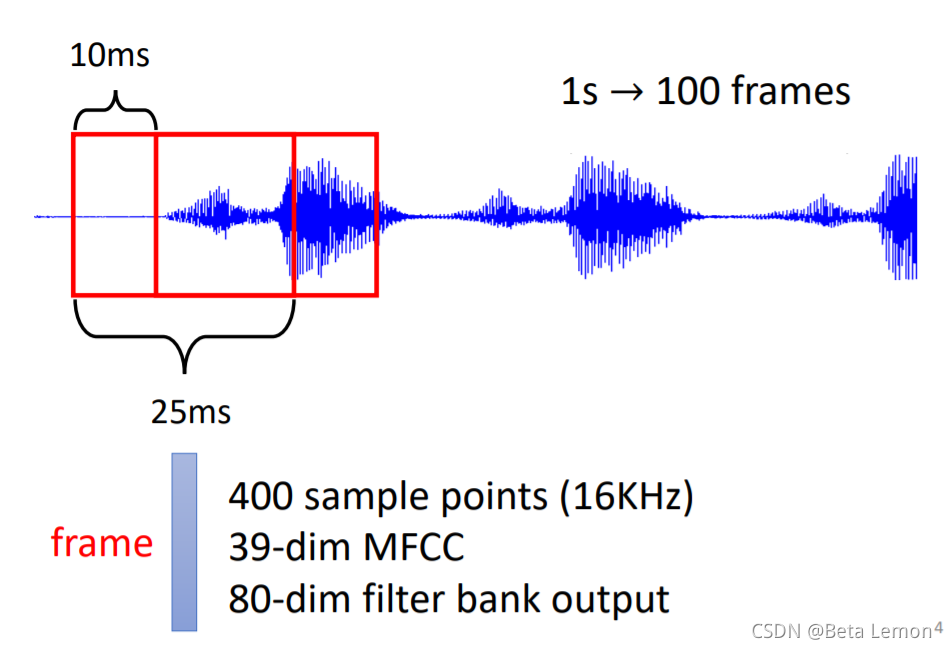
另外還有語音信號、影像信號也能描述為一串向量:
| 語音信號 | 圖論 |
|---|---|
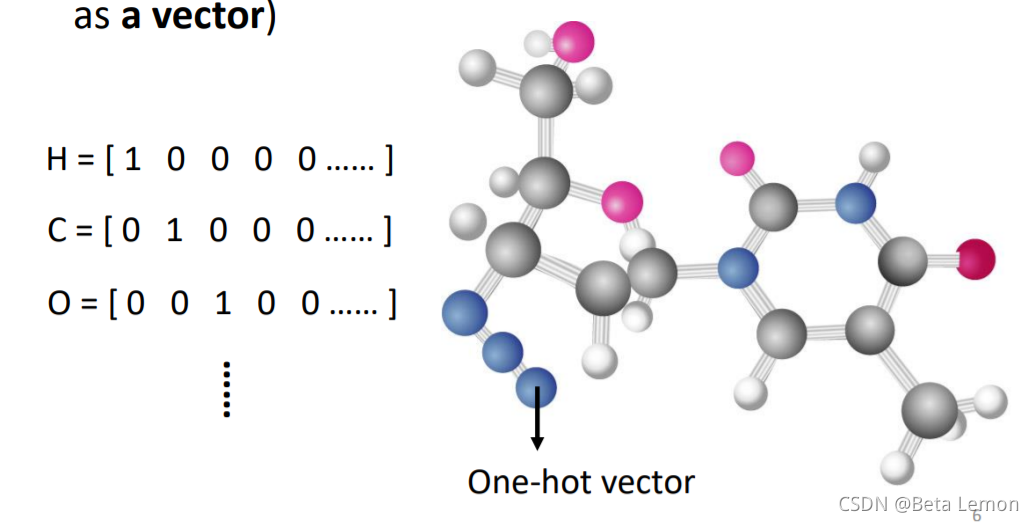
| 取一段語音信號作為視窗,把其中的資訊描述為一個向量(幀),滑動這個視窗就得到這段語音的所有向量 | ①社交網路的每個節點就是一個人,節點之間的關系用線連接,每一個人就是一個向量 ②分子上的每個原子就是一個向量(每個元素可用One-hot編碼表示),分子就是一堆向量 |
 |   |
2. 模型的輸出
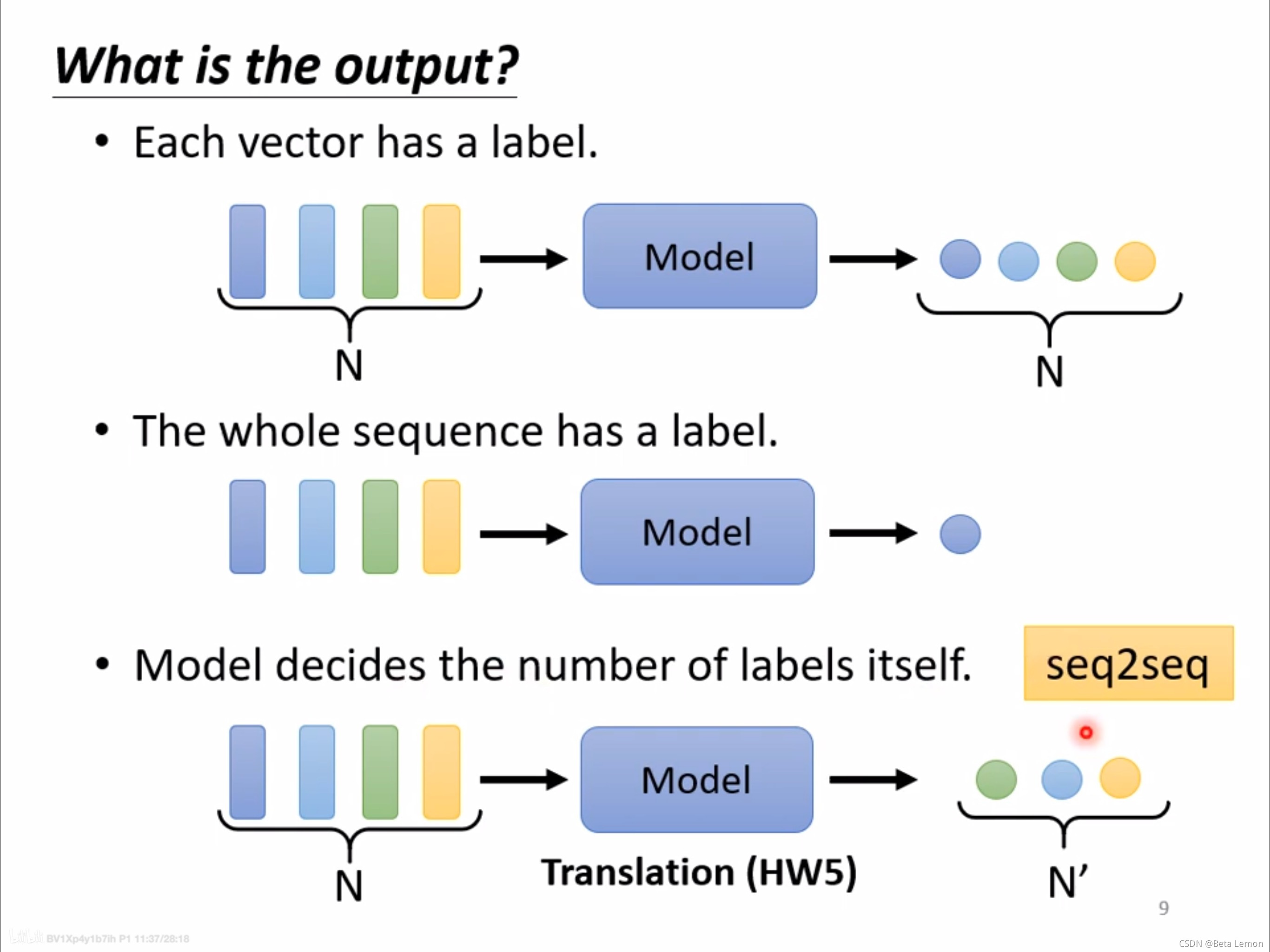
型別一:一對一(Sequence Labeling)
