目錄
一、機器學習(ML)簡介
1. 人工智能、機器學習、深度學習的關系
2. 機器學習與深度學習的比較
2.1、應用場景
2.2、所需資料量
2.3、執行時間
2.4、解決問題的方法
3. 監督學習(Supervised Learning)
4. 無監督學習(Unsupervised Learning)(如:聚類)
5.一些符號代表一些定義:
二、線性回歸
1. Python設計的一些第三方庫的使用
1.1 簡單的練習
2.單變數的線性回歸
2.1 Plotting the data
2.2 代價函式(cost function)
2.3 梯度下降
2.4 關于矩陣的一些知識
2.5 實作梯度下降演算法在線性回歸中的應用
?
?
3. 多變數(多特征)的線性回歸
3.1 Notation ?
3.2 多元梯度下降法
3.3 向量化
3.4 特征縮放?
3.5 學習率α
3.6 特征和多項式回歸
3.7 正規方程(區別于迭代方法求J(?)min的直接解法)
3.8 正規方程之矩陣不可逆情況下的解決方法
3.9 多變數線性回歸應用
三、分類
1. logistic 回歸(邏輯回歸)?
1.1 假設陳述
1.2 決策界限
1.3 代價函式
1.4 簡化代價函式與梯度下降
2. 邏輯回歸的應用
2.1 資料可視化
2.2 sigmoid 函式
2.3 代價函式和梯度
2.4 用工具庫計算θ的值
2.5 評價邏輯回歸模型
3. 正則化邏輯回歸
3.1 資料可視化
3.2 特征映射
?
3.3 代價函式和梯度
3.4 用工具庫求解引數
3.5 畫出決策的曲線
?
3.6 改變λ,觀察決策曲線
一、機器學習(ML)簡介
1. 人工智能、機器學習、深度學習的關系
機器學習是人工智能的子領域,也是人工智能的核心,它囊括了幾乎所有對世界影響最大的方法(包括深度學習),
機器學習理論主要是設計和分析一些讓計算機可以自動學習的演算法,
深度學習(DeepLearning,DL)屬于機器學習的子類,它的靈感來源于人類大腦的作業方式,是利用深度神經網路來解決特征表達的一種學習程序,
深度神經網路本身并非是一個全新的概念,可理解為包含多個隱含層的神經網路結構,為了提高深層神經網路的訓練效果,人們對神經元的連接方法以及激活函式等方面做出了調整,其目的在于建立、模擬人腦進行分析學習的神經網路,模仿人腦的機制來解釋資料,如文本、影像、聲音,
概括來說:人工智能包括機器學習,機器學習包括深度學習
2. 機器學習與深度學習的比較
2.1、應用場景
機器學習在指紋識別、特征物體檢測等領域的應用基本達到了商業化的要求,
深度學習主要應用于文字識別、人臉技術、語意分析、智能監控等領域,目前在智能硬體、教育、醫療等行業也在快速布局,
2.2、所需資料量
機器學習能夠適應各種資料量,特別是資料量較小的場景,
如果資料量迅速增加,那么深度學習的效果將更加突出,這是因為深度學習演算法需要大量資料才能完美理解,
2.3、執行時間
執行時間是指訓練演算法所需要的時間量,
一般來說,深度學習演算法需要大量時間進行訓練,這是因為該演算法包含有很多引數,因此訓練它們需要比平時更長的時間,
相對而言,機器學習演算法的執行時間更少,
2.4、解決問題的方法
機器學習演算法遵循標準程式以解決問題,它將問題拆分成數個部分,對其進行分別解決,而后再將結果結合起來以獲得所需的答案,
深度學習則以集中方式解決問題,而不必進行問題拆分,
世界上最大的MOOC平臺
3. 監督學習(Supervised Learning)
指我們給演算法一個資料集,其中包含了正確答案,演算法的目的就是給出更多的正確答案,也被成為 回歸問題(Regression)
回歸問題:目的 預測連續的數值輸出,
分類問題:目的 預測離散值得輸出,
在監督學習中,我們有一個資料集,它被稱為一個訓練集,
4. 無監督學習(Unsupervised Learning)(如:聚類)
吳恩達建議:先用Octave建立起原型,再用其他編程語言(Python)實作速度會大大提高效率!(可以試一試)
無監督學習:指(給定一組無標簽的資料集)根據類別未知(沒有被標記)的訓練樣本解決模式識別中的各種問題,
5.一些符號代表一些定義:
m:表示訓練樣本的數量
x:代表輸入變數(或輸入特征)
y:代表輸出變數(即需要預測的目標變數)
(x,y):表示一個訓練樣本
(x^(i), y^(i)):表示第i個訓練樣本
h(hypothesis<假設>):表示假設函式
二、線性回歸
1. Python設計的一些第三方庫的使用
numpy教程
pandas教程
matplotlib教程
1.1 簡單的練習
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
A = np.eye(5)
A運行結果:
array([[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1.]])
