MiniVGGNet:更深層的卷積神經網路
? VGGNet,首次被Simonyan和Zisserman在他們的論文:Very Deep Learning Convolutional Neural Networks for Large-Scale Image Recognition 中提出,
? 在此之前,深度學習中的神經網路混合使用各種尺寸的卷積核,
? 經常是第一層卷積核大小在7 * 7到 11*11之間,然后減小到5*5,最深層一般是3*3,
? VGG則不同,在整個網路結構中,只使用3*3的卷積核,
? 這種只用小尺寸卷積核的做飯被廣泛認為幫助VGGNet提高了其泛化能力,
? 這種3*3的卷積核成為了VGG的代表,如果一個網路結構中只使用了3*3的卷積核,那么說明這是從VGGNet中得到的靈感,
? 但是,完整版的VGG16和VGG19對我們目前的水平來說還是有些過于高級了,
? 所以我們先來討論VGG家族的網路,以及其必須具有的特征,并且通過實作和訓練一個小型的類VGGNet的結構來學習它,在其實作程序中,我們會用到兩種網路層:BN以及Dropout
VGG家族
? VGG家族的卷積神經網路往往具有以下兩個關鍵特征:
- 所有卷積層的卷積核的尺寸均為3 * 3
- 在進行了多次的卷積與激活之后,才執行一次池化,
MiniVGGNet
我們先將MiniVGGNet的網路結構列出來,如下表:
| Layer Type | Output Size | Filter Size / Stride |
|---|---|---|
| INPUT IMAGE | 32 * 32 *3 | |
| CONV | 32 * 32 *32 | 3 * 3 , K = 32 |
| ACT | 32 * 32 *32 | |
| BN | 32 * 32 *32 | |
| CONV | 32 * 32 *32 | 3 * 3 , K = 32 |
| ACT | 32 * 32 *32 | |
| BN | 32 * 32 *32 | |
| POOL | 32 * 32 *32 | 2 * 2 |
| DROPOUT | 32 * 32 *32 | |
| CONV | 32 * 32 *32 | 3 * 3 , K = 64 |
| ACT | 32 * 32 *32 | |
| BN | 32 * 32 *32 | |
| CONV | 32 * 32 *32 | 2 * 2 |
| ACT | 32 * 32 *32 | |
| BN | 32 * 32 *32 | |
| POOL | 32 * 32 *32 | |
| DROPOUT | 32 * 32 *32 | |
| FC | 512 | |
| ACT | 512 | |
| BN | 512 | |
| DROPOUT | 512 | |
| FC | 10 | |
| SOFTMAX | 10 |
代碼實作:
目錄結構:
----pyimagesearch
| |----__init__.py
| |----nn
| | |----__init__.py
| | |----conv
| | | |----__init__.py
| | | |----lenet.py
| | | |----minivggnet.py
| | | |----shallownet.py
打開minivggnet.py寫入如下代碼
from keras.models import Sequential
from keras.layers import BatchNormalization
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Flatten
from keras.layers.core import Dense
from keras.layers.core import Dropout
from keras import backend as K
class MiniVGGNet:
@staticmethod
def build(width, height, depth, classes):
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
if K.image_data_format == "channels_first":
inputShape = (depth, height, width)
chanDim = 1
model.add(Conv2D(32, (3, 3), padding="same", input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(32, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(classes))
model.add(Activation("softmax"))
return model
在CIFAR-10資料集上使用MiniVGGNet
創建minivggnet_cifar-10.py檔案,寫入如下代碼:
import matplotlib
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from nn.conv.minivggnet import MiniVGGNet
from tensorflow.keras.optimizers import SGD
from keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
matplotlib.use("Agg")
print("[INFO] loading CIFAR-10 data...")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float") /255.0
testX = testX.astype("float") / 255.0
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
labelNames = ["airplane", "automobile", "bird", "cat", "deer", "dog",
"frog", "horse", "ship", "truck"]
print("[INFO] compiling model...")
opt = SGD(learning_rate=0.01, decay=0.01/40, momentum=0.9, nesterov=True)
model = MiniVGGNet.build(width=32, height=32, depth=3, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])
print("[INFO] training network...")
