作者主頁(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文網址:https://blog.csdn.net/HiWangWenBing/article/details/120919308
目錄
第1章 簡單堆疊神經元導致引數量劇增的問題
1.1 網路層數增加大帶來的好處
1.2 一個奇怪的現象
1.3 網路層數增加帶來的負面效果
第2章 引數量劇增導致的訓練問題
2.1 計算量的增加
2.2 模型容易過擬合,泛化能力變差,
2.3 梯度例外
2.4 loss例外
第3章 梯度消失:引數的變化率接近與
3.1 什么是梯度消失和梯度彌散
3.2 梯度的由來:反向傳播的梯度下降來優化神經網路引數
3.3 采取反向傳播的原因:
3.4 梯度消失會帶來哪些影響
3.5 梯度消失的原因
3.5 梯度消失的解決思路
3.6 梯度消失的幾個解決辦法
第4章 梯度爆炸:梯度接近于無窮
4.1 什么事梯度爆炸
4.2 梯度爆炸的原因
4.3 梯度爆炸的解決方法
第5章 網路退回現象
5.1 什么事網路回退線性
5.2 管理層級與專有化、精細化分工
5.3 神經網路退回現象背后的原理
5.4 神經網路退回現象的解決辦法
第1章 簡單堆疊神經元導致引數量劇增的問題
1.1 網路層數增加大帶來的好處
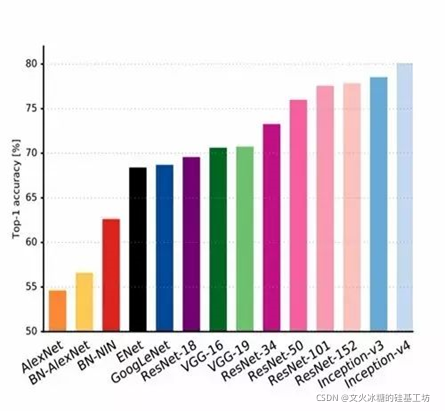
1.2 一個奇怪的現象
從LeNet網路到Inception-V4,其性能不斷的提升, 網路的層數不斷雜在增加,當網路增加到20層左右時研究人員發現:隨著網路層數的增加,性能反而是下降的,如下圖所示:
隨著網路層數的增加,網路總體性能在下降!!!
1.3 網路層數增加帶來的負面效果
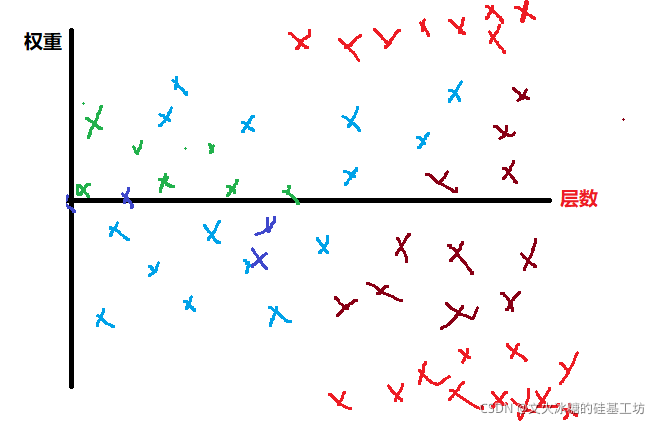
