一、使用列運算式查詢資料幀(DataFrame)
1、列、列名和列運算式
- 大多數DataFrame的轉換(transformations)需要你指定一個或多個列
- select(column1, column2, …)
- orderBy(column1, column2, …)
- 對于許多簡單的查詢(queries),只需將列名指定為字串
- peopleDF.select(“firstName”,“lastName”)
- 有些型別的轉換(transformations)使用列參考或列運算式而不是列名字串

2、示例:列參考(Python)
- 在Python中,有兩種相同的方法來參考列
peopleDF = spark.read.option("header","true").csv("people.csv")
peopleDF['age']
Column<age>
peopleDF.age
Column<age>
peopleDF.select(peopleDF.age).show()
+---+
|age|
+---+
| 52|
| 32|
| 28|
3、示例:列參考(Scala)
- 在Scala中,同樣有兩種方法來參考列
- 第一:使用DataFrame的列名
- 第二:僅使用列名,直到在轉換(transformations)中使用時才完全決議
val peopleDF = spark.read.option("header","true").csv("people.csv")
peopleDF("age")
org.apache.spark.sql.Column = age
$"age"
org.apache.spark.sql.ColumnName = age
peopleDF.select(peopleDF("age")).show
+---+
|age|
+---+
| 52|
| 32|
4、列運算式
- 創建列運算式時,使用列參考而不是簡單的字串
- 列操作包括:
- 算術運算子,如+、-、%、/和*
- 比較和邏輯運算子,如>、<、&&和||
- “等于” 比較在Scala中是"= = =",在Python中是"=="
- 字串函式,如contains, like和substring
- 資料測驗函式,如isNull, isNotNull和NaN(不是一個數字)
- 排序函式,如asc和desc
- 僅在sort或者orderBy中使用時有效
- 有關運算子和函式的完整串列,請參閱API檔案中的Column
5、示例:列運算式(Python)
peopleDF.select("lastName", peopleDF.age * 10).show()
+--------+----------+
|lastName|(age * 10)|
+--------+----------+
| Hopper| 520|
| Turing| 320|
peopleDF.where(peopleDF.firstName.startswith("A")).show()
+-----+--------+---------+---+
|pcode|lastName|firstName|age|
+-----+--------+---------+---+
|94020| Turing| Alan| 32|
|94020|Lovelace| Ada| 28|
+-----+--------+---------+---+
6、示例:列運算式(Scala)
peopleDF.select($"lastName", $"age" * 10).show
+--------+----------+
|lastName|(age * 10)|
+--------+----------+
| Hopper| 520|
| Turing| 320|
peopleDF.where(peopleDF("firstName").startsWith("A")).show
+-----+--------+---------+---+
|pcode|lastName|firstName|age|
+-----+--------+---------+---+
|94020| Turing| Alan| 32|
|94020|Lovelace| Ada| 28|
+-----+--------+---------+---+
7、列別名(1)
- 使用列別名函式重命名結果集中的列
- name是別名(alias)的同義詞
- 示例(Python):針對列名(age * 10)使用新別名age_10
peopleDF.select("lastName",(peopleDF.age * 10).alias("age_10")).show()
+--------+------+
|lastName|age_10|
+--------+------+
| Hopper| 520|
| Turing| 320|
- 示例(Scala):針對列名(age * 10)使用新別名age_10
peopleDF.select($"lastName",($"age" * 10).alias("age_10")).show
+--------+------+
|lastName|age_10|
+--------+------+
| Hopper| 520|
| Turing| 320|
二、Queries的分組(Group)和聚合(Aggregation)
1、Queries的聚合(Aggregation)
- 聚合查詢對一組值執行計算,并回傳單個值
- 若要對一組分組值執行聚合,需要將groupBy與聚合函陣列合使用
- 例子:每個郵政編碼有多少人?