2.單變數的線性回歸
這個部分需要根據城市人口數量,預測開小吃店的利潤,
資料在ex1data1.txt里,第一列是城市人口數量,第二列是該城市小吃店利潤,
2.1 Plotting the data
讀入資料,然后展示資料
資料說明
ex1data1.txt需要根據學生的2次測驗成績,預測該學生是否被錄取,第一列是第一次測驗成績,第二列是第二次測驗成績
path = 'E:/Python/machine learning/data/ex1_data1.txt'
data = pd.read_csv(path, header=None, names=['Population', 'Profit'])
data.head() # head()是觀察前5行
# 運行結果如下圖| Population | Profit | |
|---|---|---|
| 0 | 6.1101 | 17.5920 |
| 1 | 5.5277 | 9.1302 |
| 2 | 8.5186 | 13.6620 |
| 3 | 7.0032 | 11.8540 |
| 4 | 5.8598 | 6.8233 |
data.plot(kind='scatter', x='Population', y='Profit', figsize=(12,8)) #figsize(a,b)設定圖形的大小,a為圖形的寬,b為圖形的高,單位為英寸
plt.show() # scatter代表散點圖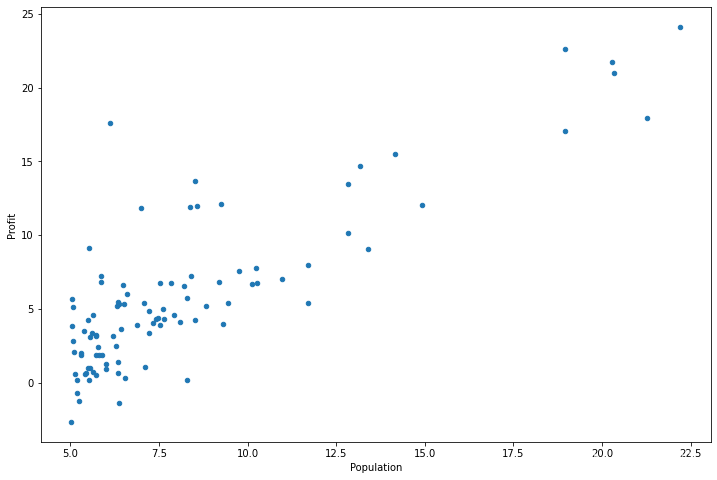
2.2 代價函式(cost function)
有時也叫平方誤差函式(square error function),或者平方誤差代價函式(square error cost function),
對于大多數問題,特別是回歸問題,都是一個合理的選擇,
一個好的代價函式需要滿足兩個最基本的要求:能夠評價模型的準確性,對引數θ可微,
在線性回歸中,最常用的是均方誤差(Mean squared error),具體形式為:
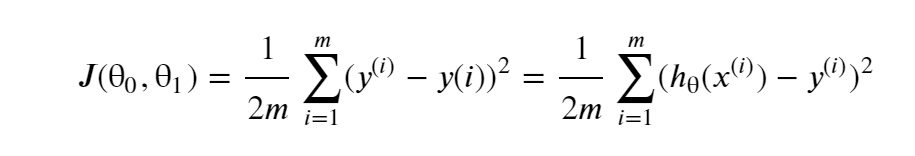
m:訓練樣本的個數;
hθ(x):用引數θ和x預測出來的y值;
y:原訓練樣本中的y值,也就是標準答案
上角標(i):第i個樣本
目標:找到θ0,θ1使J(θ)的值最小,目標函式:minmizeJ(θ)
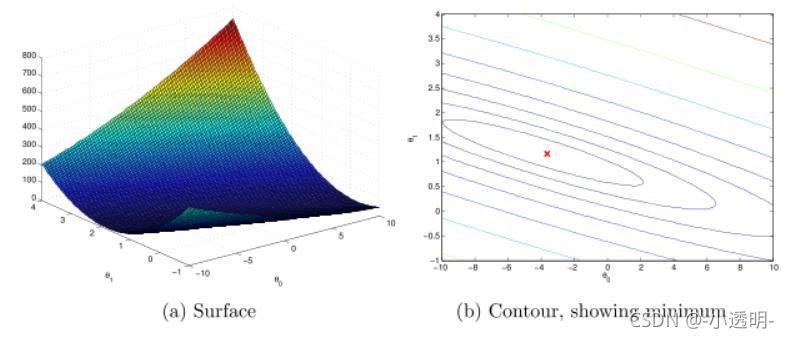
影像:通常用等高線圖表示,J(θ)是一個碗狀的圖形,并且有全域最小值,全域最小值就是θ0和θ1的最優解,梯度下降的每一步都會更接近這個最小值
2.3 梯度下降
這個部分你需要在現有資料集上,訓練線性回歸的引數θ
公式: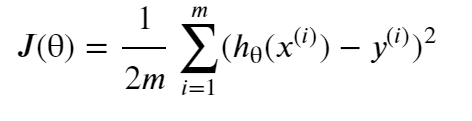
如下圖所示梯度下降演算法的定義,不斷更新θj,直到收斂,

其中 := 表示賦值; =表示真偽判斷;α表示學習速率,來控制梯度下降時,“邁的步子”,α越大,下降越快;α太小,收斂速度太慢,α太大,會導致無法收斂甚至發散,當達到最優解時,偏導數為0,θ收斂
微妙之處:1.看for可得,需要同時更新θ0和θ1;2.不必減小α,因為當越來越接近最優解時,偏導數會變得越來越小!!!

2.4 關于矩陣的一些知識
矩陣和向量
矩陣(matrix)的維度 = 行數 x 列數
向量(vector):rows x 1 維度的矩陣
通常用大寫字母表示 矩陣 ,用 y 表示向量
矩陣的加法 和 與標量的乘法
兩個矩陣相加:對應位置元素相加即可
標量矩陣 = 矩陣中每個元素都標量(除法同理)
與矩陣乘法
矩陣前提:一個矩陣的列數=另一個矩陣的行數
A1 x A2 = A1行對應的元素 x A2列對應的元素 然后相加求和 得:rowsA1 x colsA2維度的矩陣
矩陣乘法的特性
A x B != B x A
A x B x C == A x (B x C) == (A x B) x C
單位矩陣:I(n*n) A x I == I x A
矩陣的逆(inverse)和轉置(transpose)
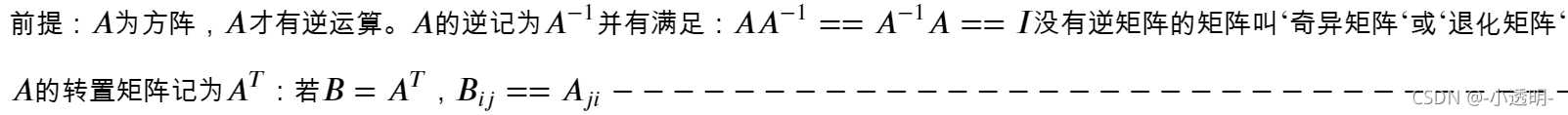
2.5 實作梯度下降演算法在線性回歸中的應用
#資料前面已經讀取完畢,我們要為加入一列x,用于更新?,然后我們將?初始化為0,學習率初始化為0.01,迭代次數為1500次
data.insert(0, 'Ones', 1)
# 初始化x,y
cols = data.shape[1]