H = model.fit(trainX,trainY,validation_data=(testX, testY), batch_size=64, epochs=40, verbose=1)
print("[INFO] evaluating network....")
predictions = model.predict(testX, batch_size=64)
print(classification_report(testY.argmax(axis=1), predictions.argmax(axis=1), target_names=labelNames))
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 40), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 40), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 40), H.history["accuracy"], label="train_accuracy")
plt.plot(np.arange(0, 40), H.history["val_accuracy"], label="val_accuracy")
plt.title("Training Loss And Accuracy On CIFAR-10")
plt.xlabel("Epoch")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(r"E:\PycharmProjects\DLstudy\result\MiniVGGNet_On_Cifar10.png")
在獲取cifar-10資料集時可能會報錯,我們需要到網頁https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz中手動下載,然后放在.keras/datasets/目錄下,并將cifar-10-python.tar.gz重命名為cifar-10-batches-py.tar.gz,這樣每次運行程式檢測到本地已經有下載好的資料集,就不會再去網路上下載了,
運行結果
E:\DLstudy\Scripts\python.exe E:/PycharmProjects/DLstudy/run/minivggnet_cifar10.py
2021-10-22 19:44:58.806381: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'cudart64_110.dll'; dlerror: cudart64_110.dll not found
2021-10-22 19:44:58.806748: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
[INFO] loading CIFAR-10 data...
[INFO] compiling model...
2021-10-22 19:45:22.204239: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'nvcuda.dll'; dlerror: nvcuda.dll not found
2021-10-22 19:45:22.204718: W tensorflow/stream_executor/cuda/cuda_driver.cc:269] failed call to cuInit: UNKNOWN ERROR (303)
2021-10-22 19:45:22.407002: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:169] retrieving CUDA diagnostic information for host: DESKTOP-VBBSMRF
2021-10-22 19:45:22.407654: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:176] hostname: DESKTOP-VBBSMRF
2021-10-22 19:45:22.454679: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
[INFO] training network...
2021-10-22 19:45:31.153369: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:185] None of the MLIR Optimization Passes are enabled (registered 2)
Epoch 1/40
782/782 [==============================] - 324s 410ms/step - loss: 1.6101 - accuracy: 0.4619 - val_loss: 1.4320 - val_accuracy: 0.5093
Epoch 2/40
782/782 [==============================] - 297s 380ms/step - loss: 1.1239 - accuracy: 0.6119 - val_loss: 1.1982 - val_accuracy: 0.5898
Epoch 3/40
782/782 [==============================] - 296s 378ms/step - loss: 0.9459 - accuracy: 0.6684 - val_loss: 0.9293 - val_accuracy: 0.6719
Epoch 4/40
782/782 [==============================] - 273s 348ms/step - loss: 0.8489 - accuracy: 0.7030 - val_loss: 0.7934 - val_accuracy: 0.7203
Epoch 5/40
782/782 [==============================] - 252s 323ms/step - loss: 0.7798 - accuracy: 0.7266 - val_loss: 0.7070 - val_accuracy: 0.7471
Epoch 6/40
782/782 [==============================] - 257s 329ms/step - loss: 0.7207 - accuracy: 0.7451 - val_loss: 0.7138 - val_accuracy: 0.7534
Epoch 7/40
782/782 [==============================] - 328s 419ms/step - loss: 0.6782 - accuracy: 0.7621 - val_loss: 0.6627 - val_accuracy: 0.7709
Epoch 8/40
782/782 [==============================] - 286s 366ms/step - loss: 0.6377 - accuracy: 0.7759 - val_loss: 0.6518 - val_accuracy: 0.7737
Epoch 9/40
782/782 [==============================] - 268s 343ms/step - loss: 0.6082 - accuracy: 0.7863 - val_loss: 0.6610 - val_accuracy: 0.7720
Epoch 10/40
782/782 [==============================] - 271s 347ms/step - loss: 0.5835 - accuracy: 0.7935 - val_loss: 0.6093 - val_accuracy: 0.7878
Epoch 11/40
782/782 [==============================] - 270s 345ms/step - loss: 0.5516 - accuracy: 0.8035 - val_loss: 0.6036 - val_accuracy: 0.7903
Epoch 12/40
782/782 [==============================] - 251s 321ms/step - loss: 0.5255 - accuracy: 0.8129 - val_loss: 0.5873 - val_accuracy: 0.7979
Epoch 13/40
782/782 [==============================] - 251s 321ms/step - loss: 0.5093 - accuracy: 0.8178 - val_loss: 0.5878 - val_accuracy: 0.7981