每個輸入向量對應一個輸出標簽,
- 文字處理:詞性標注(每個輸入的單詞都輸出對應的詞性),
- 語音處理:一段聲音信號里面有一串向量,每個向量對應一個音標,
- 影像處理:在社交網路中,推薦某個用戶商品(可能會買或者不買),
型別二:多對一
多個輸入向量對應一個輸出標簽,
- 語意分析:正面評價、負面評價,
- 語音識別:識別某人的音色,
- 影像:給出分子的結構,判斷其親水性,
型別三:由模型自定(seq2seq)
不知道應該輸出多少個標簽,機器自行決定,
- 翻譯:語言A到語言B,單詞字符數目不同
- 語音識別
3. 序列標注 (Sequnce Labeling) 的問題
利用全連接網路,輸入一個句子,輸出對應單詞數目的標簽,當一個句子里出現兩個相同的單詞,并且它們的詞性不同(例如:I saw a saw. 我看見一把鋸子),這個時候就需要考慮背景關系:利用滑動視窗,每個向量查看視窗中相鄰的其他向量的性質,
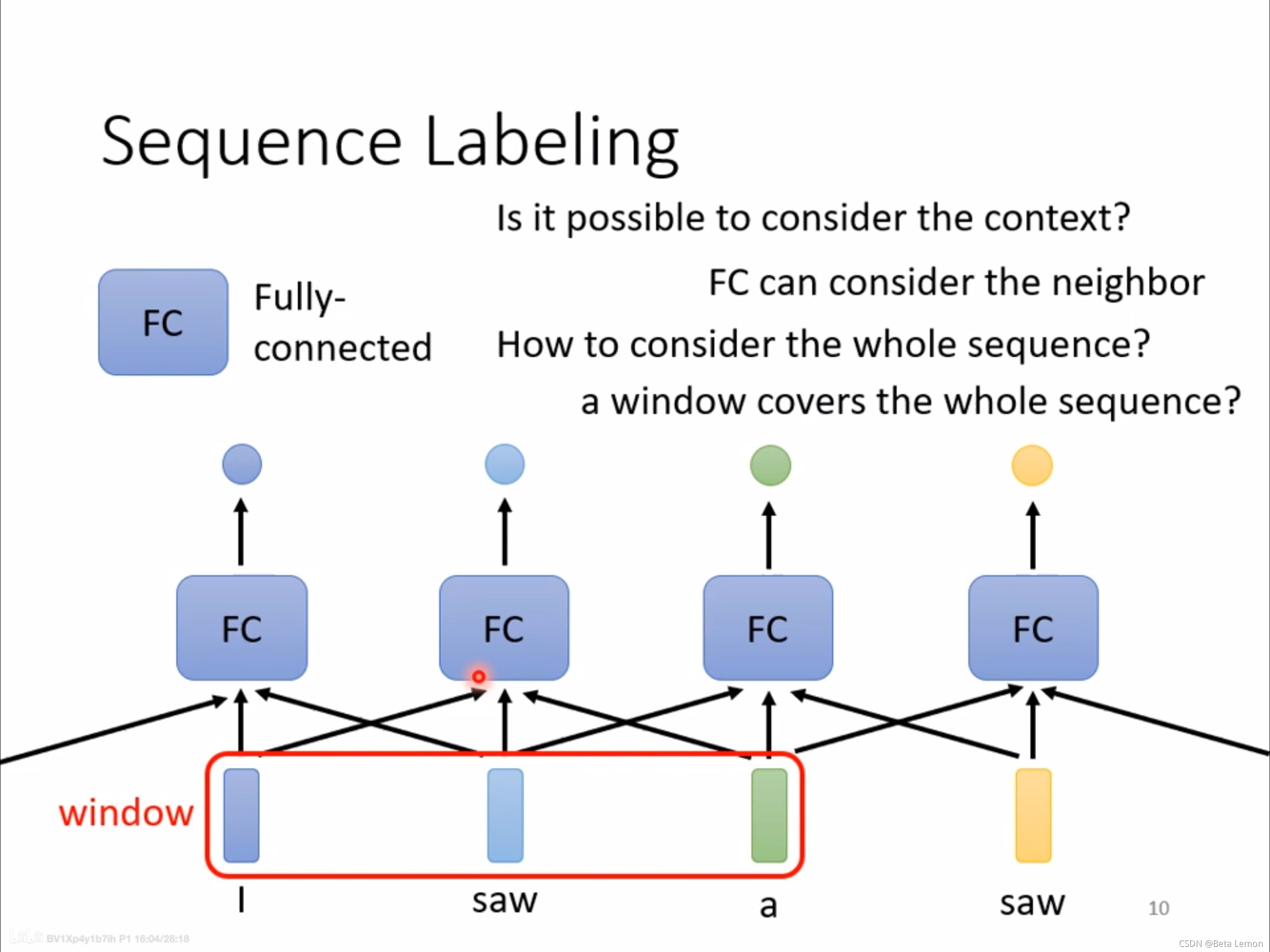
但是這種方法不能解決整條陳述句的分析問題,即語意分析,這就引出了 Self-attention 技術,
二、Self-attention 自注意力機制
輸入整個陳述句的向量到self-attention中,輸出對應個數的向量,再將其結果輸入到全連接網路,最后輸出標簽,以上程序可多次重復:
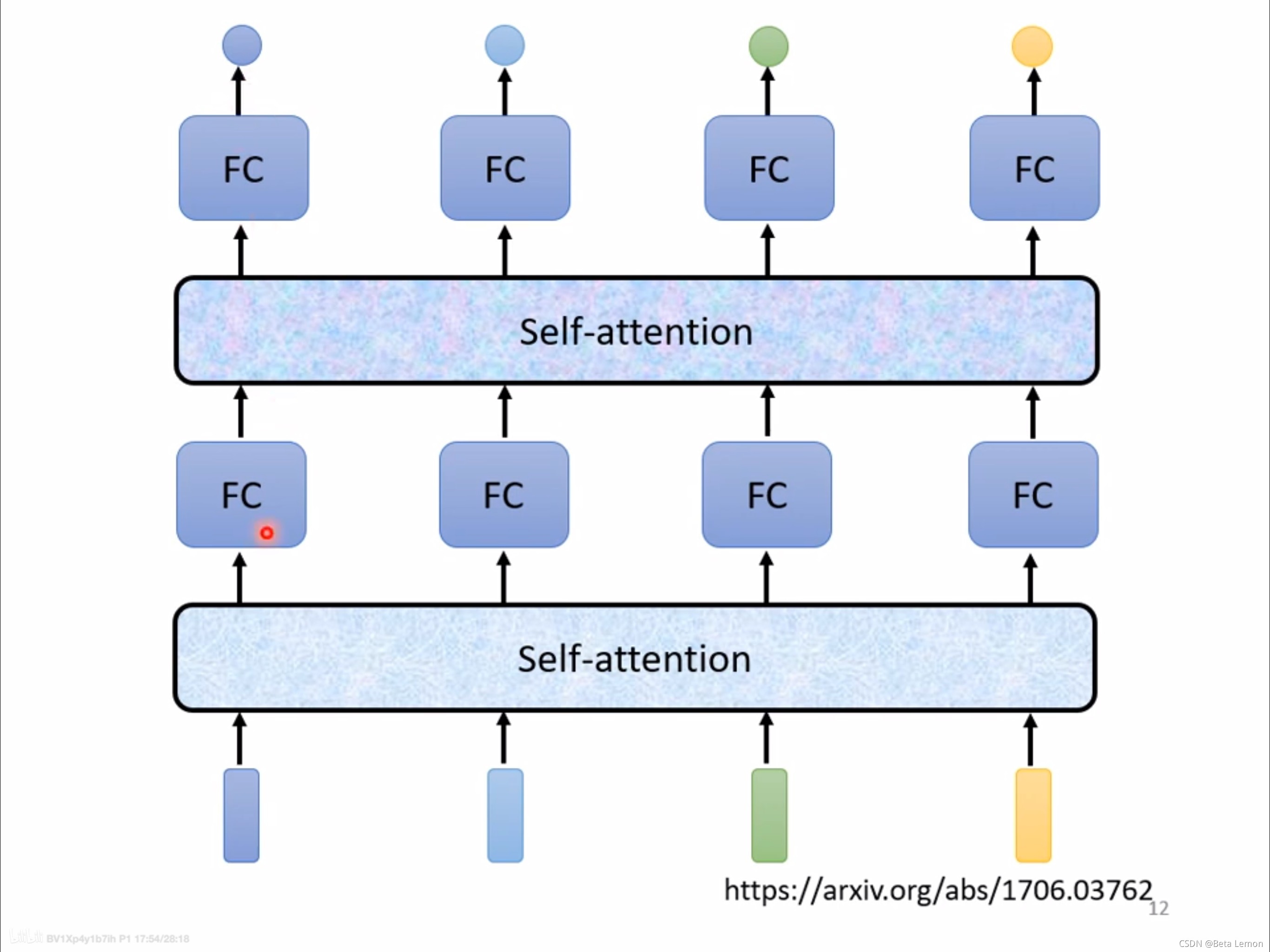
Google 根據自注意力機制在《Attention is all you need》中提出了 Transformer 架構,
