機器學習基礎知識點
文章目錄
- 機器學習基礎知識點
- 監督學習
- 回歸
- 線性回歸
- 嶺回歸
- lasso回歸
- 分類
- k最近鄰分類
- 樸素貝葉斯分類
- logistic回歸
- 支持向量機
- 其他
- 隨機梯度下降
- 線性判別分析
- 決策樹
- 無監督學習
- 聚類
- k均值
- 分層次聚類
- 譜聚類
- 高斯混合模型
- 降維
- PCA降維
- LLE降維
- MDS和t-SNE
- 獨立成分分析
- 等距特征映射
- 譜嵌入
- 深度學習(一些基本概念)
- 一維卷積(離散)
- 二維卷積(離散)
- padding
- 反卷積(轉置卷積)
- 學習率
- 反向傳播
- 正則化
- softmax
- dropout
- 歷史
- 隨機梯度下降(mini-batch)
- 萬有逼近定理
- 幾種激活函式
- 白化
- 動量方法
- 交叉熵和KL散度
- batch normalization
- maxout
- 上采樣和下采樣
- 池化
- 預訓練
- 自編碼機
- 梯度消失(爆炸)和區域極值
- Flatten
- 特征圖
- 強化學習
- 核心內容
- 元素簡介
- 優化目標:狀態值函式
- 狀態-動作值函式
- 策略迭代和值迭代
- 策略迭代
- 值迭代
- Q學習、SARSA、時序差分學習
- Q學習
- SARSA和時序差分學習
- 深度強化學習
- 一些學習資料
- 集成學習
- bagging
- 隨機森林
- boosting
- 其他方面
- 概率圖模型
- 貝葉斯網
- 馬爾科夫隨機場
- 推廣搜相關
- 概念解釋
- 準確率、精確率、召回率、F1值、ROC、AUC
- 詞袋模型
- TF-IDF
- 泛化
- 過擬合
- 生成模型和判別模型
- 線性分類器和非線性分類器
- L1 和 L2 正則化
- 歸一化方法
- 交叉驗證
- Bias(偏差)、Error(誤差)、Variance(方差)
機器學習主要分為監督學習和無監督學習,
- 有監督學習:對具有標記的訓練樣本進行學習,以盡可能對訓練樣本集外的資料進行分類預測,(LR、SVM、BP、RF、GBRT)
- 無監督學習:對未標記的樣本進行訓練學習,比發現這些樣本中的結構知識,(KMeans、DL)
監督學習
回歸
線性回歸
所謂的線性回歸,就是要找一個線性的超平面,去盡可能地擬合各個樣本點,在一維的情況下,如圖所示:

我們要尋找一條直線,讓它盡可能地穿過這些點,“盡可能”可能有一些度量,比如說讓誤差平方和最小,
求解這條直線的方法有最小二乘方法等,
線性回歸是一種簡單但卻使用的回歸技術,
多重共線性(Multicollinearity)是指線性回歸模型中的自變數之間由于存在高度相關關系而使模型的權重引數估計失真或難以估計準確的一種特性,多重是指一個自變數可能與多個其他自變數之間存在相關關系,共線性不影響模型的預測而是影響對模型的解釋,神經網格本來可解釋性就差,就不存在這種共線性的問題,
嶺回歸
lasso回歸
分類
k最近鄰分類
所謂物以類聚,人以群分,你的圈子基本決定了你的狀態,我們可以用周圍的鄰居來判斷自己的情況,基于這個思想,就有了k-NN演算法,k近鄰演算法不僅可以用于分類,也可以用于回歸,我這里將它放在了分類的條目下,
分類問題中,一個物件的分類是由其鄰居的“多數表決”確定的,k個最近鄰居(k為正整數,通常較小)中最常見的分類決定了賦予該物件的類別,若k=1,則該物件的類別直接由最近的一個節點賦予,無論是分類還是回歸,衡量鄰居的權重都非常有用,使較近鄰居的權重比較遠鄰居的權重大,例如,一種常見的加權方案是給每個鄰居權重賦值為1/d,其中d是到鄰居的距離,這樣會避免一些單純計數帶來的問題,
k 引數的選擇可以使用交叉驗證和自助法等等,
k-近鄰演算法的缺點是對資料的區域結構非常敏感,
三要素:
- k 值的選擇
- 距離的度量(常見的距離度量有歐式距離,馬氏距離等)
- 分類決策規則 (多數表決規則)
k 值的選擇
k 值越小表明模型越復雜,更加容易過擬合,k 值越大,模型越簡單,極端情況如果 k=N 的時候就表明無論什么點都是訓練集中類別最多的那個類,所以一般 k 會取一個較小的值,然后用過交叉驗證來確定,這里所謂的交叉驗證就是將樣本劃分一部分出來為預測樣本,比如 95% 訓練,5% 預測,然后 k 分別取1,2,3,4,5之類的,進行預測,計算最后的分類誤差,選擇誤差最小的 k,簡單地來說,就是試一試,
KNN 的回歸
在找到最近的 k 個實體之后,可以計算這 k 個實體的平均值作為預測值,或者還可以給這 k 個實體添加一個權重再求平均值,這個權重與度量距離成反比(距離越大,權重越低),
優缺點:
KNN演算法的優點:思想簡單,理論成熟,既可以用來做分類也可以用來做回歸;可用于非線性分類;訓練時間復雜度為O(n);準確度高,對資料沒有假設,對 outlier 不敏感,
KNN演算法的缺點:計算量大;樣本不平衡問題(即有些類別的樣本數量很多,而其它樣本的數量很少);需要大量的記憶體,
KNN 演算法中 KD 樹的應用
我們知道在上述 KNN 的計算中,我們要找一個點的 k 近鄰,必須要計算這個點到所有點的距離,再取小的一部分,這個計算量超大,KD tree 就是為了解決這個問題的,順著 KD tree 去搜索,我們可以很快地找到一個點的最近鄰,而不需要計算這個點到所有點的距離,
當點隨機分布的時候,搜索的復雜度為
log
?
(
N
)
\log(N)
log(N),N 為實體的個數,KD 樹更加適用于點的
數量遠大于空間維度的 KNN 搜索,如果空間維度與點個數差不多時,它的效率基于等于線性掃描,
關于 KD 數的構建,搜索和 KNN 查找,網上有很多資料,這里就不介紹了,
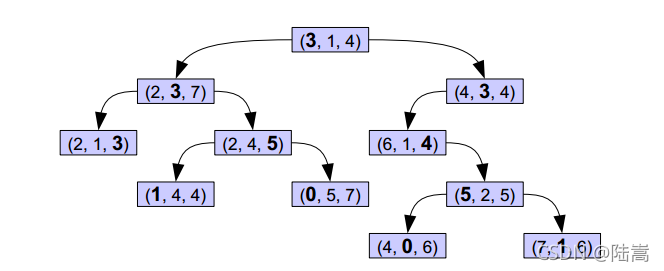
可以觀察到 KD-tree 是這樣一種 tree,它的第一層的第一個元素大于左子樹的第一個元素,小于右子樹的第一個元素,第二層的第二個元素大于左子樹的第二個元素,小于右子樹的第二個元素,第 i 層的第 i%k 個元素大于左子樹的第 i%k 個元素,小于右子樹的,依次類推,
樸素貝葉斯分類
樸素貝葉斯真的很樸素,用到的僅僅只是貝葉斯公式,以二分類為例,它給定若干組的帶標簽的資料,當新給一組特征時,我們需要判斷它屬于哪一類,
我們通過比較這組特征下的條件概率
P
(
標簽1
∣
{
特征1,特征2,特征3
}
)
P(\text{標簽1}|\{\text{特征1,特征2,特征3}\})
P(標簽1∣{特征1,特征2,特征3})和
P
(
標簽2
∣
{
特征1,特征2,特征3
}
)
P(\text{標簽2}|\{\text{特征1,特征2,特征3}\})
P(標簽2∣{特征1,特征2,特征3})大小來對其分類,條件概率的計算可通過貝葉斯公式來計算,即
P
(
標簽i
∣
{
特征1,特征2,特征3
}
)
=
P
(
{
特征1,特征2,特征3
}
∣
標簽i
)
?
P
(
標簽i
)
P
(
{
特征1,特征2,特征3
}
)
P(\text{標簽i}|\{\text{特征1,特征2,特征3}\}) = \frac{P(\{\text{特征1,特征2,特征3}\}|\text{標簽i} )* P(\text{標簽i})}{P(\{\text{特征1,特征2,特征3}\})}
P(標簽i∣{特征1,特征2,特征3})=P({特征1,特征2,特征3})P({特征1,特征2,特征3}∣標簽i)?P(標簽i)?
我們假設特征之間是獨立的,那么就有
P
(
{
特征1,特征2,特征3
}
∣
標簽i
)
=
P
(
特征1
∣
標簽i
)
?
P
(
特征2
∣
標簽i
)
?
P
(
特征3
∣
標簽i
)
P
(
{
特征1,特征2,特征3
}
)
=
P
(
特征1
)
?
P
(
特征2
∣
標簽i
)
?
P
(
特征3
)
\begin{aligned} P(\{\text{特征1,特征2,特征3}\}|\text{標簽i} ) &=& P(\text{特征1}|\text{標簽i} )*P(\text{特征2}|\text{標簽i} )*P(\text{特征3}|\text{標簽i} ) \\ P(\{\text{特征1,特征2,特征3}\} ) &=& P(\text{特征1})*P(\text{特征2}|\text{標簽i} )*P(\text{特征3} )\end{aligned}
P({特征1,特征2,特征3}∣標簽i)P({特征1,特征2,特征3})?==?P(特征1∣標簽i)?P(特征2∣標簽i)?P(特征3∣標簽i)P(特征1)?P(特征2∣標簽i)?P(特征3)?
這些量和**P(標簽i)**都是可以通過統計已有的樣本資料,用頻率來概率得到,
注意要,使用樸素貝葉斯分類方法,我們假設了特征之間相互獨立,看起來很有局限,事實上,我們在處理文本資料的時候,常常用到這種方法,
主要就是利用貝葉斯公式,把某組特征下產生某個標簽的概率進行了拆解,進一步拆解是利用到了特征之間的不相關性,
基本程序如下:
- 假設現在有樣本 x = ( a 1 , a 2 , a 3 , … a n ) x=\left(a_{1}, a_{2}, a_{3}, \ldots a_{n}\right) x=(a1?,a2?,a3?,…an?) 這個待分類項 (并認為 x x x 里面的特征獨立),
- 再假設現在有分類目標 Y = { y 1 , y 2 , y 3 , y 4 . . y n } Y=\left\{y_{1}, y_{2}, y_{3}, y_{4} . . y_{n}\right\} Y={y1?,y2?,y3?,y4?..yn?},
- 那么 max ? { P ( y 1 ∣ x ) , P ( y 2 ∣ x ) , P ( y 3 ∣ x ) … P ( y n ∣ x ) } \max \left\{P\left(y_{1} \mid x\right), P\left(y_{2} \mid x\right), P\left(y_{3} \mid x\right) \ldots P\left(y_{n} \mid x\right)\right\} max{P(y1?∣x),P(y2?∣x),P(y3?∣x)…P(yn?∣x)} 就是最終的分類類別,
- 而根據貝葉斯公式 P ( y i ∣ x ) = P ( x ∣ y i ) ? P ( y i ) P ( x ) P\left(y_{i} \mid x\right)=\frac{P\left(x \mid y_{i}\right) * P(y i)}{P(x)} P(yi?∣x)=P(x)P(x∣yi?)?P(yi)?,
- 因為 x x x 對于每個分類目標來說都一樣, 所以不用管分子,就是求 max ? { P ( x ∣ y i ) ? p ( y i ) } \max \left\{P\left(x \mid y_{i}\right) * p\left(y_{i}\right)\right\} max{P(x∣yi?)?p(yi?)},
- P ( x ∣ y i ) ? P ( y i ) = P ( y i ) ? ∏ j = 1 n ( P ( a j ∣ y i ) ) P\left(x \mid y_{i}\right) * P\left(y_{i}\right)=P\left(y_{i}\right) * \prod\limits_{j=1}^n\left(P\left(a_{j} \mid y_{i}\right)\right) P(x∣yi?)?P(yi?)=P(yi?)?j=1∏n?(P(aj?∣yi?))
- 而具體的 P ( a j ∣ y i ) P\left(a_{j} \mid y_{i}\right) P(aj?∣yi?) 和 P ( y i ) P\left(y_{i}\right) P(yi?) 都是能從訓練樣本中統計出來: p ( a j ∣ y i ) p\left(a_{j} \mid y_{i}\right) p(aj?∣yi?) 表示該類別下該特征出現的概率, p ( y i ) p\left(y_{i}\right) p(yi?) 表示全部類別中這個這個類別出現的概率,
就這么簡單,特征為離散值時直接統計即可(表示統計概率),特征為連續值的時候假定特征符合高斯分布,
拉普拉斯校驗
當某個類別下某個特征劃分沒有出現時,會有
P
(
a
∣
y
)
=
0
P(a \mid y)=0
P(a∣y)=0, 就是導致分類器質量降低, 所以此時引入 Laplace 校驗,就是對每個類別下所有劃分的計數加1,
特征不獨立問題
參考改進的貝葉斯網路,使用有向無環圖來進行概率圖的描述,
優缺點
- 優點: 對小規模的資料表現很好,適合多分類任務,適合增量式訓練,
- 缺點:對輸入資料的表達形式很敏感 (離散、連續, 值極大極小之類的) ,
logistic回歸
邏輯回歸在有些書中也叫對數幾率回歸,常用于分類問題,特別是二分類問題,邏輯回歸是線性回歸的一個延伸,對于二分類問題,我們需要將回歸的連續值搞成離散值,基本做法是看其是否大于零,那么引數如何選取呢?所謂的邏輯回歸,就是我們在原有的線性回歸的基礎上,外套一個Sigmoid函式作為取值的概率(準確地來說,應該是取值為正樣本 1 的概率),其實上也就是:
p ( y = 1 ∣ x ) = e w T x + b 1 + e w T x + b p ( y = 0 ∣ x ) = 1 1 + e w T x + b \begin{aligned} &p(y=1 \mid \boldsymbol{x})=\frac{e^{\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+b}}{1+e^{\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+\boldsymbol{b}}} \\ &p(y=0 \mid \boldsymbol{x})=\frac{1}{1+e^{\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+b}} \end{aligned} ?p(y=1∣x)=1+ewTx+bewTx+b?p(y=0∣x)=1+ewTx+b1??