隨著網路層數的增加,出現幾個數學現象:
(1)權重參與的數量巨量增加
(2)不同層的引數的分布特征不同,
(3)不同層的引數的變化率不同,
(4)不同層的引數對結果的影響不同,然后梯度迭代時的效果是相同,
第2章 引數量劇增導致的訓練問題
訓練的程序就是梯度逐漸迭代的程序,反向傳播的梯度計算是每一次的梯度計算要依賴于后一級的梯度,隨著網路層數的增加,上述引數的變化,會導致深度學習、訓練出現一些新的問題:
2.1 計算量的增加
(1)問題
權重參與的數量巨量增加,導致計算量的大幅度增加,
(2)接近辦法
針對這個問題,可以通過GPU集群來解決,對于一個企頁澩并不是很大的問題;
2.2 模型容易過擬合,泛化能力變差,
(1)問題
引數越多,擬合樣本的能力越強,但樣本本身也是誤差的,且樣本本身的表現形態也是多樣的,
過渡的擬合,導致擬合出來的網路,過于注重樣本的形態,而忽略了樣本內在的特征和規律,
這就是過擬合,過擬合的結果就是模型泛化能力變差,無法發現模型內部的本質特征 ,
(2)解決辦法
可以通過采集海量資料,并配合Dropout正則化等方法也可以有效避免;
2.3 梯度例外
(1)梯度消失或梯度彌散:梯度接近于0
(2)梯度爆炸:梯度接近于無窮
2.4 loss例外
(1)網路回退:當增加網路深度,訓練集loss反而會增大的現象,
第3章 梯度消失:引數的變化率接近與
3.1 什么是梯度消失和梯度彌散
簡單的講,就是某些網路層的梯度在沒有擬合完成前,就已經降低解決于0,導致網路無法學習,
即在梯度的反向傳播程序中,經過多層的梯度相乘,導致靠近輸入神經元會比靠近輸出的神經元的梯度成指數級衰減,甚至接近于0.
靠近輸出層的hidden layer 梯度大,引數更新快,所以很快就會收斂;
