對于信號的采樣可以參考我之前的文章:數字信號處理 2.1 — 采樣
對于信號的量化可以參考:數字信號處理 2.4 — ADC 中的有限字長效應
在本篇文章中繪圖使用到了 matplotlib 庫,需要了解學習可以參考我之前寫的用來總結這個繪圖庫的文章:Python 繪圖庫 Matplotlib
目錄
1. 影像量化與采樣處理
(1)基本概念
(2)量化操作
(2)采樣操作
2. 影像金字塔
(1)基本概念
(2)操作實作
高斯金子塔下采樣
拉普拉斯金子塔恢復原影像
3. 區域馬賽克處理
(1)實作原理
(2)實戰操作
結束語
1. 影像量化與采樣處理
經典開頭讀取影像資訊:
"""
Author:XiaoMa
date:2021/10/22
"""
#呼叫所需的包
import matplotlib.pyplot as plt
import cv2
import numpy as np
#讀取原始影像的資訊
img0 = cv2.imread('E:\From Zhihu\For the desk\ZHM.jpeg') #讀取影像
img1 = cv2.resize(img0, fx = 0.5, fy = 0.5, dsize = None) #調整影像大小
img2 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY) #將影像轉化為灰度影像
height = img1.shape[0] #shape[0] 影像第一維度,高度
width = img1.shape[1] #shape[1] 影像第二維度,寬度
print(img1.shape)
print(width, height)
cv2.namedWindow("W0")
cv2.imshow("W0", img1)
cv2.waitKey(delay = 0)
(1)基本概念
此處參考:知乎文章
把一幅影像表示為二元函式形式:f(x, y),那么該函式在不同的坐標點有不同的幅度值,而這些幅度值是連續的,無法使用計算機進行處理,所以我們需要對幅度值進行離散化(數字化),這個程序即為影像量化處理,一般常見的量化方式是將影像用黑白兩種顏色表示,稱為二值影像
在之前的文章中提到一幅影像可以表示為在 x 軸和 y 軸上連續的信號,但計算機無法處理連續信號,所以我們需要將影像在這兩個維度進行離散化處理,該程序就稱為影像的采樣處理,即對影像的坐標軸進行數字化
(2)量化操作
具體代碼如下,都已經添加了注釋,理解起來應該沒問題,如果有我注釋的不清楚的地方可以在評論區提出來,我們一起探討學習:
"""
Author:XiaoMa
date:2021/10/22
"""
#呼叫所需的包
import matplotlib.pyplot as plt
import cv2
import numpy as np
#讀取原始影像的資訊
img0 = cv2.imread('E:\From Zhihu\For the desk\ZHM.jpeg') #讀取影像
img1 = cv2.resize(img0, fx = 0.5, fy = 0.5, dsize = None) #調整影像大小
