目錄
1 案例介紹
2 資料預處理
2.1 rle編碼轉換
2.2 資料擴增
2.3 例外資料的處理
3 自定義資料庫類
4 模型訓練
5 語意分割的準確率評價方法
3.1 像素準確率(PA)
3.2 類別像素準確率(CPA)
3.3 類別平均像素準確率(MPA)
3.4 交并比(IoU)
3.5 平均交并比(MIoU)
1 案例介紹
遙感技術已成為獲取地表覆寫資訊最為行之有效的手段,遙感技術已經成功應用于地表覆寫檢測、植被面積檢測和建筑物檢測任務,本賽題使用航拍資料,需要參賽選手完成地表建筑物識別,將地表航拍影像素劃分為有建筑物和無建筑物兩類,
如下圖,左邊為原始航拍圖,右邊為對應的建筑物標注,

本案例訓練集為航拍的地標建筑物,訓練集影像為30000張圖片,其中訓練集的標簽為rle序列的csv檔案,測驗集為2500個影像,
2 資料預處理
2.1 rle編碼轉換
RLE編碼是微軟開發為AVI格式開發的一種編碼,假設一個影像的像素色彩值是這樣排列的:紅紅紅紅紅紅紅紅紅紅紅紅藍藍藍藍藍藍綠綠綠綠,經過RLE壓縮后就成為了:紅12藍6綠4,這樣既保證了壓縮的可行性,而且不會有損失,而且可以看到,當顏色數越少時,壓縮效率會更高,
在本案例中,我們首先要對rle編碼進行讀取,將其轉換為jpg格式的圖片,
官方給出的解碼檔案可以將rle編碼序列轉化為一個numpy矩陣,轉碼函式如下:
我們首先對csv檔案進行讀取,保存到一個二維陣列中,
train_mask = pd.read_csv('../dataset/train_mask.csv/train_mask.csv', sep='\t', names=['name', 'mask'])
# 讀取第一張圖,并將對于的rle解碼為mask矩陣
img = cv2.imread('../dataset/train/' + train_mask['name'].iloc[0]) # name列的第0行
mask = rle_decode(train_mask['mask'].iloc[0])
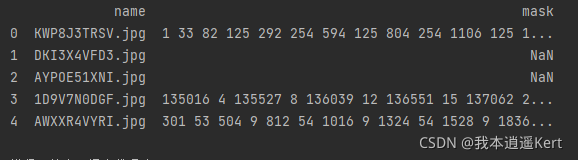
print(train_mask.head())train_mask['name'].lioc[0]:lioc用于提取行資料,整體含義為name列第0行資料
names欄位作用:命名csv檔案列名
train_mask.head()輸出檢驗列名,我們可以看到csv檔案如下:
我們通過觀察發現,轉碼后的變數是一個矩陣,我們將矩陣轉化為一個二值圖,再將其做為標簽存放,需要注意的是,矩陣中的值都是0或1,而二值圖的8位編碼范圍為0-255,這樣我們在觀察標簽的時候會看到幾乎全黑的情況,所以我們在得到輸出后的矩陣,一定要將其乘上255,
要注意的是二值圖和灰度圖的區別,二值圖是一種單通道影像,其矩陣形式只可表現為兩個數值;灰度圖是一種RGB三通道影像,每個通道的數值相等,它相比于二值圖更多的保留了原始影像的資訊,
for i in range(30000):
try:
train_mask = rle_decode(train_rle['mask'].iloc[i])
print(type(train_mask)) # 矩陣形式
train_mask = train_mask * 255
train_mask = train_mask.astype(np.uint8)
cv2.imwrite('D:\\00Com_TianChi\\dataset\\train\\build_label\\' + train_rle['name'].iloc[i], train_mask)
except:
pass
train_mask = np.zeros((512, 512)).astype('uint8')
train_mask = train_mask * 255
cv2.imwrite('D:\\00Com_TianChi\\dataset\\train\\build_label\\' + train_rle['name'].iloc[i], train_mask)
其中將矩陣轉為numpy格式并存盤成圖片的轉換函式為astype(),
使用方法為 train_mask = train_mask.astype(np.uint8)
在訓練集中有很多例外資料,對于例外資料,我們使用try-except語法來進行處理,
try:正常情況
except:資料例外情況
2.2 資料擴增
資料擴增是一種有效的正則化方法,可以防止模型過擬合,在深度學習模型的訓練程序中應用廣泛,資料擴增的目的是增加資料集中樣本的資料量,同時也可以有效增加樣本的語意空間,
在語意分割領域,我們通常將訓練集的影像與標簽進行同步的影像變換,這樣可以對模型進行有效的訓練,
本案例利用albumentations庫進行資料擴增,albumentations是基于OpenCV的快速訓練資料增強庫,擁有非常簡單且強大的可以用于多種任務(分割、檢測)的介面,易于定制且添加其他框架非常方便,