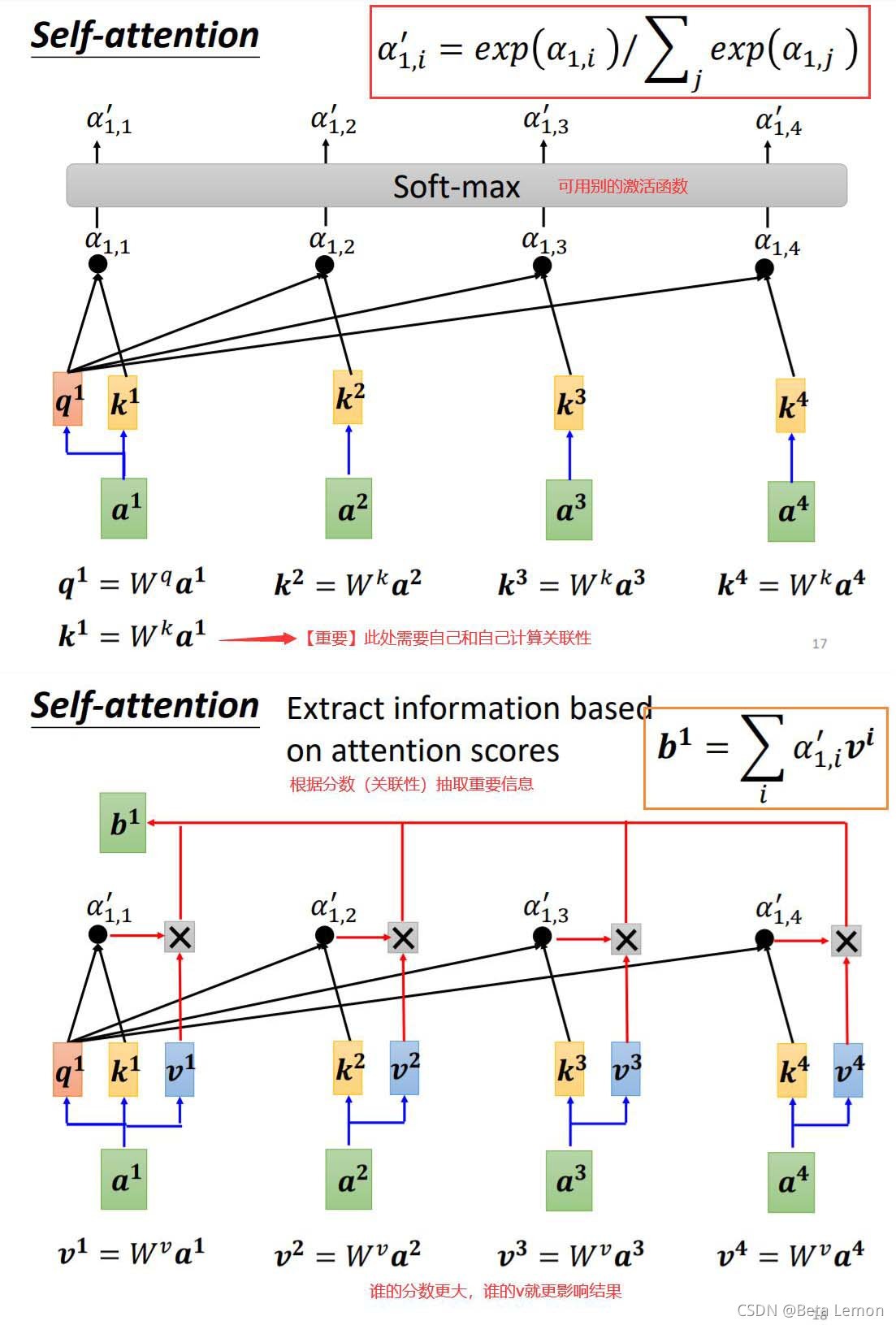
1. 運行原理
這里需要三個向量:Query,Key,Value,其解釋參考文章 《如何理解 Transformer 中的 Query、Key 與 Value》- yafee123
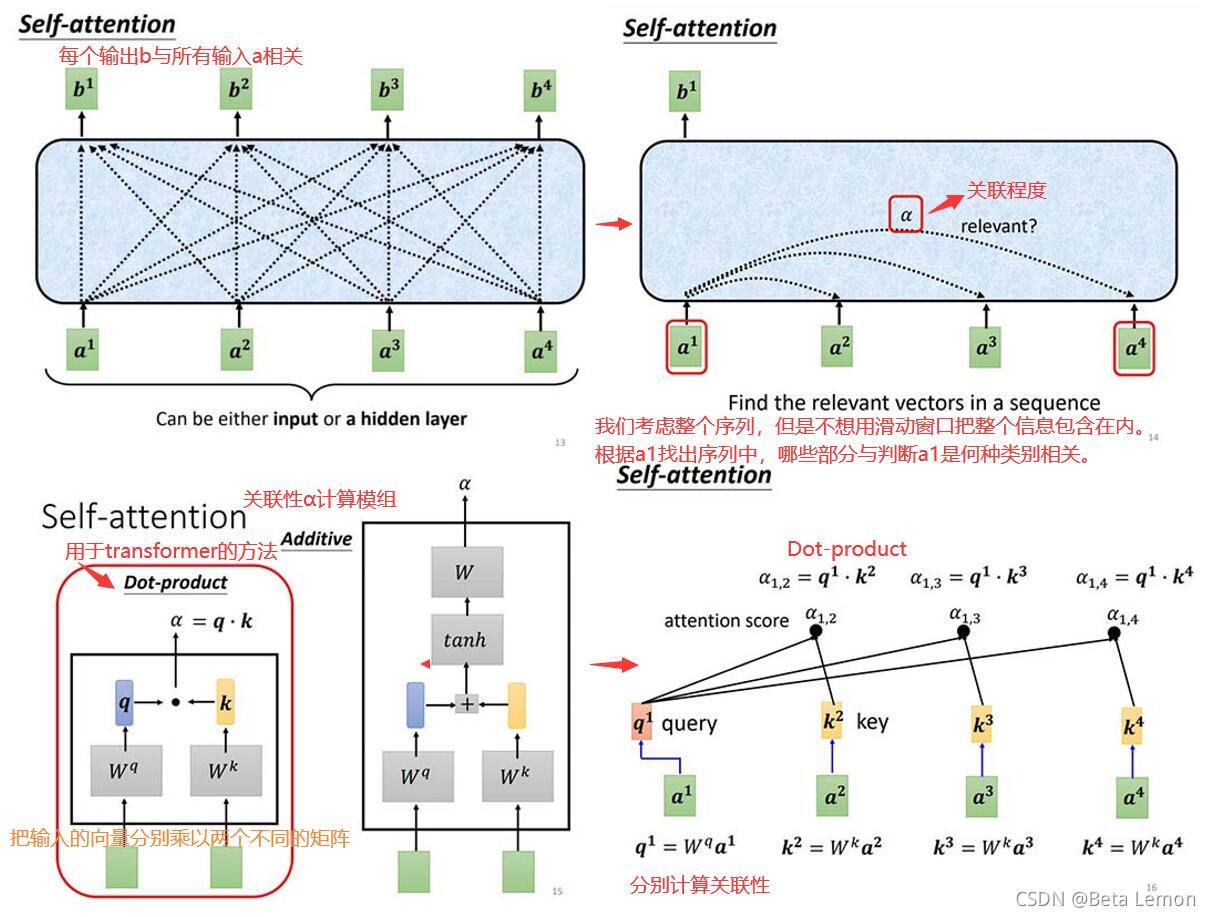
注:
b
i
(
1
≤
i
≤
4
)
b^i (1≤i≤4)
bi(1≤i≤4) 是同時計算出來的,
a
i
,
j
a_{i,j}
ai,j?為
q
i
q^i
qi和
k
j
k^j
kj的內積,
上述程序可總結為:
- 輸入矩陣 I I I分別乘以三個 W W W得到三個矩陣 Q , K , V Q,K,V Q,K,V