img2 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY) #將影像轉化為灰度影像
height = img1.shape[0] #shape[0] 影像第一維度,高度
width = img1.shape[1] #shape[1] 影像第二維度,寬度
print(img1.shape)
print(width, height)
cv2.namedWindow("W0")
cv2.imshow("W0", img2)
cv2.waitKey(delay = 0)
#創建和原始影像同等大小的矩陣
img3 = np.zeros((width, height, 3), np.uint(8))
img4 = np.zeros((width, height, 3), np.uint(8))
img5 = np.zeros((width, height, 3), np.uint(8))
img6 = np.zeros((width, height, 3), np.uint(8))
img7 = np.zeros((width, height, 3), np.uint(8))
#對原始影像矩陣的值進行操作
img3 = np.uint8(img2/4) * 4
img4 = np.uint8(img2/16) * 16
img5 = np.uint8(img2/32) * 32
img6 = np.uint8(img2/64) * 64
img7 = np.uint8(img2 >= 128) * 128
plt.rcParams['font.family'] = 'SimHei' #將全域中文字體改為黑體
plt.rcParams['axes.unicode_minus'] = False #正常表示負號
#顯示得到的影像
title = ['原始影像', '量化為64份', '量化為16份', '量化為8份', '量化為4份', '量化為2份'] #子圖示題
img = [img2, img3, img4, img5, img6, img7]
for i in range(6):
plt.subplot(2, 3, i + 1) #python 串列從0開始計數,所以此處 i+1
plt.imshow(img[i], 'gray')
plt.title(title[i])
plt.xticks([]),plt.yticks([])
plt.savefig('E:\From Zhihu\For the desk\ZHM1.jpeg')
plt.show()
然后得到的量化后的影像如下:

(2)采樣操作
具體代碼如下:
"""
Author:XiaoMa
date:2021/10/22
"""
#呼叫所需的包
import matplotlib.pyplot as plt
import cv2
import numpy as np
#讀取原始影像的資訊
img0 = cv2.imread('E:\From Zhihu\For the desk\ZHM.jpeg') #讀取影像
img1 = cv2.resize(img0, fx = 0.5, fy = 0.5, dsize = None) #調整影像大小
