目錄
1. 概要
2. 資料格式轉換
2.1 LIBSVM的資料格式
2.2 資料格式轉換
3. Step-by-step
4. Grid Search
5. Auto full-flow
6. 基于sklearn SVC的實驗
1. 概要
本文介紹以UCI-SPECTF資料實驗物件,基于LIBSVM的分類實驗,以及相應的資料轉換,最后還給出了直接使用SKLEARN的的實驗代碼及結果對比,
2. 資料格式轉換
Reference: https://blog.csdn.net/cclaree/article/details/103392803
2.1 LIBSVM的資料格式
libSVM的資料格式為:
Label index1:value1 index2:value2 index3:value3 ….
Label index1:value1 index2:value2 index3:value3 ….
Label:是類別的標識,可以自己隨意定,比如1,-1,再比如-10,0,15,當然,如果是回歸,這是目標值,就要實事求是了,
index :是有順序的索引,通常是連續的整數,就是指特征編號,必須按照升序排列,
Value:就是要訓練的資料,從分類的角度來說就是特征值,資料之間用空格隔開,比如:
-15 1:0.708 2:1056 3:-0.3333需要注意的是,如果特征值為0,該項特征可以跳過,因此index看上去就不連續(資料處理程式看到有index被跳過就知道這是特征值為0的項),如:
-15 1:0.708 3:-0.3333中間跳過了index=2的項,表明第2個特征值為0,
2.2 資料格式轉換
查閱了一下網上資源,八仙過海各顯神通,有多種辦法,最終覺得[2]看上去比較對眼,其中提供了一個將matlab陣列轉換為LIBSVM所接受的格式的matlab函式,為了方便各位讀者,轉錄如下(親測OK各位放心使用):
% https://blog.csdn.net/cclaree/article/details/103392803
% Matlab function.
function libsvmtransform(A,filename)
[m,n]=size(A);
txt='.txt';
file=[filename,txt];
fid = fopen(file,'w');%寫入檔案路徑
for i=1:m
temp1 = A(i,2:n);%存盤A中每一行從第2位開始的值
temp2 = [];
for j = 1:length(temp1)
if temp1(j) ~= 0
temp2 = [temp2 ' ' num2str(j) ':' num2str(temp1(j))];
else
temp2 = [temp2];
end
end % temp2存放A一行添加序號的結果
temp3 = [num2str(A(i,1)) temp2];%temp3存放最終一行的結果
[m1,n1] = size(temp3);
for k = 1:n1
if k == n1
fprintf(fid,'%c\n',temp3(k));
else
fprintf(fid,'%c',temp3(k));
end
end
end
fclose(fid);
基于以上轉換函式,我寫了matlab腳本進行資料轉換,先讀入資料(原始資料相當于是csv格式) ,得到matlab陣列,然后再呼叫以上函式生成LIBSVM所需要的格式檔案,
% Matlab/Octave scipt
% chenxy 2021-10-24
close all; clear; clc
SPECTF = csvread('SPECTF.train'); % read a csv file
libsvmtransform(SPECTF,'SPECTF_train');
open('SPECTF_train.txt')
SPECTF = csvread('SPECTF.test'); % read a csv file
libsvmtransform(SPECTF,'SPECTF_test');
open('SPECTF_test.txt')這樣得到了LIBSVM資料檔案SPECTF_train.txt和SPECTF_test.txt,可以開始干活了,
3. Step-by-step
首先還是step-by-step地做(畢竟現在還不是很熟練),多麻煩一點兒沒有壞處,
第一步,scaling后訓練
>> svm-scale -l -1 -u 1 -s SPECTF_range SPECTF_train.txt > SPECTF_train.scale
>> svm-scale -r SPECTF_range SPECTF_test.txt > SPECTF_test.scale
>> svm-train SPECTF_train.scale
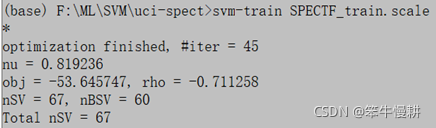
第2步, 對訓練集和測驗集做預測
>> svm-predict SPECTF_train.scale SPECTF_train.scale.model SPECTF_train.predict
