一、前言
前面兩篇文章我已經把requests基礎與高階篇都做了詳細講解,也有不少了例子,那么本篇在基于前兩篇文章之上,專門做一篇實戰篇,
環境:jupyter
如果你不會使用jupyter請看我這一篇文章:jupyter安裝教程與使用教程
二、實戰
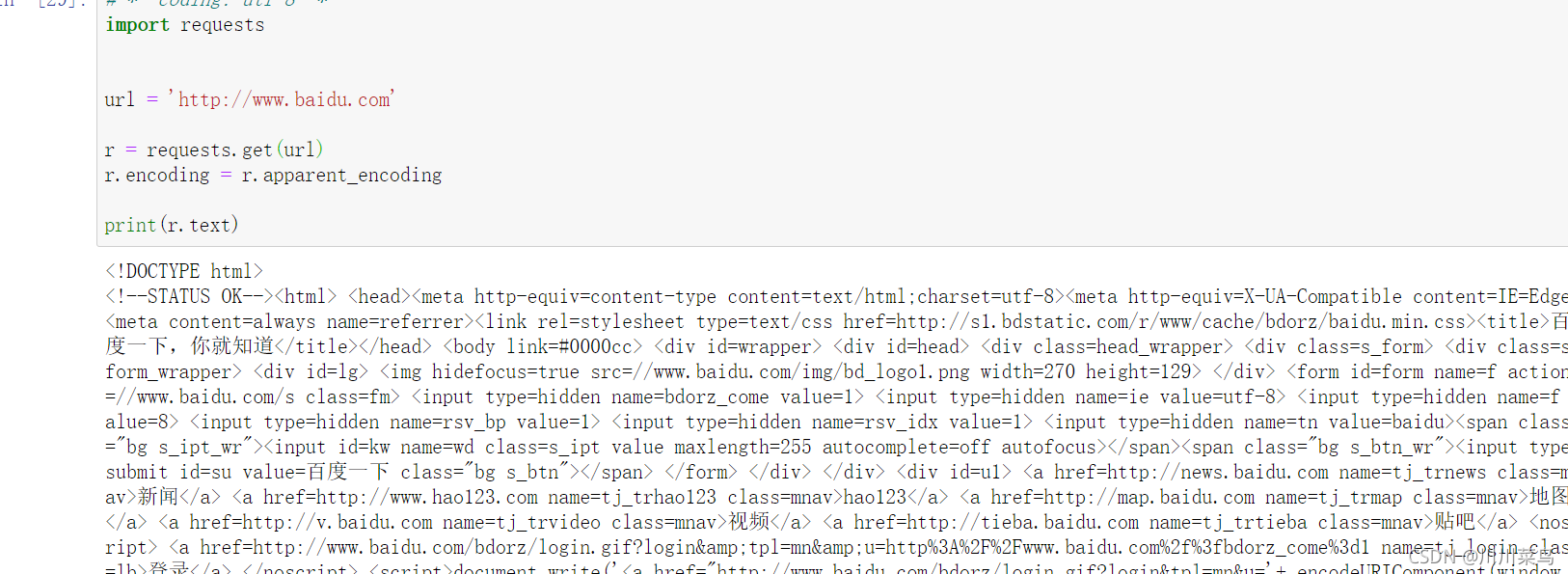
1)獲取百度網頁并列印
#-*- coding: utf-8 -*
import requests
url = 'http://www.baidu.com'
r = requests.get(url)
r.encoding = r.apparent_encoding
print(r.text)
運行:
2)獲取帥哥圖片并下載到本地

比如我們得到鏈接:張杰圖片鏈接
我現在想把這張圖片下載下來:
import requests
src = 'https://cn.bing.com/images/search?view=detailV2&ccid=XQzISsWk&id=979B73C4E472CCA4C34C216CD0693FDC05421E1E&thid=OIP.XQzISsWklI6N2WY4wwyZSwHaHa&mediaurl=https%3A%2F%2Ftse1-mm.cn.bing.net%2Fth%2Fid%2FR-C.5d0cc84ac5a4948e8dd96638c30c994b%3Frik%3DHh5CBdw%252fadBsIQ%26riu%3Dhttp%253a%252f%252fp2.music.126.net%252fPFVNR3tU9DCiIY71NdUDcQ%253d%253d%252f109951165334518246.jpg%26ehk%3Do08VEDcuKybQIPsOGrNpQ2glID%252fIiEV7cw%252bFo%252fzopiM%253d%26risl%3D1%26pid%3DImgRaw%26r%3D0&exph=1410&expw=1410&q=%e5%bc%a0%e6%9d%b0&simid=608020541519853506&form=IRPRST&ck=68F7B9052016D84898D3E330A6F4BC38&selectedindex=2&ajaxhist=0&ajaxserp=0&vt=0&sim=11'
r = requests.get(src)
with open('bizhi.jpg', 'wb') as f:
f.write(r.content)
print('下載完成')
運行:
4) 獲取美女視頻并下載到本地
比如我得到一個視頻鏈接為:jk美女搖擺搖擺
代碼:
import requests
src = 