X = data.iloc[:,:-1] #X是data里的除最后列
y = data.iloc[:,cols-1:cols] #y是data最后一列
# 觀察下 X (訓練集) and y (目標變數)是否正確.
X.head() 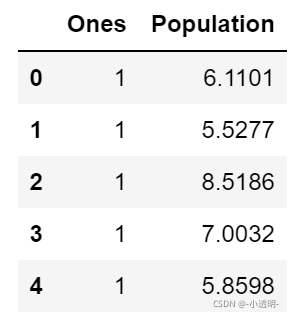
y.head() 
# 代價函式應該是numpy矩陣,所以我們需要轉換X和Y,然后才能使用它們, 我們還需要初始化theta,
X = np.matrix(X.values)
y = np.matrix(y.values)
theta = np.matrix(np.array([0,0]))
#看下維度
X.shape, theta.shape, y.shape
((97, 2), (1, 2), (97, 1))
#這個部分計算J(?),X是矩陣
def computeCost(X, y, theta):
inner = np.power(((X * theta.T) - y), 2)
return np.sum(inner) / (2 * len(X))
#2.2.3計算J(θ)計算代價函式 (theta初始值為0)
computeCost(X, y, theta)32.072733877455676
#2.2.4梯度下降
'''記住J(θ)的變數是θ,而不是X和y,意思是說,我們變化的值來使J(θ)變化,而不是變化X和y的值,
一個檢查梯度下降是不是在正常運作的方式,是列印出每一步J(θ)的值,看他是不是一直都在減小,并且最后收斂至一個穩定的值,
最后的結果會用來預測小吃店在35000及70000人城市規模的利潤,'''
#這個部分實作了?的更新
def gradientDescent(X, y, theta, alpha, iters):
temp = np.matrix(np.zeros(theta.shape))
parameters = int(theta.ravel().shape[1])
cost = np.zeros(iters)
for i in range(iters):
error = (X * theta.T) - y
for j in range(parameters):
term = np.multiply(error, X[:,j])
temp[0,j] = theta[0,j] - ((alpha / len(X)) * np.sum(term))
theta = temp
cost[i] = computeCost(X, y, theta)
return theta, cost
#初始化一些附加變數 - 學習速率α和要執行的迭代次數,2.2.2中已經提到,
alpha = 0.01
iters = 1500
#現在讓我們運行梯度下降演算法來將我們的引數θ適合于訓練集,
g, cost = gradientDescent(X, y, theta, alpha, iters)
gmatrix([[-3.63029144, 1.16636235]])
#預測35000和70000城市規模的小吃攤利潤
predict1 = [1,3.5]*g.T
print("predict1:",predict1)
predict2 = [1,7]*g.T
print("predict2:",predict2)predict1: [[0.45197679]] predict2: [[4.53424501]]
x = np.linspace(data.Population.min(), data.Population.max(), 100)
f = g[0, 0] + (g[0, 1] * x)
#原始資料以及擬合的直線
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(x, f, 'r', label='Prediction')
ax.scatter(data.Population, data.Profit, label='Traning Data')
ax.legend(loc=2)
ax.set_xlabel('Population')
ax.set_ylabel('Profit')
ax.set_title('Predicted Profit vs. Population Size')
plt.show()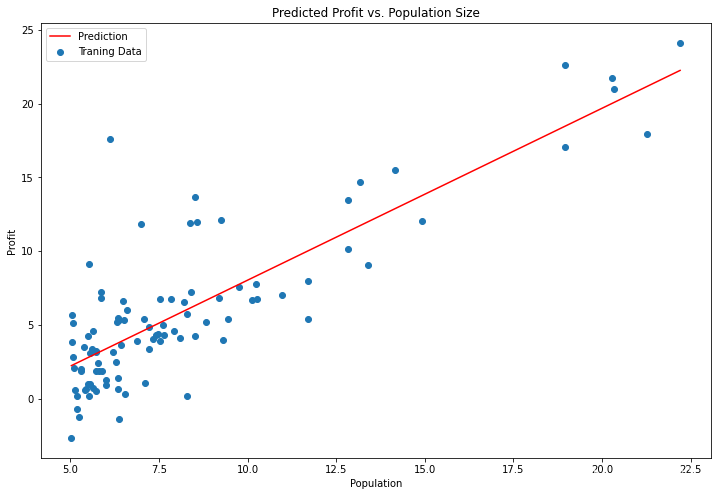
3. 多變數(多特征)的線性回歸
3.1 Notation 
3.2 多元梯度下降法
上面的假設函式的引數:?0~?n看做一個n+1維的向量
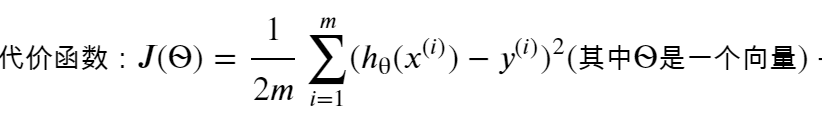

3.3 向量化
在很多特征時,用回圈實作?的更新很慢,用向量代替上圖式子中?-的內個求和式,再用代碼可以更簡潔的實作并且提高速度
3.4 特征縮放?
當 不同特征的取值在相近的范圍內,這樣梯度下降就能更好的收斂, 所以,當范圍相差太大的時候,可以使用特征縮放的方法,以兩個特征量為例理解:

通常將特征的取值約束在 -1到+1 的范圍內,本身范圍很近超一點點的也是ok的,
x>>1 / <0x<<1 / x<<-1 / -1<<x<0都是不合適的
均值歸一化(Mean normalization)
do:(xi-μi)/Si (μi:x的平均值,Si:范圍大小(最大-最小)) 讓你的特征值具有為0的平均值(x0除外,x0永遠為1)
3.5 學習率α
首先通過 J(?) 關于迭代次數的曲線圖檢驗演算法是否執行正常,當曲線成上升趨勢時,很可能是 α 太大了
選α時,try:α=0.001/0.003/0.01/0.03/0.1/0.3/1...(通常每隔大約3倍取一個值),然后通過繪制J(?)與迭代次數的曲線,選擇使J(?)下降最快的α值
3.6 特征和多項式回歸
特征可以任意選擇(例如:已知特征長和寬,可以定義長*寬作為新的特征):有演算法可以自動識別選擇什么特征特征,后面會學習,
多項式回歸:(需要注意每個變數的范圍會差很多,需要特征縮放)
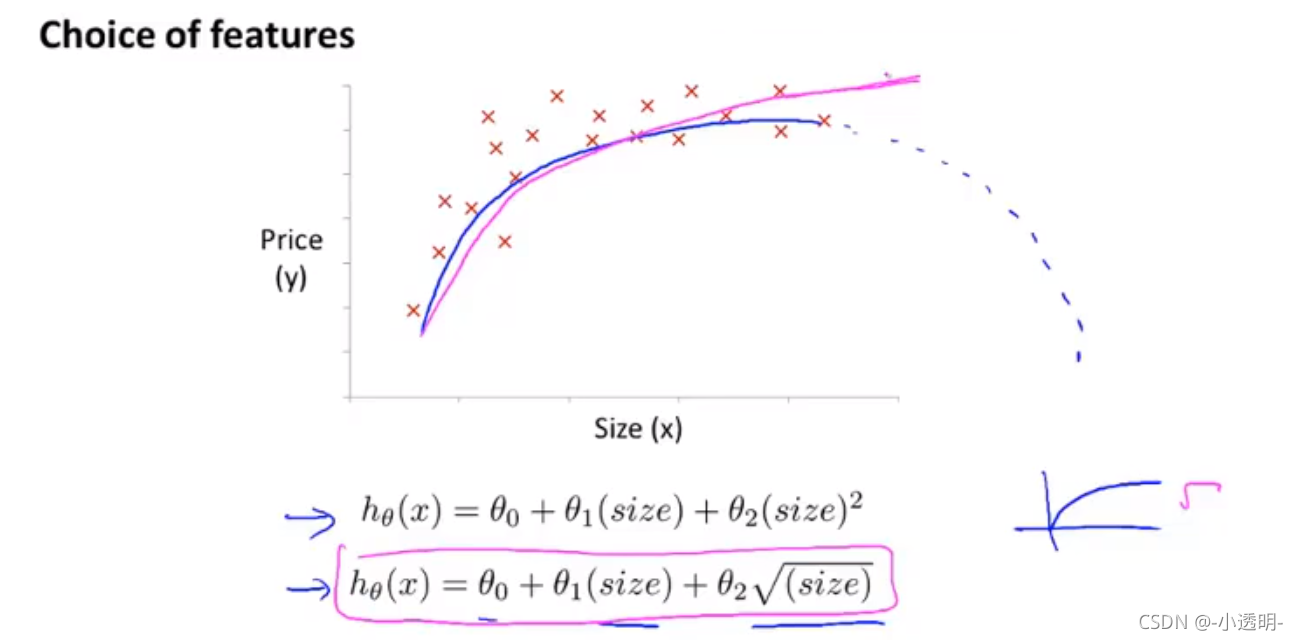
3.7 正規方程(區別于迭代方法求J(?)min的直接解法)
正規方程法:可以一步得到最優解 (原理:?為實數時,求導;?為向量時,對每一個?求偏導,)
此方法不需要特征縮放,
n越大,計算X的轉置和逆時間(O(n^3))越長,該方法在后面學學習的更復雜的演算法中不能用,梯度下降演算法更為常用,該演算法是特定模型下的替代演算法,
選擇:通常,當n>1百萬時,選擇梯度下降法或其他演算法;當n<10000時,選擇正規方程法,
3.8 正規方程之矩陣不可逆情況下的解決方法
原因:1.有多余的特征 2.特征太多(m<=n時)
解決:尋找是否有線性關系的特征,刪掉一個;否則,如果有太多特征,刪去一些不影響的或考慮使用正規化方法,
3.9 多變數線性回歸應用
ex1data2.txt里的資料,第一列是房屋大小,第二列是臥室數量,第三列是房屋售價
根據已有資料,建立模型,預測房屋的售價
path = 'E:/Python/machine learning/data/ex1_data2.txt'
data2 = pd.read_csv(path, header=None, names=['Size', 'Bedrooms', 'Price'])
data2.head()| Size | Bedrooms | Price | |
|---|---|---|---|
| 0 | 2104 | 3 | 399900 |
| 1 | 1600 | 3 | 329900 |
| 2 | 2400 | 3 | 369000 |
| 3 | 1416 | 2 | 232000 |
| 4 | 3000 | 4 | 539900 |
特征歸一化?
觀察資料發現,size變數是bedrooms變數的1000倍大小,統一量級會讓梯度下降收斂的更快,做法就是,將每類特征減去他的平均值后除以標準差,
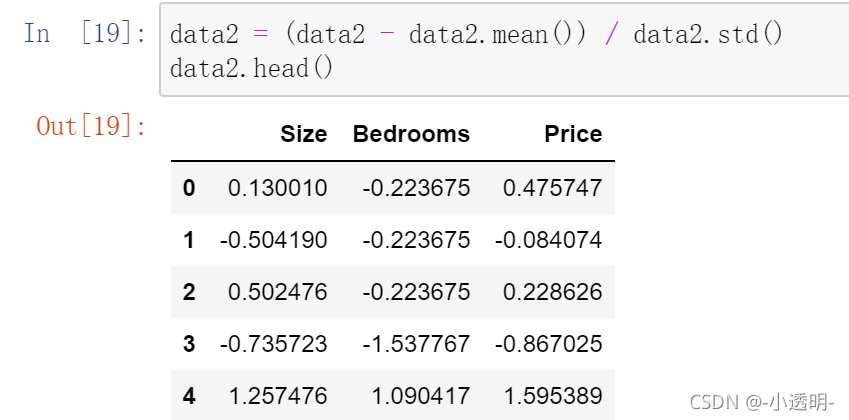
梯度下降
# 加一列常數項
data2.insert(0, 'Ones', 1)
# 初始化X和y
cols = data2.shape[1]
X2 = data2.iloc[:,0:cols-1]
y2 = data2.iloc[:,cols-1:cols]
# 轉換成matrix格式,初始化theta
X2 = np.matrix(X2.values)
y2 = np.matrix(y2.values)
theta2 = np.matrix(np.array([0,0,0]))
# 運行梯度下降演算法
g2, cost2 = gradientDescent(X2, y2, theta2, alpha, iters)
g2matrix([[-1.10898288e-16, 8.84042349e-01, -5.24551809e-02]])
# 正規方程
def normalEqn(X, y):
theta = np.linalg.inv(X.T@X)@X.T@y# X.T@X等價于X.T.dot(X)
return theta
final_theta2=normalEqn(X, y)#這里用的是data1的資料
final_theta2
matrix([[-3.89578088],
[ 1.19303364]])
梯度下降得到的結果是matrix([[-3.24140214, 1.1272942 ]])
三、分類
對于要預測的變數y為離散值時的分類問題,一種新的分類演算法:logistic 回歸演算法,該演算法:0<=h(?)<=1
二分類:y∈{0,1},多分類:y∈{1,2,...}(一些離散的值)
1. logistic 回歸(邏輯回歸)?
1.1 假設陳述
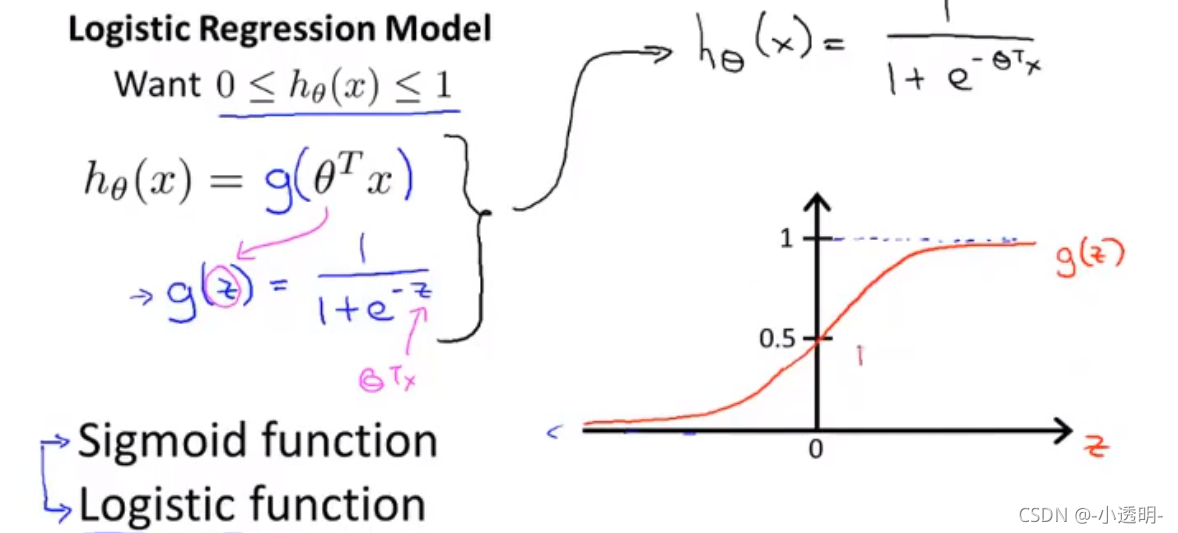
1.2 決策界限
決策邊界是假設函式的一個屬性,決定于假設函式的引數?的取值,不取決于資料集,是兩個取值樣本的分界線,
1.3 代價函式
即如何擬合邏輯回歸模型的引數?,通過資料集,確定?