peopleDF.groupBy("pcode").count().show()
+-----+-----+
|pcode|count|
+-----+-----+
|94020| 2|
|87501| 1|
|02134| 2|
+-----+-----+
2、轉換(Transformation)中的groupBy
- groupBy接受一個或多個列名或參考
- 在Scala中,回傳一個RelationalGroupedDataset物件
- 在Python中,回傳GroupedData物件
- 回傳的物件提供了聚合函式,包括:
- count
- max and min
- mean (and its alias avg)
- sum
- pivot(行轉列)
- agg(使用附加聚合函式進行聚合)
3、附加聚合函式
- 函式物件提供了幾個附加的聚合函式
- 聚合函式包括:
- first/last:回傳組中的第一個或最后一個項
- countDistinct:回傳組中唯一項(去重后)的數目
- approx_count_distinct:回傳唯一項(去重后)的近似計數
- Much faster than a full count
- stddev:計算一組值的標準偏差
- var_sample/var_pop:計算一組值的方差
- covar_samp/covar_pop:計算一組值的樣本和總體協方差
- corr:回傳一組值的相關性
4、示例:使用函式物件
python:
from pyspark.sql.functions import stddev
peopleDF.groupBy("pcode").agg(stddev("age")).show()
+-----+------------------+
|pcode| stddev_samp(age)|
+-----+------------------+
|94020|0.7071067811865476|
|87501| NaN|
|02134|2.1213203435596424|
+-----+------------------+
三、Joining DataFrames
1、Joining DataFrames
- 使用轉換(transformation)中的join來連接兩個dataframe
- DataFrames支持幾種型別的連接
- inner (default)
- outer
- left_outer
- right_outer
- leftsemi
- 轉換(transformation)中的crossJoin將一個DataFrame的每個元素與另一個DataFrame的每個元素連接起來
2、示例:一個簡單的Inner Join