我們通過最大似然估計來估計引數,最大似然估計就是寫出在引數下出現這個結果的概率(為了計算方便,一般取個對數),然后對于引數變數,極大化這個概率值,一般可以直接對引數直接求導,其實,也就是極大化如下的似然函式,
? ( w , b ) = ∑ i = 1 m ln ? p ( y i ∣ x i ; w , b ) \ell(\boldsymbol{w}, b)=\sum_{i=1}^{m} \ln p\left(y_{i} \mid \boldsymbol{x}_{i} ; \boldsymbol{w}, b\right) ?(w,b)=i=1∑m?lnp(yi?∣xi?;w,b)
所謂的Sigmoid函式,它的運算式和影像如圖所示,影像右端 y y y的取值表示將線性回歸的連續值按零點離散化,

邏輯回歸的并行化最主要的就是對目標函式梯度計算的并行化,邏輯回歸的條件分布是伯努利分布,而線性回歸的是高斯分布,邏輯回歸認為函式其概率服從伯努利分布,將其寫成指數族分布的形式,最后是可以推導得到 sigmoid 函式,這也是用這個函式的原因,
邏輯回歸用于多分類:
對于多分類問題,我們可以用 softmax,這時候優化的引數,不是向量,而是矩陣 θ \theta θ,我們用線性函式外套一個 softmax 作為每個第 j 個類別取值的概率:
p j = e θ j T x ∑ s = 1 k e θ s T x p_{j}=\frac{e^{\theta_{j}^{T} x}}{\sum_{s=1}^{k} e^{\theta_{s}^{T} x}} pj?=∑s=1k?eθsT?xeθjT?x?
別的程序是一樣的,
優缺點:
優點
- 實作簡單,
- 分類時計算量非常小,速度很快,存盤資源低,
缺點
- 容易欠擬合,一般準確度不太高,
- 只能處理兩分類問題(在此基礎上衍生出來的 softmax可以用于多分類),且必須線
性可分,
支持向量機
支持向量機,我們先說線性的情況,以可分的二維的二分類問題為例,它其實上就是尋找一根直線,將平面上的資料點正確地分為兩類,并滿足分割的間隔達到最大,如圖所示,

要分割(a)所示的資料點,顯然(b)的分割間隔要大于?的分割間隔,這里可變引數是分割線(“決策面”)的斜率和截距,所謂的間隔就是分割線離兩個資料集合的距離,它是用離它最近的一個點來衡量的,我們引兩根平行于分割線的面,相切兩個資料集,那么就形成了一個間隙,這個間隙內部不含任何的資料點,間隙邊緣上的點稱作支持向量,
如果將直線表示為
w
?
T
x
?
+
b
?
=
0
\vec{w}^T\vec{x}+\vec{b}={0}
w
Tx
+b
=0,那么合理的分割如圖,
通過數學推導,我們可以知道,這個問題其實就是求解如下的一個優化問題(
w
?
\vec{w}
w
和
b
?
\vec{b}
b
是待求變數):
KaTeX parse error: Unknown column alignment: @ at position 70: …\begin{array}{r@?{\quad}r@{}l@{\…

其中 y i ∈ { ? 1 , 1 } y_i\in \{-1,1\} yi?∈{?1,1},表示兩類樣本的標簽,通過最優化的基本理論(拉格朗日對偶,KKT條件,SMO演算法等),我們可以求解這個優化問題,
一般情況下,資料點不一定可以通過一個線性的超平面將其分開,那么我們可以將其映射到更高維的空間中,使其在高維的特征空間中線性可分,通過線性SVM方法將其分開,
線性情況下,最后的決策面的運算式可以表示為
f
(
x
)
=
∑
i
=
1
n
α
i
y
i
<
x
i
,
x
>
+
b
f(\textbf{x}) =\sum\limits_{i=1}^n \alpha_iy_i\left<\textbf{x}_i,\textbf{x}\right>+b
f(x)=i=1∑n?αi?yi??xi?,x?+b,這里的
α
i
\alpha_i
αi?是原問題拉格朗日乘子系數,對應于高維特征空間,使用線性SVM方法,最后決策面的運算式為:
f
(
x
)
=
∑
i
=
1
n
α
i
y
i
<
Φ
(
x
i
)
,
Φ
(
x
)
>
+
b
f(\textbf{x}) =\sum\limits_{i=1}^n \alpha_iy_i\left<\Phi(\textbf{x}_i),\Phi(\textbf{x})\right>+b
f(x)=i=1∑n?αi?yi??Φ(xi?),Φ(x)?+b,也就是說,分類決策函式只依賴于輸入x與訓練樣本的輸入的內積,
這里的 Φ \Phi Φ是原始空間到高維空間的一個映射,比如說它可以是 ( x , y ) → ( x , y , x 2 + y 2 ) (x,y)\rightarrow(x,y,x^2+y^2) (x,y)→(x,y,x2+y2),因為升維可能造成計算量暴漲,我們尋求一種方法可以直接計算內積 < Φ ( x i ) , Φ ( x ) > \left<\Phi(\textbf{x}_i),\Phi(\textbf{x})\right> ?Φ(xi?),Φ(x)?,即尋找一個函式 k ( x i , x ) k(x_i,x) k(xi?,x)來表示 < Φ ( x i ) , Φ ( x ) > \left<\Phi(\textbf{x}_i),\Phi(\textbf{x})\right> ?Φ(xi?),Φ(x)?,這種替換技巧叫做核技巧,因為核函式方法的存在,使得高維空間中的兩個向量的內積可以直接計算,大大減少了計算量,
高維空間的決策平面用核函式來表達,那么高維空間中的對偶問題等也可以用核函式來表達,當使用SMO演算法迭代求解時,計算量就會大大減小,簡單地說,核方法通過用核函式表示高維空間中向量的內積,將原空間升維至高維空間和在高維空間中使用線性SVM方法兩個步驟合成了一個步驟,所謂的升維,也可以理解為在原來線性基的基礎上,添加一些非線性的基函式,使得分割線不再是直線,
常用的核函式為徑向基函式,它的運算式為:
κ
(
x
1
,
x
2
)
=
e
?
∣
∣
x
1
?
x
2
∣
∣
2
2
σ
2
\kappa(x_1,x_2) = e^{\frac{-||x_1-x_2||^2}{2\sigma^2}}
κ(x1?,x2?)=e2σ2?∣∣x1??x2?∣∣2?
σ \sigma σ越小,非線性化程度越高,如果 σ \sigma σ選得很小,則可以將任意的資料映射為線性可分,這有可能會過擬合問題,
常用核函式有:多項式核函式、高斯核函式、字串核函式,
數學推導:
關于第一步的數學推導,我們只需要有以下的幾個基本認知:
- 我們用線性水平集函式 z = w T x + b z = \boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+b z=wTx+b的零水平集 w T x + b = 0 \boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+b=0 wTx+b=0來表示決策面,
- 點到決策面的距離是:
r = ∣ w T x + b ∣ ∥ w ∥ . r=\frac{\left|\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+b\right|}{\|\boldsymbol{w}\|} . r=∥w∥∣∣?wTx+b∣∣??.
這里的 ∥ w ∥ \|\boldsymbol{w}\| ∥w∥實際上是表示這個水平集函式的斜率, - 因為斜面的斜率不影響決策面,那么就不影響分類的結果,那么對于上述問題,事實上就多了一個自由度,那么我們就可以限制 w \boldsymbol{w} w,是的支持向量的距離 $d = \frac{1} {|\boldsymbol{w}|} $,那么約束的目標函式實際上就有了,
- 上述約束,其實也就以為著,對于決策點
∣
w
T
x
+
b
∣
=
1
\left|\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+b\right| = 1
∣∣?wTx+b∣∣?=1,那么要想其他點正確地分類,自然而然地就有:
{ w T x i + b ? + 1 , y i = + 1 w T x i + b ? ? 1 , y i = ? 1 \begin{cases}\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b \geqslant+1, & y_{i}=+1 \\ \boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b \leqslant-1, & y_{i}=-1\end{cases} {wTxi?+b?+1,wTxi?+b??1,?yi?=+1yi?=?1?
優缺點:
優點:
- 使用核函式可以向高維空間進行映射,可以解決非線性的分類,
- 分類思想很簡單,就是將樣本與決策面的間隔最大化,
- 分類效果較好,
缺點:
- 對大規模資料訓練比較困難,
- 無法直接支持多分類,一般使用間接的方法來做,直接方法可以在目標函式上下功夫,但計算量比較大,間接法有兩種,一種是一對多,即取出一類作為一類,另外的 N-1 類作為一類,做一次二分類,接著在分得的子類中重復這個操作,第二種是一對一,即兩兩之間都進行一次分類,最后看哪一類被分到的次數最多,就選哪一類(vote 的思想,libsvm,可以用回圈圖加速),
其他
隨機梯度下降
我們知道,在做有監督的問題中,有一個損失函式,用來衡量模型的好壞,在回歸問題中,如果我們已經知道方程的形式,我們可以做出問題的損失函式,那么我們要做的就是尋找方程的最佳引數,即尋找引數,使得損失函式函式達到最小,乍一聽,這就是個優化問題,當然可以對引數的各個分量求導,最后解方程組,問題是,你能確定最后的方程組好解?一般的數值解法有梯度下降法、牛頓法、擬牛頓方法以及信賴域方法等等,
梯度下降方法簡單易行,可是當資料量比較大時,梯度下降的計算就特別大,為解決大資料量的優化求解,我們一般可以采用隨機梯度下降,
所謂的隨機梯度下降,就是相比梯度下將,我們不選擇全部的資料點,而是每次隨機選擇一個或者若干個資料點來構建損失函式,接著再用梯度下降方法求解,看起來很不靠譜的樣子,事實上多做幾次這個操作,它是可以收斂的最優解的某個鄰域的,
隨機梯度下降比起梯度下降:
- 可以避免區域極值
- 收斂速度快
- 易并行
說完隨機梯度下降,順便提一下 Adam加速,Adam使用動量和自適應學習率來加快收斂速度,其在SGD基礎上加入了一、二階動量,
AdaGrad 能夠實作學習率的自動更改,如果這次梯度大,那么學習速率衰減的就快一些;如果這次梯度小,那么學習速率衰減的就滿一些,
線性判別分析
所謂的線性判別分析(LDA),實際上是一種有監督的降維方法,之所以把它放在分類的標題下,是因為資料通過這種方式,在距離上有了更高的區分度,也可以說是為后續的分類做了降維處理,
線性判別分析,以二維資料點舉例,就是要一條直線,使得資料點在這根直線上的投影滿足類內方差盡可能小,類間距離盡可能大,如圖所示,
投影面的選擇,往往會影響類內方差,和類間距離,顯然圖所示的右邊一個圖更能滿足我們的要求,


我們將類間距離的度量作為分子,類內距離的度量作為分母,形成一個目標函式,我們要做的就是最大化這個目標函式,利用廣義瑞利商等一些基本的知識,我們就將問題轉化為了求特征值的問題,
決策樹
決策樹,顧名思義就是像樹一樣不斷分支,我們對每個特征,選擇一定的條件進行判斷,就可以將資料不斷地分類,直到最后葉子節點滿足一定的條件,比如說有同一個標簽,那么這就是一棵決策樹,舉個例子,比如說西瓜好壞的判斷,從資料中,我們可能會學習出如圖所示的一棵決策樹,

分類問題,往往是給定若干組資料,每組資料有一些特征和標簽,需要找一棵決策樹,使得每組資料按照決策樹路徑走,最后盡可能地能走到使它正確分類的葉子節點中,一般來說,可能滿足條件的決策樹有很多,用于做判斷特征選擇的次序和特征判斷條件(閾值設定不同等)的不同都會導致樹的不同,我們要做的就是找一棵最好的樹,在不同的演算法中,“好”的標準往往不同,
比較常用的決策樹有ID3、C4.5和分類回歸樹(CART),他們分別使用資訊增益、資訊增益率和基尼指數來作為分類條件選擇好壞的標準,C4.5是為解決ID3因偏向細小分割造成的過擬合問題的,CART方法的過擬合往往由剪枝方法來處理,
- ID3 選擇資訊增益最大的特征作為當前節點的決策特征,
- C4.5 選擇資訊增益率大的作為劃分特征,
- CART 選擇那個使得劃分后基尼指數最小的屬性作為最優劃分屬性,
優缺點:
優點:
- 計算量簡單,可解釋性強,比較適合處理有缺失屬性值的樣本,能夠處理不相關的特
征,
缺點:
2. 單棵決策樹分類能力弱,并且對連續值變數難以處理,
3. 容易過擬合(后續出現了隨機森林,減小了過擬合現象),
基本概念:
資訊熵:
Ent
?
(
D
)
=
?
∑
k
=
1
∣
Y
∣
p
k
log
?
2
p
k
\operatorname{Ent}(D)=-\sum_{k=1}^{|\mathcal{Y}|} p_{k} \log _{2} p_{k}
Ent(D)=?k=1∑∣Y∣?pk?log2?pk?
資訊增益:
Gain
?
(
D
,
a
)
=
Ent
?
(
D
)
?
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
Ent
?
(
D
v
)
\operatorname{Gain}(D, a)=\operatorname{Ent}(D)-\sum_{v=1}^{V} \frac{\left|D^{v}\right|}{|D|} \operatorname{Ent}\left(D^{v}\right)
Gain(D,a)=Ent(D)?v=1∑V?∣D∣∣Dv∣?Ent(Dv)
增益率:
Gain
?
_
ratio
?
(
D
,
a
)
=
Gain
?
(
D
,
a
)
IV
?
(
a
)
\operatorname{Gain}\_{\operatorname{ratio}}(D, a)=\frac{\operatorname{Gain}(D, a)}{\operatorname{IV}(a)}
Gain_ratio(D,a)=IV(a)Gain(D,a)?
IV
?
(
a
)
=
?
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
log
?
2
∣
D
v
∣
∣
D
∣
\operatorname{IV}(a)=-\sum_{v=1}^{V} \frac{\left|D^{v}\right|}{|D|} \log _{2} \frac{\left|D^{v}\right|}{|D|}
IV(a)=?v=1∑V?∣D∣∣Dv∣?log2?∣D∣∣Dv∣?
基尼值:
Gini
?
(
D
)
=
∑
k
=
1
∣
Y
∣
∑
k
′
≠
k
p
k
p
k
′
=
1
?
∑
k
=
1
∣
Y
∣
p
k
2
\begin{aligned} \operatorname{Gini}(D) &=\sum_{k=1}^{|\mathcal{Y}|} \sum_{k^{\prime} \neq k} p_{k} p_{k^{\prime}} \\ &=1-\sum_{k=1}^{|\mathcal{Y}|} p_{k}^{2} \end{aligned}
Gini(D)?=k=1∑∣Y∣?k′?=k∑?pk?pk′?=1?k=1∑∣Y∣?pk2??
屬性 a 基尼指數:
KaTeX parse error: Expected '}', got '_' at position 14: \text { Gini_?index }(D, a)=\…
簡單來說就是分而治之的思想,
Cart : 分類模型:采用基尼系數的大小度量特征各個劃分點的優劣,回歸模型:采用誤差平方和度量,
無監督學習
聚類
k均值
所謂的k-mean演算法,就是要找到點的一個劃分(假設分成k類),使得類內平方和達到最小,用數學來表述就是要求解下式表示的優化問題,
arg
?
min
?
