聊聊Lucene的創始人
我們在了解ElasticSearch的時候,必將繞不開Lucene,因為ElasticSearch是基于Luence開發的,因為Luence又是Doug Cutting開發的,所以我們先了解一下Doug Cutting這個人,
本故事內容來自公眾號:酸棗課堂
聊聊Doug Cutting
大資料就兩個問題:存盤+計算,
1998年9月4日,Google公司在美國硅谷成立,正如大家所知,它是一家做搜索引擎起家的公司,

無獨有偶,一位叫Doug Cutting的美國工程師,也迷上了搜索引擎,他做了一個用于文本搜索的函式庫(姑且理解為軟體的功能組件),命名為Lucene,
Lucene是用Java撰寫的,其作用是為各種中小型應用軟體加入全文檢索功能,因為好用而且開源(代碼公開),非常受廣大開發者們的歡迎,
早期的時候,這個專案被發布在Doug Cutting的個人網站和SourceForge(一個開源的軟體網站),后開,2001年底,lucene成為Apache軟體基金會Jakarta專案的一個子專案,

2004年,Doug Cutting再接再厲,在Lucene的基礎上和Apache開源伙伴Mike Cafarella合作,開發了一款可以替代當時的主流搜索的開源搜索引擎,命名為Nutch,

Nutch是一個建立在lucene核心之上的網頁搜索應用程式,可以下載下來直接使用,它在lucene的基礎上加了網路爬蟲和一些網頁相關的功能,目的就是從一個簡單的站內檢索推廣到全球網路的搜索上,就像Google一樣,
Nutch在業內的影響力比Lucene更大,
大批網站采用了Nutch平臺,大大降低了技術門檻,使低成本的普通計算機取代高價的Web服務器成為可能,甚至有一段時間,在硅谷有了一股用Nutch低成本的創業的潮流,
隨著時間的推移,無論是Google還是Nutch,都面臨搜索物件“體積”不斷增大的問題,尤其是Google,作為互聯網搜索引擎,需要存盤大量的網頁,并不斷優化自己的搜索演算法,提升搜索效率,

在這個程序中,Goolge確實找到了不少好辦法,并且無私地分享了出來,
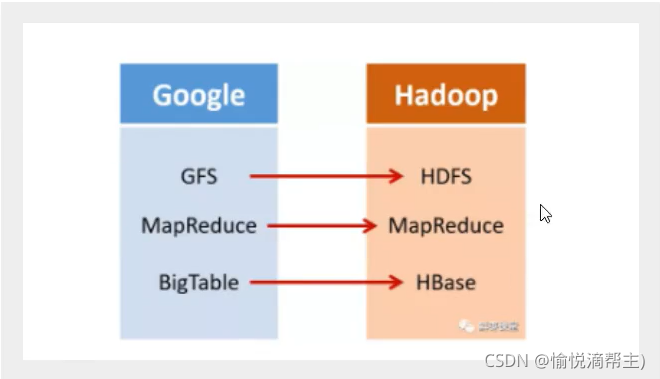
2003年,Google發表了一篇技術學術論文,公開介紹了自己的谷歌檔案系統GFS(Google File System),這是Google公司為了存盤海量搜索資料而設計的專用檔案存盤系統,
第二年,也就是2004年,Doug Cutting基于Google的GFS論文,實作了分布式檔案存盤系統,并將它命名為NDFS(Nutch Distributed File System),
還是2004年,Google又發表了一篇技術學術論文,介紹了自己的MapReduce編程模型,這個編程模型,用于大規模資料集(大于1TB)的并行分析運算,
第二年(2005年),Doug Cutting又基于MapReduce,在Nutch搜索引擎實作了該功能,
2006年,當時依然很厲害的Yahoo(雅虎)公司,招安了Doug Cutting,
加盟Yahoo之后,Doug Cutting將NDFS和MapReduce進行了升級改造,并重新命名為Hadoop(NDFS也改名為HDFS,Hadoop Distributed File),
這個,就是后來大名鼎鼎的大資料框架系統———Hadoop的由來,而Doug Cutting,則被人們稱為Hadoop之父,

Hadoop這個名字,實際上使Doug Cutting他兒子的黃色玩具大象的名字,所以,Hadoop的Logo,就是一只奔跑的黃色大象,
我們繼續往下說,還是2006年,Google又發表論文了,這次,他們介紹了自己的BigTable,這是一種分布式資料存盤系統,一種用來處理海量資料的非關系型資料庫,
Doug Cutting當然沒有放過,在自己的hadoop系統里面,引入了BigTable,并命名為HBanse,
好吧,反正就是跟緊Google時代的步伐,你出什么,我學什么,所以,Hadoop的核心部分,基本上都有Google的影子,
2008年1月,Hadoop成功上位,正式稱為Apache基金會的頂級專案,
同年2月,Yahoo宣布建成了一個擁有一萬個內核的Hadoop集群,并將自己的搜索引擎產品部署在上面,7月,Hadoop打破世界紀錄,稱為最快排序1TB資料的系統,用時209秒,
聊聊Shay Banon
通過上述介紹我們了解到Lucence的由來,并且知道了Lucene是一套資訊檢索工具包,是一個基于Java撰寫的jar包,不包含搜索引擎系統,
包含的:索引結構!讀寫索引的工具!排序,搜索規則,,,工具類!
Lucene和ElasticSearch關系:
ElasticSearch是基于Lucene做了一些封裝和增強(我們上手是十分簡單的),
歷史由來:
多年前,一個叫做Shay Banon的剛結婚不久的失業開發者,由于妻子要去倫敦學習廚師,他便跟著也去了,他在找作業的程序中,為了給妻子構建一個食譜的搜索引擎,他開始構建一個早期版本的Lucene,
直接基于Luence作業會比較困難,所以Shay開始抽象Lucene代碼以便java程式員可以在應用中添加搜索功能,他發布的第一個開源專案,叫做“Compass”,
后開Shay找到一份作業,這份作業處在高性能和記憶體資料網路的分布式環境中,因此高性能的、實時的、分布式的搜索引擎也就是利索當然需要的,然后他決定重寫Compass庫使其成為一個獨立的服務叫做Elasticsearch,
第一個公開版本出現在2010年2月,在那之后Elasticsearch已經成為GitHub上最受歡用的專案之一,代碼貢獻者超過300人,一家主營ElasicSearch的公司就此成立,他們一邊提供商業支持一邊開發新功能,不過Elasticseach將永遠開源且對所有人可用,
不過,Shay的妻子依舊等待者她的搜索食譜......
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/336197.html
標籤:其他