Epoch 14/40
782/782 [==============================] - 284s 363ms/step - loss: 0.4881 - accuracy: 0.8274 - val_loss: 0.5716 - val_accuracy: 0.8056
Epoch 15/40
782/782 [==============================] - 289s 370ms/step - loss: 0.4730 - accuracy: 0.8321 - val_loss: 0.5920 - val_accuracy: 0.8014
Epoch 16/40
782/782 [==============================] - 331s 423ms/step - loss: 0.4581 - accuracy: 0.8374 - val_loss: 0.5892 - val_accuracy: 0.8005
Epoch 17/40
782/782 [==============================] - 272s 348ms/step - loss: 0.4394 - accuracy: 0.8434 - val_loss: 0.5592 - val_accuracy: 0.8095
Epoch 18/40
782/782 [==============================] - 269s 344ms/step - loss: 0.4253 - accuracy: 0.8488 - val_loss: 0.5580 - val_accuracy: 0.8139
Epoch 19/40
782/782 [==============================] - 296s 378ms/step - loss: 0.4098 - accuracy: 0.8548 - val_loss: 0.5629 - val_accuracy: 0.8128
Epoch 20/40
782/782 [==============================] - 290s 371ms/step - loss: 0.3983 - accuracy: 0.8574 - val_loss: 0.5820 - val_accuracy: 0.8075
Epoch 21/40
782/782 [==============================] - 270s 345ms/step - loss: 0.3898 - accuracy: 0.8616 - val_loss: 0.5691 - val_accuracy: 0.8119
Epoch 22/40
782/782 [==============================] - 307s 392ms/step - loss: 0.3791 - accuracy: 0.8642 - val_loss: 0.5596 - val_accuracy: 0.8137
Epoch 23/40
782/782 [==============================] - 308s 393ms/step - loss: 0.3712 - accuracy: 0.8687 - val_loss: 0.5546 - val_accuracy: 0.8186
Epoch 24/40
782/782 [==============================] - 285s 364ms/step - loss: 0.3537 - accuracy: 0.8734 - val_loss: 0.5523 - val_accuracy: 0.8210
Epoch 25/40
782/782 [==============================] - 265s 339ms/step - loss: 0.3509 - accuracy: 0.8742 - val_loss: 0.5577 - val_accuracy: 0.8182
Epoch 26/40
782/782 [==============================] - 268s 343ms/step - loss: 0.3405 - accuracy: 0.8776 - val_loss: 0.5586 - val_accuracy: 0.8193
Epoch 27/40
782/782 [==============================] - 255s 326ms/step - loss: 0.3295 - accuracy: 0.8825 - val_loss: 0.5367 - val_accuracy: 0.8214
Epoch 28/40
782/782 [==============================] - 257s 329ms/step - loss: 0.3228 - accuracy: 0.8850 - val_loss: 0.5467 - val_accuracy: 0.8218
Epoch 29/40
782/782 [==============================] - 255s 326ms/step - loss: 0.3157 - accuracy: 0.8873 - val_loss: 0.5434 - val_accuracy: 0.8236
Epoch 30/40
782/782 [==============================] - 257s 328ms/step - loss: 0.3114 - accuracy: 0.8877 - val_loss: 0.5638 - val_accuracy: 0.8191
Epoch 31/40
782/782 [==============================] - 257s 328ms/step - loss: 0.3008 - accuracy: 0.8928 - val_loss: 0.5505 - val_accuracy: 0.8216
Epoch 32/40
782/782 [==============================] - 259s 331ms/step - loss: 0.2959 - accuracy: 0.8946 - val_loss: 0.5443 - val_accuracy: 0.8233
Epoch 33/40
782/782 [==============================] - 254s 325ms/step - loss: 0.2868 - accuracy: 0.8981 - val_loss: 0.5613 - val_accuracy: 0.8236
Epoch 34/40
782/782 [==============================] - 256s 328ms/step - loss: 0.2814 - accuracy: 0.8997 - val_loss: 0.5470 - val_accuracy: 0.8273
Epoch 35/40
782/782 [==============================] - 255s 326ms/step - loss: 0.2757 - accuracy: 0.9017 - val_loss: 0.5507 - val_accuracy: 0.8251
Epoch 36/40
782/782 [==============================] - 258s 330ms/step - loss: 0.2743 - accuracy: 0.9022 - val_loss: 0.5510 - val_accuracy: 0.8255
Epoch 37/40
782/782 [==============================] - 255s 326ms/step - loss: 0.2691 - accuracy: 0.9044 - val_loss: 0.5577 - val_accuracy: 0.8203
Epoch 38/40
782/782 [==============================] - 254s 325ms/step - loss: 0.2629 - accuracy: 0.9055 - val_loss: 0.5465 - val_accuracy: 0.8277
Epoch 39/40
782/782 [==============================] - 255s 326ms/step - loss: 0.2602 - accuracy: 0.9066 - val_loss: 0.5584 - val_accuracy: 0.8239
Epoch 40/40
782/782 [==============================] - 261s 333ms/step - loss: 0.2541 - accuracy: 0.9082 - val_loss: 0.5691 - val_accuracy: 0.8238
[INFO] evaluating network....