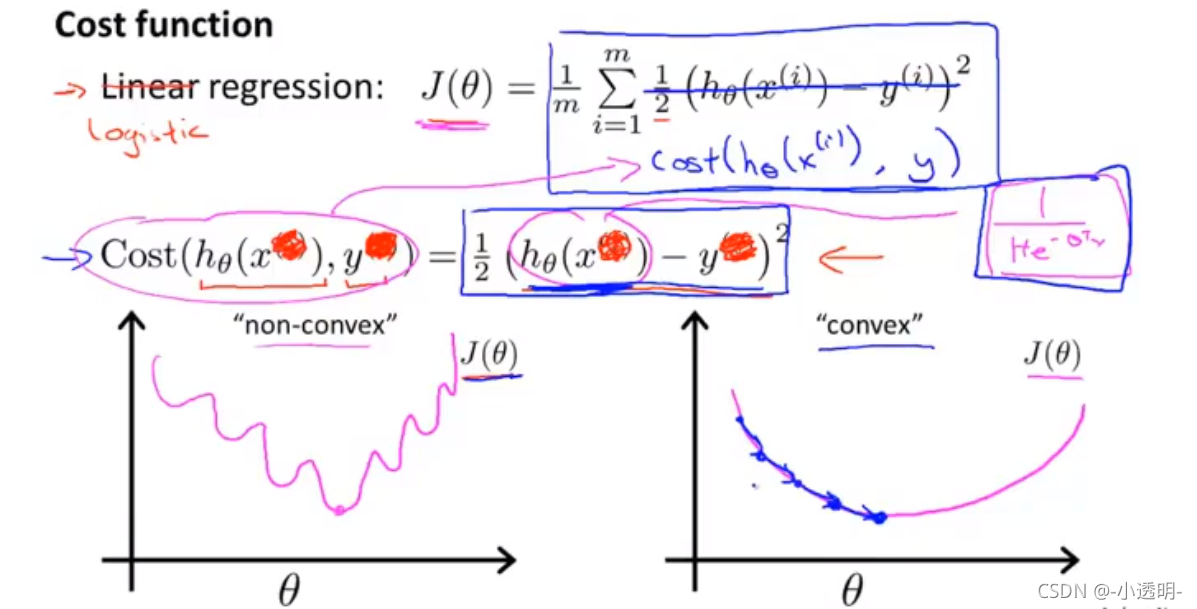
J(?)為非凹函式,無法得到區域最優解

1.4 簡化代價函式與梯度下降

上面的特征縮放仍然適用于邏輯回歸
2. 邏輯回歸的應用
在訓練的初始階段,我們將要構建一個邏輯回歸模型來預測,某個學生是否被大學錄取,設想你是大學相關部分的管理者,想通過申請學生兩次測驗的評分,來決定他們是否被錄取,現在你擁有之前申請學生的可以用于訓練邏輯回歸的訓練樣本集,對于每一個訓練樣本,你有他們兩次測驗的評分和最后是被錄取的結果,
2.1 資料可視化
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
path = 'E:/Python/machine learning/data/ex2_data1.txt'
data = pd.read_csv(path, header=None, names=['Exam 1', 'Exam 2', 'Admitted'])
data.head()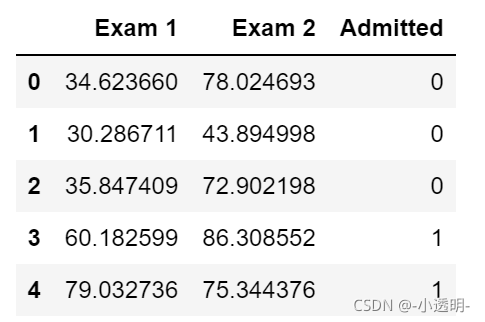
positive = data[data['Admitted'].isin([1])]
negative = data[data['Admitted'].isin([0])]
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(positive['Exam 1'], positive['Exam 2'], s=50, c='b', marker='o', label='Admitted')
ax.scatter(negative['Exam 1'], negative['Exam 2'], s=50, c='r', marker='x', label='Not Admitted')
ax.legend()
ax.set_xlabel('Exam 1 Score')
ax.set_ylabel('Exam 2 Score')
plt.show() 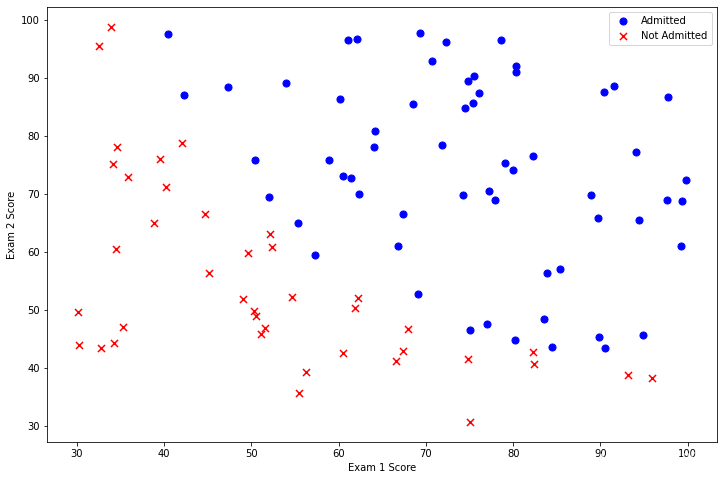
2.2 sigmoid 函式

# 實作sigmoid函式
def sigmoid(z):
return 1 / (1 + np.exp(-z))2.3 代價函式和梯度

# 實作代價函式
def cost(theta, X, y):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
first = np.multiply(-y, np.log(sigmoid(X * theta.T)))
second = np.multiply((1 - y), np.log(1 - sigmoid(X * theta.T)))
return np.sum(first - second) / (len(X))
# 加一列常數列
data.insert(0, 'Ones', 1)
# 初始化X,y,θ
cols = data.shape[1]
X = data.iloc[:,0:cols-1]
y = data.iloc[:,cols-1:cols]
theta = np.zeros(3)
# 轉換X,y的型別
X = np.array(X.values)
y = np.array(y.values)
# 檢查矩陣的維度
X.shape, theta.shape, y.shape
((100, 3), (3,), (100, 1))
# 用初始θ計算代價
cost(theta, X, y)0.6931471805599453
# 實作梯度計算的函式(并沒有更新θ)
def gradient(theta, X, y):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
parameters = int(theta.ravel().shape[1])
grad = np.zeros(parameters)
error = sigmoid(X * theta.T) - y
for i in range(parameters):
term = np.multiply(error, X[:,i])
grad[i] = np.sum(term) / len(X)
return grad2.4 用工具庫計算θ的值
在此前的線性回歸中,我們自己寫代碼實作的梯度下降(ex1的2.2.4的部分),當時我們寫了一個代價函式、計算了他的梯度,然后對他執行了梯度下降的步驟,這次,我們不自己寫代碼實作梯度下降,我們會呼叫一個已有的庫,這就是說,我們不用自己定義迭代次數和步長,功能會直接告訴我們最優解, andrew ng在課程中用的是Octave的“fminunc”函式,由于我們使用Python,我們可以用scipy.optimize.fmin_tnc做同樣的事情, (另外,如果對fminunc有疑問的,可以參考下面這篇百度文庫的內容matlab最小值優化問題中fminunc、fmincon的應用 - 百度文庫 )
import scipy.optimize as opt
result = opt.fmin_tnc(func=cost, x0=theta, fprime=gradient, args=(X, y))
result(array([-25.16131863, 0.20623159, 0.20147149]), 36, 0)
# 用θ的計算結果代回代價函式計算
cost(result[0], X, y)0.20349770158947458