# ---------------資料擴增部分---------------
aug_data = 'D:\\00Com_TianChi\\dataset\\train_aug\\'
image_build_aug = "build_image_aug"
label_build_aug = "build_label_aug"
# 擴增img和擴增label的路徑
image_build_aug_path = os.path.join(aug_data, image_build_aug)
label_build_aug_path = os.path.join(aug_data, label_build_aug)
# 原始影像的名稱 build_dataset.image_list[0] build_dataset.label_list[0]
# 路徑測驗
# print(os.path.join(root_dir, image_build, build_dataset.image_list[0]))
# print( os.path.join(image_build_aug_path, 'scale' + build_dataset.image_list[0]))
for i in range(0, 5):
print(i)
# 將 原始影像和原始標簽路徑 放入函式 得到路徑
img_path = os.path.join(root_dir, image_build, build_dataset.image_list[i])
label_path = os.path.join(root_dir, label_build, build_dataset.label_list[i])
# 根據路徑加載圖片 轉為np類
trans_img = np.asarray(Image.open(img_path))
trans_label = np.asarray(Image.open(label_path))
# 水平翻轉操作
augments = aug.HorizontalFlip(p=1)(image=trans_img, mask=trans_label)
img_aug_hor, mask_aug_hor = augments['image'], augments['mask']
# 隨即裁剪操作
augments = aug.RandomCrop(p=1, height=256, width=256)(image=trans_img, mask=trans_label)
img_aug_ran, mask_aug_ran = augments['image'], augments['mask']
# 旋轉操作
augments = aug.ShiftScaleRotate(p=1)(image=trans_img, mask=trans_label)
img_aug_rot, mask_aug_rot = augments['image'], augments['mask']
# 復合操作
trfm = aug.Compose([
aug.Resize(256, 256),
aug.HorizontalFlip(p=0.5),
aug.VerticalFlip(p=0.5),
aug.RandomRotate90(),
])
augments = trfm(image=trans_img, mask=trans_label)
img_aug_mix, mask_aug_mix = augments['image'], augments['mask']
# 保存路徑 變換后的檔案名
# 水平翻轉
save_hor_path_img = os.path.join(image_build_aug_path, 'hor' + build_dataset.image_list[i])
save_hor_path_label = os.path.join(label_build_aug_path, 'hor' + build_dataset.label_list[i])
cv2.imwrite(save_hor_path_img, img_aug_hor)
cv2.imwrite(save_hor_path_label, mask_aug_hor)
# 隨即裁剪
save_ran_path_img = os.path.join(image_build_aug_path, 'ran' + build_dataset.image_list[i])
save_ran_path_label = os.path.join(label_build_aug_path, 'ran' + build_dataset.label_list[i])
cv2.imwrite(save_ran_path_img, img_aug_ran)
cv2.imwrite(save_ran_path_label, mask_aug_ran)