S
∑
i
=
1
k
∑
x
∈
S
i
∣
∣
x
?
μ
i
∣
∣
2
\mathop {\arg \min }\limits_S \sum\limits_{i = 1}^k {\sum\limits_{x \in {S_i}} {||x - {\mu _i}|{|^2}} }
Sargmin?i=1∑k?x∈Si?∑?∣∣x?μi?∣∣2
演算法的基本思想是迭代,首先選擇k個點作為k個類中心,將所有點按距離中心的遠近分配給k個類,接著計算k個類的重心作為新的類中心,繼續前述的分配程序,直到中心不再改變,那么分類也不再改變,
容易想到,更新中心為重心步驟,類內距離平方是不增的,重新分配點的步驟距離也是不增,距離平方和有下界,故而演算法必然是收斂的,
事實上,演算法收斂到會收斂到一個區域最優值,初始點選擇得不同,那么最終收斂到的結果可能就不同,
初始點的選擇:
-
首先隨機選取一個點作為初始點,然后選擇距離與該點最遠的那個點作為中心點,再選擇距離與前兩個點最遠的店作為第三個中心店,以此類推,直至選取大 k 個,
-
選用層次聚類或者 Canopy 演算法進行初始聚類,
kmeans 的優化:使用 kd 樹,將所有的觀測實體構建成一顆 kd 樹,之前每個聚類中心都是需要和每個觀測點做依次距離計算,現在這些聚類中心根據 kd 樹只需要計算附近的一個區域區域即可,
k 怎么選?
- 根據專家、行業經驗進行主觀判斷
- 基于變化的演算法:即定義一個函式,隨著 k 的改變,認為在正確的 k 時會產生極值,
- 基于結構的演算法:即比較類內距離,類間距離以確定 k,這也是比較常用的方法,如使用平均輪廓系數,越趨近于1,聚類效果越好,
- 基于一致性矩陣的演算法:即認為在正確的 k 時,不同次聚類的結果會近似,以此確定 k,
- 基于層次聚類:即基于合并或分裂的思想,在一定情況下停止從而獲得 k,
- 使用 BIC 演算法進行初始劃分,
- 基于采樣的演算法:即對樣本采樣,分別做聚類,根據這些結果的相似性確定 k,
- 使用 Canopy Method 演算法進行初始劃分,
分層次聚類
譜聚類
高斯混合模型
EM演算法可以形象地比喻雞生蛋,蛋生雞的程序,EM 用于隱含變數的概率模型的極大似然估計,它一般分為兩步:
- 第一步求期望(E)
- 第二步求極大(M)
如果概率模型的變數都是觀測變數,那么給定資料之后就可以直接使用極大似然法或者
貝葉斯估計模型引數,但是當模型含有隱含變數的時候就不能簡單的用這些方法來估計,EM 就是一種含有隱含變數的概率模型引數的極大似然估計法,
應用到的地方:混合高斯模型、混合樸素貝葉斯模型、因子分析模型,
降維
PCA降維
所謂的主成分分析,不過是在高維的空間中尋找一個低維的正交坐標系,比如說在三維空間中尋找一個二維的直角坐標系,那么這個二維的直角坐標系就會構成一個平面,將三維空間中的各個點在這個二維平面上做投影,就得到了各個點在二維空間中的一個表示,由此資料點就從三維降成了二維,
這個程序的關鍵在于,我們如何選取這個低維的坐標系,即坐標系原點在哪?各個軸朝哪個方向?一個原則就是使得各個點到到這個平面的距離平方和達到最小,由此,通過簡單地數學推導,就能得到原點的表達公式和坐標系的各個基向量的表達公式,
下面以基于矩陣的視角寫出PCA演算法的演算法流程,輸入為p*N矩陣X,輸出為d*N矩陣Y,矩陣的每一列都表示一個物件,每一行都表示物件的一個特征表示,
選取了2000x1680的資料集進行了測驗,選取降維后維數為20,其降維前后的影像(降維后的影像指的是投影點還原到原空間對應的坐標值重構出的影像)如下所示(選取第一個點為代表):


LLE降維
當資料具備某些非線性結構,如流形結構時,我們希望降維后的資料仍然保持這些結構,那么就提出了LLE降維演算法,
LLE (Locally linear embedding):在資料降維后仍然保留原始高維資料的拓撲結構,這種拓撲結構表現為資料點的區域鄰接關系,
此演算法我們首先要尋求每個資料點的k個最近鄰,然后將當前資料點用k個最近鄰線性表出,那么就有相對的權重系數,
我們希望資料在降維后資料點之間依然能保持這種線性表出的關系,并且在滿足另外一些約束條件的前提下,我們很容易求得降維后的資料,
具體原理和公式網路上有很多人整理得很好,這里不提了,
下面時LLE演算法的演算法流程,輸入為p*N矩陣X,輸出為d*N矩陣Y,矩陣的每一列都表示一個物件,每一行都表示物件的一個特征表示,

MDS和t-SNE
獨立成分分析
獨立成分分析的經典問題是“雞尾酒會問題”(cocktail party problem),該問題描述的是給定混合信號,如何分離出雞尾酒會中同時說話的每個人的獨立信號,當有N個信號源時,通常假設觀察信號也有N個(例如N個麥克風或者錄音機),
等距特征映射
譜嵌入
深度學習(一些基本概念)
我所理解的神經網路,無非就是向量和矩陣做乘法,對得到的向量加一個偏置后,外嵌套一個激活函式,得到一個新的向量,對新的向量反復以上程序,就得到新的一層網路……最后的結果和最后的標簽有偏差,我們通過鏈式法則等方式,調整權值矩陣,使偏差達到最小,訓練多層神經網路的程序一般就叫做深度學習,
我們所需要考慮的細節就是矩陣的規模,激活函式選什么,記憶體處理等等問題,
深度學習中的一些基本概念,
一維卷積(離散)
對于一維卷積的理解,是在一次坐火車的時候,所謂的一維卷積,無非就是兩列火車相向而馳,從頭碰頭,到尾離尾的程序,我們把兩個向量比作兩列火車,向量的元素比作每個車廂,那么兩個向量做卷積得到的值的每個分量就是計算每個時刻火車重疊部分的點乘,所謂的點乘,就是對應位置做乘法最后求和,花了一點時間做了一個gif如下:
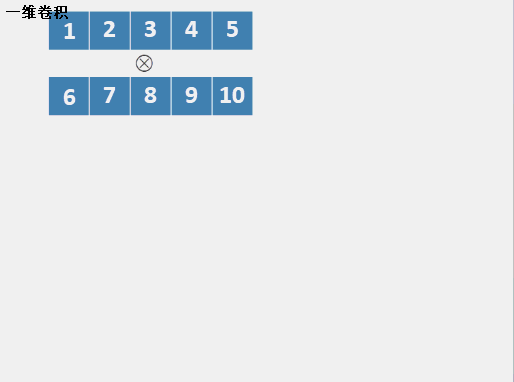
這里需要注意的是,兩列火車的長度不定,更不一定等長,可能只有一節車廂,也可能有一列火車或者兩列火車有無限長度,所以,卷積的長度=長火車的車廂數+短火車的車廂數-1,當然,也有的一維卷積只考慮計算短火車和長火車重疊部分包含短火車的時刻,即所謂的沒有padding,當然,滑動步長也可以不是1,
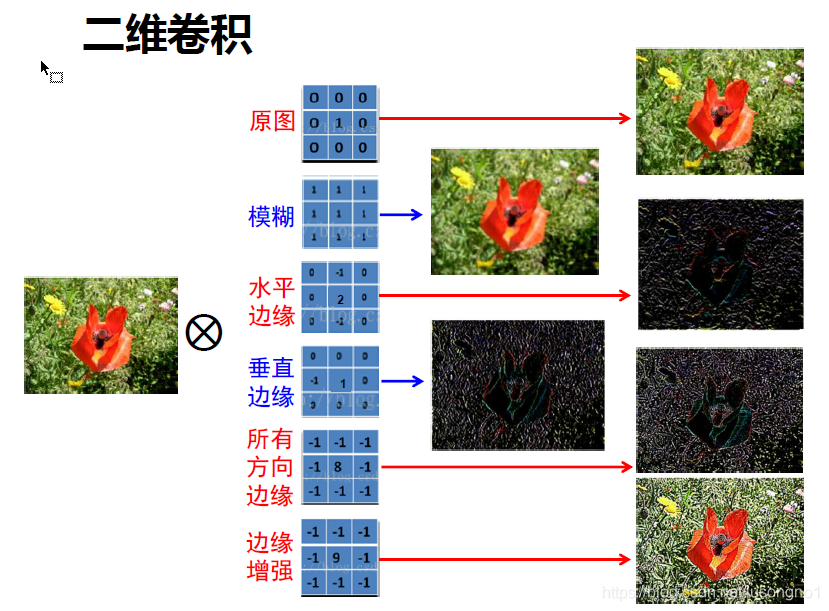
二維卷積(離散)
理解了一維卷積,二維卷積不過只是在一維卷積的基礎上,將一維向二維進行了擴充,即拿一個所謂的小矩陣(卷積核、濾波器)去按一定的順序去掃原矩陣,每個“時刻”都計算矩陣的一個點積,得到一個數值,如下圖所示:
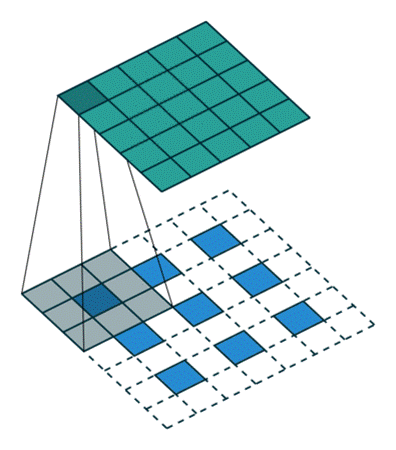
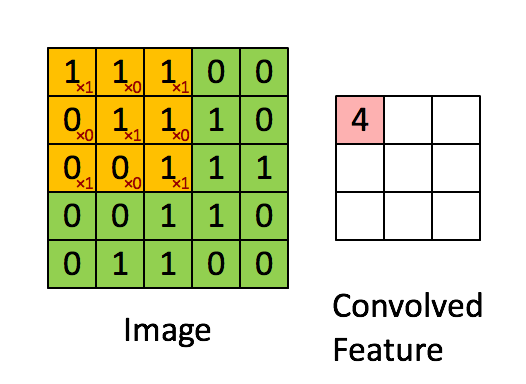
可以看出,在從有數字的地方開始卷(沒有padding)的話,且步長為1的話,卷出來的矩陣邊長=大矩陣邊長-小矩陣邊長+1,
那么,這么多有什么意義呢?舉個簡單的例子,它可以提取邊緣,如下:
padding
卷積網路,經常說padding,那么所謂的padding又是什么意思呢?一般來說,為了減少資訊的丟失或者其他的一些目的,padding表示在原有向量或者矩陣的邊緣上擴充地補一些數,比如說補0(zero padding),padding有三種模式,valid、same和full,什么意思呢?