# 畫出決策曲線
plotting_x1 = np.linspace(30, 100, 100)
plotting_h1 = ( - result[0][0] - result[0][1] * plotting_x1) / result[0][2]
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(plotting_x1, plotting_h1, 'y', label='Prediction')
ax.scatter(positive['Exam 1'], positive['Exam 2'], s=50, c='b', marker='o', label='Admitted')
ax.scatter(negative['Exam 1'], negative['Exam 2'], s=50, c='r', marker='x', label='Not Admitted')
ax.legend()
ax.set_xlabel('Exam 1 Score')
ax.set_ylabel('Exam 2 Score')
plt.show()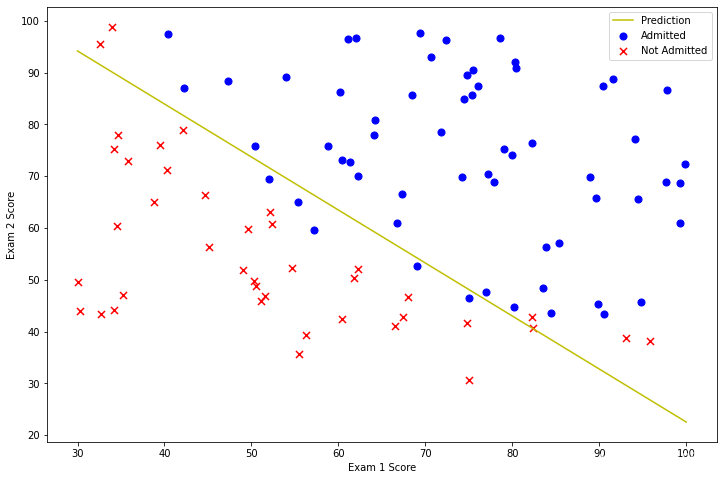
2.5 評價邏輯回歸模型
在確定引數之后,我們可以使用這個模型來預測學生是否錄取,如果一個學生exam1得分45,exam2得分85
# 實作hθ
def hfunc1(theta, X):
return sigmoid(np.dot(theta.T, X))
hfunc1(result[0],[1,45,85])0.7762906240463825
另一種評價θ的方法是看模型在訓練集上的正確率怎樣,寫一個predict的函式,給出資料以及引數后,會回傳“1”或者“0”,然后再把這個predict函式用于訓練集上,看準確率怎樣,
# 定義預測函式
def predict(theta, X):
probability = sigmoid(X * theta.T)
return [1 if x >= 0.5 else 0 for x in probability]
# 統計預測正確率
theta_min = np.matrix(result[0])
predictions = predict(theta_min, X)
correct = [1 if ((a == 1 and b == 1) or (a == 0 and b == 0)) else 0 for (a, b) in zip(predictions, y)]
accuracy = (sum(map(int, correct)) % len(correct))
print ('accuracy = {0}%'.format(accuracy))accuracy = 89%
3. 正則化邏輯回歸
在訓練的第二部分,我們將實作加入正則項提升邏輯回歸演算法, 設想你是工廠的生產主管,你有一些芯片在兩次測驗中的測驗結果,測驗結果決定是否芯片要被接受或拋棄,你有一些歷史資料,幫助你構建一個邏輯回歸模型,
3.1 資料可視化
path = 'E:/Python/machine learning/data/ex2_data2.txt'
data_init = pd.read_csv(path, header=None, names=['Test 1', 'Test 2', 'Accepted'])
data_init.head()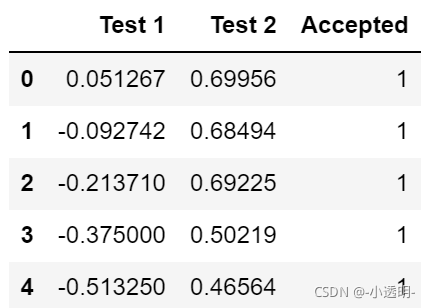
positive2 = data_init[data_init['Accepted'].isin([1])]
negative2 = data_init[data_init['Accepted'].isin([0])]
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(positive2['Test 1'], positive2['Test 2'], s=50, c='b', marker='o', label='Accepted')
ax.scatter(negative2['Test 1'], negative2['Test 2'], s=50, c='r', marker='x', label='Rejected')
ax.legend()
ax.set_xlabel('Test 1 Score')
ax.set_ylabel('Test 2 Score')
plt.show()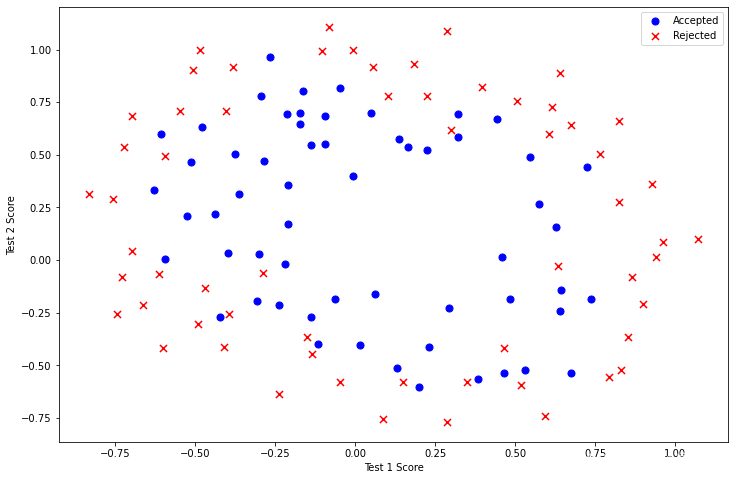
以上圖片顯示,這個資料集不能像之前一樣使用直線將兩部分分割,而邏輯回歸只適用于線性的分割,所以,這個資料集不適合直接使用邏輯回歸,
3.2 特征映射
一種更好的使用資料集的方式是為每組資料創造更多的特征,所以我們為每組添加了最高到6次冪的特征
degree = 6
data2 = data_init
x1 = data2['Test 1']
x2 = data2['Test 2']
data2.insert(3, 'Ones', 1)
for i in range(1, degree+1):
for j in range(0, i+1):
data2['F' + str(i-j) + str(j)] = np.power(x1, i-j) * np.power(x2, j)
#此處原答案錯誤較多,已經更正
data2.drop('Test 1', axis=1, inplace=True)
data2.drop('Test 2', axis=1, inplace=True)