img2 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY) #將影像轉化為灰度影像
height = img1.shape[0] #shape[0] 影像第一維度,高度
width = img1.shape[1] #shape[1] 影像第二維度,寬度
print(img1.shape)
print(width, height)
cv2.namedWindow("W0")
cv2.imshow("W0", img1)
cv2.waitKey(delay = 0)
plt.rcParams['font.family'] = 'SimHei' #將全域中文字體改為黑體
img8 = img2[0:-1:2, 0:-1:2]
#img8_1 = cv2.resize(img8, dsize = None, fx = 2, fy = 2) #這個注釋先不管,后面解釋
img9 = img2[0:-1:4, 0:-1:4]
#img9_1 = cv2.resize(img9, dsize = None, fx = 4, fy = 4)
img10 = img2[0:-1:8, 0:-1:8]
#img10_1 = cv2.resize(img10, dsize = None, fx = 8, fy = 8)
img11 = img2[0:-1:16, 0:-1:16]
#img11_1 = cv2.resize(img11, dsize = None, fx = 16, fy = 16)
titles = ['原始影像', '256*256', '128*128', '64*64', '32*32', '16*16']
image = [img1, img2, img8, img9, img10, img11] #此處一定要注意不加引號,別問我為什么知道,心累
for j in range(6):
plt.subplot(2, 3, j + 1)
if j == 0:
plt.imshow(image[j])
else:
plt.imshow(image[j], 'gray')
plt.title(titles[j])
plt.xticks([]), plt.yticks([])
plt.savefig('E:\From Zhihu\For the desk\ZHM2.jpeg')
plt.show()

得到的影像如上,但是第一幅圖是不是很怪?其實原因在前面講過的:
OpenCV 對于影像的處理方式是 BGR 的,而對于 matplotlib 來說是 RGB 的,所以要將通道順序進行修改:
只要加上這一句代碼就可以了,添加的位置是在組成串列之前就行
img_rgb = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)

關于前面的代碼中的注釋部分:影像經過采樣之后尺寸大小發生變化,對其尺寸進行調整使其能夠正常顯示(當然這只會在單獨顯示影像時用到)
如:未改變尺寸前的 16*16 影像如下(在原圖左上角)