- **valid:**表示不填充,那么在二維情況下,那么它輸出的size就可以表示為:
out_height = ceil(float(in_height - filter_height + 1) / float(strides[1]))
out_width = ceil(float(in_width - filter_width + 1) / float(strides[2]))
這個運算式中的 out_height 表示輸出的高度,in_height表示輸入的高度,filter_height 表示濾波器的高度,strides表示步長(兩個維度),width亦如是,
也就是說當步長為1時,如果用valid(不填充),那么做完卷積之后,矩陣的邊的長度就會減小 濾波器的長度-1,如果步長不為1,卷到后面如果不夠的話,后面的也不填充,直接drop掉,
舉個例子,一維,輸入長度為13,濾波器長度為6,步長為5,后面兩個數字,不夠濾波器長度,直接drop掉,

- **same:**所謂的相同,做填充,使得輸出的特征圖的空間維度和輸入的特征圖的空間維度是相同的(這里特征圖的概念后面會講到),事實上,這句話只是對步長為1的時候的描述是準確的,
我們先來看看這個輸出長度的運算式,再理解這個就簡單了,
out_height = ceil(float(in_height) / float(strides[1]))
out_width = ceil(float(in_width) / float(strides[2]))
我們現在要做的就是,在兩邊均勻地填充,使得卷出來的輸出滿足這個長度,一般的填充,我們都是盡可能均勻地填充在兩邊,如果要填充的個數為奇數個,實在無法均勻地填充地話,我們一般選擇讓右邊多填充一個,
很容易計算得到,我們需要填充的量為,以寬為例:max{filter_width-in_width%strides[2],0},百分號表示取余,特別地,in_width%1的值為1,算得這個數字之后,平均分配到兩邊,
下面舉幾個例子:
1、步長為1,卷出來的規模和原來的相同,體現了same的含義,

從這也可以看出,如果步長為1的話,我們做卷積一般是讓卷積核的中心放到最邊上一個開始卷,這樣的話,能保持卷出來的規模和原來的一樣,但是如果步長不為1的話就不一樣了,可以看下面一個例子,
2、一維,輸入長度為13,濾波器長度為6,步長為5,因為13/6取上界為3,所以要做一些填充,使得卷出來的東西長度為3,這也體現了所謂的same,

- **full:**如圖所示,設輸入的大小是7x7,filter的大小是3x3,full型的padding就是讓卷積卷出來的矩陣在不完全失去原有資訊的基礎上盡可能大,所謂的不完全失去,就是做卷積卷積核和原矩陣至少有一格的重復,
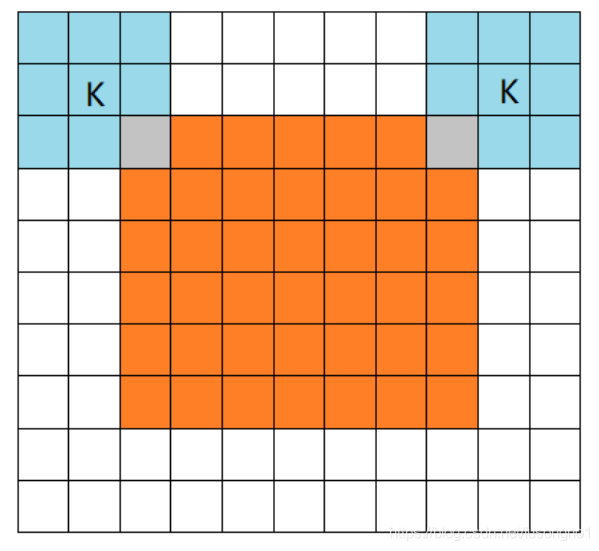
橙色部分為輸入, 藍色部分為filter,full模式的意思是,從filter和輸入矩陣剛相交開始就做卷積,白色部分為填0,
反卷積(轉置卷積)
好像要說清楚這個東西不是特別容易的事情,一句話解釋就是:反卷積相對于卷積,像是一個逆程序,注意,這里說的逆,只是規模上的逆,而不是整整意義下恢復原來矩陣的逆,想想這也是不可能的,
轉置卷積,把矩陣拉成向量來理解比較好理解,舉個栗子:4x4的輸入,卷積Kernel為3x3, 沒有Padding / Stride, 則輸出為2x2,這時,輸入矩陣可展開為16維向量,記作 x x x,輸出矩陣可展開為4維向量,記作 y y y,那么卷積運算可表示為 y = C x y = Cx y=Cx,事實上, C C C可以表示為如下:
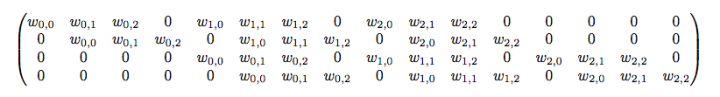
那么,轉置卷積是什么呢?沒錯,就是 x ^ = C T y ^ \hat x = C^T\hat y x^=CTy^?,
矩陣拉成向量確實好理解了,但是它在原矩陣(向量)時,又是怎么樣一種表現呢?能否可視化一下?二維比較抽象,以一維舉個例子,考慮no padding,步長為1的卷子,看看它的反卷積是什么,因為:
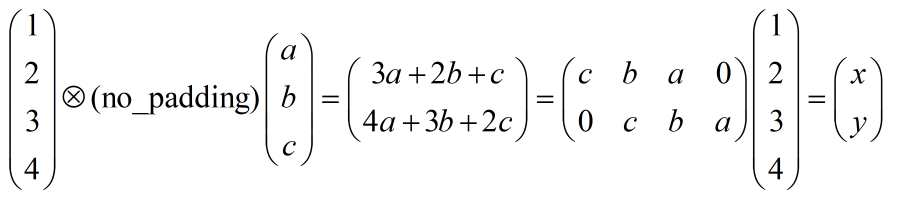
由上描述,可知:
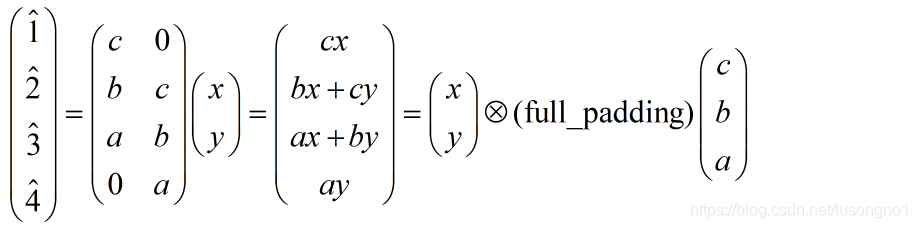
可以看得出來,這種情況下的反卷積,其實就是把卷積核倒過來,然后對輸入做full_padding的卷積,這是沒有步長的情況,我們再來看看有步長的情況,假設步長是2,依然是沒有padding的卷積,我們來看看反卷積,
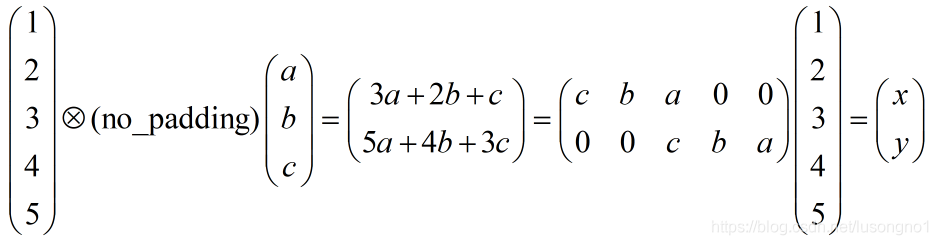
反卷積表示為:
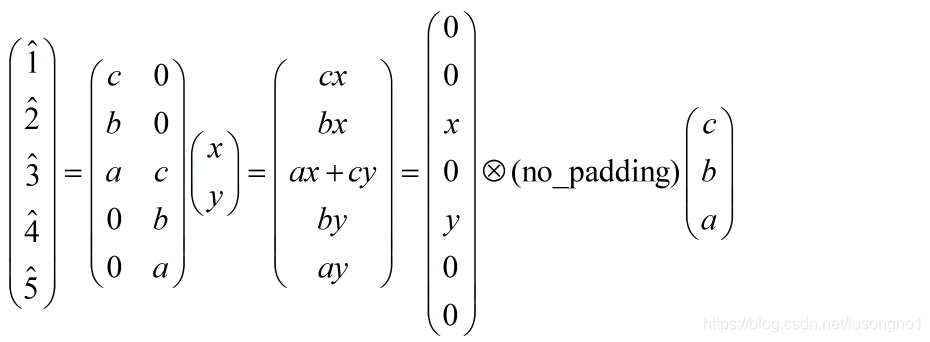
我們找一下上面兩種情況的規律,發現所謂的反卷積,就是把卷積核倒一下,對輸入矩陣做一些0值得插補,最后做各種形式的卷積(same、full等),我們把這個推廣到二維,梳理一下程序如下:
- 首先是將卷積核反轉(并不是轉置,而是上下左右方向進行遞序操作),
- 再將卷積結果作為輸入,做補0擴充操作,即往每一個元素后面補0,這一步是根據步長來的,對于每個元素沿著步長方向補(步長-1)個0,例如,步長為1就不用補0了,
- 在擴充后的輸入基礎上再對整體補0,以原始輸入的shape作為輸出,按照前面介紹的卷積padding規則,計算pading的補0的位置及個數,得到補0的位置及個數,得到補0的位置要上下和左右各自顛倒一下,
- 將補0后的卷積結果作為真正的輸入,反轉后的卷積核為filter,進行步長為1的卷積操作,
注意:計算padding按規則補0時,統一按照padding=‘SAME’、步長為1*1的方式來計算,
通過以上的介紹,我們已經基本了解了反卷積操作的程序,看下面幾張圖能夠更好地幫助理解,
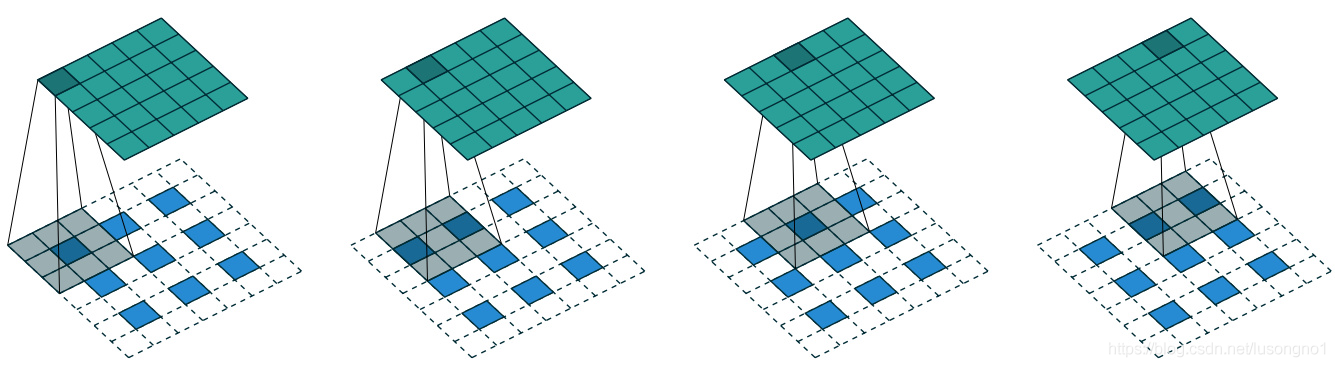
上圖是步長為2的反卷積的一個圖示,在藍色內部補夠0后,需要做到5的same padding,所以需要在藍色外部也要做padding,這里灰色那個是卷積核,表示原卷積核的一個上下顛倒,左右顛倒,當然,反卷積還有很多更一般的情況,總結起來為一下幾種:
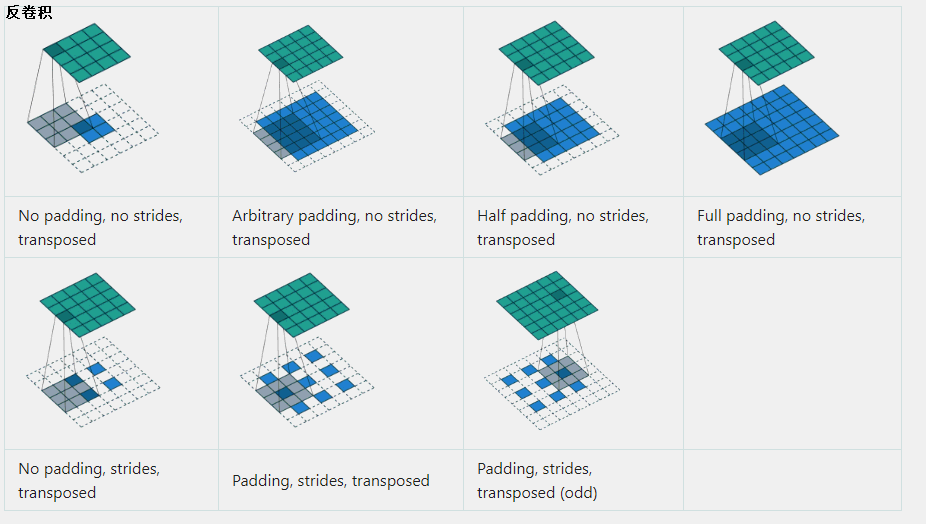
反卷積,可以理解為卷積操作的逆運算,千萬不要當成反卷積操作可以復原卷積操作的輸入值,反卷積并沒有那個功能,它僅僅是將卷積變換程序中的步驟反向變換一次而已,通過將卷積核轉置,與卷積后的結果再做一遍卷積,所以它還有個名字叫轉置卷積,
雖然它不能還原出原來卷積的樣子,但是在作用上具有類似的效果,可以將帶有小部分缺失的資訊最大化恢復,也可以用來恢復被卷積生成后的原始輸入,
學習率
就是梯度下降的步長,
反向傳播
應用梯度下降方法,需要導數,求導數的方法,有反向傳播,其實就是鏈式法則,
正則化
正則化是針對過擬合而提出的,正則化項是模型引數向量的范數,是為了降低模型的復雜度,一般的優化問題只是最小化經驗風險,正則化是在此基礎上加上模型復雜度這一項,并用一定的比率來衡量這一項的系數,加上這一項,可以防止模型訓練過度復雜,有效的降低過擬合的風險,
避免過擬合,提高泛化能力的方法有:
- L1、L2正則化
- 早點停止訓練
- 資料集擴增
- dropout
- 其他
正則化(Regularization)包括L1正則化、L2正則化,正則化其實就是在原有的loss funtion后面加上權重,