Scala:
val peopleDF = spark.read.option("header","true").csv("people-no-pcode.csv")
val pcodesDF = spark.read.option("header","true").csv("pcodes.csv")
python:
peopleDF.join(pcodesDF, "pcode").show()
+-----+--------+---------+---+---------+-----+
|pcode|lastName|firstName|age| city|state|
+-----+--------+---------+---+---------+-----+
|02134| Hopper| Grace| 52| Boston| MA|
|94020|Lovelace| Ada| 28|Palo Alto| CA|
|87501| Babbage| Charles| 49| Santa Fe| NM|
|02134| Wirth| Niklaus| 48| Boston| MA|
+-----+--------+---------+---+---------+-----+
3、示例:一個Left Outer Join
- 需要指定連接型別為inner(默認)、outer、left_outer、right_outer或leftsemi
python:
peopleDF.join(pcodesDF, "pcode", "left_outer").show()
+-----+--------+---------+---+---------+-----+
|pcode|lastName|firstName|age| city|state|
+-----+--------+---------+---+---------+-----+
|02134| Hopper| Grace| 52| Boston| MA|
| null| Turing| Alan| 32| null| null|
|94020|Lovelace| Ada| 28|Palo Alto| CA|
|87501| Babbage| Charles| 49| Santa Fe| NM|
|02134| Wirth| Niklaus| 48| Boston| MA|
+-----+--------+---------+---+---------+-----+
Scala:
peopleDF.join(pcodesDF,peopleDF("pcode") === pcodesDF("pcode"),"left_outer").show