經過改變后的影像如下:

2. 影像金字塔
(1)基本概念
概念這方面參考的文章:OpenCV(23)---影像金字塔
影像金字塔是由一副影像的多個不同解析度的子圖所構成的影像集合,該組影像是由單個影像通過不斷地降低采樣所產生的,最小的影像可能僅僅只有一個像素點,如下圖所示,解析度從低到高,逐漸降低的影像集合,(該段全部摘自上面的文章)
下面說說我的理解:在影像的采樣的介紹中我們得到了五張經過采樣后的影像,而它們的解析度都是不同的, 因為在采樣的程序中總會失去一些資訊,影像中失去的是像素點(這方面不理解可以參考文章頭粘貼的關于采樣的文章),然后將不同解析度的影像按照上圖中的金子塔從大到小排列上去,就是影像金子塔了
就拿上圖舉例,所謂的影像金子塔就是將第二幅圖放在 Level0 層,將第三幅放在 Level1 層,以此類推,得到最終的影像
(2)操作實作
高斯金子塔下采樣
#呼叫所需的包
import matplotlib.pyplot as plt
import cv2
#讀取原始影像的資訊
img0 = cv2.imread('E:\From Zhihu\For the desk\ZHM.jpeg') #讀取影像
img1 = cv2.resize(img0, fx = 0.5, fy = 0.5, dsize = None) #調整影像大小
img2 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY) #將影像轉化為灰度影像
img12 = cv2.pyrDown(img2) #高斯濾波下采樣得到高斯金字塔
cv2.namedWindow("W1")
cv2.imshow("W1", img12)
cv2.waitKey(delay = 0)

將其與原影像對比: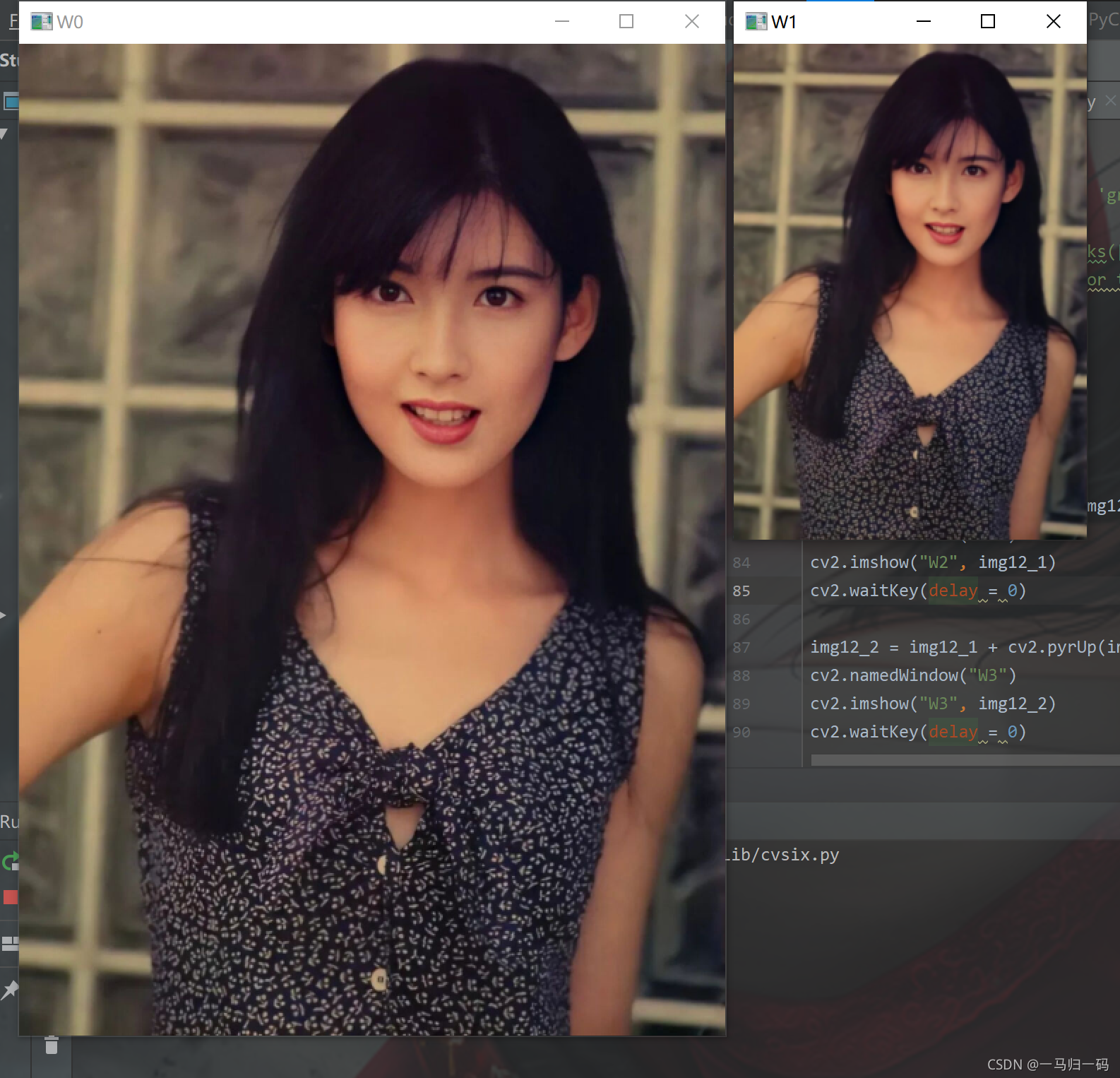
可以看出,經過降采樣得到的影像與原影像對比最主觀的變化是尺寸大小的變化,當然尺寸大小也可以通過引數進行設定,其實就是對采樣率的設定了
拉普拉斯金子塔恢復原影像
通過高斯金子塔下采樣得到的影像沒辦法通過高斯上采樣恢復出來,因為按照采樣的意義來說已經丟失了那部分的像素點,沒辦法憑空出現,但丟失的那些資訊,剛好就構成了拉普拉斯金字塔,將高斯金字塔加進去就能復原出原影像了
#呼叫所需的包
import matplotlib.pyplot as plt
import cv2
#讀取原始影像的資訊
img0 = cv2.imread('E:\From Zhihu\For the desk\ZHM.jpeg') #讀取影像
img1 = cv2.resize(img0, fx = 0.5, fy = 0.5, dsize = None) #調整影像大小
img2 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY) #將影像轉化為灰度影像
img12 = cv2.pyrDown(img2) #高斯濾波下采樣得到高斯金字塔
cv2.namedWindow("W1")
cv2.imshow("W1", img12)
cv2.waitKey(delay = 0)