- A = K T Q A=K^TQ A=KTQ,經過處理得到注意力矩陣 A ′ A' A′
- 輸出
O
=
V
A
′
O=VA'
O=VA′
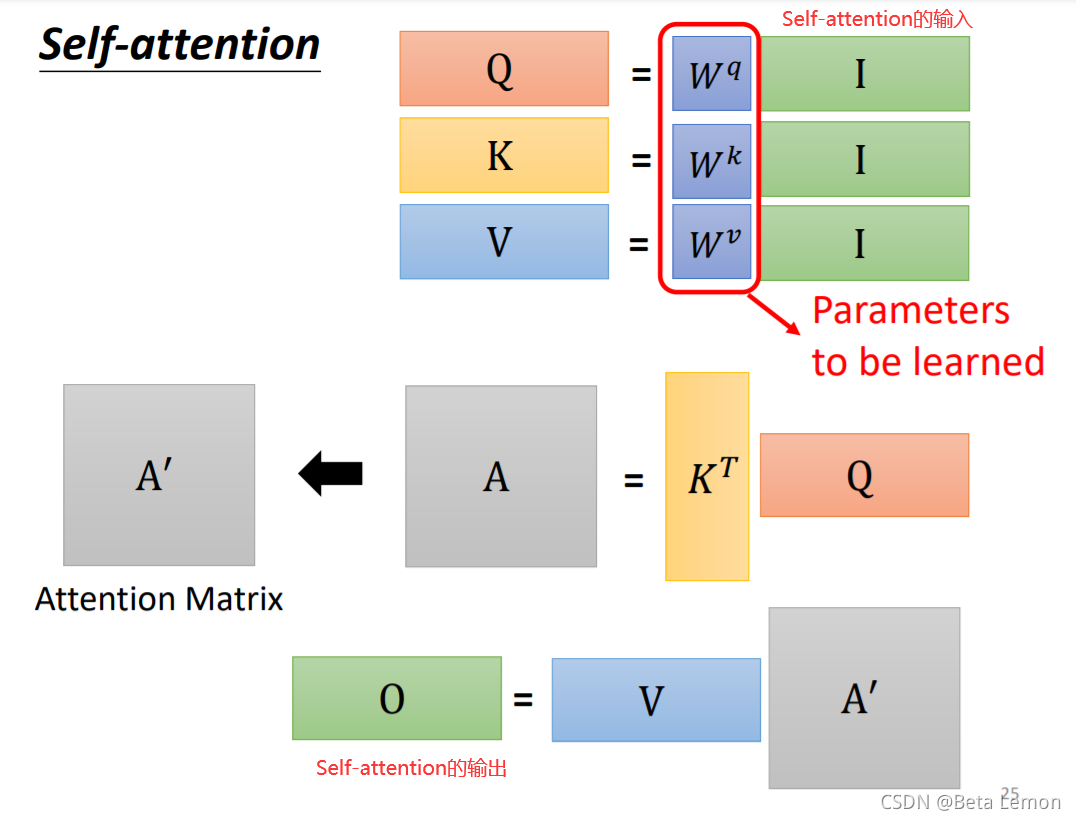
其中唯一要訓練出的引數就是 W W W.
2. 多頭注意力機制 (Multi-head Self-attention)
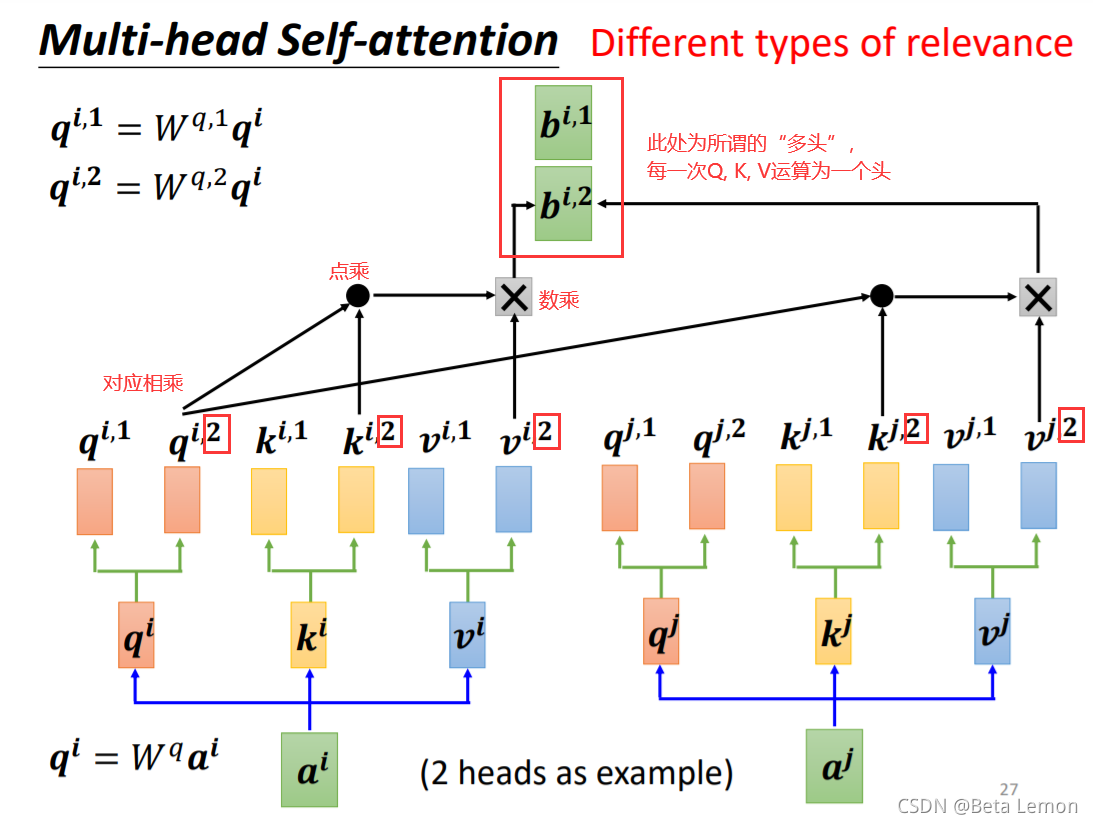
b
i
=
W
0
[
b
i
,
1
b
i
,
2
]
b^i=W^0\left[ \begin{array}{c} b^{i,1} \\ b^{i,2} \end{array} \right]
bi=W0[bi,1bi,2?]
