前言
目標檢測任務的目標是識別影像中物體的類別并且定位物體所在位置用矩形框框出,目標檢測領域的深度學習方法的發展主要分為兩大類:兩階段(Two-stage)目標檢測演算法和單階段(One-stage)目標檢測演算法,
1)兩步模型:分成兩個步驟,第一,提取候選區域提取程序,即先在輸入影像上篩選出一些可能存在物體的候選區域,然后針對每個候選區域提取特征,判斷其是否存在物體,經典演算法模型有R-CNN、SPPNet、Fast R-CNN、Faster R-CNN、R-FCN、Mask R-CNN等,
缺點: 耗時耗力,而且沒有考慮到影像的全域資訊,比如人坐在車上,這種關系很難被捕捉到,
2)單步模型: end-to-end,直接將影像輸入到網路,輸出得到物體的類別和位置資訊,將分類問題轉換成回歸問題,影像先被裁剪到同一尺寸,并以網格(grid cell)劃分成N*N,模型僅需輸入影像,輸出就能得到位置和分類結果,經典演算法模型有MultiBox、OverFeat、YOLO、SSD等,
總結:單步模型大大提高了計算效率,兩步模型在檢測精度上有優勢,
一、YOLOv1介紹
論文鏈接: http://arxiv.org/abs/1506.02640
2016年CVPR,由華盛頓大學Joseph Red提出,與原來RCNN等兩步模型(先提取候選框,再用分類器篩選)不同,yolov1將目標檢測當作回歸問題,預測一系列數值,預測的數值包括影像的位置資訊和類別資訊,
YOLO優點:由于輸入是一整張圖片,所以對圖片的全域資訊捕獲能力強,背景錯誤(把背景錯認為物體)比較少,隱式的學習影像中物體之間的關系,遷移能力泛化能力強,速度快,可以實時處理視頻流,
缺點:與滑窗的方法相比,檢測小物體的能力弱,
二、YOLOv1框架
24層卷積層提取影像特征, 2層全連接層,最后輸出7×7×30的tensor,

實作方法:
1、將輸入image分成S×S(論文里是7×7)個grid cell,如果某個object的中心落在grid cell中,則由這個grid cell產生的bounding box預測該object,(注意:每個grid cell只能預測一類物體,所以7×7最對預測49類物體,)
2、每個grid cell產生預測的B個(論文中是2個)bounding box,每個bounding box除了要預測四個位置坐標(x,y,w,h),還需要預測一個置信度(confidence),confidence計算公式如下圖,Pr(object) 非0即1,表示box 包含物體的概率,IOU(truth上,pred下)表示人工標框和預測框的交并比,兩者相乘為confidence,這個confidence代表了所預測的box中含有object的置信度和這個box預測的有多準,
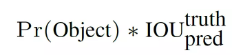
3、測驗階段:
Pr(classi|Object)表示BBox負責預測物體的條件下是某一類別的概率,由條件概率公式得到如下等式,最后等式右邊為每一類得分(包分類和位置資訊):
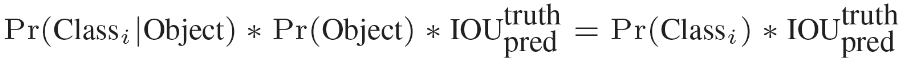
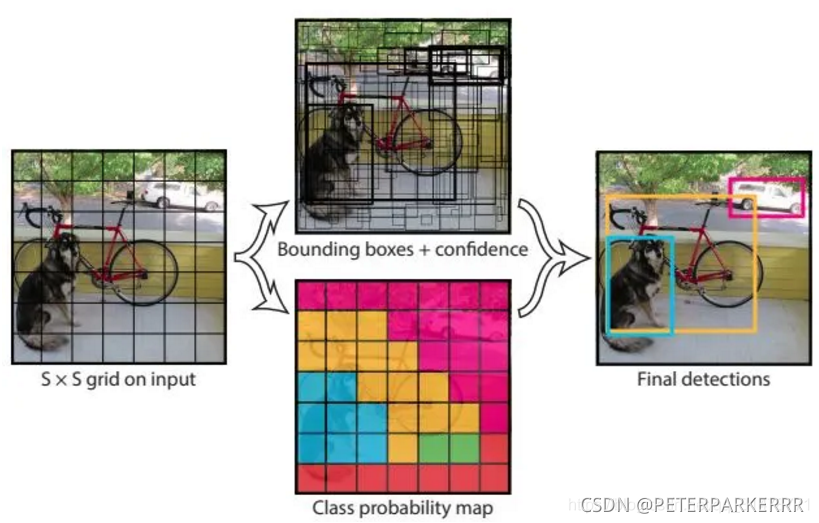
4、圖中框的粗細代表置信度,每個grid cell生成兩個BBox,由與實際GT的IOU最大的BBox去擬合,另一個被舍棄(依據NMS方法舍棄),模型輸出的tensor尺寸為7×7×30,7×7表示49個grid cell,30包括(x,y,w,h,confidence)×2,以及20個類別,
4、訓練階段:

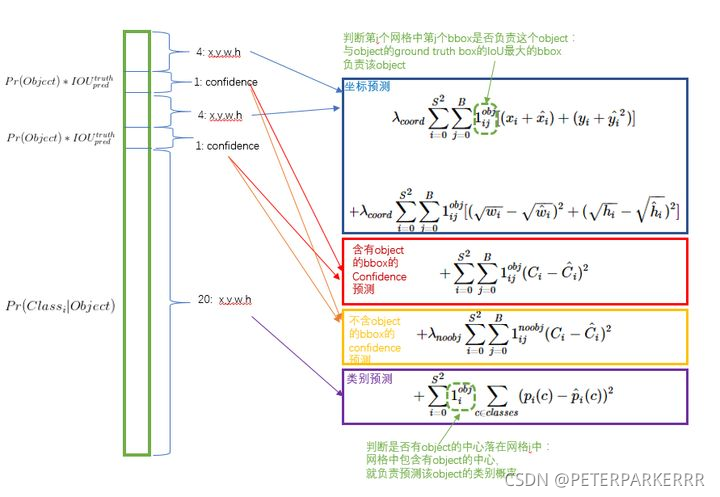
圖片轉自https://blog.csdn.net/c20081052/article/details/80236015?ops_request_misc=&request_id=&biz_id=102&utm_term=yolov1&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-0-80236015.first_rank_v2_pc_rank_v29&spm=1018.2226.3001.4187
總共分為三種BBox:1)負責檢測物體的,且與GT的IOU最大的,2)負責檢測物體,但IOU小的,3)不負責檢測物體的,
損失函式共分為五部分:1)負責檢測物體的BBox中心點定位誤差,2)負責檢測物體的寬高定位誤差,取根號使對小框更敏感,3)負責檢測物體的置信度誤差,4)不負責檢測物體的置信度誤差,5)類別預測誤差,
三、總結
1)YOLOv1提取全域資訊,隱式編碼尺寸、關系、形狀、位置,
2)單階段模型,速度快,可以實時檢測,
3)小目標檢測效果差,密集物體檢測效果差(因為只有兩個框),但把背景誤認為物體的概率低,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/335339.html
標籤:其他