# 旋轉操作
save_rot_path_img = os.path.join(image_build_aug_path, 'rot' + build_dataset.image_list[i])
save_rot_path_label = os.path.join(label_build_aug_path, 'rot' + build_dataset.label_list[i])
cv2.imwrite(save_rot_path_img, img_aug_rot)
cv2.imwrite(save_rot_path_label, mask_aug_rot)
# 復合操作
save_mix_path_img = os.path.join(image_build_aug_path, 'rot' + build_dataset.image_list[i])
save_mix_path_label = os.path.join(label_build_aug_path, 'rot' + build_dataset.label_list[i])
cv2.imwrite(save_mix_path_img, img_aug_mix)
cv2.imwrite(save_mix_path_label, mask_aug_mix)2.3 例外資料的處理
在rle轉mask編碼的處理中,我們將例外rle資料轉換成全黑圖片處理,可是在后面的訓練中發現,損失函式的振蕩較大,于是考慮將例外資料全部剔除,再次訓練函式觀察損失函式的變化,(待更)
3 自定義資料庫類
在資料預處理后,我們進行資料庫類的定義,在每次進行模型訓練前,我們要將訓練集的資料輸入給一個類中,這樣能夠使我們清晰地有條理地利用好我們的訓練集資料,本案例的資料庫類定義如下,
class MyData(Dataset):
def __init__(self, root_dir, image_dir, label_dir, transform):
self.root_dir = root_dir
self.image_dir = image_dir
self.label_dir = label_dir
self.label_path = os.path.join(self.root_dir, self.label_dir)
self.image_path = os.path.join(self.root_dir, self.image_dir)
self.image_list = os.listdir(self.image_path)
self.label_list = os.listdir(self.label_path)
self.transform = transform
# 因為label 和 Image檔案名相同,進行一樣的排序,可以保證取出的資料和label是一一對應的
self.image_list.sort()
self.label_list.sort()
def __getitem__(self, idx):
img_name = self.image_list[idx]
label_name = self.label_list[idx]
img_item_path = os.path.join(self.root_dir, self.image_dir, img_name)
label_item_path = os.path.join(self.root_dir, self.label_dir, label_name)
img = Image.open(img_item_path)
label = Image.open(label_item_path)
# label = self.label_dir
trans_tensor = transforms.ToTensor()
img = trans_tensor(img) # 將圖片變為tensor格式
label = trans_tensor(label)
return img, label
# with open(label_item_path, 'r') as f:
# label = f.readline()
#
# # img = np.array(img)
# img = self.transform(img)
# sample = {'img': img, 'label': label}
# return sample
def __len__(self):
assert len(self.image_list) == len(self.label_list)
return len(self.image_list)函式有四個輸入變數:
- root_dir:為資料集根目錄
- train_dir:為訓練集目錄
- text_dir:為測驗集目錄
- transform:為對資料集做的transform
我們利用os對路徑進行整合,這一部分有很多實用的資料轉換代碼,在這里小結一下,
存圖片