Query,Key,Value首先經過一個線性變換,然后輸入到放縮點積attention,注意這里要做 h h h 次,其實也就是所謂的多頭,每一次算一個頭,而且每次Q,K,V進行線性變換的引數 W W W是不一樣的( W q , W k , W v W^q,W^k,W^v Wq,Wk,Wv),然后將 h h h 次的放縮點積attention結果進行拼接,再進行一次線性變換得到的值作為多頭attention的結果,1
對于Self-attention來說,并沒有序列中字符位置的資訊,例如動詞是不太可能出現在句首的,因此可以降低動詞在句首的可能性,但是自注意力機制并沒有該能力,因此需要加入 Positional Encoding 的技術來標注每個詞匯在句子中的位置資訊,
3. 位置編碼 (Positional Encoding)
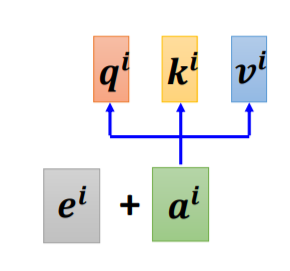
每一個不同的位置都有一個專屬的向量 e i e^i ei,然后再做 e i + a i e^i+a^i ei+ai 的操作即可,但是這個 e i e^i ei 是人工標注的,就會出現很多問題:在確定 e i e^i ei的時候只定到128,但是序列長度是129,在最早的論文2中是沒有這個問題的,它通過某個規則(sin、cos函式)3 產生,盡管如此,位置編碼也可以通過學習來得出,
BERT4 模型也用到了自注意力機制