'https://apd-36ae3724d7c0b6835e09d09afc998cfa.v.smtcdns.com/om.tc.qq.com/Amu-xLH92Fdz3C-7PsjutQi_lMKUzCnkiicBjZ69cAqk/uwMROfz2r55oIaQXGdGnC2dePkfe0TtOFg8QaGVhJ2MPCPEj/svp_50001/szg_9711_50001_0bf26aabmaaaqyaarhnfdnqfd4gdc3yaafsa.f632.mp4?sdtfrom=v1010&guid=442bebcff8ab31b452c4a64140cd7f3a&vkey=762D67379522C89E3A76A0759F02B2905311E3FE385B3EC351571A1F2D5A0A6A58D5744F68F9C668211191507472C84F4D2B7D147B7F1BB833B04D6E0CC3945CA361CF9E63E01C277F08CD3D69B288562D33EB7EB83861585CB549B2D4EE38E50CA732275EE0B5ECD680378B2DBEBB0DBEE5B100998B1A83694140CF8588CABD91EB22B4369D5940'
r = requests.get(src)
with open('movie.mp4', 'wb') as f:
f.write(r.content)
print('下載完成')
運行:(下載成功,自行點開視頻查看,不演示)
5)搜狗關鍵詞搜索爬取

代碼:
import requests
#指定url
url='https://www.sogou.com/web'
kw=input('enter a word: ')
header={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'
}
param={
'query':kw
}
#發起請求,做好偽裝
response=requests.get(url=url,params=param,headers=header)
#獲取相應資料
content=response.text
fileName=kw+'.html'
#將資料保存在本地
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(content)
print(fileName,'爬取完成!!!')
運行輸入:張杰,回車

點開下載好的html如下:
6)爬取百度翻譯
分析找到介面:
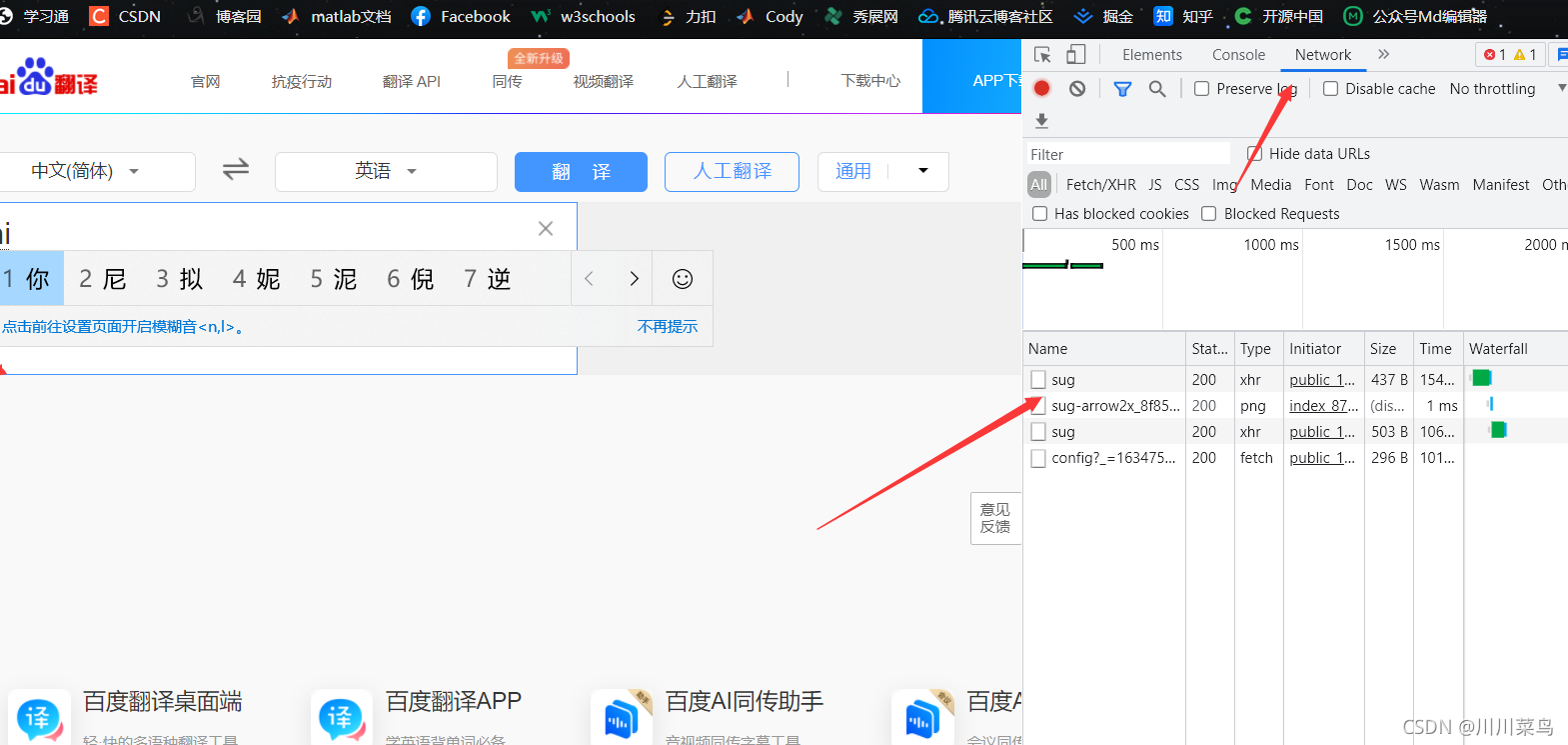
點開:
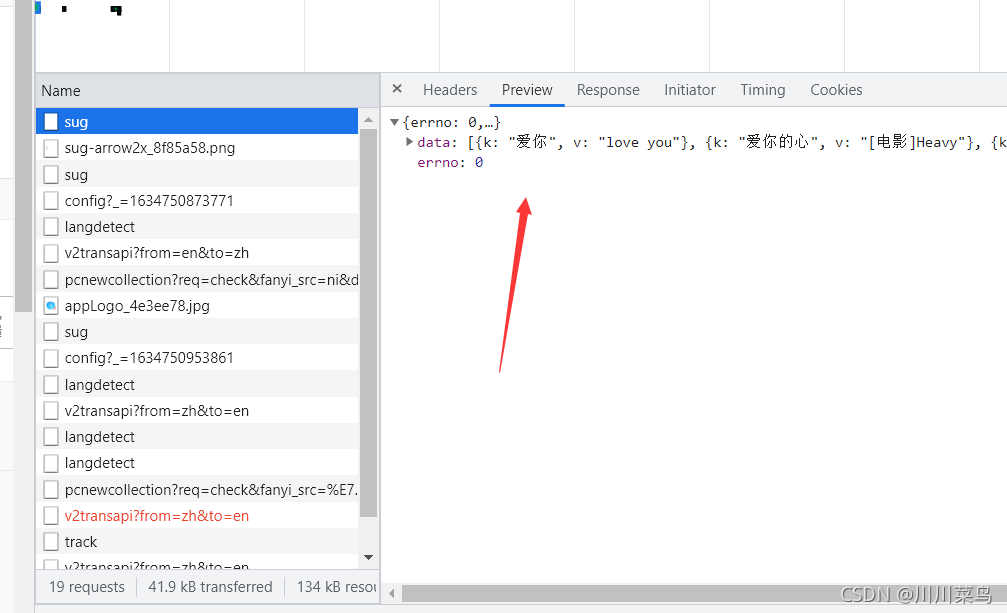
由此我們可以拿到介面和請求方式:
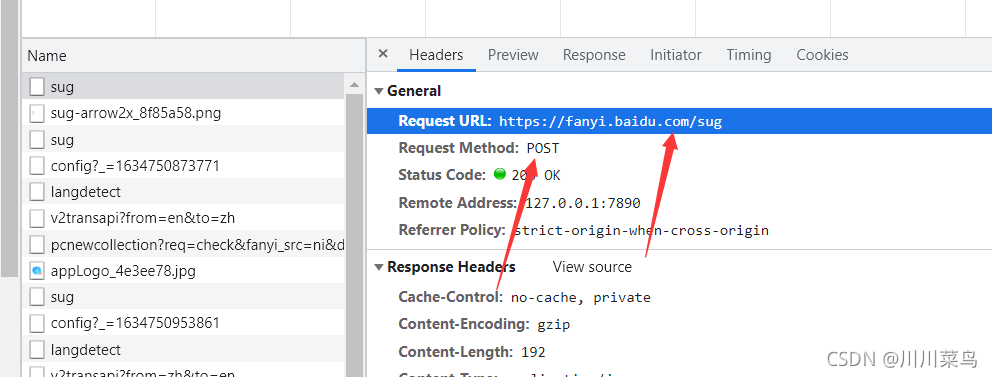
代碼為:
import json
import requests
url='https://fanyi.baidu.com/sug'
word=input('請輸入想翻譯的詞語或句子:')
data={
'kw':word
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2626.106 Safari/537.36'
}
reponse=requests.post(url=url,data=data,headers=headers)
dic_obj=reponse.json()
# print(dic_obj)
filename=word+'.json'