+-----+--------+---------+---+---------+-----+
|pcode|lastName|firstName|age| city|state|
+-----+--------+---------+---+---------+-----+
|02134| Hopper| Grace| 52| Boston| MA|
| null| Turing| Alan| 32| null| null|
|94020|Lovelace| Ada| 28|Palo Alto| CA|
|87501| Babbage| Charles| 49| Santa Fe| NM|
|02134| Wirth| Niklaus| 48| Boston| MA|
+-----+--------+---------+---+---------+-----+
4、示例:對名稱不同的列進行連接
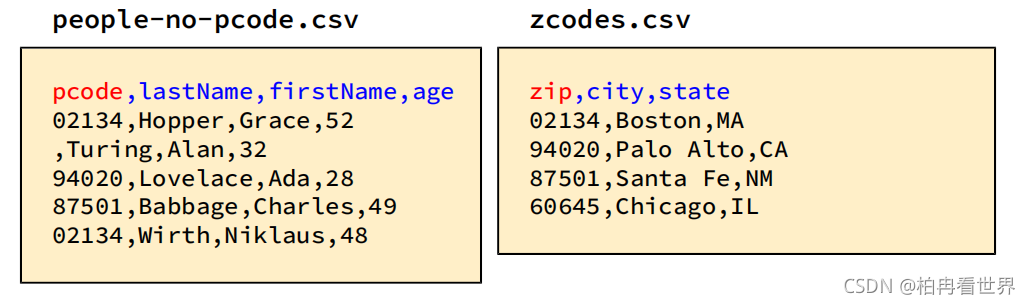
- 當連接列的名稱不同時,請使用列運算式
- 結果包括兩個連接列
Scala:
peopleDF.join(zcodesDF, $"pcode" === $"zip").show
+-----+--------+---------+---+-----+---------+-----+
|pcode|lastName|firstName|age| zip| city|state|
+-----+--------+---------+---+-----+---------+-----+
|02134| Hopper| Grace| 52|02134| Boston| MA|
|94020|Lovelace| Ada| 28|94020|Palo Alto| CA|
|87501| Babbage| Charles| 49|87501| Santa Fe| NM|
|02134| Wirth| Niklaus| 48|02134| Boston| MA|
+-----+--------+---------+---+-----+---------+-----+
python:
peopleDF.join(zcodesDF,peopleDF.pcode == zcodesDF.zip).show()
+-----+--------+---------+---+-----+---------+-----+
|pcode|lastName|firstName|age| zip| city|state|
+-----+--------+---------+---+-----+---------+-----+
|02134| Hopper| Grace| 52|02134| Boston| MA|