Self-attention 還可以用在除NLP以外的問題上:語音處理,影像處理,
三、其他應用
1. 語音識別
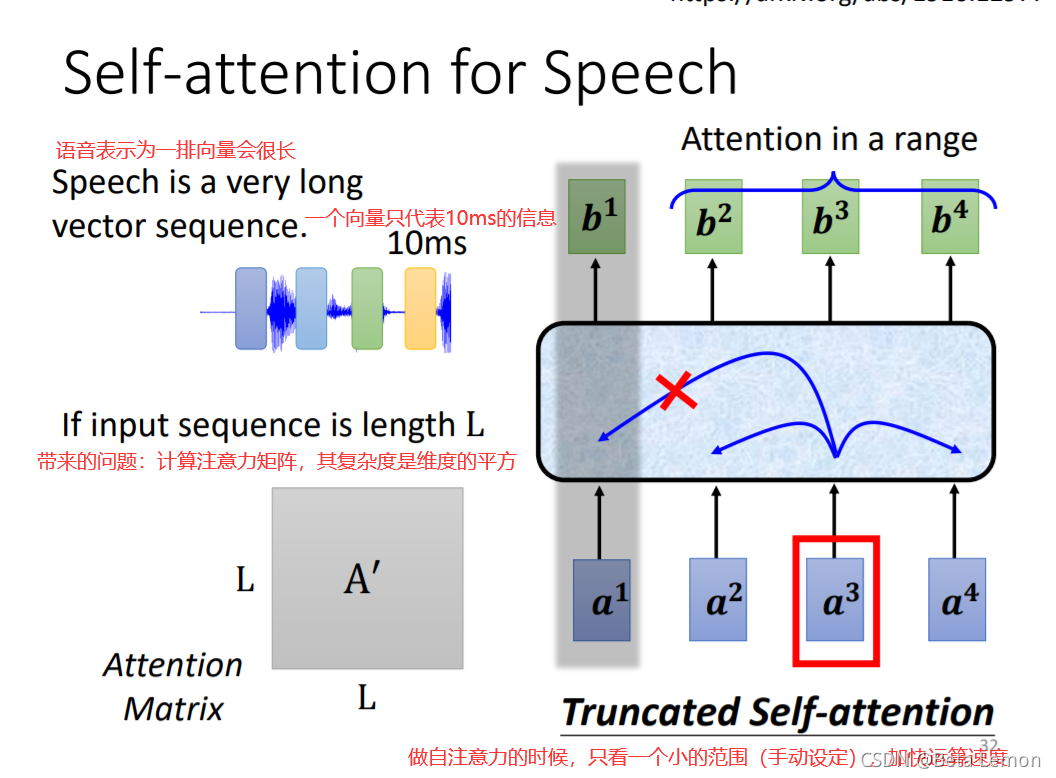
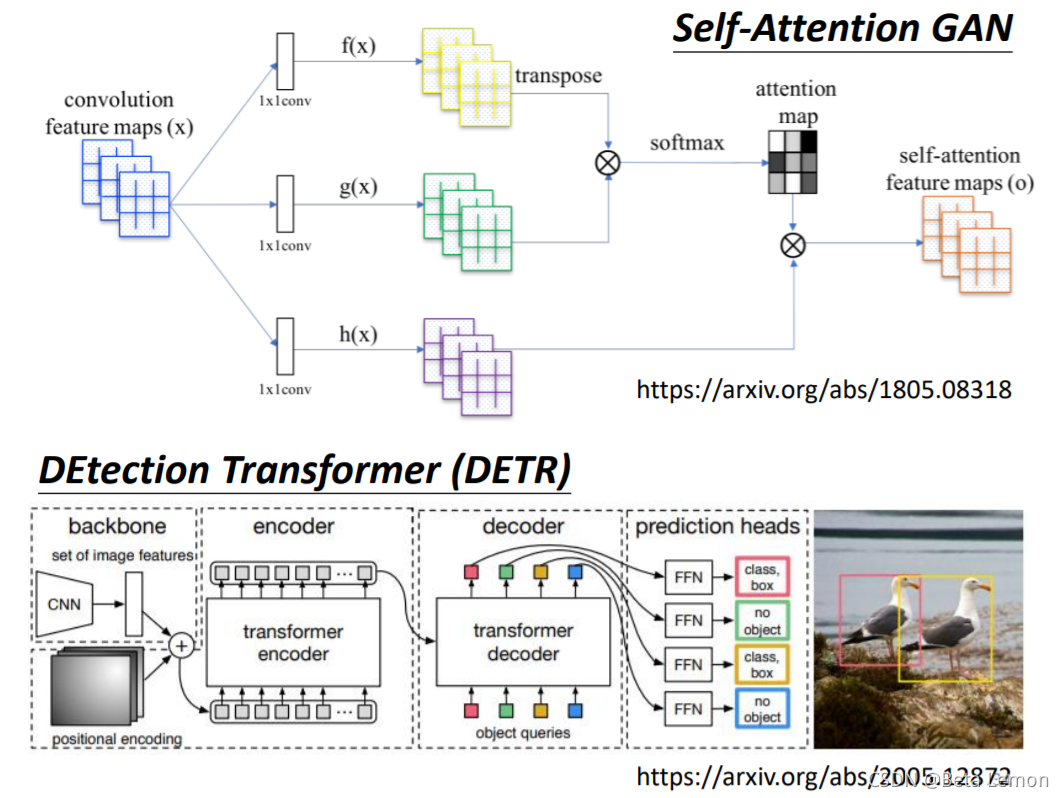
2. 影像識別
在做CNN的時候,一張圖片可看做一個很長的向量,它也可看做 一組向量:一張
5
?
10
5*10
5?10的RGB影像可以看做
5
?
10
5*10
5?10的三個(通道)矩陣,把三個通道的相同位置看做一個三維向量,

具體應用:GAN、DETR
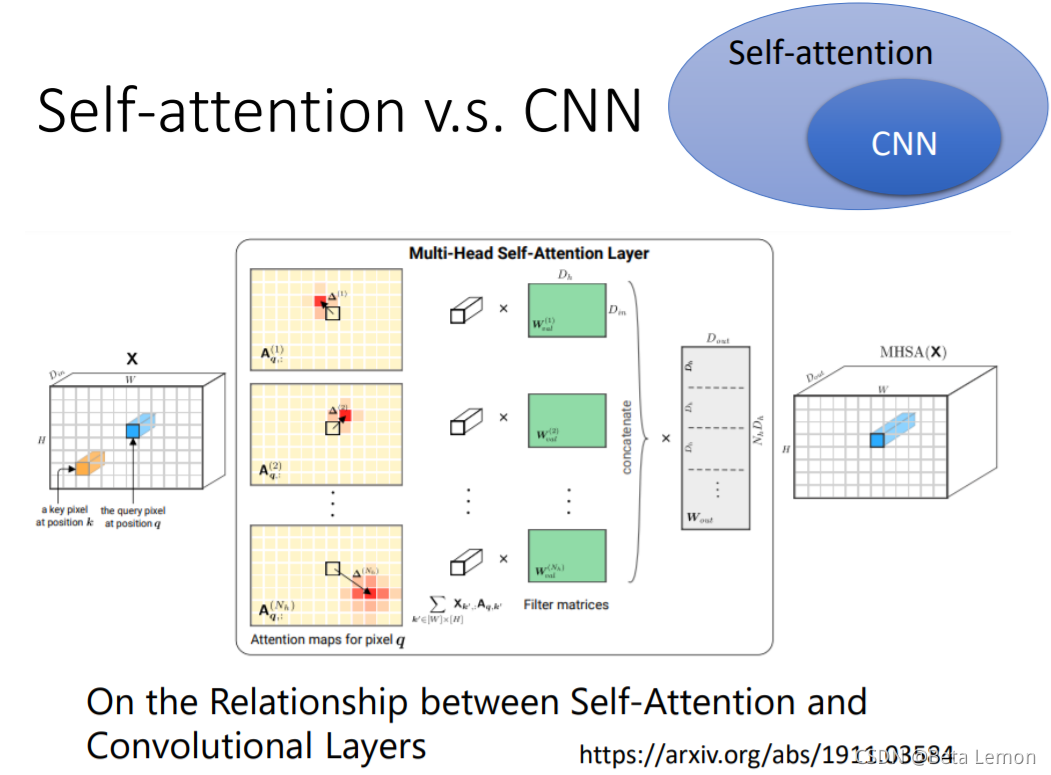
2.1 自注意力機制和CNN的差異
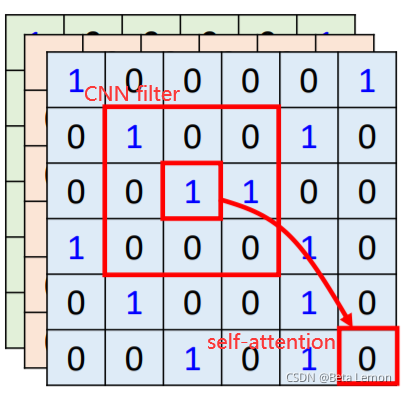
- CNN看做簡化版的self-attention:CNN只考慮一個感受野里的資訊,self-attention考慮整張圖片的資訊
- self-attention是復雜版的CNN:CNN里面每個神經元只考慮一個感受野,其范圍和大小是人工設定的;自注意力機制中,用attention去找出相關的像素,感受野就如同自動學出來的,
如果用不同的資料量來訓練CNN和self-attention,會出現不同的結果,大的模型self-attention如果用于少量資料,容易出現過擬合;而小的模型CNN,在少量資料集上不容易出現過擬合,5