data2.head()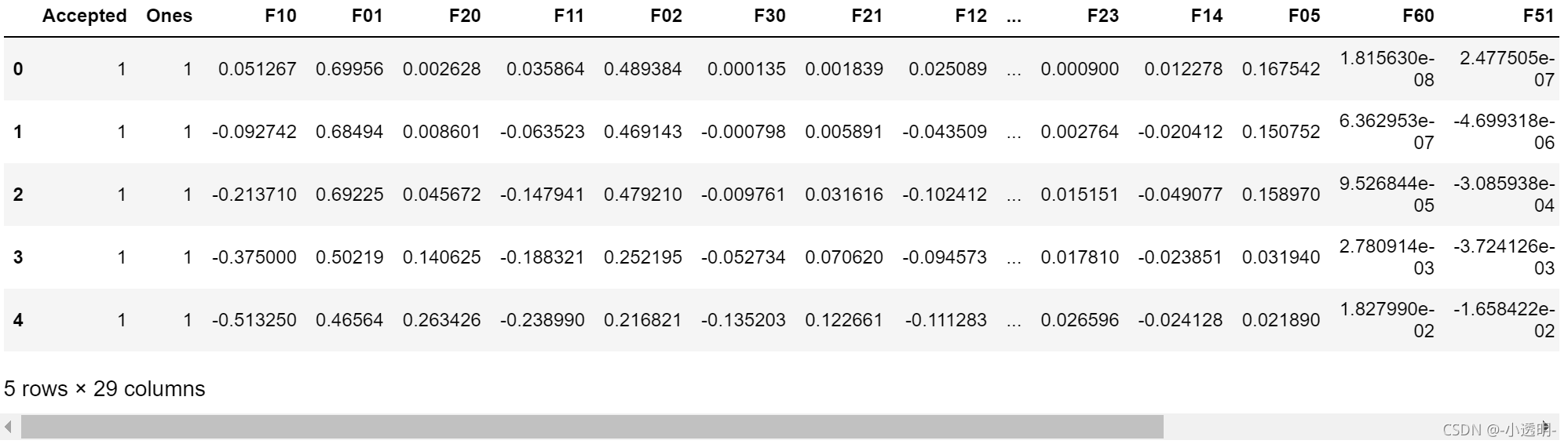
3.3 代價函式和梯度
在原來的基礎上加上正則項(縮小每一個?) 記住?0是不需要正則化的,下標從1開始, 梯度的第j個元素的更新公式為:對上面的演算法中 j=1,2,...,n 時的更新式子進行調整可得:把初始(所有元素為0)帶入,代價應為0.693這一部分要實作計算邏輯回歸的代價函式和梯度的函式,代價函式公式如下:
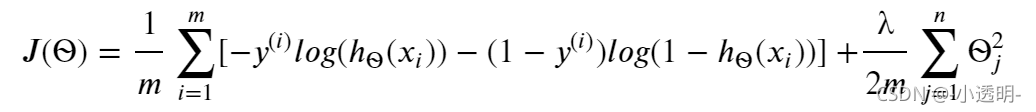
# 實作正則化的代價函式
def costReg(theta, X, y, learningRate):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
first = np.multiply(-y, np.log(sigmoid(X * theta.T)))
second = np.multiply((1 - y), np.log(1 - sigmoid(X * theta.T)))
reg = (learningRate / (2 * len(X))) * np.sum(np.power(theta[:,1:theta.shape[1]], 2))
return np.sum(first - second) / len(X) + reg
# 實作正則化的梯度函式
def gradientReg(theta, X, y, learningRate):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
parameters = int(theta.ravel().shape[1])
grad = np.zeros(parameters)
error = sigmoid(X * theta.T) - y
for i in range(parameters):
term = np.multiply(error, X[:,i])
if (i == 0):
grad[i] = np.sum(term) / len(X)
else:
grad[i] = (np.sum(term) / len(X)) + ((learningRate / len(X)) * theta[:,i])
return grad
# 初始化X,y,θ
cols = data2.shape[1]
X2 = data2.iloc[:,1:cols]
y2 = data2.iloc[:,0:1]
theta2 = np.zeros(cols-1)
# 進行型別轉換
X2 = np.array(X2.values)
y2 = np.array(y2.values)
# λ設為1
learningRate = 1
# 計算初始代價
costReg(theta2, X2, y2, learningRate)0.6931471805599454
3.4 用工具庫求解引數
result2 = opt.fmin_tnc(func=costReg, x0=theta2, fprime=gradientReg, args=(X2, y2, learningRate))
result2(array([ 1.27271027, 0.62529965, 1.18111686, -2.01987399, -0.9174319 ,
-1.43166929, 0.12393227, -0.36553118, -0.35725403, -0.17516292,
-1.45817009, -0.05098418, -0.61558552, -0.27469165, -1.19271298,
-0.24217841, -0.20603297, -0.04466178, -0.27778952, -0.29539513,
-0.45645981, -1.04319155, 0.02779373, -0.29244872, 0.01555761,
-0.32742406, -0.1438915 , -0.92467487]),32,1)
最后,我們可以使用第1部分中的預測函式來查看我們的方案在訓練資料上的準確度,
theta_min = np.matrix(result2[0])
predictions = predict(theta_min, X2)
correct = [1 if ((a == 1 and b == 1) or (a == 0 and b == 0)) else 0 for (a, b) in zip(predictions, y2)]
accuracy = (sum(map(int, correct)) % len(correct))
print ('accuracy = {0}%'.format(accuracy))accuracy = 98%
3.5 畫出決策的曲線
def hfunc2(theta, x1, x2):
temp = theta[0][0]
place = 0
for i in range(1, degree+1):
for j in range(0, i+1):
temp+= np.power(x1, i-j) * np.power(x2, j) * theta[0][place+1]
place+=1
return temp
def find_decision_boundary(theta):
t1 = np.linspace(-1, 1.5, 1000)
t2 = np.linspace(-1, 1.5, 1000)
cordinates = [(x, y) for x in t1 for y in t2]