|94020|Lovelace| Ada| 28|94020|Palo Alto| CA|
|87501| Babbage| Charles| 49|87501| Santa Fe| NM|
|02134| Wirth| Niklaus| 48|02134| Boston| MA|
+-----+--------+---------+---+-----+---------+-----+
四、基本要點
- DataFrame中的列可以通過名稱或Column物件指定
- 可以使用列運算子定義列運算式
- 使用groupBy和聚合函式計算行組的聚合值
- 使用join操作連接兩個dataframe
- 支持inner, left outer, right outer and semi joins
五、實踐練習:使用DataFrame的Queries分析資料
1、使用列運算式查詢資料幀
1、可選:查看Column類(在Python模塊pyspark中)的API檔案,sql和Scala包org.apache.spark.sql),注意各種可用的選項,
2、在終端中啟動Spark shell(如果還沒有運行),
3、基于Hive devsh,新建一個名為accountsDF的DataFrame,accounts表,
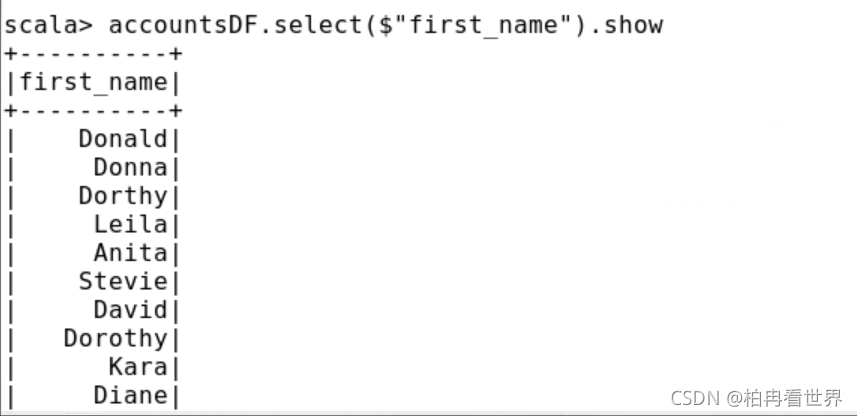
4、嘗試使用select進行一個簡單的查詢,使用兩種列參考語法,
pyspark> accountsDF.select(accountsDF["first_name"]).show()
pyspark> accountsDF.select(accountsDF.first_name).show()
scala> accountsDF.select(accountsDF("first_name")).show
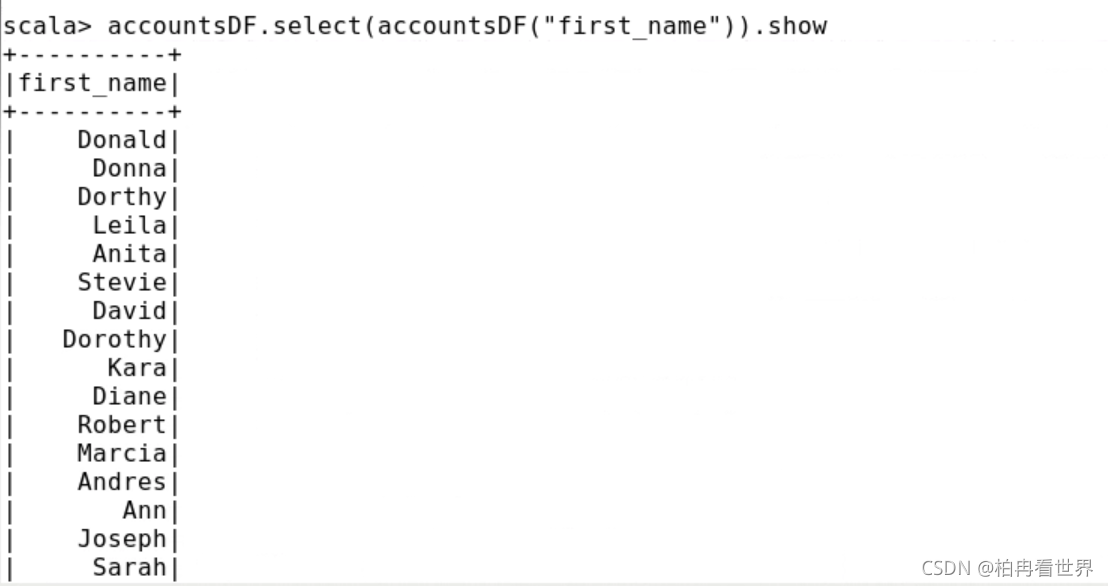
scala> accountsDF.select($"first_name").show
5、要研究列運算式,請基于accountsDF DataFrame中的first_name列創建一個要使用的列物件,
pyspark> fnCol = accountsDF.first_name
scala> val fnCol = accountsDF("first_name")

6、注意,物件型別是Column,要查看可用的方法和屬性,請使用制表符補全—即輸入fnCol,其次是選項卡,
7、當您對現有列執行操作時,將創建New Column物件,在上面創建的fnCol物件上使用相等運算子,根據一個列運算式創建一個新的Column物件,該列運算式標識名為Lucy的用戶,