2.2 與RNN的差異
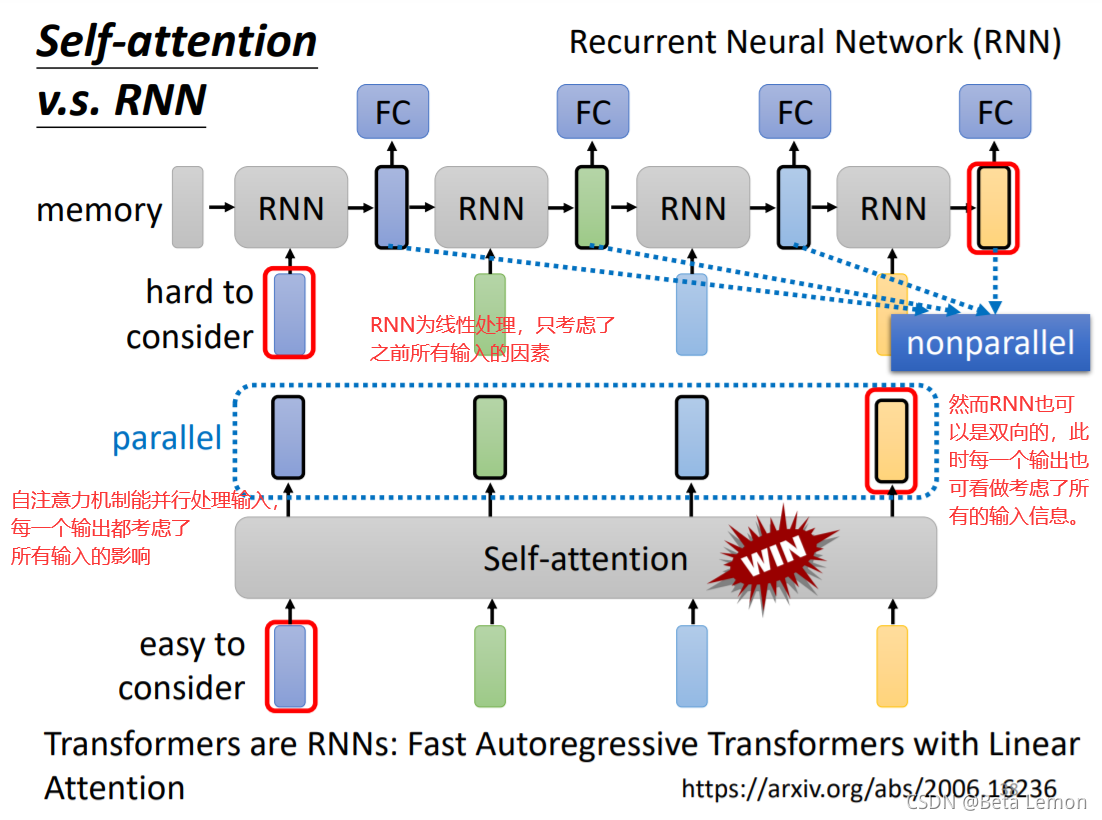
因此很多的應用逐漸把RNN的架構改為Self-attention架構,6
3. 應用于圖論(GNN)
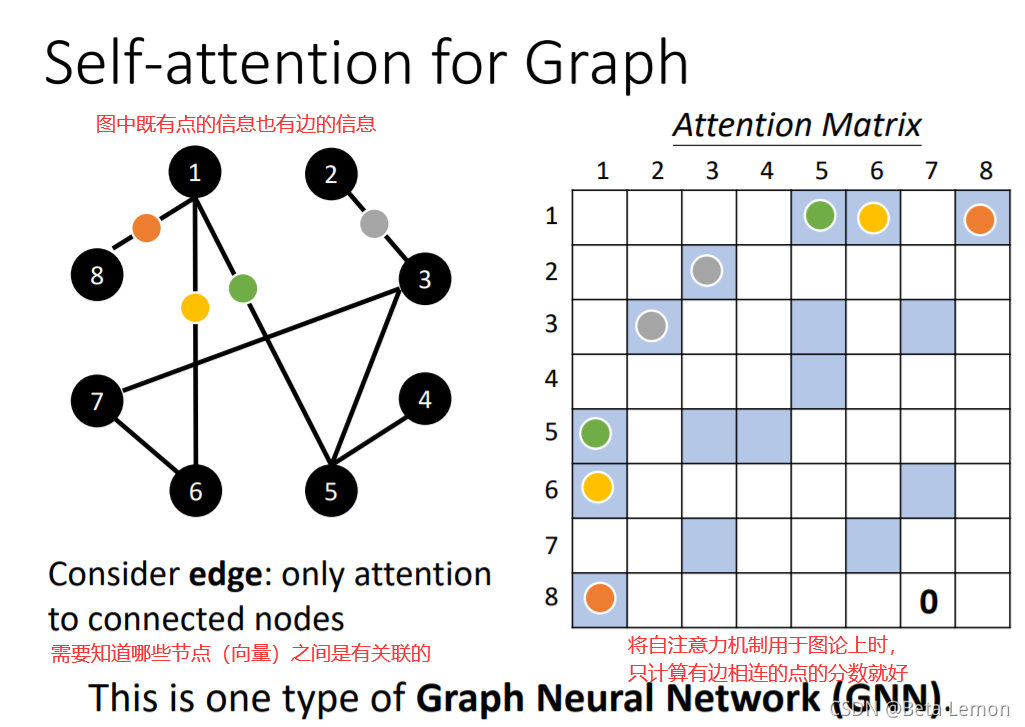
自注意力機制的缺點就是計算量非常大,因此如何優化其計算量是未來研究的重點,
transformer模型中的self-attention和multi-head-attention機制 - 小鎮大愛 ??
Learning to Encode Position for Transformer with Continuous Dynamical Model ??
淺談Positional Encoding(位置編碼)和WordPiece - Shaw_Road ??
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding ??
On the Relationship between Self-Attention and Convolutional Layers ??
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/330445.html
標籤:其他