>> svm-predict SPECTF_test.scale SPECTF_train.scale.model SPECTF_test.predict

![]()
訓練集和測驗集的分類準確度都不是很高,
4. Grid Search
>>python ..\libsvm-master\tools\grid.py SPECTF_train.scale輸出:0.5, 0.125, 78.75
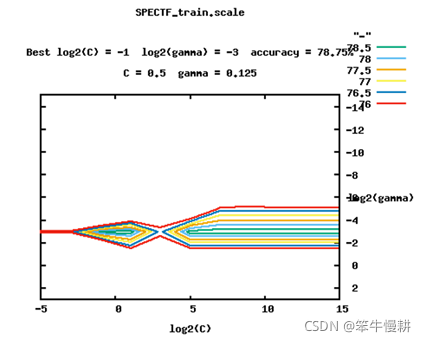
基于以上搜索的引數(C=0.5, gamma=0.125)重新進行訓練和分類評估:
>>svm-train -c 0.5 -g 0.125 SPECTF_train.scale
>>svm-predict SPECTF_train.scale SPECTF_train.scale.model SPECTF_train.predict
>>svm-predict SPECTF_test.scale SPECTF_train.scale.model SPECTF_test.predict
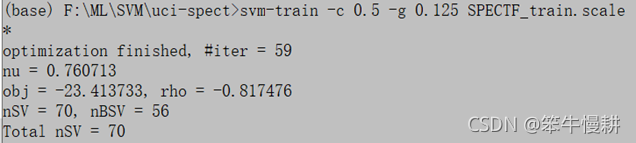

比上一節的結果略有提高,
這是這個資料集用SVM所能取得的性能極限呢?還是因為以上做法有問題呢?
5. Auto full-flow
作為一個既定的實驗流程,也重新做一次全自動的流程:
>>python easy.py SPECTF.train SPECTF.test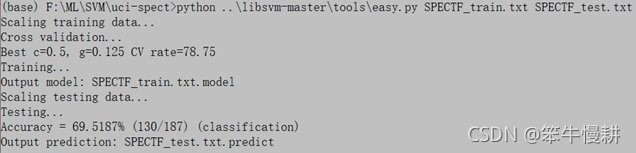
結果與上面的半手動流程相同,毫不意外,
6. 基于sklearn SVC的實驗
為了做個對比,直接呼叫sklearn SVC進行分類實驗并于以上分類結果進行對比,并且都直接使用預設引數,
注意,UCI-SPECTF的原始資料格式是符合SKLEARN要求的,不需要進行變換,因此在這個實驗中直接用UCI-SPECTF的原始資料,代碼如下:
# -*- coding: utf-8 -*-
"""
Created on Wed Sep 29 12:50:49 2021
@author: chenxy
Experiment on UCI-SPECTF using sklearn SVC
"""
print(__doc__)
import numpy as np
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
# X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
# y = np.array([1, 1, 2, 2])
train_data = np.loadtxt('SPECTF.train', delimiter=',')
X = train_data[:,1:]
y = train_data[:,0]
clf = make_pipeline(StandardScaler(), SVC(gamma='auto'))
clf.fit(X, y)
print('SPECTF train data accuracy = ',clf.score(X, y))
test_data = np.loadtxt('SPECTF.test', delimiter=',')
X_test = test_data[:,1:]
y_test = test_data[:,0]
print('SPECTF test data accuracy = ',clf.score(X_test, y_test))輸出結果:
SPECTF train data accuracy = 0.95
SPECTF test data accuracy = 0.7433155080213903
這是個典型的欠擬合的癥狀,
另外,作為參考:
An accuracy comparison between scikit-learn’s SVM and LightTwinSVM program – The Blog of Amir Mir (mirblog.net) 報告的基于Scikit-learn's SVM 的UCI-SPECTF的結果為79.78%,
這說明以上不管是直接基于libSVM的訓練還是基于sklearn-SVC的訓練都還有不足之處,有待進一步研究(終于要進入煉丹的領域了,,,^-^),
關于LIBSVM的安裝(Windows)以及初始實驗參見:
LIBSVM安裝和使用實驗(Windows 10)https://blog.csdn.net/chenxy_bwave/article/details/120923321![]() https://blog.csdn.net/chenxy_bwave/article/details/120923321
https://blog.csdn.net/chenxy_bwave/article/details/120923321
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/335395.html
標籤:AI
上一篇:機器學習基礎知識點
下一篇:[人工智能-深度學習-36]:卷積神經網路CNN - 簡單地網路層數堆疊導致的問題分析(梯度消失、梯度彌散、梯度爆炸)與解決之道