pyspark> lucyCol = (fnCol == "Lucy")
scala> val lucyCol = (fnCol === "Lucy")

8、在選擇陳述句中使用lucyCol列運算式,因為lucyCol是基于布爾運算式的,所以列值將是true或false,具體取決于first_name列的值,確認以true標識名為Lucy的用戶,
pyspark> accountsDF.select(accountsDF.first_name,accountsDF.last_name,lucyCol).show()
scala> accountsDF.select($"first_name",$"last_name",lucyCol).show
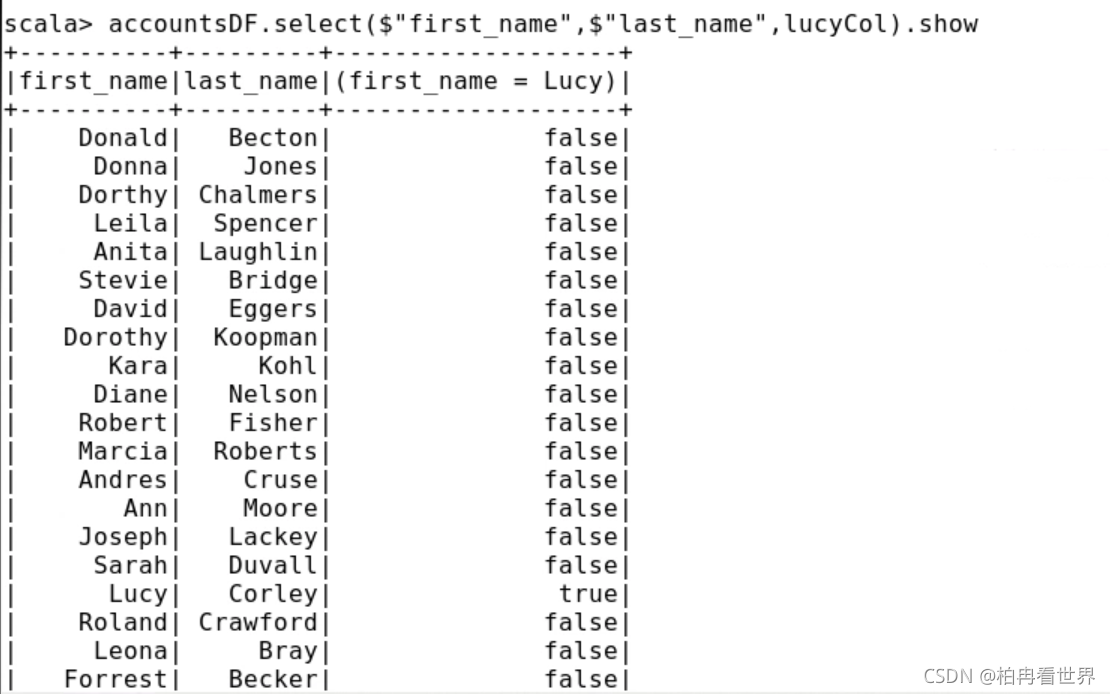
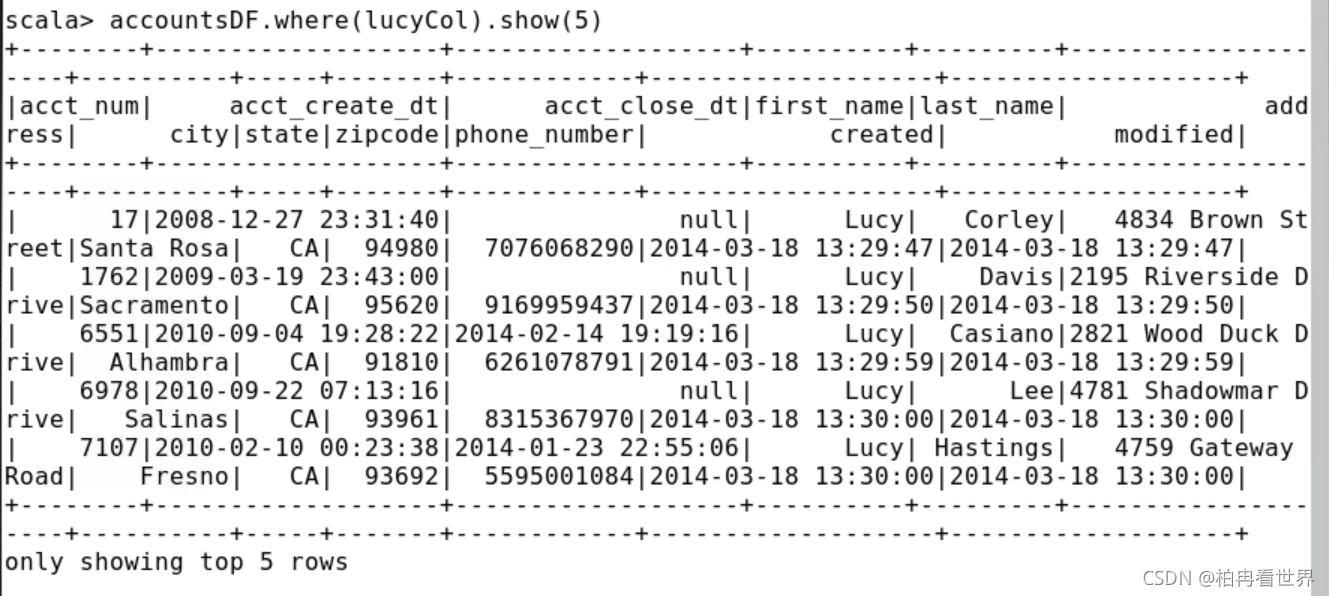
9、where操作需要一個基于布爾的列運算式,在where轉換中使用lucyCol列運算式,并在生成的DataFrame中查看資料,確認資料中只有名為Lucy的用戶,
> accountsDF.where(lucyCol).show(5)
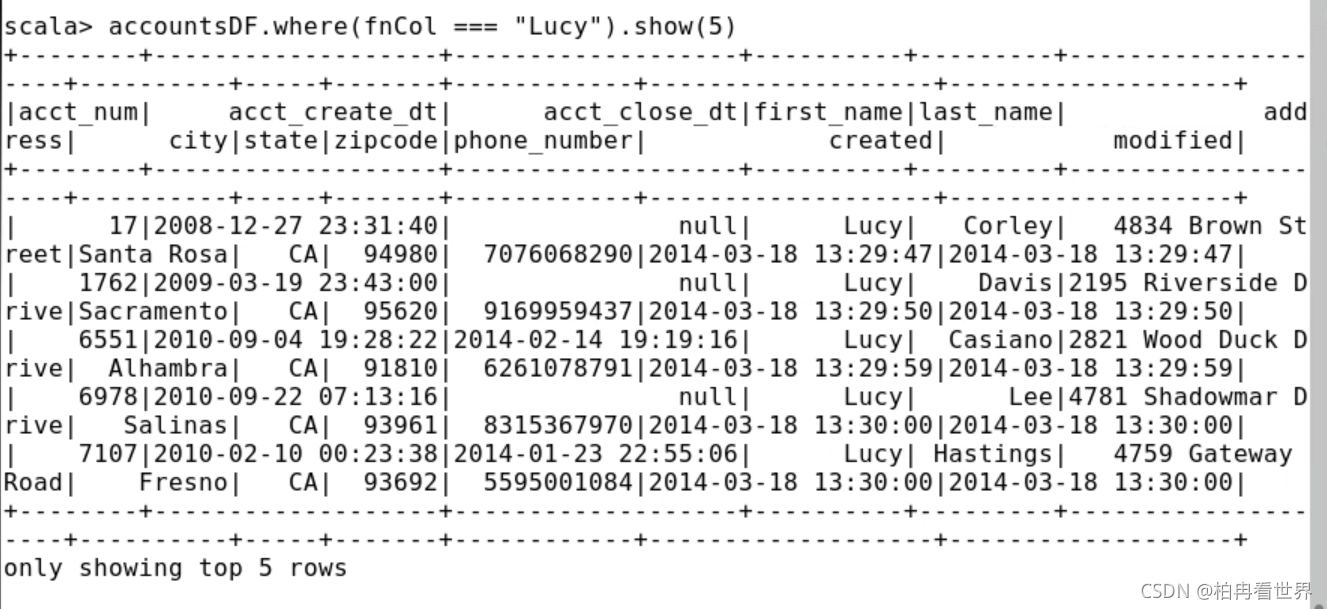
10、列運算式不需要賦值給變數,嘗試不使用lucyCol變數的相同查詢,
pyspark> accountsDF.where(fnCol == "Lucy").show(5)
scala> accountsDF.where(fnCol === "Lucy").show(5)
11、列運算式不限于上面的操作,它們可以用于任何可以使用簡單列的轉換,例如選擇,嘗試選擇城市和州列,以及phone_number列的前三個字符(在美國,電話號碼的前三個數字被稱為地區代碼),在phone_number列上使用substr運算子提取區域代碼,
pyspark> accountsDF.select("city","state",accountsDF.phone_number.substr(1,3)).show(5)
scala> accountsDF.select($"city",$"state",$"phone_number".substr(1,3)).show(5)

12、注意,在最后一步中,查詢回傳的值是正確的,但是列名是子字串(phone_number, 1, 3),它很長,很難處理,重復相同的查詢,使用別名運算子將該列重命名為area_code,
pyspark> accountsDF.select("city","state",accountsDF.phone_number.substr(1,3).alias("area_code")).show(5)
