總體思路:
由于我在查詢同義詞的時候,發現很多專業詞語都可能不在這個詞向量訓練模型里面,于是我想到了可以寫成,輸入一個詞,查詢這個庫中有沒有詞表示,如果沒有就把它分詞后查詢,
先匯入庫
import jieba
import gensim
import numpy as np再匯入已經訓練好的詞向量模型(我這里設定limit為1000000,總共有600多萬個詞)
百科模型下載
word_vectors=gensim.models.KeyedVectors.load_word2vec_format('D:\\BAIKE/baike_26g_news_13g_novel_229g.bin', binary=True,limit=1000000)輸入查詢同義詞
if word in word_vectors:
print(word_vectors.most_similar(positive = [word], topn = 5))比如查詢”人口學”這個詞語得到結果如下

但是查詢一些專有名詞,如果不在詞向量里面會報錯
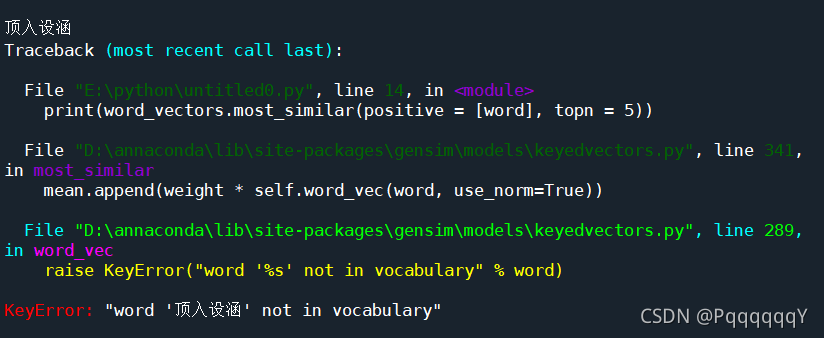
于是將其分詞以后查詢
else:
wordcut = jieba.lcut(word)
print("第一次分詞結果")
print(wordcut)
for i in wordcut:
if i in word_vectors:
print(i)
print(word_vectors.most_similar(positive = [i], topn = 5))
else:
c=[one for one in i]
print("第二次分為一個一個字")
print(c)
for j in c:
print(j)
print(word_vectors.most_similar(positive = [j], topn = 5))得到結果如下:(我使用兩次分詞,第一次jieba分詞,第二次直接分成一個一個字)

完整代碼如下(可能還有字不在詞向量里面,還需改進):
import jieba
import gensim
import numpy as np
word=input()
word_vectors=gensim.models.KeyedVectors.load_word2vec_format('D:\\BAIKE/baike_26g_news_13g_novel_229g.bin', binary=True,limit=1000000)
if word in word_vectors:
print(word_vectors.most_similar(positive = [word], topn = 5))
else:
wordcut = jieba.lcut(word)
print("第一次分詞結果")
print(wordcut)
for i in wordcut:
if i in word_vectors:
print(i)
print(word_vectors.most_similar(positive = [i], topn = 5))
else:
c=[one for one in i]
print("第二次分為一個一個字")
print(c)
for j in c:
print(j)
print(word_vectors.most_similar(positive = [j], topn = 5))轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/335397.html
標籤:AI
上一篇:[人工智能-深度學習-36]:卷積神經網路CNN - 簡單地網路層數堆疊導致的問題分析(梯度消失、梯度彌散、梯度爆炸)與解決之道