L2正則化(權重衰減)為:
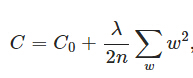
對權重求導,可得:
 這里體現了權重的一個衰減,
這里體現了權重的一個衰減,
L1正則化為:
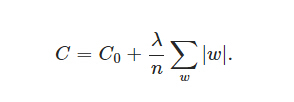
這個也可以做類似的求導,
L正則化,有點罰函式的味道,這里因為把權重加入到損失函式了,就盡量使得權重盡量小了,人們普遍認為:更小的權值w,從某種意義上說,表示網路的復雜度更低,對資料的擬合剛剛好(這個法則也叫做奧卡姆剃刀),
引數服從拉普拉斯分布匯出 L1 正則化,引數服從高斯分布,匯出 L2 正則化,
softmax
softmax是一種歸一化,它的好處就是使得計算上非常方便,誰用誰知道,
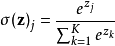
Softmax計算簡單,效果顯著,非常好用,它也能緩解區域極值的問題,
dropout
所謂的dropout,就是以一定的概率p(比如說0.5)先把隱藏層的部分節點藏起來(之所以叫藏起來,是因為與之相關的權重一直都在,只是不更新,下一次選擇的時候,如果被藏的節點顯示出來了,與之相關的權重還是保持原來的權重),變成一個比較小的網路,對于這個比較小的網路訓練,訓練到一定程度后,這些顯示節點的權重有所更新了,這時候顯示隱藏節點,重新以概率p進行選擇……反復進行這個程序,知道訓練好一個網路,測驗的時候,用的是所有的節點,只不過權重得乘以p,
它的基本程序如下:
- 首先隨機(臨時)刪掉網路中一半的隱藏神經元(備份被洗掉神經元的引數),輸入輸出神經元保持不變(圖中虛線為部分臨時被洗掉的神經元),
- 對于修改后的網路,使用一小批訓練樣本去訓練,按隨機梯度下降法更新對應的引數,
- 恢復隱藏的神經元,包括恢復與它相關的原來的引數,重復上述程序(此時被洗掉的神經元保持原樣,而沒有被洗掉的神經元已經有所更新),
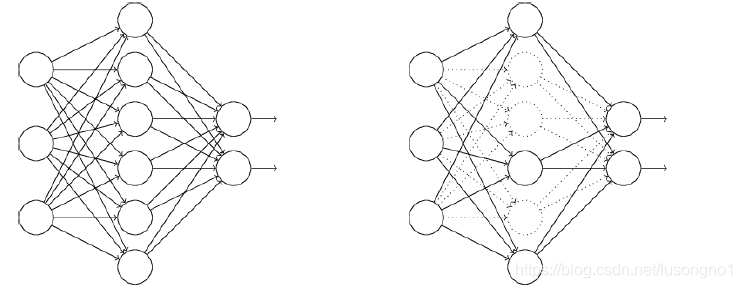
dropout是一種有效的防止過擬合的方法,另外也是為了減少計算量,它是緩解過擬合的技巧之一,
dropout也是一種集成,如圖:
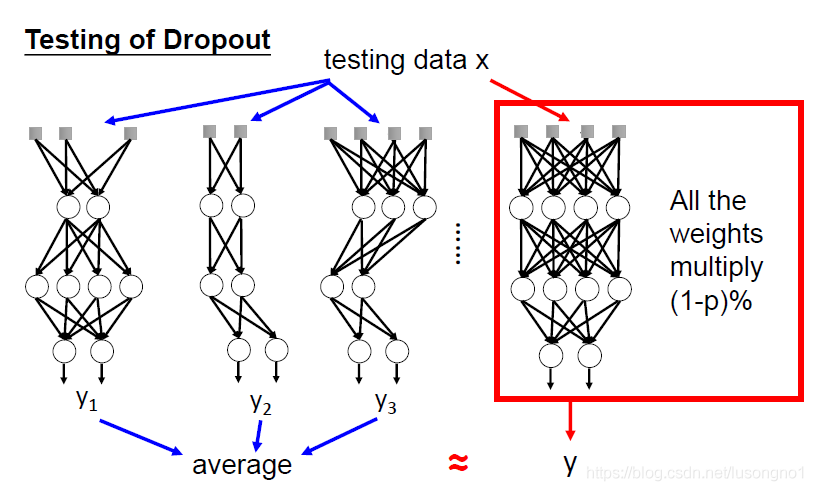
它相當于訓練時隨機丟棄部分神經元,測驗時整合所有神經元,dropout為什么能work呢?好像大家都沒有一個很好的解釋,簡單地理解,有時候,老板交付的任務,兩個人單獨完成再整合,總比兩個人一塊做結果要好,有點“三個和尚沒水喝”的意思,但也不是絕對的,
歷史

隨機梯度下降(mini-batch)
我們知道,在做有監督的問題中,有一個損失函式,用來衡量模型的好壞,在回歸問題中,如果我們已經知道方程的形式,我們可以做出問題的損失函式,那么我們要做的就是尋找方程的最佳引數,即尋找引數,使得損失函式函式達到最小,乍一聽,這就是個優化問題,當然可以對引數的各個分量求導,最后解方程組,問題是,你能確定最后的方程組好解?一般的數值解法有梯度下降法、牛頓法、擬牛頓方法以及信賴域方法等等,梯度下降方法簡單易行,可是當資料量比較大時,梯度下降的計算就特別大,
為解決大資料量的優化求解,我們一般可以采用隨機梯度下降,所謂的隨機梯度下降,就是相比梯度下降,我們不選擇全部的資料點,而是每次隨機選擇一個或者若干個資料點(一個資料點)來構建損失函式,接著再用梯度下降方法求解,看起來很不靠譜的樣子,事實上多做幾次這個操作,它是可以收斂的最優解的某個鄰域的,
萬有逼近定理
-
如果一個隱層包含足夠多的神經元,三層前饋神經網路(輸入-隱層
-輸出)能以任意精度逼近任意預定的連續函式, -
當隱層足夠寬時,雙隱層感知器(輸入-隱層1-隱層2-輸出)可以逼
近任意非連續函式:可以解決任何復雜的分類問題,
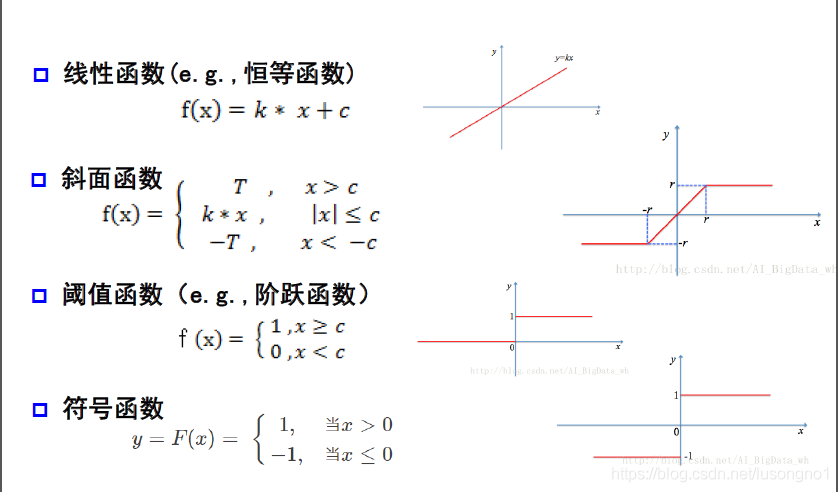
幾種激活函式
常用激活函式如下:
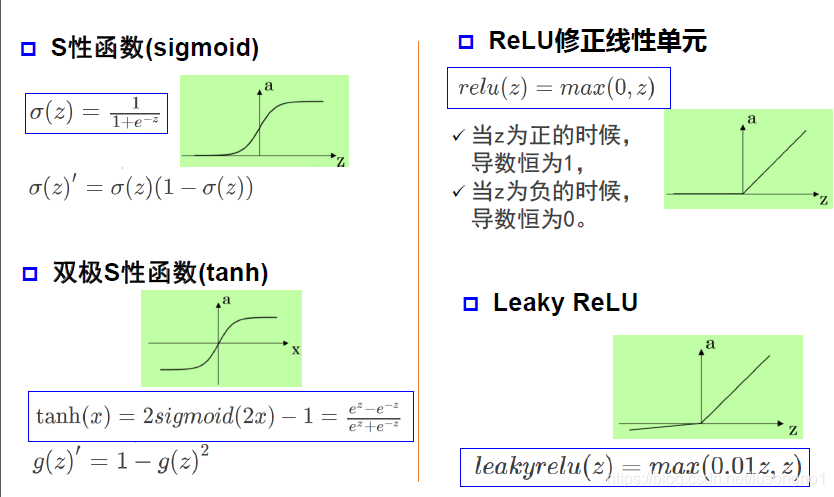
白化
白化的目的是去除輸入資料的冗余資訊,比如訓練資料是影像,由于影像中相鄰像素之間具有很強的相關性,所以用于訓練時輸入是冗余的,白化的目的就是降低輸入的冗余性,
所謂白化,就是對輸入資料分布變換到均值為0,方差為1的正態分布,那么神經網路較快收斂,BN也是源于這個想法,
動量方法

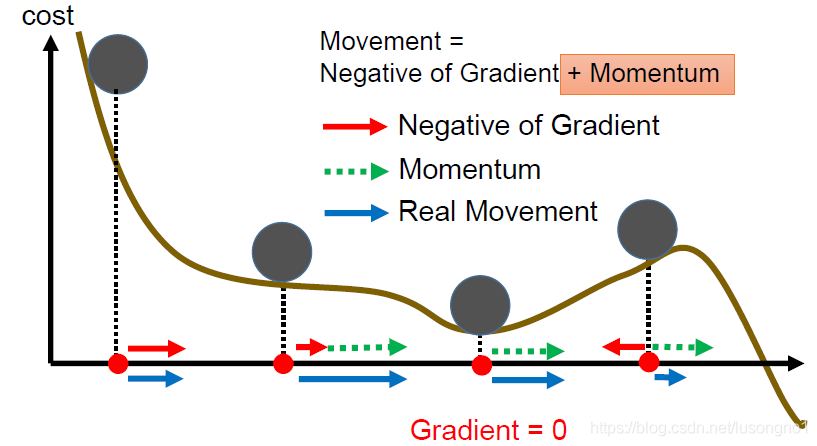
梯度下降,一般是沿著當前點的負梯度方向走一小步,到下一點,又沿那個那個點的負梯度方向走一步,那么這樣走走停停,無疑是走得很慢,
 ])
])
而一個真正的小球的下降要比這聰明多了,從A點滾動到B點的時候,小球帶有一定的初速度,在當前初速度下繼續加速下降,小球會越滾越快,更快的奔向谷底,momentum動量法就是模擬這一程序來加速神經網路的優化的,
它的基本演算法如下:
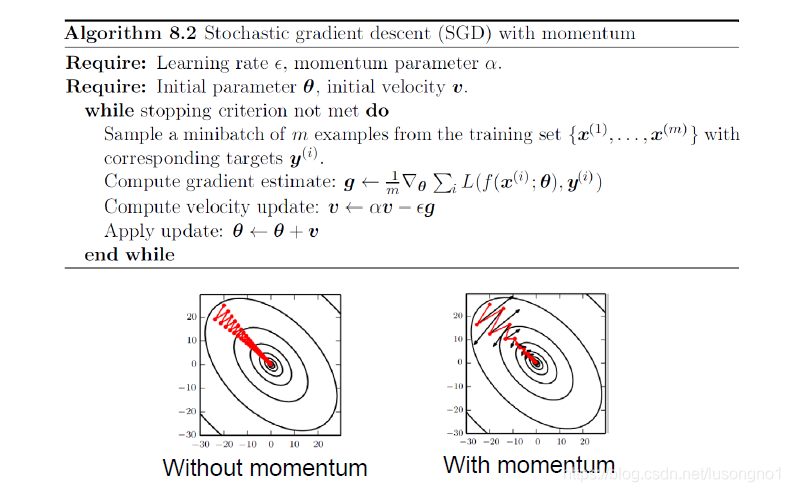
最為關鍵的一步就是,走的步長 v n v_n vn?(稱為速度)是由當前的負梯度方向和前一步的速度 v n ? 1 v_{n-1} vn?1?做線性組合得到的,前一步的速度又和前前步的速度有關,以此類推,就把速度積累下來了,也就是說,當前的行走的方向和步長,還要綜合考慮之前所有的走過的步的方向和步長,我們知道,不管是做傅里葉分析還是做半加速迭代,都習慣把之前的值做個加權平均,好像收斂就會快很多,monmentum好像就有點這個意思,它是為了解決一般SGD方法一直震蕩而遲遲不收斂的情況,
動量方法有點像CG,要結合之前的資訊,
交叉熵和KL散度
交叉熵和KL散度以及JS散度都是衡量兩個分布(向量)的距離的一種度量,
交叉熵:
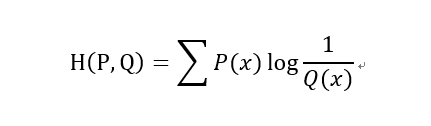
KL散度(KL距離,相對熵):
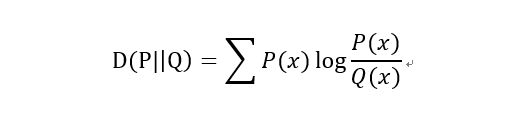
JS散度(JS距離,KL散度的變形):
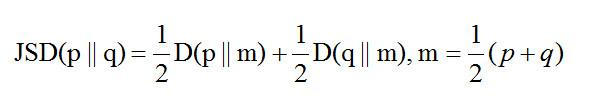
batch normalization
所謂的batch normalization(批量歸一化、批量正則化)就是“減去均值,除以方差”的標準化程序,比如一般正態分布變成標準正態分布,基本思想就是讓每個隱層節點的激活輸入分布固定下來,來提升訓練速度,
它有什么用呢?它主要是為了**避免梯度消失,加速收斂,**把輸入資料重新拉回到均值為0,方差為1的區域,這樣讓每層的輸入落在(-1,1)區間,這段剛好是激活函式性能最好的區域,它是分布變得更加均勻,從而梯度方向更接近極值點方向,如下圖:
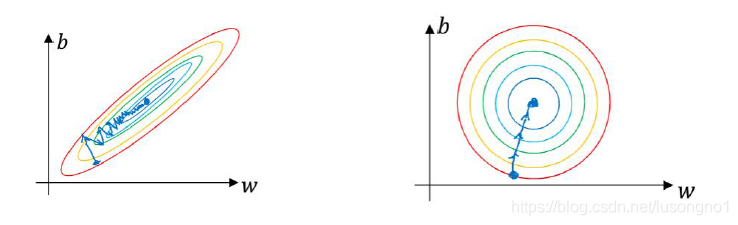
另外,它也克服神經網路受不同初值影響較大的缺點,促進神經網路穩定性發展:使不同層相對獨立,每一層可以專注解決本層的問題,
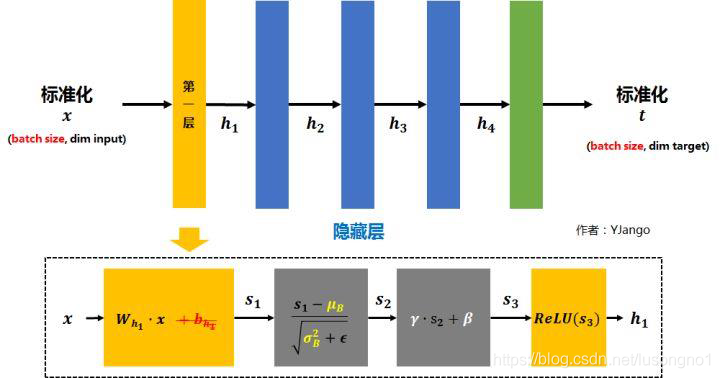
maxout
maxout是一種新型的激活函式,能夠緩解梯度消失,規避了ReLU神經元死亡的情況,但增加的引數和計算量,它其實就是在原有激活的基礎上,取個最大值,如下所示:
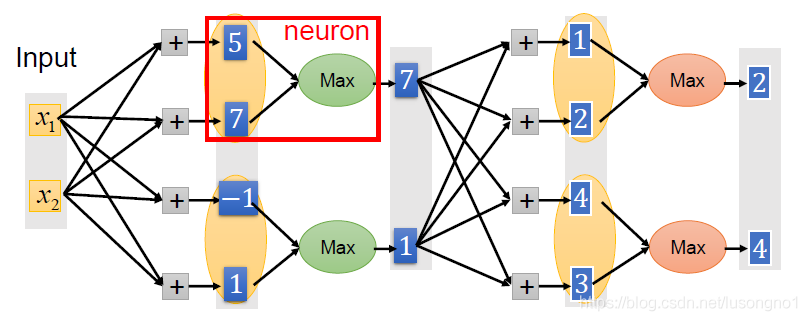
既然maxout是一個函式,那么它的輸入,輸出是什么?函式影像又是如何?