而靠近輸入層的hidden layer 梯度小,權重引數更新慢,幾乎就和初始狀態一樣,隨機分布(初始化成隨機分布),這種現象就是梯度彌散(vanishing gradient problem),
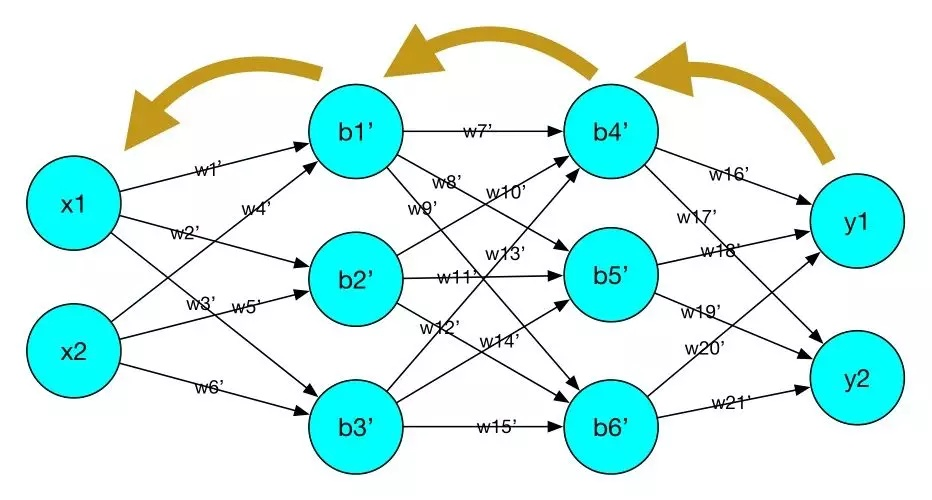
3.2 梯度的由來:反向傳播的梯度下降來優化神經網路引數
反向傳播的梯度下降來優化神經網路引數:
根據損失函式計算的誤差,通過反向傳播的方式,指導深度網路引數的更新優化,
3.3 采取反向傳播的原因:
深層網路由許多線性層和非線性層堆疊而來,每一層非線性層都可以視為是一個非線性函式f(x)(非線性來自于非線性激活函式),因此整個深度網路可以視為是一個復合的非線性多元函式,
我們最終的目的是希望這個非線性函式很好的完成輸入到輸出之間的映射,也就是找到讓損失函式取得極小值,
所以最終的問題就變成了一個尋找函式最小值的問題,在數學上,很自然的就會想到使用梯度下降來解決,
3.4 梯度消失會帶來哪些影響
舉個例子,對于一個含有三層隱藏層的簡單神經網路來說,當梯度消失發生時:
接近于輸出層的隱藏層,由于其梯度相對正常,所以權值更新時也就相對正常,
接近于輸入層的隱藏層,由于梯度消失現象,會導致靠近輸入層的隱藏層權值更新緩慢或者更新停滯,
這就導致在訓練時,只等價于后面幾層的淺層網路的學習,
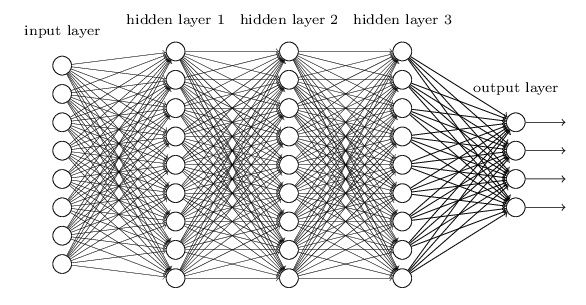
3.5 梯度消失的原因
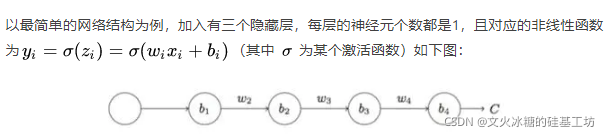

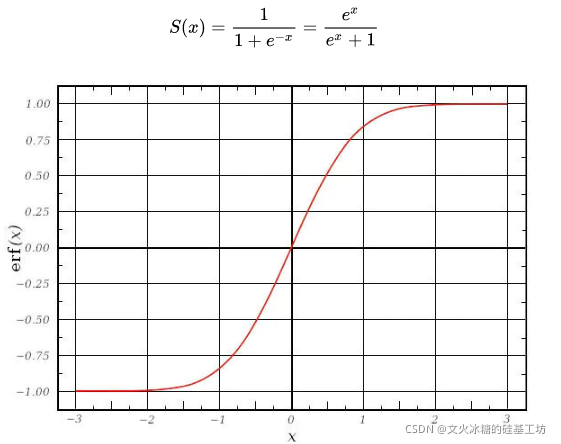
sigmod函式,導致神經元的被輸出被限制在0和1區間,
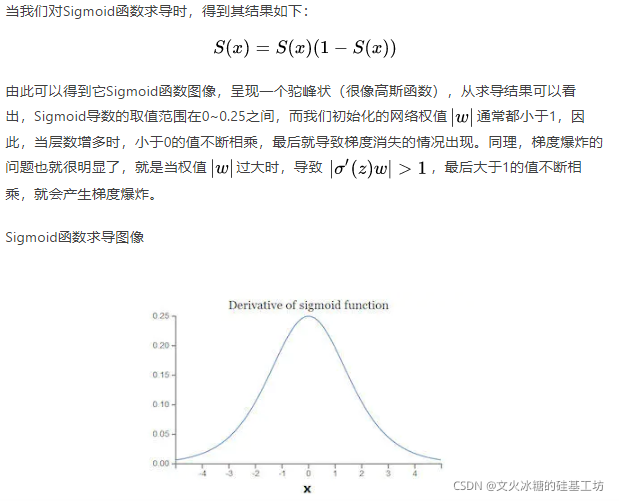
因此這種現象的根本原因,一方面來自于激活函式,另一個根本原因在于“鏈式求導”,這是深度學習的根基!!!