x_cord, y_cord = zip(*cordinates)
h_val = pd.DataFrame({'x1':x_cord, 'x2':y_cord})
h_val['hval'] = hfunc2(theta, h_val['x1'], h_val['x2'])
decision = h_val[np.abs(h_val['hval']) < 2 * 10**-3]
return decision.x1, decision.x2
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(positive2['Test 1'], positive2['Test 2'], s=50, c='b', marker='o', label='Accepted')
ax.scatter(negative2['Test 1'], negative2['Test 2'], s=50, c='r', marker='x', label='Rejected')
ax.set_xlabel('Test 1 Score')
ax.set_ylabel('Test 2 Score')
x, y = find_decision_boundary(result2)
plt.scatter(x, y, c='y', s=10, label='Prediction')
ax.legend()
plt.show()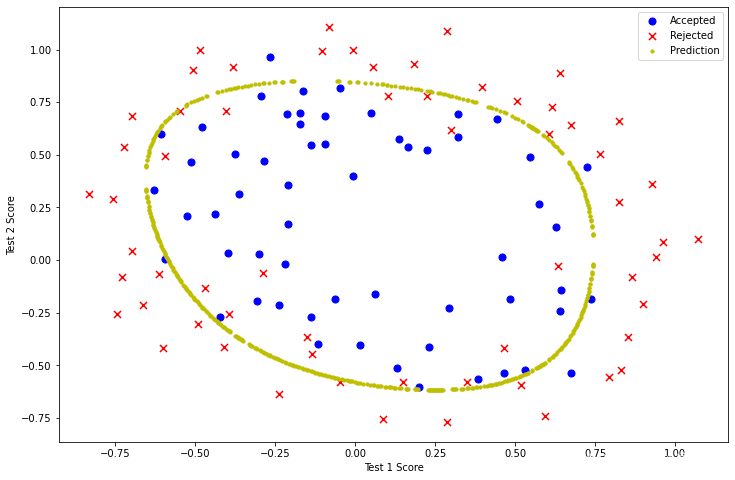
3.6 改變λ,觀察決策曲線
λ=0時 過擬合
learningRate2 = 0
result3 = opt.fmin_tnc(func=costReg, x0=theta2, fprime=gradientReg, args=(X2, y2, learningRate2))
result3(array([ 9.11192364e+00, 1.18840465e+01, 6.30828094e+00, -8.39706468e+01,
-4.48639810e+01, -3.81221435e+01, -9.42525756e+01, -8.14257602e+01,
-4.22413355e+01, -3.52968361e+00, 2.95734207e+02, 2.51308760e+02,
3.64155830e+02, 1.61036970e+02, 5.70100234e+01, 1.71716716e+02,
2.72109672e+02, 3.12447535e+02, 1.41764016e+02, 3.22495698e+01,
-1.75836912e-01, -3.58663811e+02, -4.82161916e+02, -7.49974915e+02,
-5.03764307e+02, -4.80978435e+02, -1.85566236e+02, -3.83936243e+01]),
280,
3)
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(positive2['Test 1'], positive2['Test 2'], s=50, c='b', marker='o', label='Accepted')
ax.scatter(negative2['Test 1'], negative2['Test 2'], s=50, c='r', marker='x', label='Rejected')
ax.set_xlabel('Test 1 Score')
ax.set_ylabel('Test 2 Score')
x, y = find_decision_boundary(result3)
plt.scatter(x, y, c='y', s=10, label='Prediction')
ax.legend()
plt.show()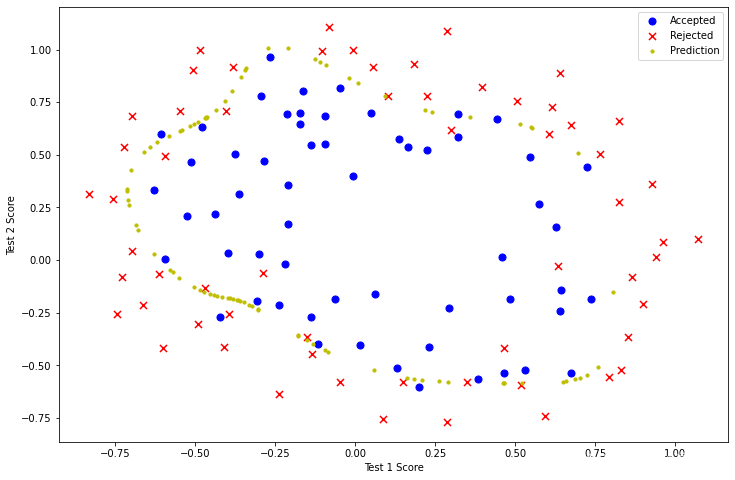
λ=100時欠擬合
learningRate3 = 100
result4 = opt.fmin_tnc(func=costReg, x0=theta2, fprime=gradientReg, args=(X2, y2, learningRate3))
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(positive2['Test 1'], positive2['Test 2'], s=50, c='b', marker='o', label='Accepted')
ax.scatter(negative2['Test 1'], negative2['Test 2'], s=50, c='r', marker='x', label='Rejected')
ax.set_xlabel('Test 1 Score')
ax.set_ylabel('Test 2 Score')
x, y = find_decision_boundary(result4)
plt.scatter(x, y, c='y', s=10, label='Prediction')
ax.legend()
plt.show()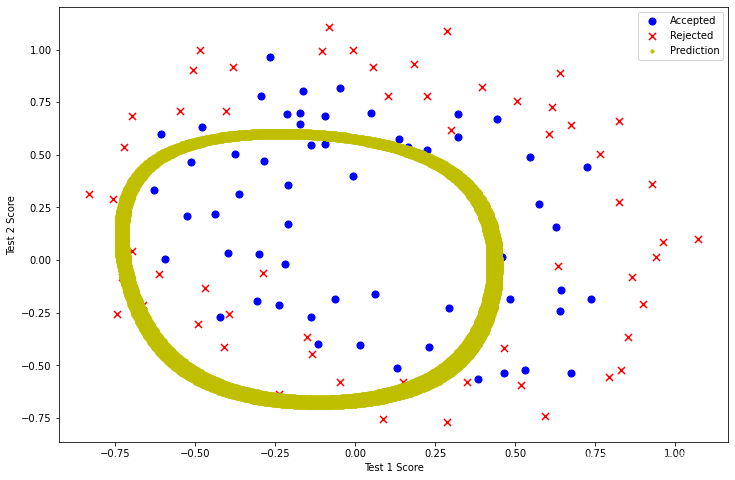
暑假大概就看這么多,先保存下來趴,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/333570.html
標籤:AI
下一篇:用TFIDF詞袋模型進行新聞分類