with open(filename,'w',encoding='utf-8') as fp:
json.dump(dic_obj,fp=fp,ensure_ascii=False)
j=dic_obj['data'][1]['v']
print(j)
測驗一:

測驗二:
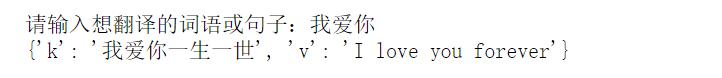
7)爬取豆瓣電影榜單
目標網址:
https://movie.douban.com/chart
代碼:
import json
import requests
url='https://movie.douban.com/j/chart/top_list?'
params={
'type': '11',
'interval_id': '100:90',
'action': '',
'start': '0',
'limit': '20',
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2626.106 Safari/537.36'
}
reponse=requests.get(url=url,params=params,headers=headers)
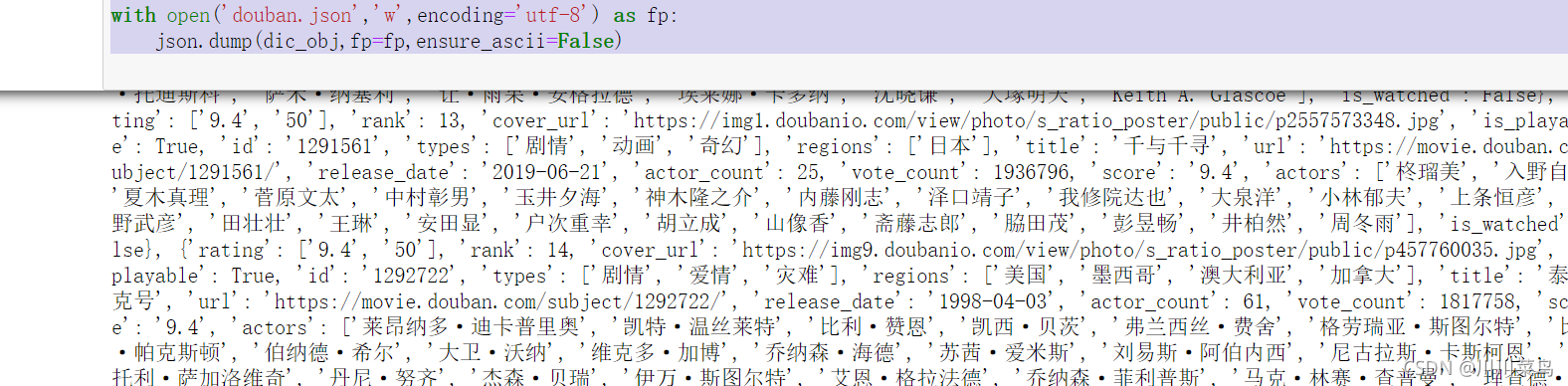
dic_obj=reponse.json()
print(dic_obj)
with open('douban.json','w',encoding='utf-8') as fp:
json.dump(dic_obj,fp=fp,ensure_ascii=False)
運行:(同時保存為json)
8) 美女私房照爬取
第一部分:定義要爬取的標簽和正在爬取的頁數
def UserUrl(theme,pagenum):
url = "https://tuchong.com/rest/tags/%(theme)s/posts?page=%(pagenum)s&count=20&order=weekly" % {'theme': urllib.parse.quote(theme), 'pagenum': pagenum}
#print(url)
return url
第二部分:防止反扒
def GetHtmltext(url):
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36"
}
try:
r = requests.get(url, headers=head, timeout=30)
r.raise_for_status() #如果回傳的狀態碼不是200,就到except中
return r
except:
pass
第三部分:定義獲取一個pagenum頁面中的所有圖集的URL鏈接的函式
def PictureFatherUrl(user_url):
try:
raw_data = GetHtmltext(user_url)
j_raw_data = json.loads(raw_data.text) #將獲取的網頁轉化為Python資料結構
# print(j_raw_data)
father_url = [] #將每個圖集的url定義為father_url的一個串列