3.5 梯度消失的解決思路
- 重構深度學習的基石:鏈式求導,這有一定的難度,
- 降低網路的層數
- 優化網路的架構,避免梯度消失或梯度爆炸
- 優化激活函式
3.6 梯度消失的幾個解決辦法
梯度消失和梯度爆炸本質上是一樣的,一個根本的因為是:
網路層數太深而引發的梯度反向傳播中的連乘效應,
解決梯度消失、爆炸主要有以下幾種方案案例:
(1)換用Relu、LeakyRelu、Elu等激活函式
ReLu:讓激活函式的導數很定為1,不會出現梯度消失或梯度爆炸,
LeakyReLu:包含了ReLu的幾乎所有優點,同時解決了ReLu中0區間帶來的影響
ELU:和LeakyReLu一樣,都是為了解決0區間問題,相對于來,elu計算更耗時一些(為什么)
(2)BN: BatchNormalization(歸一化)
歸一化,有類類似每個神經元對輸出與的限制與放大,
通過歸一化,確保每個神經元輸出,都被重選放大或縮小,以規范的方式輸出,
BN本質上是解決傳播程序中的梯度消失或爆炸問題,
(3)逐層訓練 + 整體finetunning
此方法來自Hinton在06年發表的論文上,其基本思想是:
每次訓練一層隱藏層節點,將上一層隱藏層的輸出作為輸入,而本層的輸出作為下一層的輸入,這就是逐層預訓練,
訓練完成后,再對整個網路進行“微調(fine-tunning)”,
此方法相當于是找區域最優,然后整合起來尋找全域最優;
但是現在基本都是直接拿imagenet的預訓練模型直接進行finetunning,
(4)改變網路結構
如殘差ReNet網路結構、LSTM網路結構,后續單獨討論這些網路架構,
第4章 梯度爆炸:梯度接近于無窮
4.1 什么事梯度爆炸
梯度爆炸與梯度消失正好相反,是隨著網路層數的增加,接近輸入端的網路的梯度,經過多次相乘后,梯度得到了無線的放大,
4.2 梯度爆炸的原因
梯度爆炸的原因與梯度消失基本相同,
梯度的衰減是有連續乘法導致的,如果在連續乘法中出現連續的多個非常大的值,最后計算出的梯度就會很大,
相當于優化程序中,遇到斷崖處時,會獲得一個很大的梯度值,如果按照這個梯度值進行更新,那么這次迭代的步長就很大,可能會一下子飛出了合理的區域,
4.3 梯度爆炸的解決方法
與梯度消失相似,除此之外,梯度爆炸還有自身獨特的解決辦法:
(1)閾值法
其思想是設值一個剪切閾值,如果更新梯度時,梯度超過了這個閾值,那么就將其強制限制在這個范圍之內,這樣可以防止梯度爆炸,
第5章 網路退回現象
5.1 什么事網路回退線性
針對梯度彌散或爆炸,似乎可以通過Batch Normalization(歸一化)的方法可以避免,
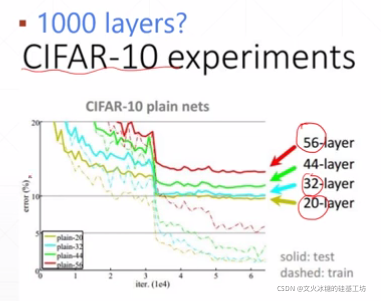
解決了梯度梯度消失和梯度爆炸后,貌似我們就可以無腦的增加網路的層數來獲得更好的網路性能:準確率和泛化能力,但實驗資料給了我們當頭一棒,
隨著網路層數的增加,發生了一個神奇的退化(degradation)的現象:
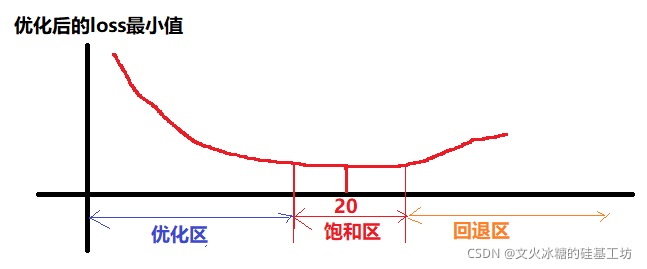
(1)優化區
一開始,當網路層數從0逐漸增多時,訓練集的loss值,在訓練學習后的值會逐漸下降,
(2)飽和區
當網路層數得到20層附近時,再通過增加網路層數,loss的減少就不明顯了,甚至loss的減少接近于0,這個區稱為loss的飽和區,
(3)回退區
當網路層數再增大時,loss不但不減少,反而會增大,這就稱為“網路回退現象”,回退到較低網路層次的水平,
注意:這并不是過擬合,因為在過擬合中訓練loss是一直減小的,甚至loss為0.