cv2.imwrite('D:\\00Com_TianChi\\dataset\\train\\build_label\\' + train_rle['name'].iloc[i], train_mask)加載一張圖片:
# 加載后圖片格式為PIL.JpegImagePlugin.JpegImageFile
img = Image.open(img_item_path)將PIL.JpegImagePlugin.JpegImageFile型別轉為陣列
# 轉換后變數的資料型別為np型
img = np.asarray(img)將陣列轉為torch.Tensor類:
img = torch.tensor(img)注意transforms.ToTensor和torch.Tensor的區別:
- transforms.ToTensor:可以將np或PIL型別的圖片轉為tensor型,但是轉換的同時也會將其歸一化,因為transform封裝的函式中將tensor型變數中的每個量設定的范圍為[0,1],
- torch.Tensor:這個函式和transforms.ToTensor的功能類似,但是沒有將張量歸一化,
下面對資料庫類實體化,
# 定義訓練集
transform = transforms.Compose([transforms.Resize((512, 512)), transforms.ToTensor()])
root_dir = "D:/00Com_TianChi/dataset/train/"
image_build = "build_image"
label_build = "build_label"
build_dataset = MyData(root_dir, image_build, label_build, transform=transform)
# 定義測驗集
test_dir = "D:/00Com_TianChi/dataset/test/"
image_build_test = "img"
label_build_test = "label"
test_dataset = MyData(test_dir, image_build_test, label_build_test, transform=transform)在對資料庫類進行實體化后,我們定義模型的data_loader,批處理量定位8,
train_dataloader = DataLoader(build_dataset, batch_size=8, shuffle=True, num_workers=4)4 模型訓練
待更
5 語意分割的準確率評價方法
在語言分割的評價方法中,我們主要利用混淆矩陣對模型準確率進行評價,在前幾期的博客中已經對混淆矩陣進行了介紹,我們再次來回顧一下混淆矩陣的概念,并嘗試從語意分割領域對混淆軍陣進行新的理解,
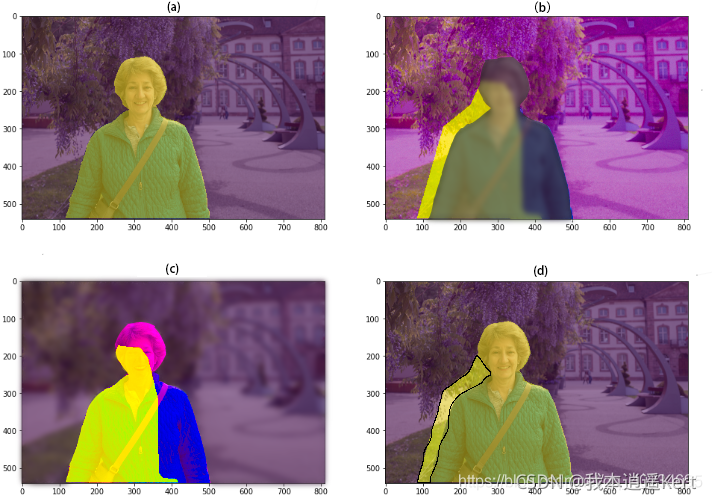
我們已經了解到,經模型輸出后影像能夠根據預測的結果分為不同的mask,每一類mask就是模型輸出的某一個類別,或者也可以成為某一個通道,當我們對背景感興趣時,圖(b)中真實值=1的情況則為全部的背景,即圖中清晰部分;模型輸出中預測值=1的部分為正確的預測,即圖中紫色部分;模型輸出中預測值=0的部分為錯誤的預測,即黃色的部分,
當我們對人物感興趣時也是同理,圖(c)中真實值=1時,則為我們感興趣的部分,即人物;當預測值=1時,則為預測正確的部分,這張圖恰巧精確度很高,圖中黃紫藍組成的顏色則為預測值=1時的情況,
那么問題來了——當真實值=0時,該是哪個區域呢?當我們對于人物感興趣時,真實值=1為人物,那么真實值=0時則為人物以外的區域,則為背景區域,圖(d)中當真實值=0,預測值=1時,則為黑色線條圈出來的部分,通俗的講可以理解為:本該預測成背景,可是預測錯了,
3.1 像素準確率(PA)
- 預測類別正確的像素數占總像素數的比例
- PA = (TP + TN) / (TP + TN + FP + FN)
3.2 類別像素準確率(CPA)
在類別 i 的預測值中,真實屬于 i 類的像素準確率,換言之:模型對類別 i 的預測值有很多,其中有對有錯,預測對的值占預測總值的比例,
P1 = TP / (TP + FP)
3.3 類別平均像素準確率(MPA)
分別計算每個類被正確分類像素數的比例,即:CPA,然后累加求平均
- 每個類別像素準確率為:Pi(計算:對角線值 / 對應列的像素總數)
- MPA = sum(Pi) / 類別數
3.4 交并比(IoU)
- 模型對某一類別預測結果和真實值的交集與并集的比值
- 混淆矩陣計算:
- IoU = TP / (TP + FP + FN)
3.5 平均交并比(MIoU)
模型對每一類交并比,求和再平均的結果,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/335320.html
標籤:其他
上一篇:大佬今天教你用python制作五款簡單又好玩的小游戲
下一篇:基于蟻群演算法影像邊緣檢測的認識