for i in j_raw_data['postList']: #決議出的j_raw_data是一個多重字典,在這里先將postList字典的內容取出來
father_url.append(i['url']) #然后再取出鍵為“url”的值
return father_url
except:
return
第四部分:定義獲取一個圖集中所有圖片的url鏈接
def PictureUrl(url):
try:
html = GetHtmltext(url)
#利用正則運算式來匹配
url_list = list(re.findall('<img id="image\d+" class="multi-photo-image" src="([a-zA-z]+://[^\s]*)" alt="">', html.text))
return url_list
except:
第五部分:
#定義一個圖集中所有圖片的下載
def Download(url):
url_list = PictureUrl(url)
for i in url_list:
r = GetHtmltext(i)
file_name = os.path.join(save_path, i.split('/')[-1])
with open(file_name, 'wb') as f:
f.write(r.content)
f.close()
time.sleep(random.uniform(0.3, 0.5)) #為防止被反爬,在這里random了0.3-0.5的數,然后在下載一張圖片后,sleep一下
print('下載成功保存至 %s' % file_name)
主函式:
if __name__ == '__main__':
theme = input("你選擇的標簽(如果你不知道有什么標簽,去https://tuchong.com/explore/去看看有什么標簽吧,輸入不存在的標簽無法下載哦):")
pagenum_all = int(input("你要爬取的頁數(不要太貪心哦,數字太大會被封IP的):"))
save_path = os.path.join(theme)
m = 0
if not os.path.exists(save_path):
os.makedirs(save_path)
print("我知道你沒有創建保存路徑,我把檔案存在和此腳本同樣的路徑下的叫做“ %s ”的檔案夾下面了" % theme)
for i in range(1, pagenum_all+1):
n = 0
m += 1
print("正在下載第%d頁,一共%d頁" % (m, pagenum_all))
user_url = UserUrl(theme, i)
father_url = PictureFatherUrl(user_url)
for j in father_url:
n += 1
print("正在下載第%d套圖,一共%d套圖" % (n, len(father_url)))
Download(j)
time.sleep(random.randint(6, 10)) #同樣為了反爬,也random了6-10之間的數,更真實的模擬人的操作
完整源代碼:
#coding=gbk
"""
作者:川川
時間:2021/10/11
"""
import os
import re
import json
import requests
import time
import urllib.parse
import random
#定義要爬取的標簽和正在爬取的頁數
def UserUrl(theme,pagenum):
url = "https://tuchong.com/rest/tags/%(theme)s/posts?page=%(pagenum)s&count=20&order=weekly" % {'theme': urllib.parse.quote(theme), 'pagenum': pagenum}
#print(url)
return url
#利用requests使用get方法請求url,使用User-Agent是為了防止被反爬,這樣使得我們的爬取行為更像人的行為
def GetHtmltext(url):
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36"
}
try:
r = requests.get(url, headers=head, timeout=30)
r.raise_for_status() #如果回傳的狀態碼不是200,就到except中
return r
except:
pass
#定義獲取一個pagenum頁面中的所有圖集的URL鏈接的函式
def PictureFatherUrl(user_url):
try:
raw_data = GetHtmltext(user_url)
j_raw_data = json.loads(raw_data.text) #將獲取的網頁轉化為Python資料結構
# print(j_raw_data)
father_url = [] #將每個圖集的url定義為father_url的一個串列
for i in j_raw_data['postList']: #決議出的j_raw_data是一個多重字典,在這里先將postList字典的內容取出來
father_url.append(i['url']) #然后再取出鍵為“url”的值
return father_url
except:
return
#定義獲取一個圖集中所有圖片的url鏈接
def PictureUrl(url):
try:
html = GetHtmltext(url)
#利用正則運算式來匹配
url_list = list(re.findall('<img id="image\d+" class="multi-photo-image" src="([a-zA-z]+://[^\s]*)" alt="">', html.text))
return url_list
except:
pass
#定義一個圖集中所有圖片的下載
def Download(url):
url_list = PictureUrl(url)
for i in url_list:
r = GetHtmltext(i)
file_name = os.path.join(save_path, i.split('/')[-1])