如果我們設定maxout的引數k=5,maxout層就如下所示:
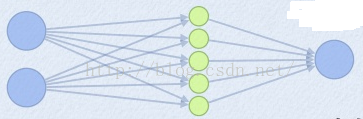
相當于在每個輸出神經元前面又多了一層,這一層有5個神經元,此時maxout網路的輸出計算公式為:
z1=w1*x+b1
z2=w2*x+b2
z3=w3*x+b3
z4=w4*x+b4
z5=w5*x+b5
out=max(z1,z2,z3,z4,z5)
所以這就是為什么采用maxout的時候,引數個數成k倍增加的原因,本來我們只需要一組引數就夠了,采用maxout后,就需要有k組引數,
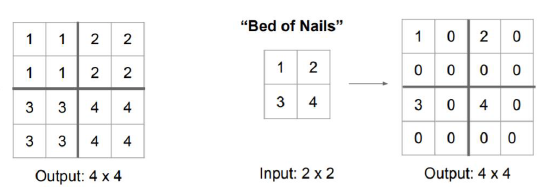
上采樣和下采樣
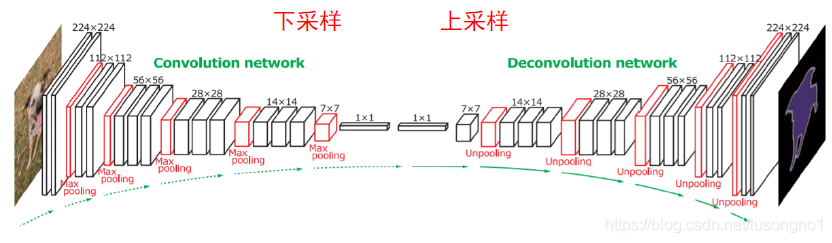
下采樣就是變小輸入,上采樣就是就是變大矩陣,有點“插值”的意思,
一般來說下采樣指的就是池化,上采樣包括unpooling和轉置卷積(transpose convolution)和一般的插值等,unpooling就是反池化,在池化程序中,記錄下max-pooling在對應kernel中的坐標,在反池化程序中,將一個元素根據kernel進行放大,根據之前的坐標將元素填寫進去,其他位置補0 ,
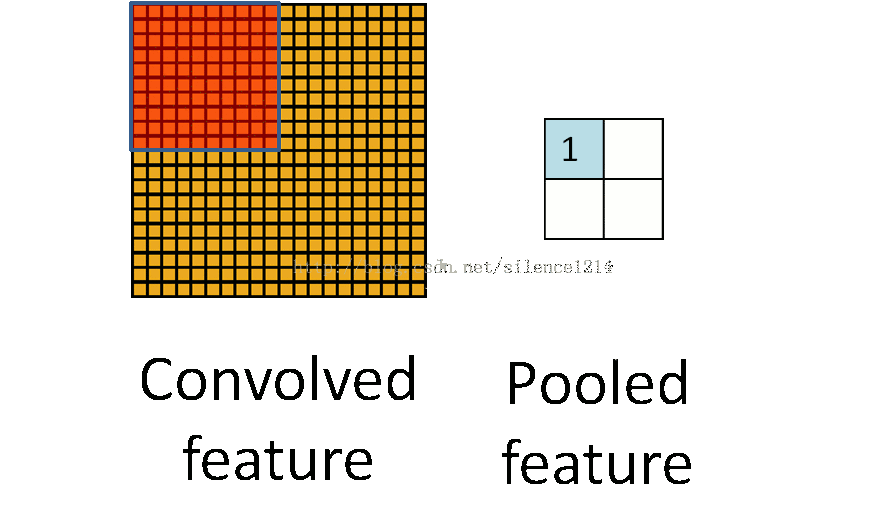
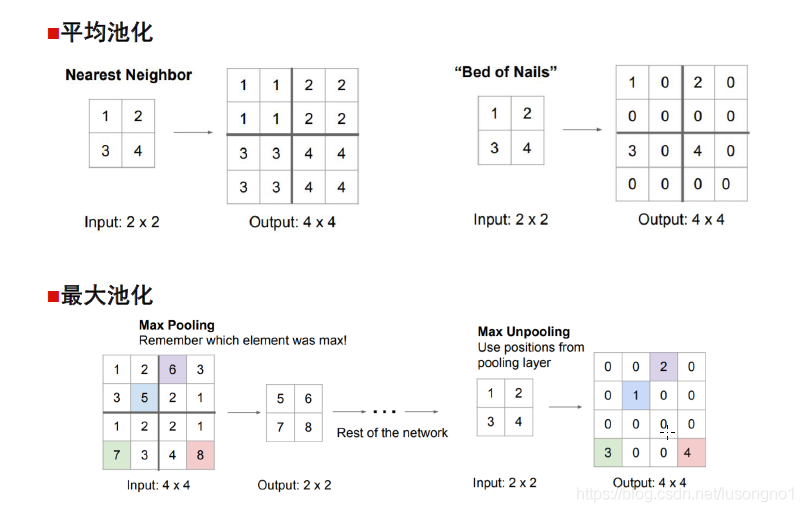
池化
池化對特征圖的每個局域進行下采樣,作為這個區域的概括,池化包括平均池化mean-pooling和最大池化max-pooling,所謂的池化,其實就是講輸入分塊,對每塊去平均值或者最大值,
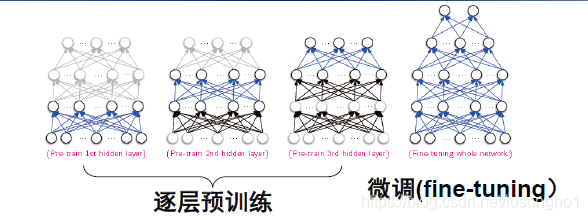
預訓練
假設你想要解決一個復雜的任務,你沒有太多的標記的訓練資料,但不幸的是,你不能找到一個類似的任務訓練模型, 不要失去所有希望! 首先,你當然應該嘗試收集更多的有標簽的訓練資料,但是如果這太難或太昂貴,你仍然可以進行無監督的訓練, 也就是說,如果你有很多未標記的訓練資料,你可以嘗試逐層訓練層,從最低層開始,然后上升,使用無監督的特征檢測演算法,如限制玻爾茲曼機(RBM)或自動編碼器, 每個層都被訓練成先前訓練過的層的輸出(除了被訓練的層之外的所有層都被凍結), 一旦所有層都以這種方式進行了訓練,就可以使用監督式學習(即反向傳播)對網路進行微調,
然而,貌似主流的深度學習平臺甚至都不支持RBM和預訓練,所以,不必深究,
預訓練在沒有太多工具的情況下,能夠解決梯度消失和區域極值,訓練困難,訓練時間長等問題,但它本質上無法解決梯度消失的問題,
自編碼機
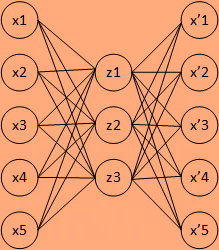
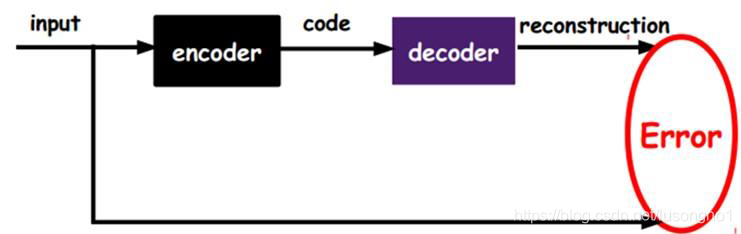
自編碼器其實是通過神經網路,學會重構自己的程序,
自編碼器(autoencoder)假設輸出與輸入相同(target=input),是一種盡可能復現輸入信號的神經網路,將input輸入一個encoder編碼器,就會得到一個code,加一個decoder解碼器,輸出資訊,通過調整encoder和decoder的引數,使得重構誤差最小,它是一種非監督學習,因為無標簽資料,誤差的來源是直接重構后信號與原輸入相比得到,
梯度消失(爆炸)和區域極值
所謂的梯度消失,具體來說,由于在向后傳遞程序中,sigmoid向下傳遞的梯度包含了一個f’(x) 因子(sigmoid關于輸入的導數),因此一旦輸入落入飽和區,f’(x) 就會變得接近于0,導致了向底層傳遞的梯度也變得非常小,此時,網路引數很難得到有效訓練,這種現象被稱為梯度消失,一般來說, sigmoid 網路在5 層之內就會產生梯度消失現象,Relu函式可以有效緩解這種情況,
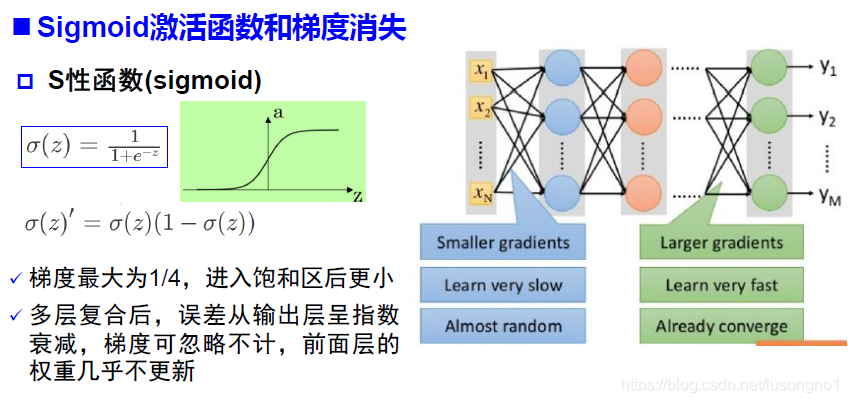
反之,如何激活函式導數乘以很大的神經網路權重引數w,那么因為乘積大于1,就會發生梯度爆炸現象,
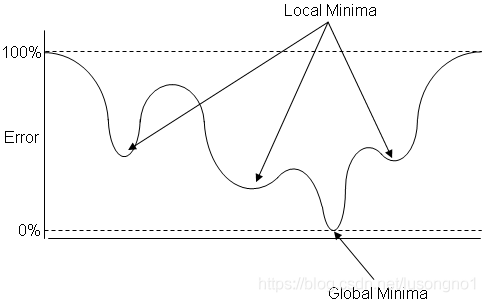
區域極小值很好理解,因為近似的函式非凸,就容易陷入區域極值,
Flatten
Flatten層用來將輸入“壓平”,即把多維的輸入一維化,常用在從卷積層到全連接層的過渡,其實就是把矩陣拉成一條,
特征圖
在做二維卷積中,用濾波器卷一次得到的結果就是一個特征圖,不同的濾波器,做多次卷積操作就會得到多個特征圖,濾波器就是卷積核,
強化學習
強化學習到底是什么?若是想略微了解強化學習大概的意思和操作,把握一個主干知識,而不做深入研究,看這篇文章就很夠了,
核心內容
元素簡介
強化學習考察的是對于一個物件(智能體),從一個狀態執行某種動作到下一個狀態,并在這個程序中,給其一定的獎賞或者懲罰,是它盡可能往好的方面去做,就像馬戲團的馴養師,對其寵物,若其表現好,就給它一點吃的,若其表現不好,就抽它兩鞭子,使得它最后,能夠有一系列出色的表現,
為了說清楚這個問題,我們需要介紹一下狀態空間 S S S、動作集 A A A、狀態轉移概率 P P P和獎賞 R R R,
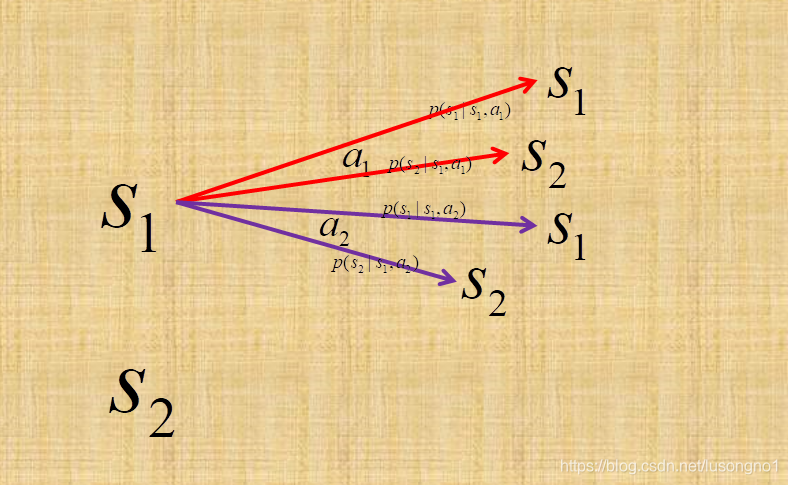
如圖所示,狀態空間表示所有狀態的一個集合,動作集表示所有動作的一個集合,
狀態轉移概率是一個函式,表示在當前狀態 s s s下,執行某個動作 a a a之后,轉移到某個狀態的概率,即 P : S × A × S ? R P : S \times A \times S \mapsto \mathbb{R} P:S×A×S?R指定了轉移概率,舉例比如說狀態 s 1 s_1 s1?下,執行動作 a 1 a_1 a1?,可能轉移到 s 1 s_1 s1?,也可能轉移 s 2 s_2 s2?,二者概率不同,圖示 s 2 s_2 s2?也是可以以一定的概率執行相應的動作,執行相應的動作,都以一定的概率轉移到不同的狀態,為了圖示簡明,沒有畫出來,
R : S × A × S ? R R : S \times A \times S \mapsto \mathbb{R} R:S×A×S?R指定了獎賞,這個獎賞不僅跟起始狀態和動作有關,也和動作執行后達到的狀態有關,
還有一個是策略函式 π \pi π,它表示給你一個狀態,你應該要執行什么動作,當然,如果你執行的動作不確定,而是以一定概率執行相應的動作,那么 π \pi π其實就是對應于動作的概率函式,即用 π ( s , a ) \pi(s,a) π(s,a)表示在狀態s下選擇動作a的概率,要有 ∑ a π ( s , a ) = 1 \sum_{a} \pi(s, a)=1 ∑a?π(s,a)=1,
優化目標:狀態值函式
給定一個策略 π \pi π(這個策略不一定是最優的),那么對于執行動作的步數有限(設為 T T T步)和無限的時候,我們分別定義狀態值函式:
{ V T π ( s ) = E π [ 1 T ∑ t = 1 T r t ∣ s 0 = s ] V γ π ( s ) = E π [ ∑ t = 0 + ∞ γ t r t + 1 ∣ s 0 = s ] \left\{\begin{array}{l}{V_{T}^{\pi}(s)=\mathbb{E}_{\pi}\left[\frac{1}{T} \sum_{t=1}^{T} r_{t} | s_{0}=s\right]} \\ {V_{\gamma}^{\pi}(s)=\mathbb{E}_{\pi}\left[\sum_{t=0}^{+\infty} \gamma^{t} r_{t+1} | s_{0}=s\right]}\end{array}\right. {VTπ?(s)=Eπ?[T1?∑t=1T?rt?∣s0?=s]Vγπ?(s)=Eπ?[∑t=0+∞?γtrt+1?∣s0?=s]?