當網路退化時,深層網路只能達到淺層網路的水平,這樣,通過增加網路層的深度的意義就不大了,反而是負面的了,因為增加網路的深度,會導致引數的增加、計算機的增加、網路傳輸的延時等,并沒有帶來錯誤率的下降和準確率的提升 ,
5.2 管理層級與專有化、精細化分工
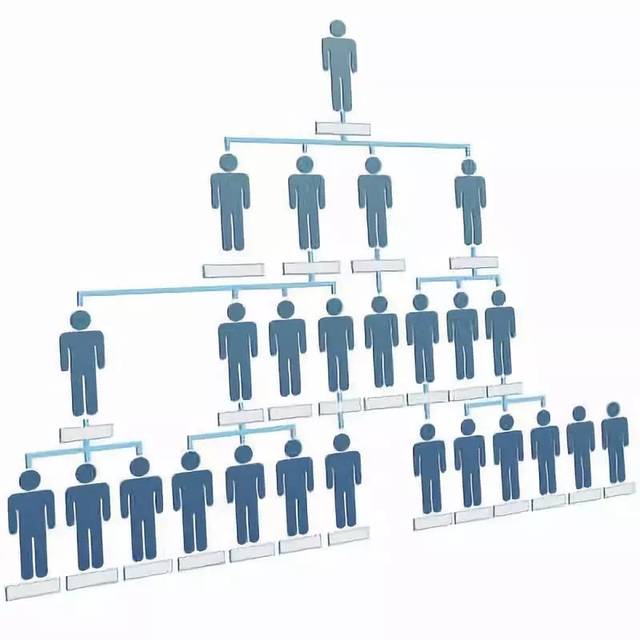
隨著公司、國家規模的增長,管理層級也越來越大,區分的種類也越來越多,但并非層級越多越好,管理層級與公司的規模有一定的關系,當管理的層級超過一定的門限后,管理的效能是整體效能是下降的,神經網路也是一樣,
5.3 神經網路退回現象背后的原理
從資訊論的角度講,由于DPI(資料處理不等式)的存在,在前向傳輸的程序中,隨著層數的加深,抽象程度也在提升,共性在提升,個性在降低,共性的資訊量是低的,共性程度越高的,資訊量是越少的,個性程度越多的,描述個性的資訊是越多的,也就說隨著網路層數的增加,也就是Feature Map包含的資訊量會逐層減少,因此,就不需要通過更多的神經元引數加以區分,
5.4 神經網路退回現象的解決辦法
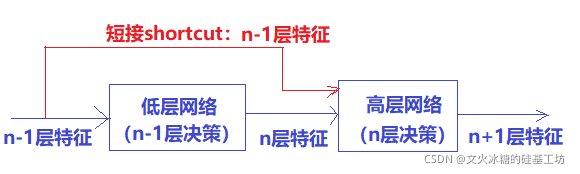
淺層網路具備更多的特征資訊,如果我們把淺層(低層管理層)的特征傳到高層(管理層),讓高層根據這些資訊進行決策(分類和特征提取),那么高層最后的效果應該至少不比淺層的網路效果差,最壞的情況是與低層更好的效果,更普遍的情況是,高層由于有更多、更抽象的特征資訊,因此高層的決策效果會比低層更準確,
更抽象的講,我們需要一種技術,確保保證了L+1層的網路一定比 L層包含更多的影像資訊,
這就是ResNet shortcut網路結構的底層邏輯和內在思想!!!,
作者主頁(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文網址:https://blog.csdn.net/HiWangWenBing/article/details/120919308
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/335396.html
標籤:AI