with open(file_name, 'wb') as f:
f.write(r.content)
f.close()
time.sleep(random.uniform(0.3, 0.5)) #為防止被反爬,在這里random了0.3-0.5的數,然后在下載一張圖片后,sleep一下
print('下載成功保存至 %s' % file_name)
#定義主函式
if __name__ == '__main__':
theme = input("你選擇的標簽(如果你不知道有什么標簽,去https://tuchong.com/explore/去看看有什么標簽吧,輸入不存在的標簽無法下載哦):")
pagenum_all = int(input("你要爬取的頁數(不要太貪心哦,數字太大會被封IP的):"))
save_path = os.path.join(theme)
m = 0
if not os.path.exists(save_path):
os.makedirs(save_path)
print("我知道你沒有創建保存路徑,我把檔案存在和此腳本同樣的路徑下的叫做“ %s ”的檔案夾下面了" % theme)
for i in range(1, pagenum_all+1):
n = 0
m += 1
print("正在下載第%d頁,一共%d頁" % (m, pagenum_all))
user_url = UserUrl(theme, i)
father_url = PictureFatherUrl(user_url)
for j in father_url:
n += 1
print("正在下載第%d套圖,一共%d套圖" % (n, len(father_url)))
Download(j)
time.sleep(random.randint(6, 10)) #同樣為了反爬,也random了6-10之間的數,更真實的模擬人的操作
運行:按照提示輸入回車



當然,難道我的心只有小姐姐私房照?NONONO!你只要輸入該網任意一個標簽的都可給下載下來,比如模特?你可以測驗一下,
三、1024程式員節的我
我從上海來到長沙,除了吃之外,更是有幸認識了很多大佬,程式員并不禿頭,我們依然頭發茂盛!發幾張我在這里的部分合影,
1-跟CSDN總裁與一些大佬的合影

1-跟CSDN副總裁與一些大佬的合影:

吃的就不發了吧hhhhh很有有幸見到大家,
四、總結
由于單純的requests做爬取我僅僅也只能找到這一些例子進行演示爬取了,希望你認真從我的文章中領悟爬蟲的快樂,本篇結尾,requests就已經寫完,后續我會上更多的教程來豐富爬蟲,不用擔心你學不好,有問題粉絲群找我,
如果本篇內容你沒有看懂,那么你一定在基礎環節出現了問題,我寫的每一篇內容都是不斷向前進階,我不會一直停留基礎文,如果你基礎不扎實,那么推薦你看我專欄:python全堆疊基礎專欄
如果你是requests基礎知識不熟悉,請看我專欄兩篇關于requests的教程:爬蟲從入門到精通教程系列
寫文不容易,大家三連支持我一下好不好,拜托了!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/335473.html
標籤:其他