這個狀態值函式的意思就是在當前狀態 s s s下,平均累積獎賞的一個數學期望,它是一個函式,對于不同的狀態 s s s,它有不同的值,當步數是無窮的時候,我們定義一個折扣因子 γ \gamma γ,使得距離越遠的地方,獎賞的對累積獎賞影響越小,這里的數學期望,其實有兩層含義,一個是指定動作之后,可能會以不同的概率轉移到不同的狀態,可以求一個期望,另一個是,對于狀態 s s s而言,會以 π ( s , a ) \pi(s,a) π(s,a)的概率執行不同的動作,對于不同的動作可以求一個期望,
所以,我們想要做的,其實就是想辦法找一個策略,使得這個狀態值函式達到最大,這是我們的目標,
有了這個優化目標,我們來看看如何最大化這個優化目標,
不妨考慮模型已知的情況,即狀態空間,動作空間,轉移概率和獎賞我們都是知道的,在模型不是已知的情況下,比如說獎賞Reward不清楚,我們可以使用模特卡洛的方法,讓智能體多做幾次動作,計算累積回報,求得平均來得到我們需要的獎賞值,貪婪演算法是在“探索”(exploration)和“利用”(exploitation)之間取一個折中,所謂的探索,其實就是以頻率替代概率,多做幾次實驗,取平均值,來作為我們需要的值的期望,所謂的利用,就是在策略中選擇期望最大的動作,
對于有限步情況,考慮某一個指定的策略 π \pi π,因為模型已知,它的狀態值函式根據數學期望的定義可以進行拆分和全概率展開:
V T π ( s ) = E π [ 1 T ∑ t = 1 T r t ∣ s 0 = s ] = E π [ 1 T r 1 + T ? 1 T 1 T ? 1 ∑ t = 2 T r t ∣ s 0 = s ] = ∑ a ∈ A π ( s , a ) ∑ s ′ ∈ S P ( s ′ ∣ s , a ) ( 1 T R ( s ′ ∣ s , a ) + T ? 1 T E π [ 1 T ? 1 ∑ t = 1 T ? 1 r t ∣ s 0 = s ′ ] ) = ∑ a ∈ A π ( s , a ) ∑ s ′ ∈ S P ( s ′ ∣ s , a ) ( 1 T R ( s ′ ∣ s , a ) + T ? 1 T V T ? 1 π ( s ′ ) ) \begin{aligned} V_{T}^{\pi}(s) &=\mathbb{E}_{\pi}\left[\frac{1}{T} \sum_{t=1}^{T} r_{t} | s_{0}=s\right] \\ &=\mathbb{E}_{\pi}\left[\frac{1}{T} r_{1}+\frac{T-1}{T} \frac{1}{T-1} \sum_{t=2}^{T} r_{t} | s_{0}=s\right] \\ &=\sum_{a \in A} \pi(s, a) \sum_{s^{\prime} \in S} P(s^{\prime}|s,a)\left(\frac{1}{T} R(s'|s,a)+\frac{T-1}{T} \mathbb{E}_{\pi}\left[\frac{1}{T-1} \sum_{t=1}^{T-1} r_{t} | s_{0}=s^{\prime}\right]\right) \\ &=\sum_{a \in A} \pi(s, a) \sum_{s^{\prime} \in S} P(s^{\prime}|s,a)\left(\frac{1}{T} R(s'|s,a)+\frac{T-1}{T} V_{T-1}^{\pi}\left(s^{\prime}\right)\right) \end{aligned} VTπ?(s)?=Eπ?[T1?t=1∑T?rt?∣s0?=s]=Eπ?[T1?r1?+TT?1?T?11?t=2∑T?rt?∣s0?=s]=a∈A∑?π(s,a)s′∈S∑?P(s′∣s,a)(T1?R(s′∣s,a)+TT?1?Eπ?[T?11?t=1∑T?1?rt?∣s0?=s′])=a∈A∑?π(s,a)s′∈S∑?P(s′∣s,a)(T1?R(s′∣s,a)+TT?1?VT?1π?(s′))?
對于無限步的情況,也可以類似展開得到如下結果:
V γ π ( s ) = ∑ a ∈ A π ( s , a ) ∑ s ′ ∈ S P ( s ′ ∣ s , a ) ( R ( s ′ ∣ s , a ) + γ V γ π ( s ′ ) ) V_{\gamma}^{\pi}(s)=\sum_{a \in A} \pi(s, a) \sum_{s^{\prime} \in S} P(s^{\prime}|s,a)\left(R(s'|s,a)+\gamma V_{\gamma}^{\pi}\left(s^{\prime}\right)\right) Vγπ?(s)=a∈A∑?π(s,a)s′∈S∑?P(s′∣s,a)(R(s′∣s,a)+γVγπ?(s′))
上面這倆方程,姑且就叫做值函式遞回方程(也叫貝爾曼方程?),從值函式遞回方程上看,我們可以知道,當模型已知,策略已知的情況下,我們其實是可以遞回地求得在該策略下各個時刻的狀態值函式,也就是說,從值函式的初始值 V 0 π V^\pi_0 V0π?出發,通過一次迭代求得各個狀態的一步獎賞 V 1 π V_1^\pi V1π?,進而再通過一次迭代求得 V 2 π V_2^\pi V2π?……
狀態-動作值函式
狀態-動作值表示的是在某狀態下,執行動作 a a a后的一個平均累積獎賞,它和狀態值函式相比,因為動作給定了,所以不再計算關于動作的期望,即:
{ Q T π ( s , a ) = ∑ s ′ ∈ S P ( s ′ ∣ s , a ) ( 1 T R ( s ′ ∣ s , a ) + T ? 1 T V T ? 1 π ( s ′ ) ) Q γ π ( s , a ) = ∑ s ′ ∈ S P ( s ′ ∣ s , a ) ( R ( s ′ ∣ s , a ) + γ V γ π ( s ′ ) ) \left\{\begin{array}{l}{Q_{T}^{\pi}(s, a)=\sum_{s^{\prime} \in S} P(s^{\prime}|s,a)\left(\frac{1}{T} R(s'|s,a)+\frac{T-1}{T} V_{T-1}^{\pi}\left(s^{\prime}\right)\right)} \\ {Q_{\gamma}^{\pi}(s, a)=\sum_{s^{\prime} \in S} P(s^{\prime}|s,a)\left(R(s'|s,a)+\gamma V_{\gamma}^{\pi}\left(s^{\prime}\right)\right)}\end{array}\right. {QTπ?(s,a)=∑s′∈S?P(s′∣s,a)(T1?R(s′∣s,a)+TT?1?VT?1π?(s′))Qγπ?(s,a)=∑s′∈S?P(s′∣s,a)(R(s′∣s,a)+γVγπ?(s′))?
所以,如果通過值函式遞回方程算得了狀態值函式,我們就可以通過上述表達來求得每一時刻的狀態-動作值函式,
策略迭代和值迭代
策略迭代
通過以上的論述,相必大家有一定的想法來計算最優策略,一個自然而然的思路就是策略迭代演算法,
演算法的基本程序就是先隨意給定一個策略,比如說 π ( s , a ) = 1 ∣ A ( s ) ∣ \pi(s, a)=\frac{1}{|A(s)|} π(s,a)=∣A(s)∣1?,然后通過值函式遞回運算式,算出該策略下每一個時刻的值函式,有了值函式,我們通過狀態-動作值函式的運算式,可以求解每一個時刻的狀態動作值,有了狀態-動作值函式,我們可以通過關于動作最大化狀態-動作值函式,進行更新策略: π ′ ( s ) = arg ? max ? a ∈ A Q π ( s , a ) \pi^{\prime}(s)=\underset{a \in A}{\arg \max } Q^{\pi}(s, a) π′(s)=a∈Aargmax?Qπ(s,a),有了更新后的策略,重復以上程序,直到收斂,這就是所謂的策略迭代演算法,通過不斷地迭代策略,來找到最優策略,容易證明,上述演算法是收斂的,
值迭代
另一個經典的迭代方法是值迭代方法,用 V ? V^* V?和 Q ? Q^* Q?來表示最優策略 π ? \pi^* π?下的狀態值函式和狀態-動作值函式,
容易想到的是,某一時刻某一狀態下,最優值函式必然是最優策略下的狀態-動作值函式關于動作的一個最大化,即:
V ? ( s ) = max ? a ∈ A Q ? ( s , a ) V^{*}(s)=\max _{a \in A} Q^{{*}}(s, a) V?(s)=a∈Amax?Q?(s,a)
這個是容易證明的,簡單地想,如果某個策略下的某一步的值函式不是最優的,那么一定可以改成狀態-動作值的最大化相對應的策略,使狀態值增大,
把這個寫開,就成了:
{ V T ? ( s ) = max ? a ∈ A ∑ s ′ ∈ S P ( s ′ ∣ s , a ) ( 1 T R ( s ′ ∣ s , a ) + T ? 1 T V T ? 1 ? ( s ′ ) ) V γ ? ( s ) = max ? a ∈ A ∑ s ′ ∈ S P ( s ′ ∣ s , a ) ( R ( s ′ ∣ s , a ) + γ V γ ? ( s ′ ) ) \left\{\begin{array}{l}{V_{T}^{*}(s)=\max _{a \in A} \sum_{s^{\prime} \in S} P(s^{\prime}|s,a)\left(\frac{1}{T} R(s'|s,a)+\frac{T-1}{T} V_{T-1}^{*}\left(s^{\prime}\right)\right)} \\ {V_{\gamma}^{*}(s)=\max _{a \in A} \sum_{s^{\prime} \in S} P(s^{\prime}|s,a)\left(R(s'|s,a)+\gamma V_{\gamma}^{*}\left(s^{\prime}\right)\right)}\end{array}\right. {VT??(s)=maxa∈A?∑s′∈S?P(s′∣s,a)(T1?R(s′∣s,a)+TT?1?VT?1??(s′))Vγ??(s)=maxa∈A?∑s′∈S?P(s′∣s,a)(R(s′∣s,a)+γVγ??(s′))?
上式是關于最優值函式的一個迭代公式,就被稱為是貝爾曼最優性方程,其對應的最優狀態-動作值函式為:
{ Q T ? ( s , a ) = ∑ s ′ ∈ S P ( s ′ ∣ s , a ) ( 1 T R ( s ′ ∣ s , a ) + T ? 1 T max ? a ′ ∈ A Q T ? 1 ? ( s ′ , a ′ ) ) Q γ ? ( s , a ) = ∑ s ′ ∈ S P ( s ′ ∣ s , a ) ( R ( s ′ ∣ s , a ) + γ max ? a ′ ∈ A Q γ ? ( s ′ , a ′ ) ) \left\{\begin{array}{l}{Q_{T}^{*}(s, a)=\sum_{s^{\prime} \in S} P(s^{\prime}|s,a)\left(\frac{1}{T} R(s'|s,a)+\frac{T-1}{T} \max _{a^{\prime} \in A} Q_{T-1}^{*}\left(s^{\prime}, a^{\prime}\right)\right)} \\ {Q_{\gamma}^{*}(s, a)=\sum_{s^{\prime} \in S} P(s^{\prime}|s,a)\left(R(s'|s,a)+\gamma \max _{a^{\prime} \in A} Q_{\gamma}^{*}\left(s^{\prime}, a^{\prime}\right)\right)}\end{array}\right. {QT??(s,a)=∑s′∈S?P(s′∣s,a)(T1?R(s′∣s,a)+TT?1?maxa′∈A?QT?1??(s′,a′))Qγ??(s,a)=∑s′∈S?P(s′∣s,a)(R(s′∣s,a)+γmaxa′∈A?Qγ??(s′,a′))?
由貝爾曼最優性方程,容易知道,我們不需要通過策略迭代,一次性就可以把最優策略 π ? \pi^* π?下的值函式統統求出來,由此,所謂的值迭代演算法,就不言而喻了,或通過迭代貝爾曼公式,或通過迭代最優動作價值函式進而關于動作求最大化,都能夠求得最優策略,不再細述,
Q學習、SARSA、時序差分學習
強化學習的演算法除了值迭代和策略迭代,比較經典的還有Q learning、Sarsa和TD(時序差分),最新的演算法還有SAC和TD3等,這些演算法的目標都是最大化值函式,都大同小異,可以簡單地理解成求動作值函式的各種不同的方法,若只想淺窺深度學習,而不做細致研究,不必再在乎這些演算法的推導以及收斂性證明,在合適的情形下直接拿來用就好了,
Q學習
Q學習演算法,需要了解Q表,Q-table 其實就是把狀態和動作一個作為行標,一個作為列標搞成表格,我們要求狀態-動作值函式( Q Q Q函式)其實也就是要想辦法求出最優動作下的Q表,
具體的演算法是先隨意初始化一個Q表,然后隨機地選擇狀態 s s s和動作 a a a,根據獎賞函式計算出獎賞 R R R,然后根據上述最優狀態-動作值函式的迭代公式,更新Q表,如此反復,直到Q表不再變化,
看簡單的例子鏈接或者鏈接,就很容易明白Q學習時怎么操作的了,
SARSA和時序差分學習
Sarsa是Q學習演算法的改進,Sarsa和Q以及TD本質上都是一脈同根的,
對于三者的一個差別和理解,可以看這個鏈接,
深度強化學習
所謂深度強化學習,只不過是用神經網路去表示出最優策略下的狀態-動作值函式 Q ? ( s , a ) Q^*(s,a) Q?(s,a),有了 Q ? ( s , a ) Q^*(s,a) Q?(s,a)的神經網路表示,下面的事情不就好辦了?