img12_1 = img1 - cv2.pyrUp(img12) #得到拉普拉斯金字塔
cv2.namedWindow("W2")
cv2.imshow("W2", img12_1)
cv2.waitKey(delay = 0)
img12_2 = img12_1 + cv2.pyrUp(img12) #恢復原影像
cv2.namedWindow("W3")
cv2.imshow("W3", img12_2)
cv2.waitKey(delay = 0)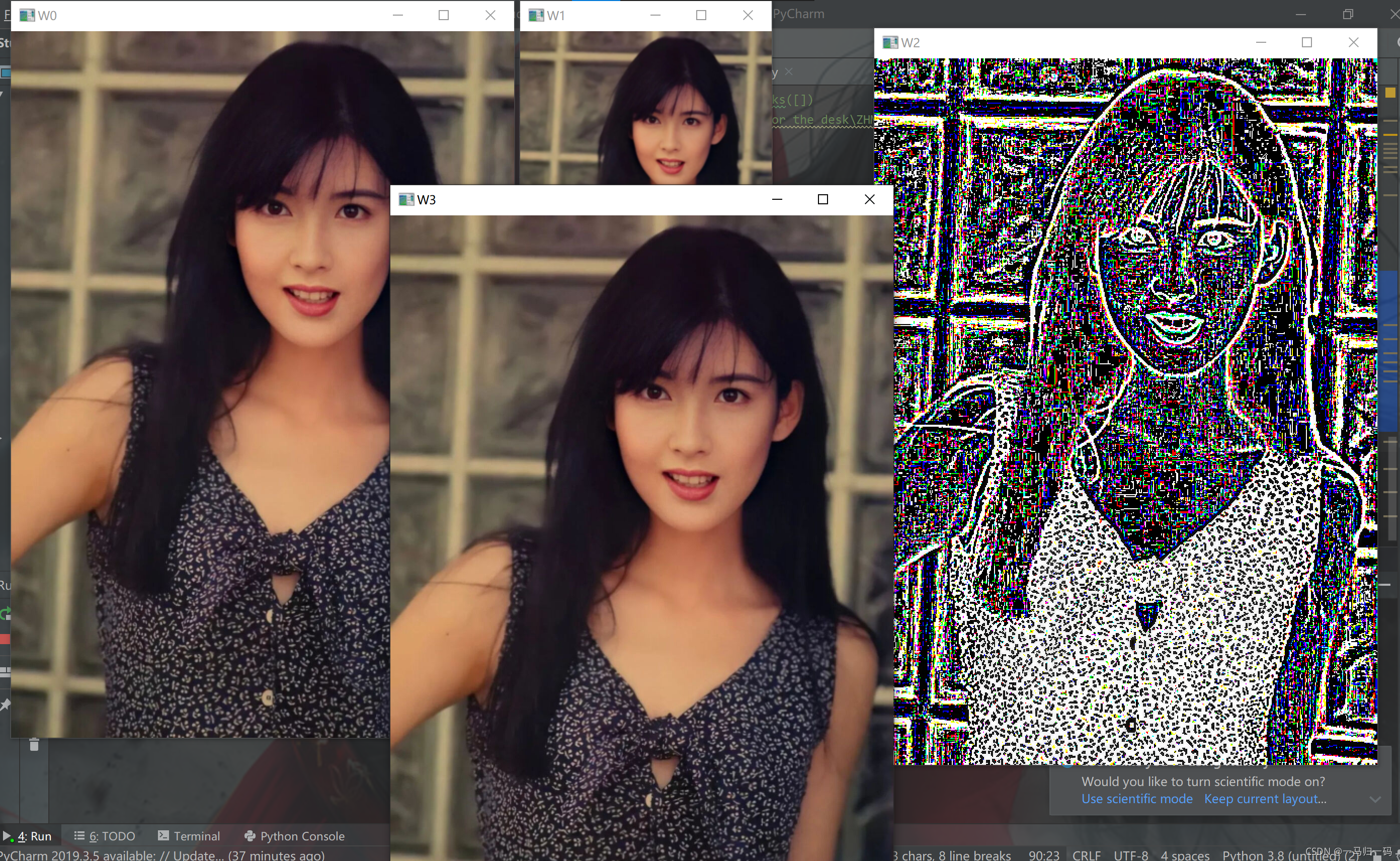
W0 中的是原圖,W1 是經過下采樣得到的高斯金字塔,W2 是拉普拉斯金字塔,W3 是恢復出來的原影像
3. 區域馬賽克處理
該段參考文章:圖片處理之馬賽克
(1)實作原理
a:確定需要生成馬賽克的目標區域
b:將目標區域分為許多同等大小的,為了打碼效果盡可能的好,劃分的數目一般不能過多或過少
c:在劃分的區域中隨機選擇一個像素點,用這個像素點代替所有該區域中的像素點
(2)實戰操作
import cv2
#讀取原始影像的資訊
img0 = cv2.imread('E:\From Zhihu\For the desk\ZHM.jpeg') #讀取影像
img1 = cv2.resize(img0, fx = 0.5, fy = 0.5, dsize = None) #調整影像大小
img2 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY) #將影像轉化為灰度影像
height = img1.shape[0] #shape[0] 影像第一維度,高度
width = img1.shape[1] #shape[1] 影像第二維度,寬度
print(img1.shape)
print(width, height)
cv2.namedWindow("W0")
cv2.imshow("W0", img1)
cv2.waitKey(delay = 0)
for i in range(200, 400, 10): #生產馬賽克的目標區域(對影像高度)
for j in range(200, 400, 10): #生成馬賽克的目標區域(對影像寬度)
for m in range(0, 10): #區域大小為 10 * 10
for n in range(0, 10):
img1[i+m, j+n] = img1[i, j] #用該區域的第一個像素點替換掉其他的像素點
cv2.namedWindow("W4")
cv2.imshow("W4", img1)
cv2.waitKey(delay = 0)得到影像如下:

結束語
本篇文章主要總結了影像的采樣以及量化的原理以及操作,在此基礎上添加了影像的馬賽克處理以及影像金子塔,其中參考的一些文章的鏈接也添加了進去,如果需要更深入的了解和學習可以點進去學習
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/335340.html
標籤:其他
上一篇:目標檢測----YOLOV1
下一篇:jenkins部署專案