precision recall f1-score support
airplane 0.86 0.82 0.84 1000
automobile 0.92 0.91 0.91 1000
bird 0.77 0.72 0.74 1000
cat 0.68 0.69 0.68 1000
deer 0.76 0.81 0.78 1000
dog 0.77 0.73 0.75 1000
frog 0.79 0.91 0.85 1000
horse 0.92 0.83 0.87 1000
ship 0.90 0.92 0.91 1000
truck 0.89 0.90 0.89 1000
accuracy 0.82 10000
macro avg 0.83 0.82 0.82 10000
weighted avg 0.83 0.82 0.82 10000
機器比較老,跑了近三個小時才跑完,
看loss圖吧,
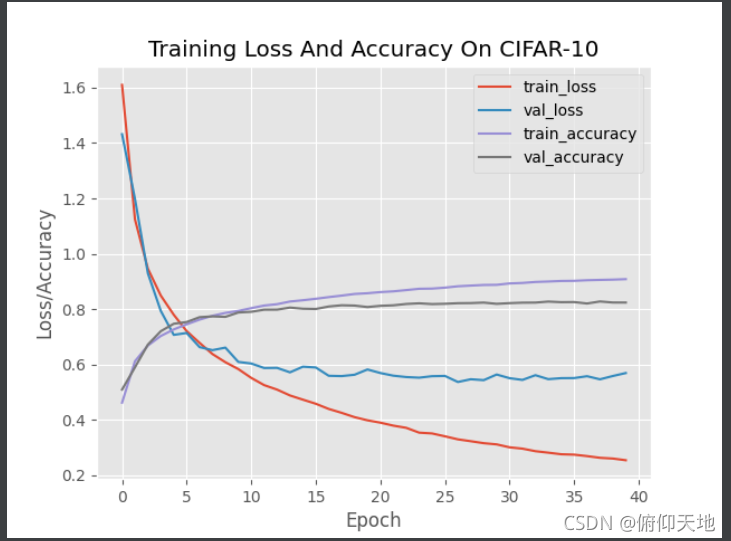
取消BN
? 上面的程式中,我們在每一個relu激活函式后面都加上了一層BN,如果去掉這一層BN,效果會是什么樣的呢?接下來我們就注釋掉模型中的BN層,然后再次運行,
from keras.models import Sequential
from keras.layers import BatchNormalization
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Flatten
from keras.layers.core import Dense
from keras.layers.core import Dropout
from keras import backend as K
class MiniVGGNet:
@staticmethod
def build(width, height, depth, classes):
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
if K.image_data_format == "channels_first":
inputShape = (depth, height, width)
chanDim = 1
model.add(Conv2D(32, (3, 3), padding="same", input_shape=inputShape))
model.add(Activation("relu"))
#model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(32, (3, 3), padding="same"))
model.add(Activation("relu"))
#model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
#model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
#model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation("relu"))
#model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(classes))
model.add(Activation("softmax"))
return model
? 從結果可以明顯的看出,在沒有BN層的情況下我們網路的訓練速度比之前快了許多,但是我們的分類準確率也有所下降,甚至還有一些過擬合的跡象,
結論
推薦在網路結構中加入BN,可以提升準確率,控制過擬合,讓網路更加穩定,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/333524.html
標籤:其他
下一篇:Qt+YOLOv4實作目標檢測