scala> accountsDF.select($"city",$"state",$"phone_number".substr(1,3).alias("area_code")).show(5)

13、執行一個查詢,結果是只包含first_name和last_name列的DataFrame,并且只包含名和姓都以相同的兩個字母開頭的用戶,(例如,用戶Roberta Roget將被包括在內,因為她的姓和名都以“Ro”開頭,)
2、按名稱分組和計數
14、使用帶有count的groupBy查詢accountsDF DataFrame,以找出共享每個姓氏的總人數,(注意計數聚合轉換回傳一個DataFrame,不像計數DataFrame操作,它回傳一個單一的值給驅動程式,)
pyspark> accountsDF.groupBy("last_name").count().show(5)
scala> accountsDF.groupBy("last_name").count.show(5)

15、還可以按多列分組,再次查詢accountsDF,這一次計算擁有相同姓和名的人數,
pyspark> accountsDF.groupBy("last_name","first_name").count().show(5)
scala> accountsDF.groupBy("last_name","first_name").count.show(5)
3、通過郵政編碼將帳戶資料與蜂窩塔連接
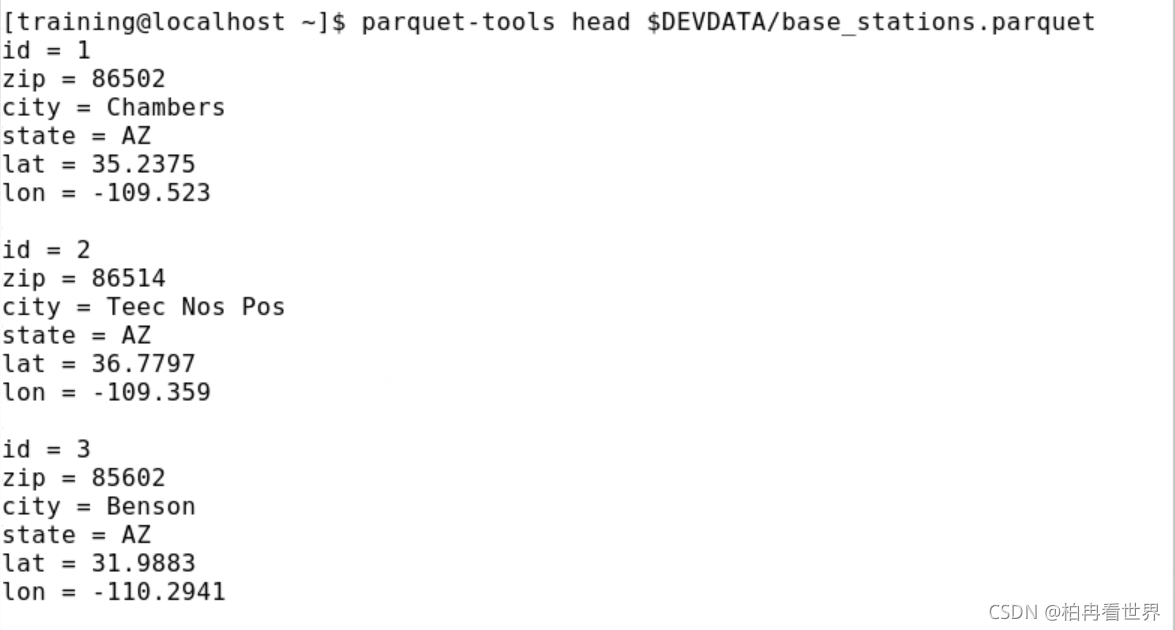
16、在本節中,您將將一直使用的帳戶資料與位于base_stations中的蜂窩基站位置資料連接起來,鑲木地板檔案,首先檢查模式和資料的一些記錄,在單獨的終端視窗(不是運行Spark shell的終端視窗)中使用parquet-tools命令,
$ parquet-tools schema $DEVDATA/base_stations.parquet

$ parquet-tools head $DEVDATA/base_stations.parquet
17、上傳資料檔案到HDFS,
$ hdfs dfs -put $DEVDATA/base_stations.parquet /devsh_loudacre/
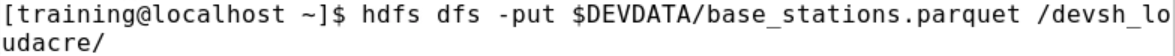
18、在Spark shell中,使用基站資料創建一個名為baseDF的新DataFrame,檢查baseDF模式和資料,確保它與Parquet檔案中的資料匹配,