為什么要用深度學習呢?因為當狀態空間和動作空間很大的時候,甚至在連續的情況下,往往是連續的,用值迭代演算法,或者Q學習演算法,來計算 Q Q Q函式,計算量都太大,而我們知道,神經網路剛好就是來逼近一個復雜的高資料量的函式的,用它來表示 Q Q Q函式,豈不妙哉?基于這樣一個想法,才有了深度強化學習,
深度學習需要提供訓練資料,標簽怎么找?可以將下一步的 Q Q Q值作為標簽,直觀上理解就是, Q Q Q值變化不大了,往往達到了最優,
但是若使用相同的網路來生成下一個目標 Q Q Q值和估計當前 Q Q Q值,會導致振蕩性甚至發散,還有就是,深度學習要求樣本之間相互獨立且同分布,但強化學習樣本并不滿足這個條件,因此DQN中使用三個技巧來來解決這一系列問題:經驗回放,目標網路和自適應性學習率調整方法,所以,深度強化學習就有了一系列可學習和研究的東西,
這個鏈接和這個鏈接上有關于DQN的簡單介紹,看看也就明白了,
一些學習資料
有幾本理論比較清晰的書籍,見此GitHub,
如果對于機器學習沒有了解,可以看一下先修課程,
張志華老師的視頻教程1,提取碼aqyf ,視頻教程2,提取碼777p ,視頻教程3,提取碼rjgi,
另外,也可以在嗶哩嗶哩上搜索張志華老師的機器學習課程以及莫煩的python教程,
集成學習
bagging
Bagging的想法很簡單,就是在訓練集中均勻、有放回地抽取m個子集作為m個訓練集,分別使用分類回歸演算法,可以得到m個模型,再通過取平均值、取多數票等方法,得到Bagging的結果,
Bagging演算法可與其他分類、回歸演算法結合,提高其準確率、穩定性的同時,通過降低結果的方差,避免過擬合的發生,
程序如下:
- 從 N 樣本中有放回的采樣 N 個樣本,
- 對這 N 個樣本在全屬性上建立分類器 (CART、SVM),
- 重復上面的步驟,建立 m 個分類器,
- 預測的時候使用投票的方法得到結果,
隨機森林
在機器學習中,隨機森林是一個包含多個決策樹的分類器,并且其輸出的類別是由個別樹輸出的類別的眾數而定,這個方法結合了 bagging 想法和隨機子空間想法,建造決策樹的集合,誤差使用最后統計誤分得個數占總預測樣本的比率作為 RF 的 oob (out-of-bag)誤分率,每棵樹選部分的資料來訓練,剩下的作為驗證,子樹特征也不必選全部的,也是選部分的,回歸采用平均,分類采用投票,
每棵樹的按照如下規則生成:
- 如果訓練集大小為 N,對于每棵樹而言,隨機且有放回地從訓練集中的抽取 N 個訓練樣本(這種采樣方式稱為bootstrap sample方法),作為該樹的訓練集,從這里我們可以知道:每棵樹的訓練集都是不同的,而且里面包含重復的訓練樣本,
- 如果每個樣本的特征維度為 M,指定一個常數 m<<M(取 M \sqrt{M} M ??)隨機地從 M 個特征中選取 m 個特征子集,每次樹進行分裂時,從這 m 個特征中選擇最優的,
- 每棵樹都盡最大程度的生長,并且沒有剪枝程序,
隨機性的引入,使得隨機森林不容易陷入過擬合,并且具有很好得抗噪能力(比如:對預設值不敏感),
隨機森林分類效果(錯誤率)與兩個因素有關:
- 森林中任意兩棵樹的相關性:相關性越大,錯誤率越大,
- 森林中每棵樹的分類能力:每棵樹的分類能力越強,整個森林的錯誤率越低,
減小特征選擇個數 m,樹的相關性和分類能力也會相應的降低,增大m,兩者也會隨之增大,所以關鍵問題是如何選擇最優的 m,這也是隨機森林唯一的一個引數,
優缺點
- 能夠處理大量特征的分類,并且還不用做特征選擇
- 在訓練完成之后能給出哪些feature的比較重要
- 訓練速度很快
- 很容易并行
- 實作相對來說較為簡單,簡單,計算開銷小
boosting
“三個臭皮匠頂個諸葛亮”,弱分類器按準確率給予一定權重組合成一個強學習器,降低偏差,這就是 boosting 的基本思想,一個經典的提升演算法例子是 AdaBoost,
采用決策樹作為弱分類器的梯度提升演算法被稱為 GBDT,GBDT 的精髓在于訓練的時候都是以上一顆樹的殘差為目標,這個殘差就是上一個樹的預測值與真實值的差值,有點像多重網格的想法,由于用的是殘差,也就是累加,所以用于分類樹是沒有意義的,所以GBDT中的樹都是回歸樹,不是分類樹,
GBDT的優點和局限性
優點:
- 預測階段的計算速度快,樹與樹之間可以并行化計算,
- 在分布稠密的資料集上,泛化性能和表達能力都很好,
- 采用決策樹作為弱分類器使得 GBDT 模型具有較好的解釋性和魯棒性,能夠自動發現特征間的高階關系,并且也不需要對資料進行特殊的預處理如歸一化等,
局限性:
- 在高維稀疏的資料集上,表現不如支持向量機或者神經網路,
- 在處理文本分類特征問題上的優勢不如在數值上明顯,
- 訓練需要串行訓練,只能在決策樹區域采用一些區域并行的手段提高訓練速度,
Boosting 在訓練的時候會給樣本加一個權重,然后使 loss function 盡量去考慮那些分錯類的樣本(比如給分錯類的樣本的權重值加大),Boosting 的好處就是每一步的參加就是變相了增加了分錯 instance 的權重,而對已經對的 instance 趨向于 0,這樣后面的樹就可以更加關注錯分的 instance 的訓練了,相當于把搞錯的,拿出來重新搞,
Shrinkage 認為,每次走一小步逐步逼近的結果要比每次邁一大步逼近結果更加容易避免
過擬合,
優缺點:
優點:
- 精度高
- 能處理非線性資料
- 能處理多特征型別
- 適合低維稠密資料
缺點:
- 并行麻煩(因為上下兩顆樹有聯系)
- 多分類的時候復雜度很大
原始的 GBDT 演算法基于經驗損失函式的負梯度來構造新的決策樹,只是在決策樹構建完成后再進行剪枝,而 XGBoost 在決策樹構建階段就加入了正則,
其他方面
概率圖模型
概率圖模型是用圖論方法以表現數個獨立隨機變數之關系的一種建模法,其圖中的任一節點為隨機變數,若兩節點間無邊相接則意味此二變數彼此條件獨立,兩種常見的概率圖模型是具有向性邊的圖及具無向性邊的圖,
概率圖模型通過構造基于圖的表達來描述多維空間上的概率分布,圖的節點和邊描述了該分布不同變數之間具有的條件獨立性質的集合,根據圖的有向性,概率圖模型可以分成兩大類,分別是貝葉斯網路和馬爾可夫網路,這兩類網路均具有因子化和條件獨立的性質,但條件獨立的型別和將分布因子化的方式有所不同,概率圖模型在影像視頻分析中用途很廣,
貝葉斯網
一般而言,貝葉斯網路的有向無環圖中的節點表示隨機變數,連接兩個節點的箭頭代表此兩個隨機變數是具有因果關系或是非條件獨立的,而兩個節點間若沒有箭頭相互連接一起的情況就稱其隨機變數彼此間為條件獨立,若兩個節點間以一個單箭頭連接在一起,表示其中一個節點是“因(parents)”,另一個是“果(descendants or children)”,兩節點就會產生一個條件概率值,
舉例來說,貝葉斯網路可用來表示疾病和其相關癥狀間的概率關系,倘若已知某種癥狀下,貝葉斯網路就可用來計算各種可能罹患疾病之發生概率,
馬爾科夫隨機場
馬爾可夫隨機場似貝葉斯網路用于表示依賴關系,但是,一方面它可以表示貝葉斯網路無法表示的一些依賴關系,如回圈依賴,另一方面,它不能表示貝葉斯網路能夠表示的某些關系,如推導關系,
馬爾可夫隨機場要求一個變數在前一個變數的條件下,和前一個變數之前所有變數的聯合是條件獨立,也就是要滿足馬爾可夫性質,
推廣搜相關
協同過濾分為 User-based CF 和 Item-based CF ,本質上都是尋求一種低秩逼近,基本程序是:初始的矩陣缺失值一個猜測,得到 Z;對 Z 做 rank-r 奇異值分解,以此得到缺失值新的估計;重復這個程序,直到收斂,
概念解釋
準確率、精確率、召回率、F1值、ROC、AUC
我不知道為什么網上那么多人總喜歡用公式去表達這幾個東西,明明很簡單的東西,你給個公式,我還要首先理解一下你公式里面每個字符表示的意思,這不是浪費時間么,
準確率(accuracy)就是我們通常意義下的分類分對的比率,這個有問題啊,比如說 100 個人里面,有 1 個壞蛋,那么我一股腦全當成好人,那還有 0.99 的準確率,
精確率(precision)是對結果而言的,就是你分的所有正樣本里面,分對的樣本占的百分比,
所謂的召回召回,就是在實際的正樣本里面,你判斷對的百分比有多少,也就是你召回來的正樣本有多少,
F1 值就是精確率和召回率在某種意義下的平均, F 1 = 2 ? p r e c i s i o n ? r e c a l l p r e c i s i o n + r e c a l l F1 = \frac{2*precision*recall }{precision + recall} F1=precision+recall2?precision?recall?,
召回率是個新奇的東西,我們拿過來,我們再想,召回率是正樣本中判定為 1 的比率,我們關注這個判定為 1 的事情,負樣本中判定為 1 的我們叫 FRR,以 FPR 為橫坐標,以召回率這個有趣的東西為縱坐標,畫出來的曲線就叫 ROC 曲線,AUC(area under curve) 就是 ROC 的面積,AUC 越大越好,ROC 越拱越好, ROC 和 AUC 通常是用來評價一個二值分類器的好壞,
ROC 曲線,x 軸為假陽率,y 軸為真陽率(召回率),針對落在 y=x 上點,表示是采用隨機猜測出來的結果,ROC 曲線建立:一般默認預測完成之后會有一個概率輸出 p,這個概率越高,表示它對positive 的概率越大,現在假設我們有一個 threshold,如果 p>threshold,那么該預測結果為positive,否則為negitive,多設定幾個 threshold,那么我們就可以得到多組真陽率和假陽率的值,就可以 plot 影像了,
AUC:AUC(Area Under Curve) 被定義為 ROC 曲線下的面積,顯然這個面積不會大于1(一般情況下ROC 會在 y=x 的上方,所以0.5<AUC<1),
當測驗集中的正負樣本發生變化時,ROC 曲線能基本保持不變,但是 precision 和 recall 可能就會有較大的波動,所以,這是一個衡量效果的一個不錯的標準,
詞袋模型
詞袋模型是 NLP 里面的一個概念,顧名思義就是把單詞丟進一個袋子里面,給你一句話,你可以數詞袋里面每個單詞出現的次數,就得到了一個詞頻向量,
TF-IDF
TF-IDF 是衡量一個字詞在一個檔案中的重要性的,字詞的重要性隨著它在檔案中出現的次數成正比增加,但同時會隨著它在語料庫中出現的頻率成反比下降,一個詞語在一篇文章中出現次數越多, 同時在所有檔案中出現次數越少, 越能夠代表該文章,
通過上面的敘述,一個簡單的想法就是用詞在文章里面的比率除以詞在語料庫里面的占比,來衡量它在這篇文章中的重要性,但是語料庫太大了,一個一個數不現實,不妨用有這個詞的檔案在語料庫里面的占比作為除數,把除變成乘,在取個 log 就有:
TFIDF ( w ) = 在某一文章中詞條 w 出現的次數 該文章中所有的詞條數目 ? log ? ( 語料庫的檔案總數 包含詞條 w 的檔案數 + 1 ) \text{TFIDF}(w) =\frac{\text { 在某一文章中詞條 } w \text { 出現的次數 }}{\text { 該文章中所有的詞條數目 }}*\log \left(\frac{\text { 語料庫的檔案總數 }}{\text { 包含詞條 } w \text { 的檔案數 }+1}\right) TFIDF(w)= 該文章中所有的詞條數目 在某一文章中詞條 w 出現的次數 ??log( 包含詞條 w 的檔案數 +1 語料庫的檔案總數 ?)
分母之所以要加1,是為了避免分母為 0,
泛化
泛化能力是指模型對未知資料的預測能力,
過擬合
所謂的過擬合就是說訓練得太好了,以至于在測驗集上效果不好,過擬合發生在測驗誤差和訓練誤差相差太大的情況下,如果一味的去提高訓練資料的預測能力,所選模型的復雜度往往會很高,這種現象稱為過擬合,特征越多,模型越復雜,越容易過擬合,
產生的原因:
- 因為引數太多,會導致我們的模型復雜度上升,容易過擬合,(模型太復雜)
- 權值學習迭代次數足夠多,擬合了訓練資料中的噪聲和訓練樣例中沒有代表性的特征,(學太久)
解決方法
- L1、L2正則化
- 減少特征
- 權值衰減
- dropout
- 資料集擴增
- 早點停止訓練
- 交叉驗證法(訓練集和測驗集交換)
生成模型和判別模型
- 生成模型:由資料學習聯合概率分布 P(X,Y),然后求出條件概率分布 P(Y|X) 作為預測的模型(樸素貝葉斯),生成模型可以還原聯合概率分布 P(X,Y),并且有較快的學習收斂速度,還可以用于隱變數的學習,如隱馬爾可夫模型 HMM,
- 判別模型:由資料直接學習決策函式條件概率分布 P(Y|X) 作為預測的模型,即判別模型,直接面對預測,往往準確率較高,
判別式模型舉例:要確定一個羊是山羊還是綿羊,用判別模型的方法是從歷史資料中學習到模型,然后通過提取這只羊的特征來預測出這只羊是山羊的概率,是綿羊的概率,
生成式模型舉例:利用生成模型是根據山羊的特征首先學習出一個山羊的模型,然后根據綿羊的特征學習出一個綿羊的模型,然后從這只羊中提取特征,放到山羊模型中看概率是多少,在放到綿羊模型中看概率是多少,哪個大就是哪個,
線性分類器和非線性分類器
如果模型是引數的線性函式,并且存在線性分類面,那么就是線性分類器,否則不是,
常見的線性分類器有:LR、貝葉斯分類、單層感知機、線性回歸,常見的非線性分類器:決策樹、RF、GBDT、多層感知機,SVM 兩種都有(看線性核還是高斯核),
線性分類器速度快、編程方便,但是可能擬合效果不會很好,非線性分類器編程復雜,但是效果擬合能力強,
特征多,資料系數,往往更容易線性可分,我們選擇線性分類器,否則,我們選擇非線性分類器,
L1 和 L2 正則化
他們都是可以防止過擬合,降低模型復雜度,
- L1 是在 loss function 后面加上模型引數的 1 范數,
- L2是在 loss function 后面加上模型引數的 2 范數,
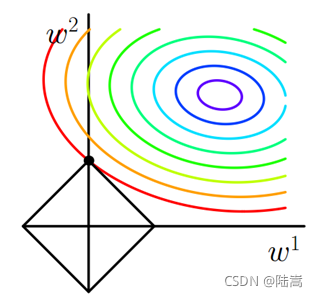
- L1 會產生稀疏的特征,L2 會產生更多地特征但是都會接近于 0,
- L1 會趨向于產生少量的特征,而其他的特征都是 0,而 L2 會選擇更多的特征,這些特征都會接近于 0,
- L1 在特征選擇時候非常有用,而 L2 就只是一種規則化而已,
歸一化方法
為了消除資料特征之間的量綱影響,我們需要對特征進行歸一化處理,使得不同指標之間具有可比性,
- scaling 到一個區間
- 減去均值,除以方差
- 函式轉化,如: y = log ? 10 ( x ) y=\log_{10} (x) y=log10?(x), y = arctan ? x π / 2 y = \frac{\arctan x}{\pi/2} y=π/2arctanx?
- softmax:取 e x i e^{x_i} exi?后,再求占比,
交叉驗證
N 折交叉驗證有兩個用途:模型評估和模型選擇,把這種策略用于劃分訓練集和測驗集,就可以進行模型評估,把這種策略用于劃分訓練集和驗證集,就可以進行模型選擇,
交叉驗證的核心思想:對資料集進行多次劃分,對多次評估的結果取平均,從而消除單次劃分時資料劃分得不平衡而造成的不良影響,因為這種不良影響在小規模資料集上更容易出現,所以交叉驗證方法在小規模資料集上更能體現出優勢,
這種過擬合可能不是模型導致的,而是因為資料集劃分不合理造成的,這種情況在用小規模資料集訓練模型時很容易出現,所以在小規模資料集上用交叉驗證的方法評估模型更有優勢,
交叉驗證與正則化不同:交叉驗證通過尋找最佳模型的方式來解決過擬合,而正則化則是通過約束引數的范數來解決過擬合,
Bias(偏差)、Error(誤差)、Variance(方差)
誤差=偏差+方差,Bias 是用所有可能的訓練資料集訓練出的所有模型的輸出的平均值與真實模型的輸出值之間的差異,Variance 是不同的訓練資料集訓練出的模型輸出值之間的差異,Bias 和 Variance 是不可兼得的,過擬合的情況是 Bias 很小,但是方差很大,訓練集上搞好了,可以追求 Bias 很小,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/335393.html
標籤:AI