scala> val baseDF = spark.read.parquet("/devsh_loudacre/base_stations.parquet")

19、一些賬戶持有人居住在有基站的郵政編碼地區,加入baseDF和accountsDF以找到這些用戶,對于每個用戶,包括他們的帳戶ID、名、姓,以及他們的郵政編碼中基站的ID和位置資料(緯度和經度),
pyspark> accountsDF.select("acct_num","first_name","last_name","zipcode").join(baseDF, baseDF.zip == accountsDF.zipcode).show()
scala> accountsDF.select("acct_num","first_name","last_name","zipcode").join(baseDF,$"zip" === $"zipcode").show()

4、計數活動設備
20、accountdevice CSV資料集包含所有帳戶使用的所有設備的串列,資料集中的每一行包括行ID、賬戶ID、設備型別的ID、設備被激活的日期和具體的設備ID,CSV資料檔案在$DEVDATA/accountdevice目錄下,查看資料集中的資料,然后將該目錄及其內容上傳到HDFS目錄/ devsh_loudacre/accountdevice,
21、基于accountdevice資料檔案創建DataFrame,
22、使用帳戶設備資料和之前在本練習中創建的DataFrames來查找所有活動帳戶(即尚未關閉的帳戶)中每個設備模型的總數,新的DataFrame應該從最常用的模型到最不常用的模型進行排序,將資料保存為Parquet檔案,保存在/devsh_loudacre/top_devices目錄下,列如下:


提示:
- 活動賬戶是賬戶表中acct_close_dt(賬戶關閉日期)為空值的賬戶,
- 設備賬戶資料中的account_id列對應于accounts表中的acct_num列,
- 設備賬戶資料中的device_id列對應/devsh_loudacre/devices中已知設備串列中的devnum列,json檔案,
- 當你計數設備時,使用withcolumnrename將計數列重命名為active_num,(count列名有二義性,因為它既是函式又是列,)
- 完成這個練習的查詢有點復雜,包括一系列的轉換,您可能希望將變數分配給由構成查詢的轉換產生的中間dataframe,以使代碼更容易使用和除錯,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/336198.html
標籤:其他
上一篇:ElasticSearch的由來